
热门标签
热门文章
- 1程序员注意了!5-25万元神仙补贴!
- 2前端代码规范常见错误 二_报错代码 规范
- 3某百度程序员:每天十点上班,午休两小时,每天闲逛,晚上八点就下班!
- 424个 Docker 常见疑难杂症处理技巧_docker 24
- 5hr谈薪资后说请示领导_当HR问你期望薪资时,请谨记这7点,助你高薪入职
- 6机器学习-K近邻算法(KNN)
- 7微信小程序云函数使用方法_微信小程序 云函数日志怎么上传
- 8十二月组队学习之——目标检测Task02:练死劲儿-网络设计_分类头和回归头
- 9安装faac-1.28报错 /bin/bash^M: bad interpreter: No such file or directory解决办法_输入bootstrap后no such
- 10ALBERT 清晰解读_albert使用
当前位置: article > 正文
大模型中的temperature参数+随机采样策略_大模型 temperature
作者:知新_RL | 2024-05-01 16:26:16
赞
踩
大模型 temperature
一、问题来源:
使用GPT-3.5的时候发现相同的输入会得不一样的结果
二、根因定位:
核心就在于采样策略,一图胜千言:
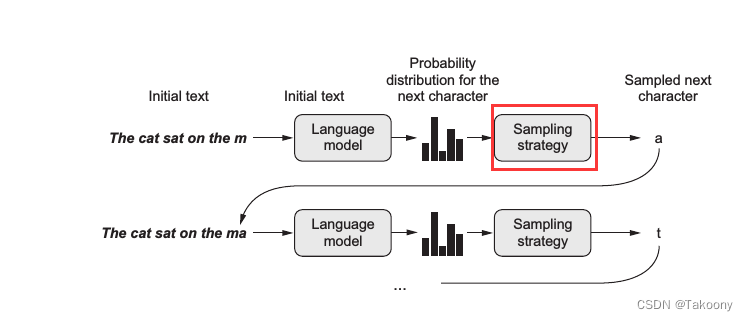
上图中语言模型 (language model) 的预测输出其实是字典中所有词的概率分布,而通常会选择生成其中概率最大的那个词。不过图中出现了一个采样策略 (sampling strategy),这意味着有时候我们可能并不想总是生成概率最大的那个词。设想一个人的行为如果总是严格遵守规律缺乏变化,容易让人觉得乏味;同样一个语言模型若总是按概率最大的生成词,那么就容易变成 XX讲话稿了
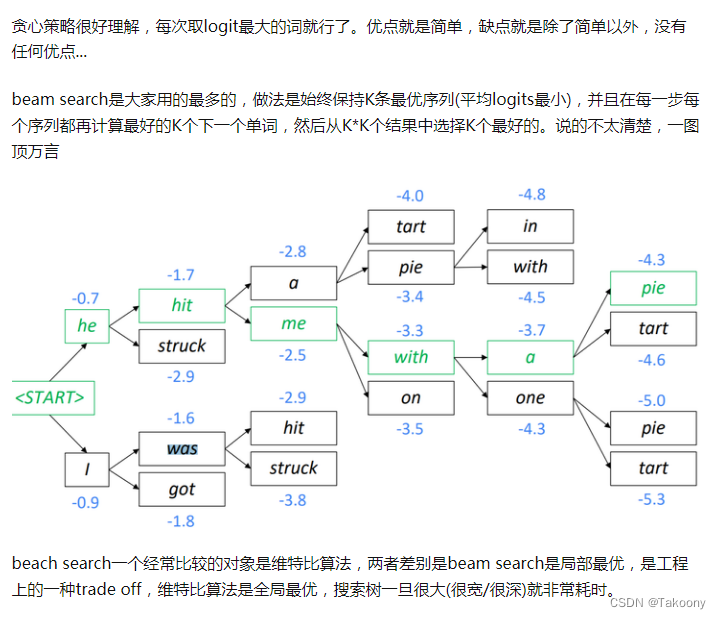
解码策略
- greedy decoding
- beam search decoding
- Sampling-based decoding
- Softmax temperature

temperature参数
因此在生成词的过程中引入了采样策略,在最后从概率分布中选择词的过程中引入一定的随机性,这样一些本来不大可能组合在一起的词可能也会被生成,进而生成的文本有时候会变得有趣甚至富有创造性。采样的关键是引入一个temperature参数,用于控制随机性。假设 p(x)为模型输出的原始分布,则加入 temperature 后的新分布为:
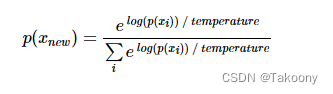
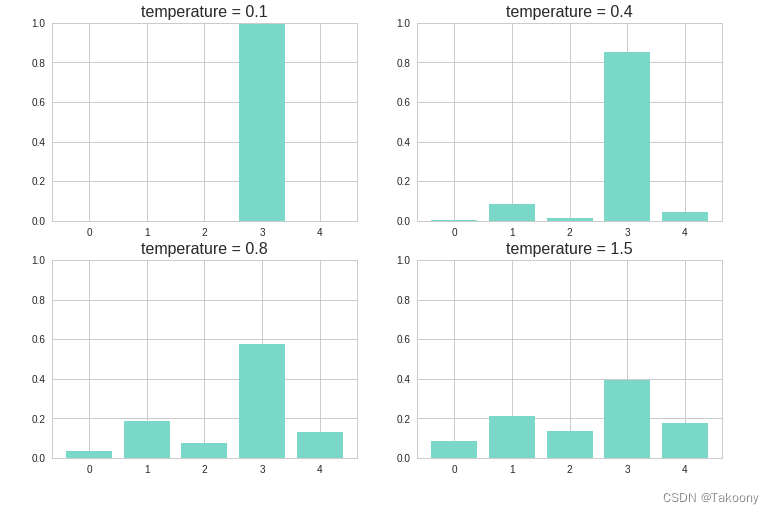
下图展示了不同的 temperature 分别得到的概率分布。temperature 越大,则新的概率分布越均匀,随机性也就越大,越容易生成一些意想不到的词。
def sample(p, temperature=1.0): # 定义采样策略
distribution = np.log(p) / temperature
distribution = np.exp(distribution)
return distribution / np.sum(distribution)
p = [0.05, 0.2, 0.1, 0.5, 0.15]
for i, t in zip(range(4), [0.1, 0.4, 0.8, 1.5]):
plt.subplot(2, 2, i+1)
plt.bar(np.arange(5), sample(p, t))
plt.title("temperature = %s" %t, size=16)
plt.ylim(0,1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
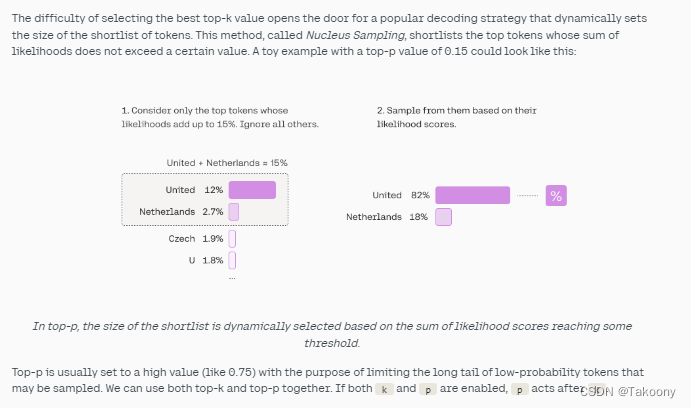
top-k参数

top-p参数
https://www.cnblogs.com/massquantity/p/9511694.html
https://zhuanlan.zhihu.com/p/560847355
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/519704
推荐阅读
相关标签

