
- 1Three.js Vue 如何加载字体,和遇到问题解决: 中加载字体的问题 Uncaught SyntaxError: Unexpected token = in JSON at position 0_threejs text3d 字体 不显示 vue3
- 2力扣45.跳跃游戏Ⅱ(贪心思路详解)_跳跃游戏 贪心
- 3Python dict字典全部操作方法_python dict操作
- 4linux kernel内存泄漏检测工具之kmemleak
- 52022-年终总结_年终总结 csdn 天津
- 6Flutter与Android混合编码配置笔记
- 7Python上海美食餐厅餐馆商家爬虫数据可视化分析和推荐查询系统 开题报告(1)
- 8不容错过,前端 Code Review 的最佳实践方案来了
- 9CCleaner2024win电脑专用系统垃圾清理与优化工具
- 10【数据结构】纯c语言双向链表_c语言 双向链表
每天十分钟学会Spark【期末必看系列】
赞
踩
Spark编程基础 [参考Spark大数据技术与应用(第二版)]

今天我们就学习过程中常见的问题进行解答
我们先来聊一聊vm无法连接Xshell的原因:
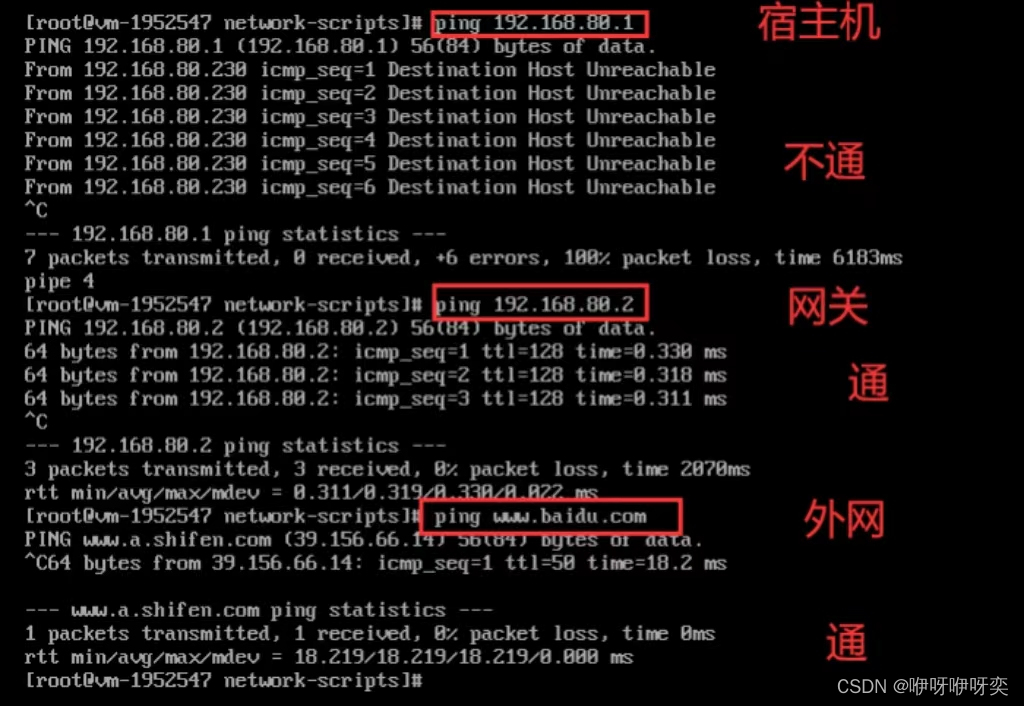
首先我们通过ping来判断是哪一类问题:
ping 主机
ping 网关
ping 外网
一:虚拟机宿主机互ping不通
二:虚拟机对宿主机ping不通,但能ping外网
三:虚拟机对宿主机ping通,不能ping外网
问题一:防火墙未关闭
解决方法:关闭防火墙
问题二:网卡未生效
输入命令 ifconfig,若输出的网卡信息不含inet [ip地址],则说明网卡未生效
解决方法:修改配置文件:/etc/sysconfig/network-scripts/ifcfg-[网卡名]
问题三:虚拟网卡VMnet8
查看是否禁止了网络连接
解决方法:打开网络连接显示已启用

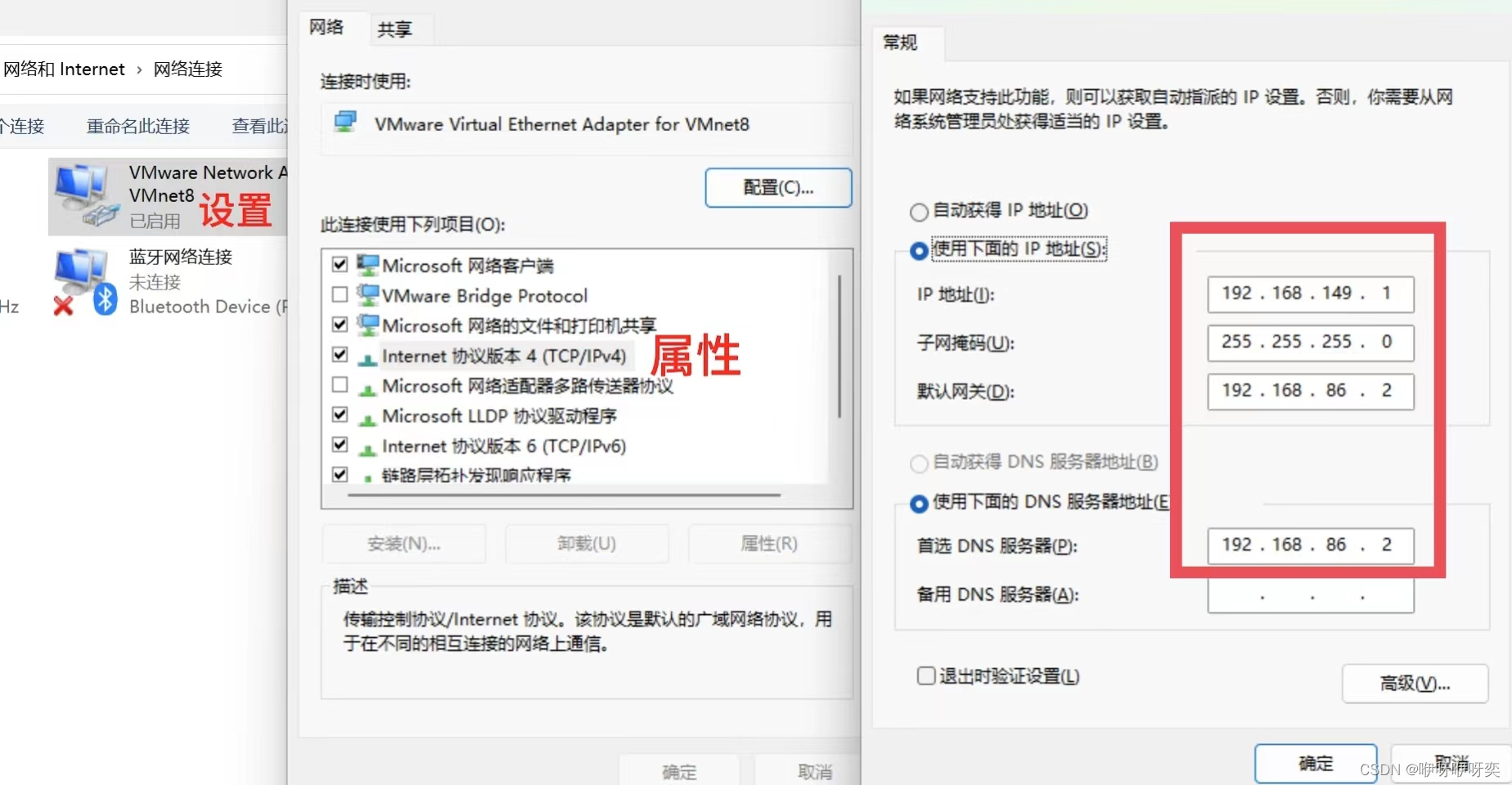
问题四:网关和DNS设置问题
解决方法:

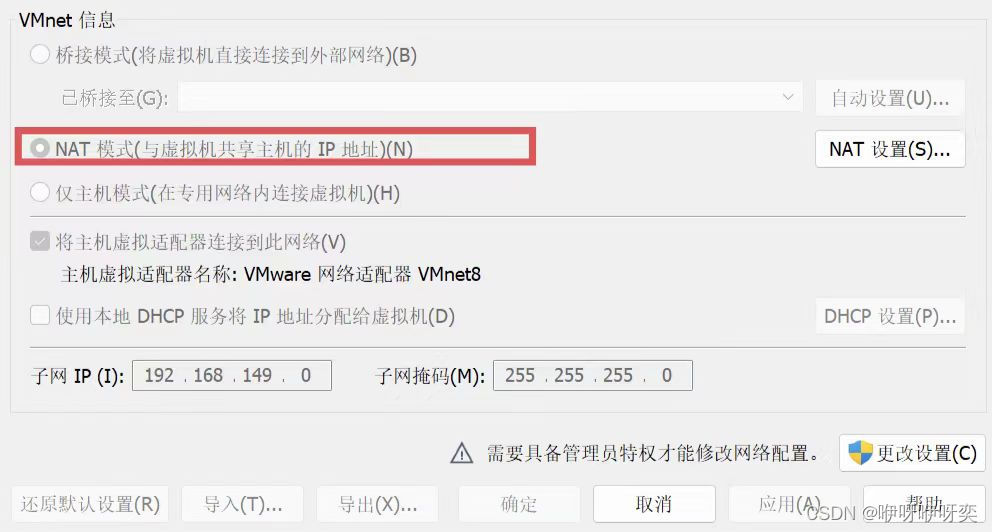
问题五:网络模式为仅Host-only,或为Bridge但分配了不合法的IP
解决方法:
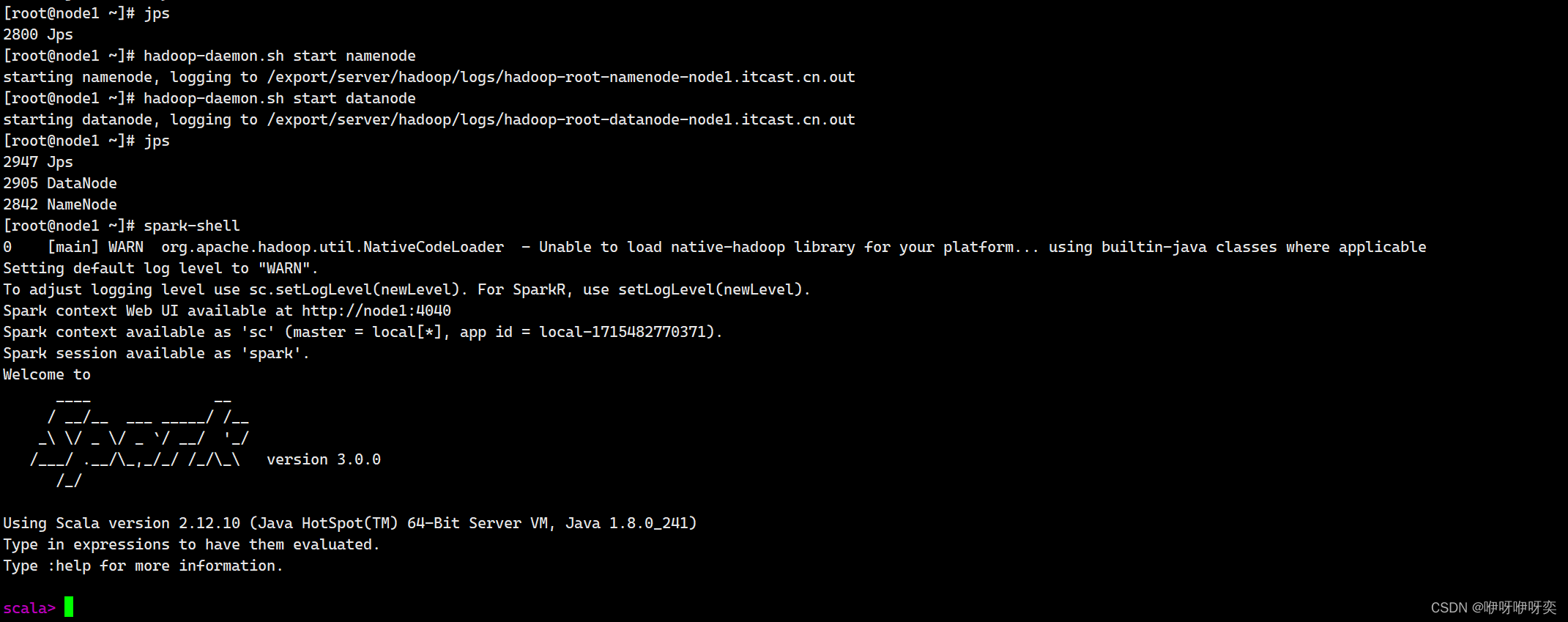
连接上了Xshell后我们要查看进程jps然后打开spark-shell
关键代码:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
接着我们来讲讲另一个问题:
打jar包
(已上传参考代码,待审核中。。。)
方法一:
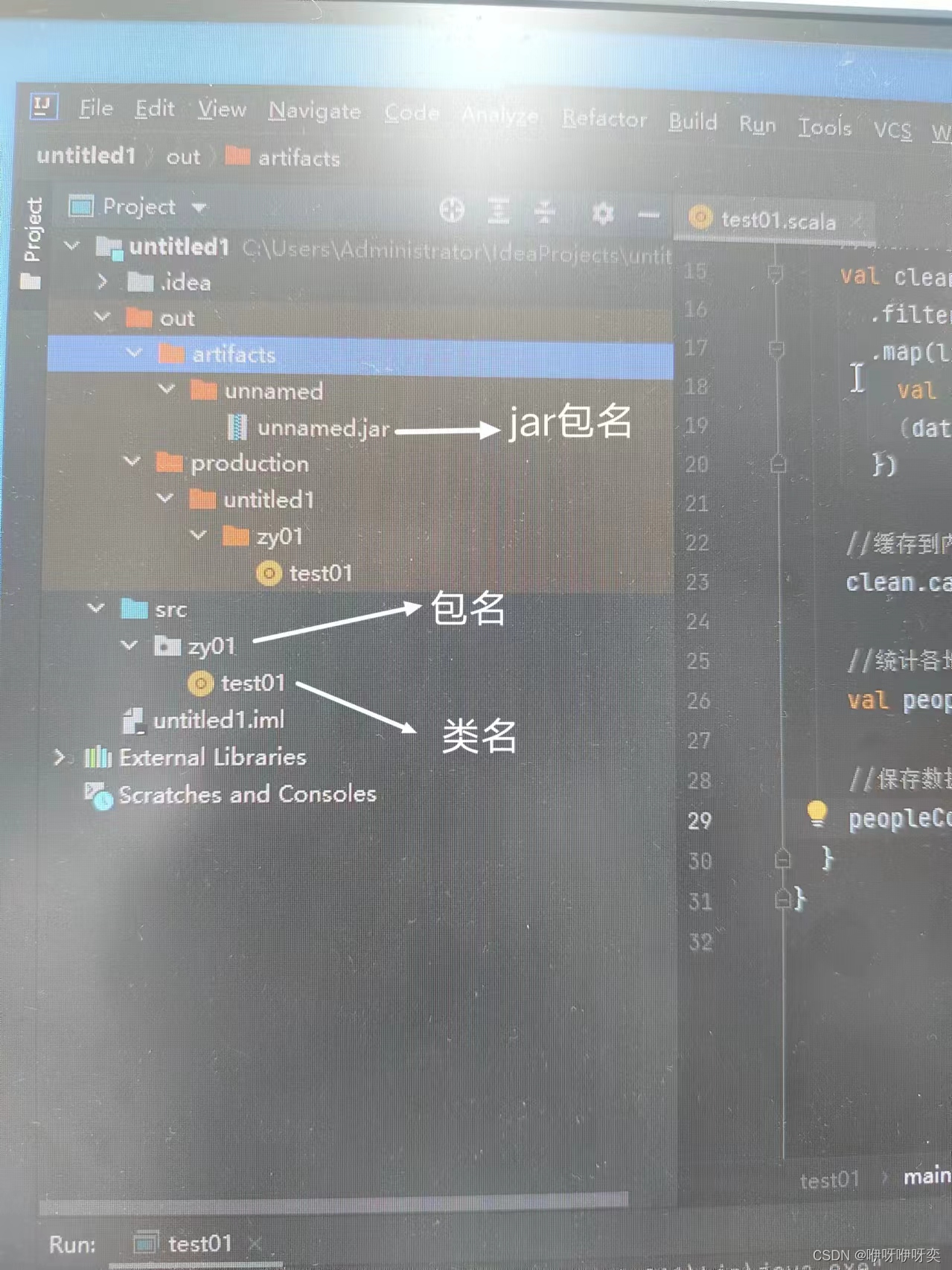
步骤一:在IDEA上写文件
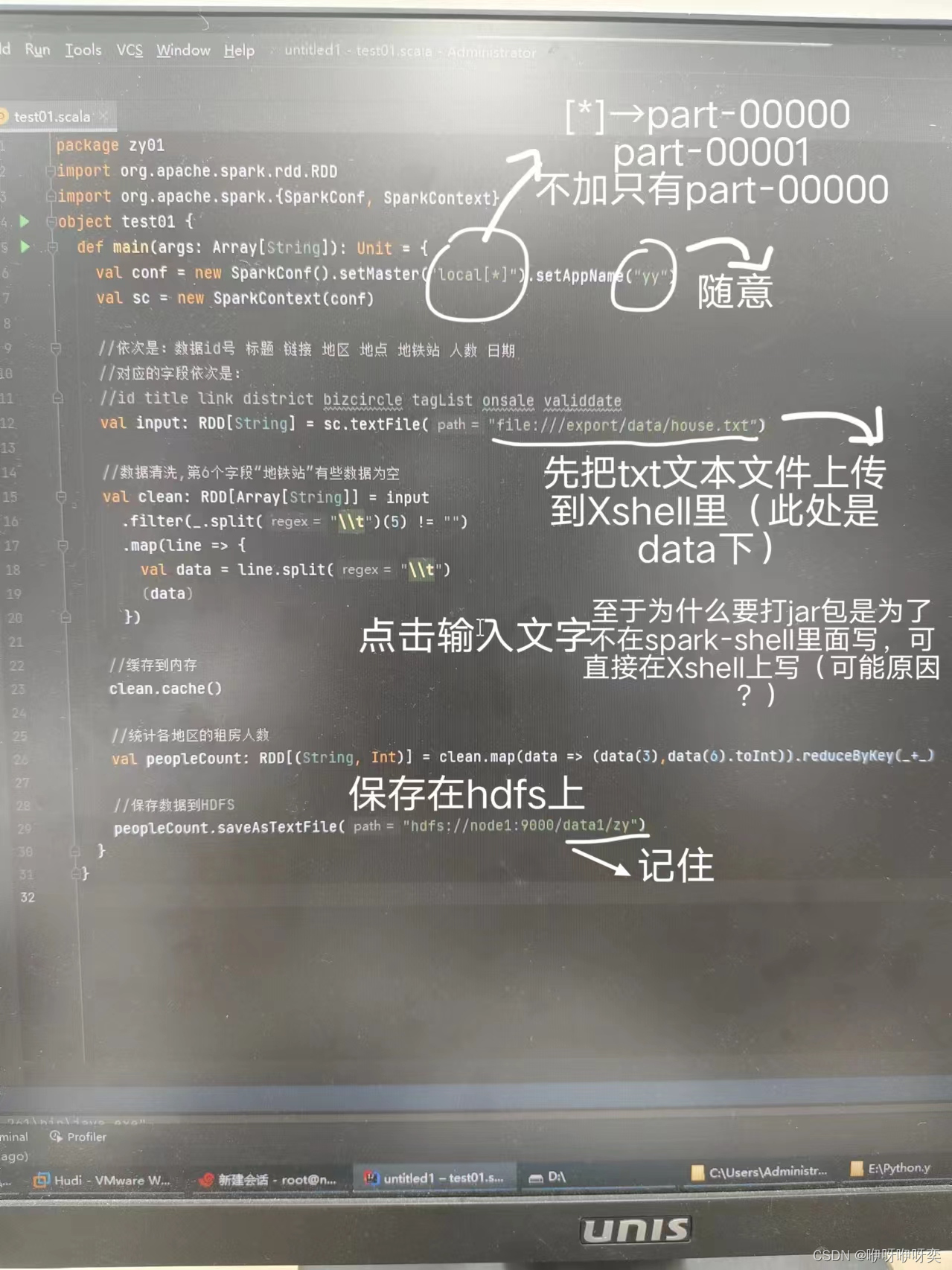
步骤二:点击Project Structure里的Artifacts
(别忘了,关键)
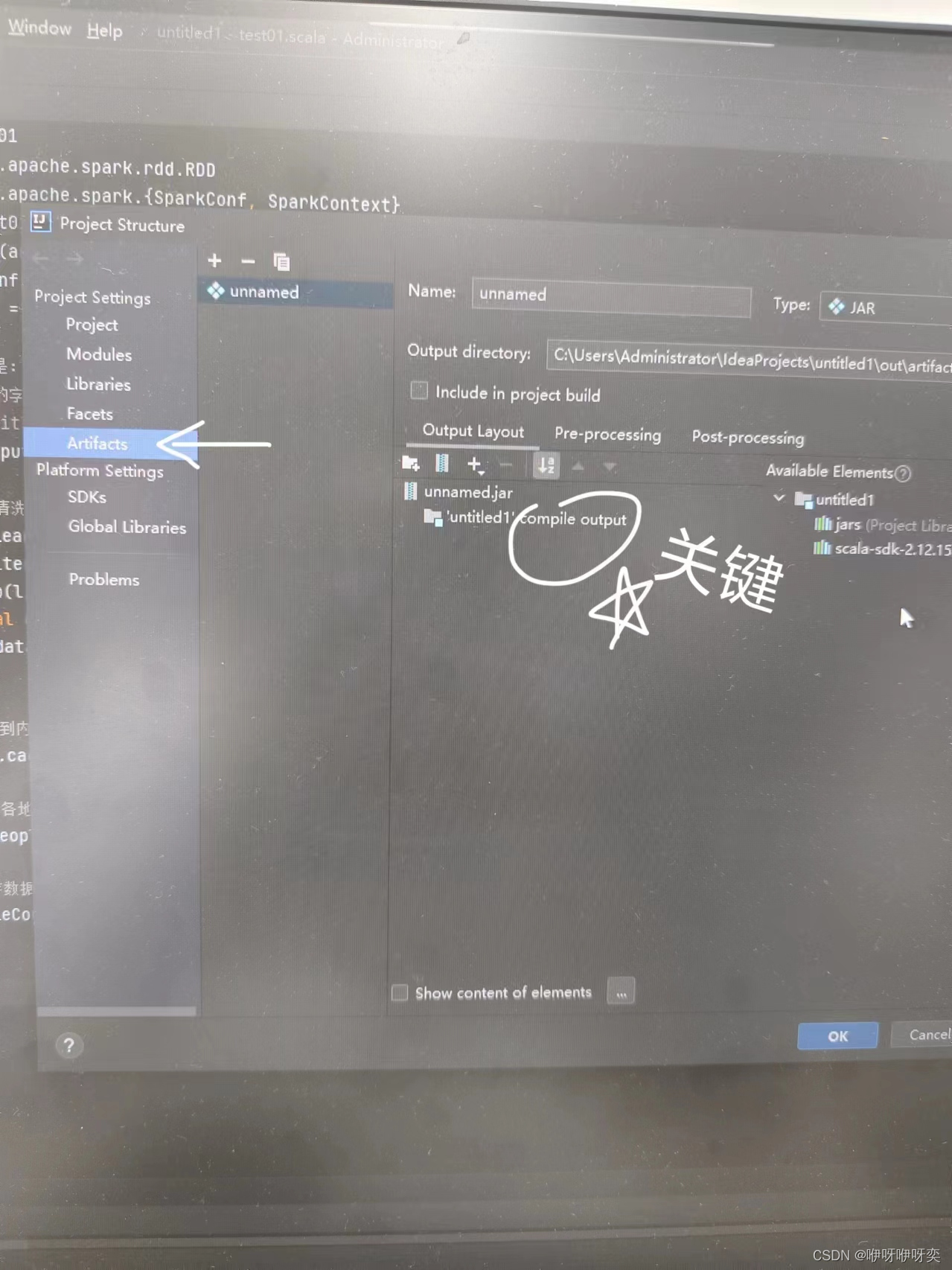
步骤三:点击Build里的Build Artifacts里的unnamed里的Build
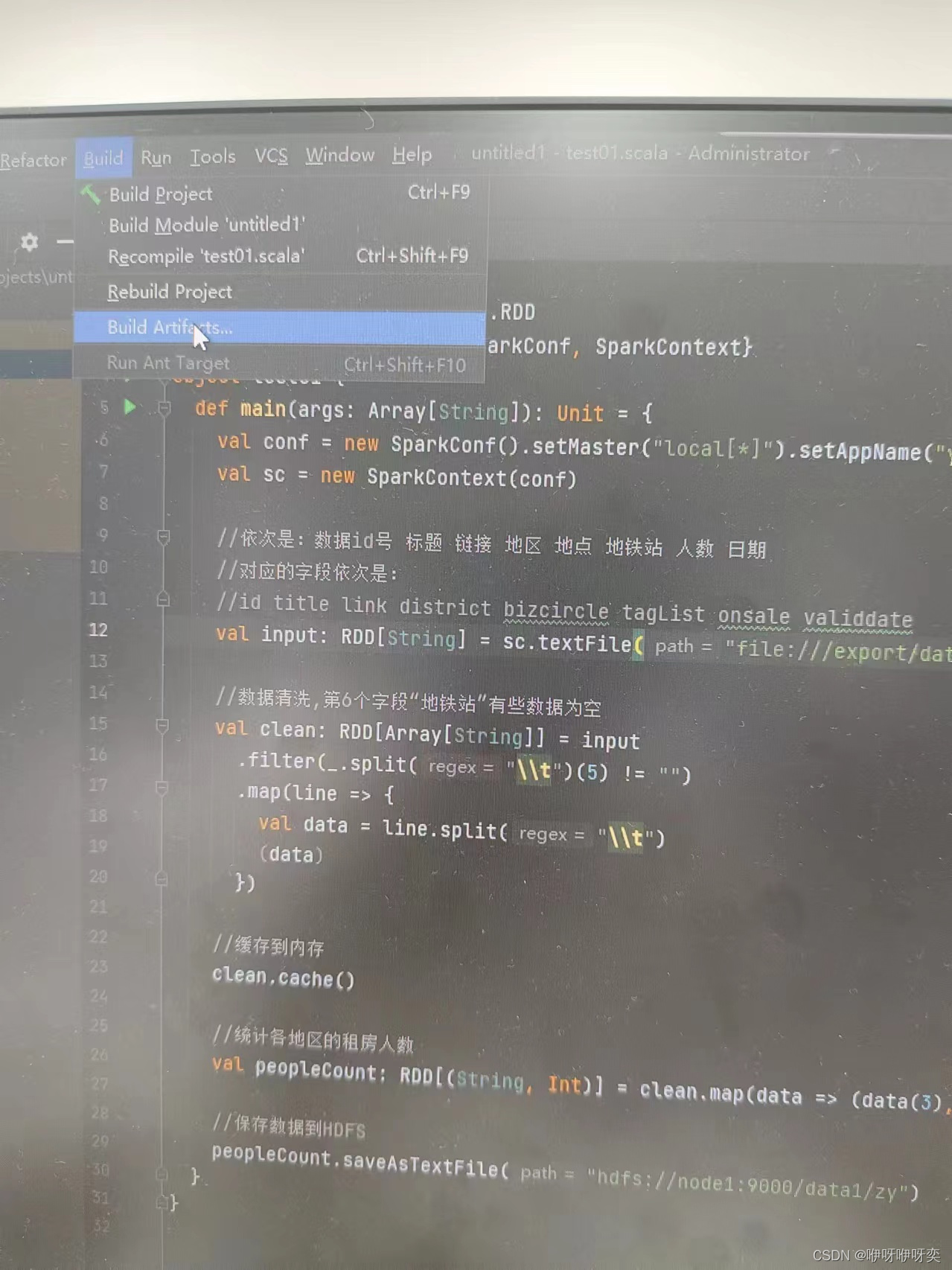
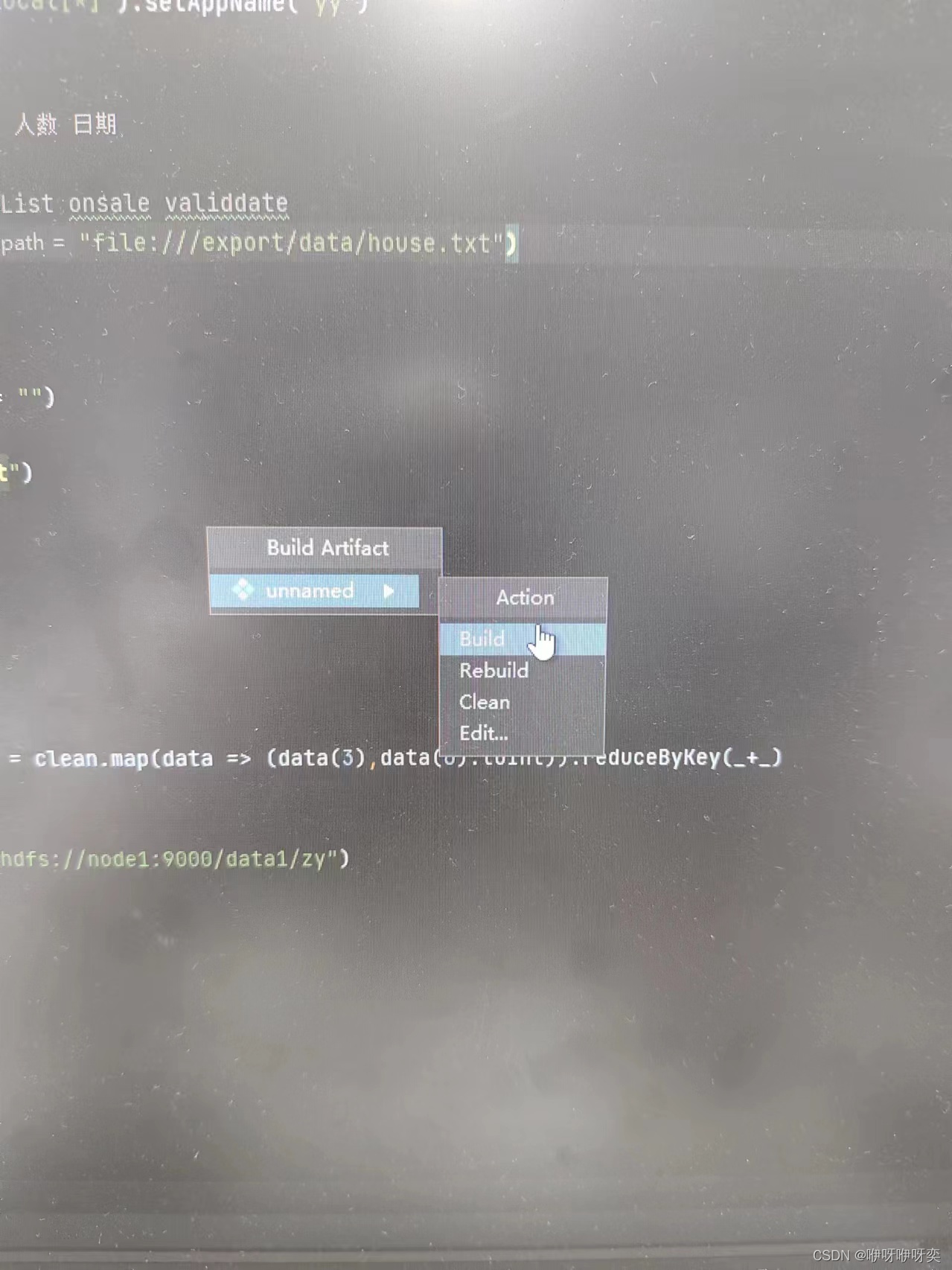
【PS:区分包名,类名,jar包名】
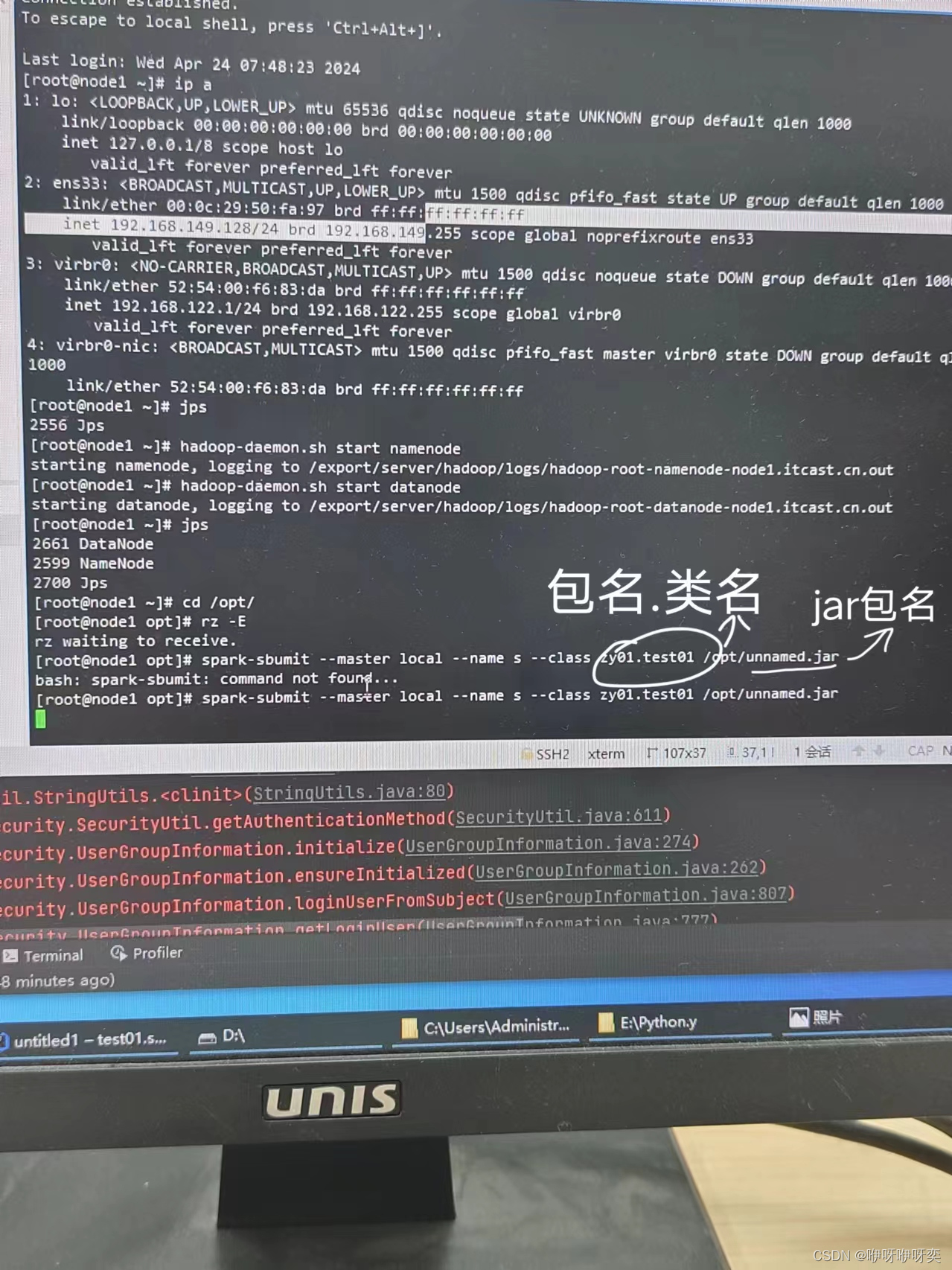
步骤四:把jar包上传到Xshell上
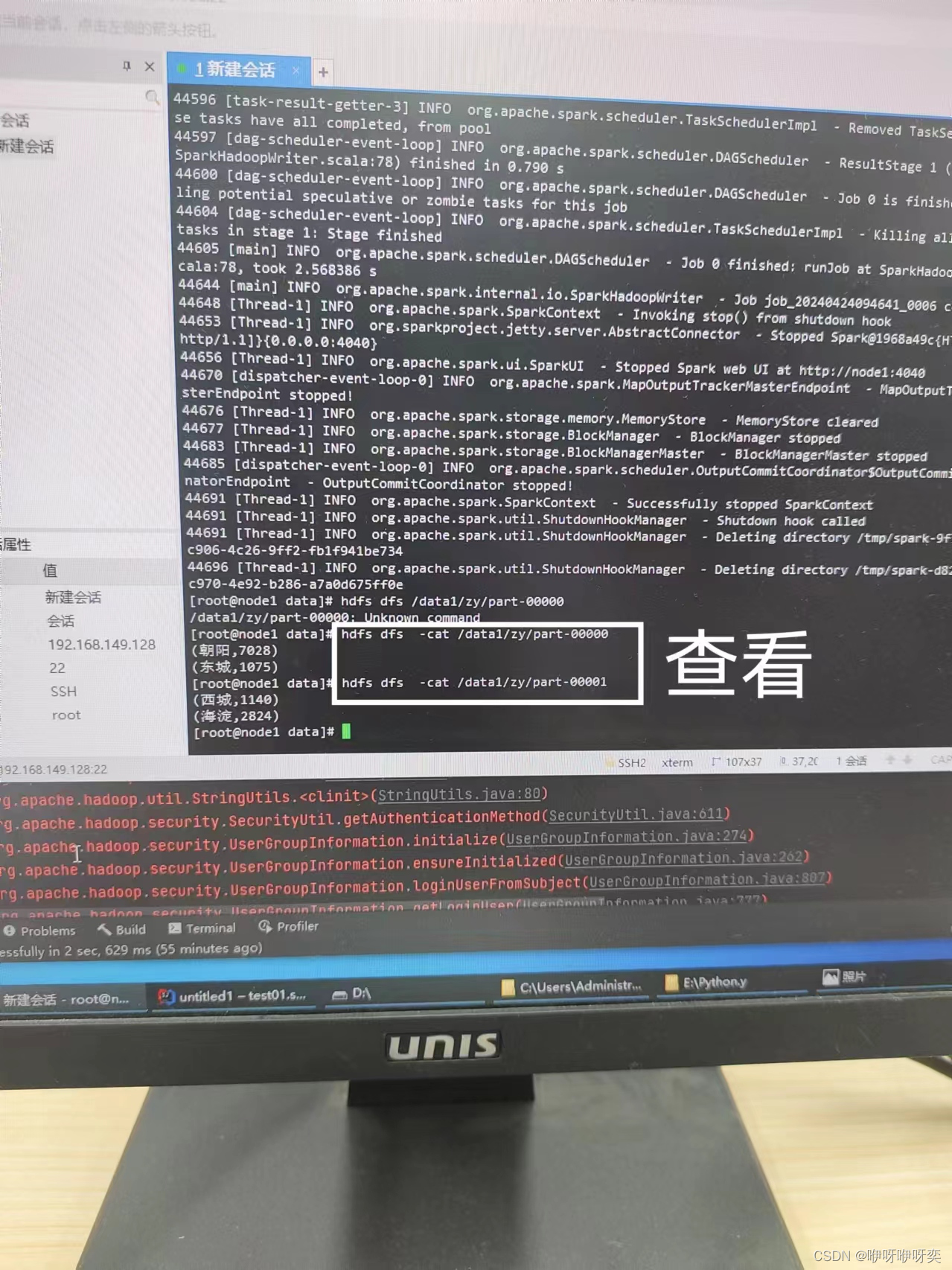
完成后查看即可
方法二:
步骤一:创建maven项目
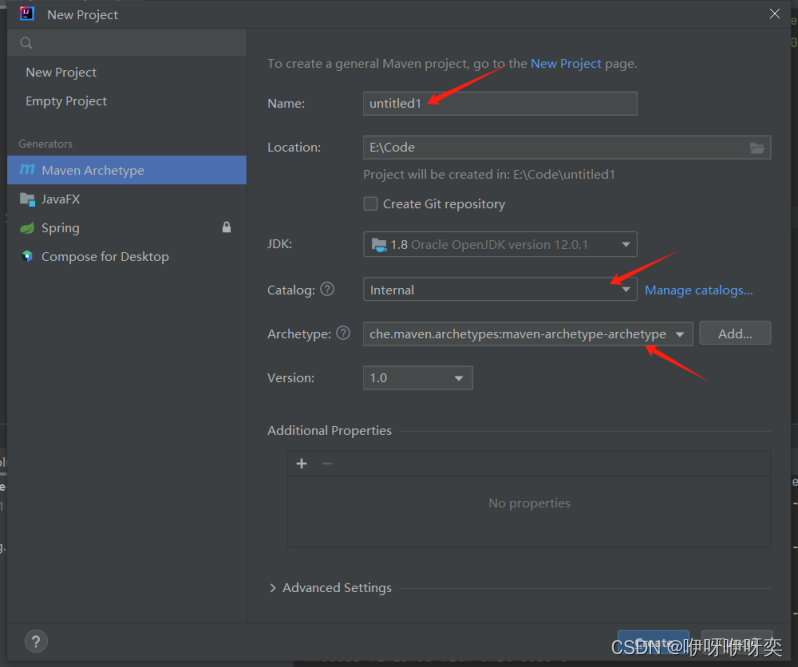
步骤二:配置maven项目
(pom.txt文件已上传,待审核中。。。)
File->setting->
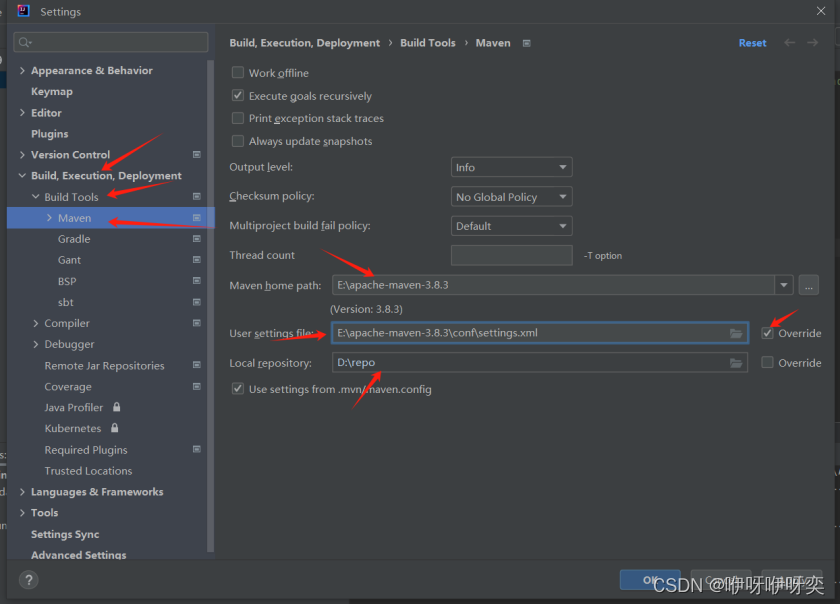
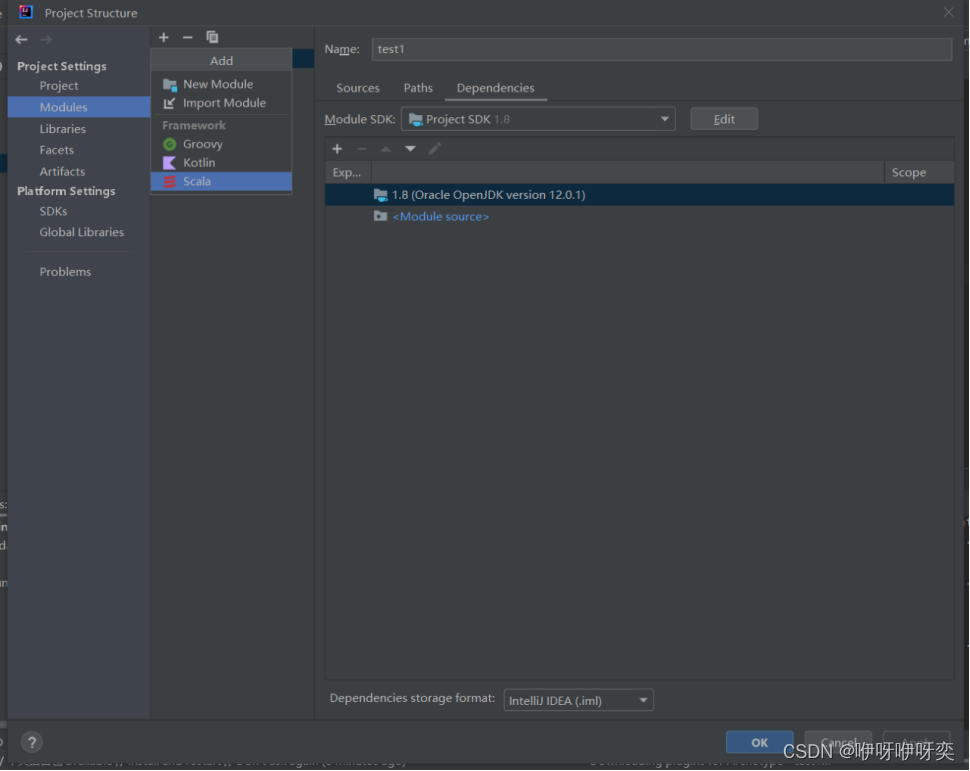
步骤三:路径问题,本地或者集群
步骤四:Spark提交jar包
spark-submit --class com.exmple.Main test1.jarb
最后,让我们来巩固一下近期学习的方法
一、SparkRDD
RDD是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合。
RDD的创建有3种不同的方法:
第一种是将程序中已存在的Seq集合(如集合、列表、数组)转换成RDD。
第二种是对已有RDD进行转换得到新的RDD。
(这两种方法都是通过内存中已有的集合创建RDD的)
第三种是直接读取外部存储系统的数据创建RDD。
创建RDD:
【内部】makeRDD()、parallelize()
【外部】textFile()
显示RDD中的元素(即输出):
rdd.collect().foreach(println)
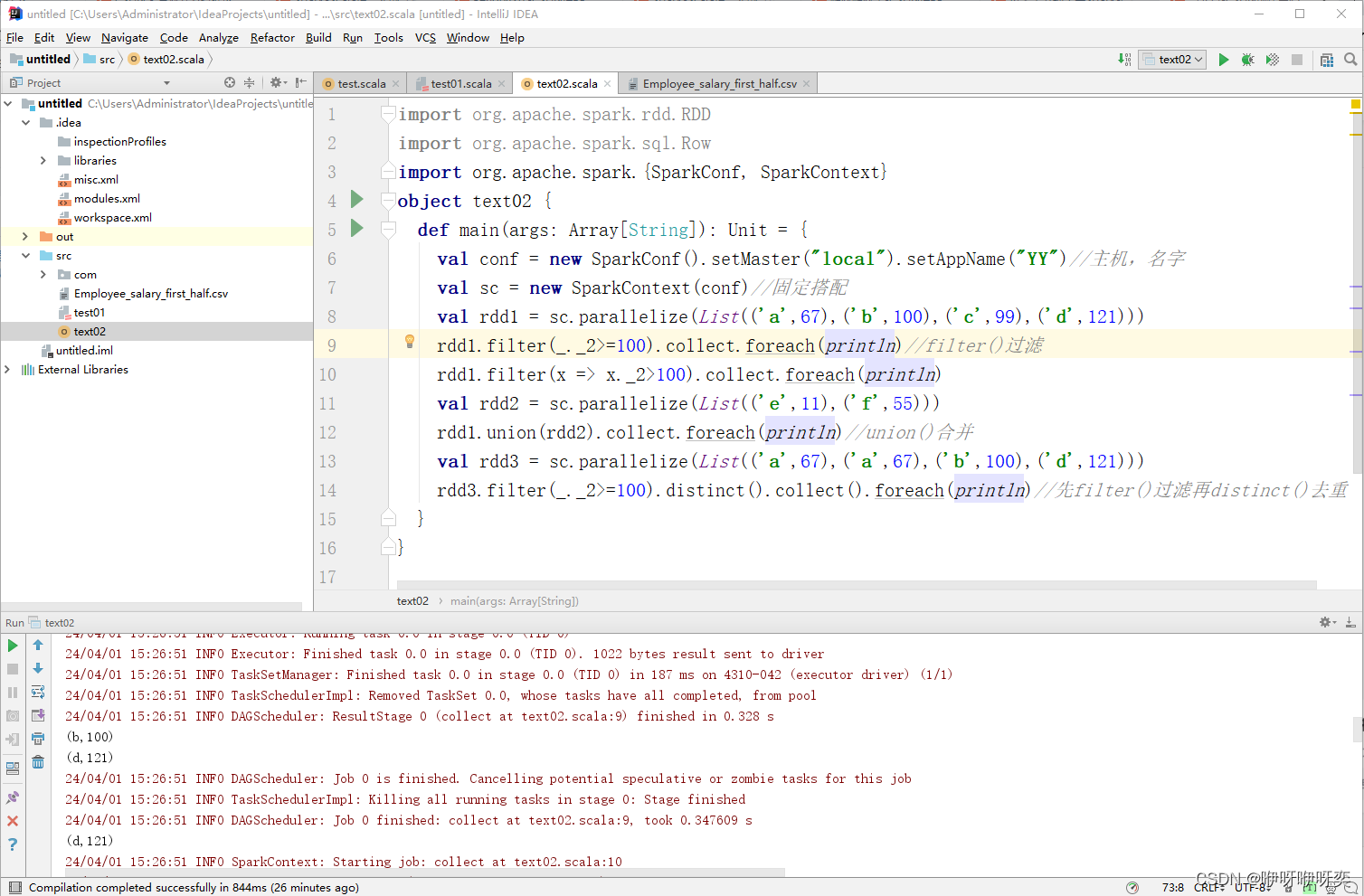
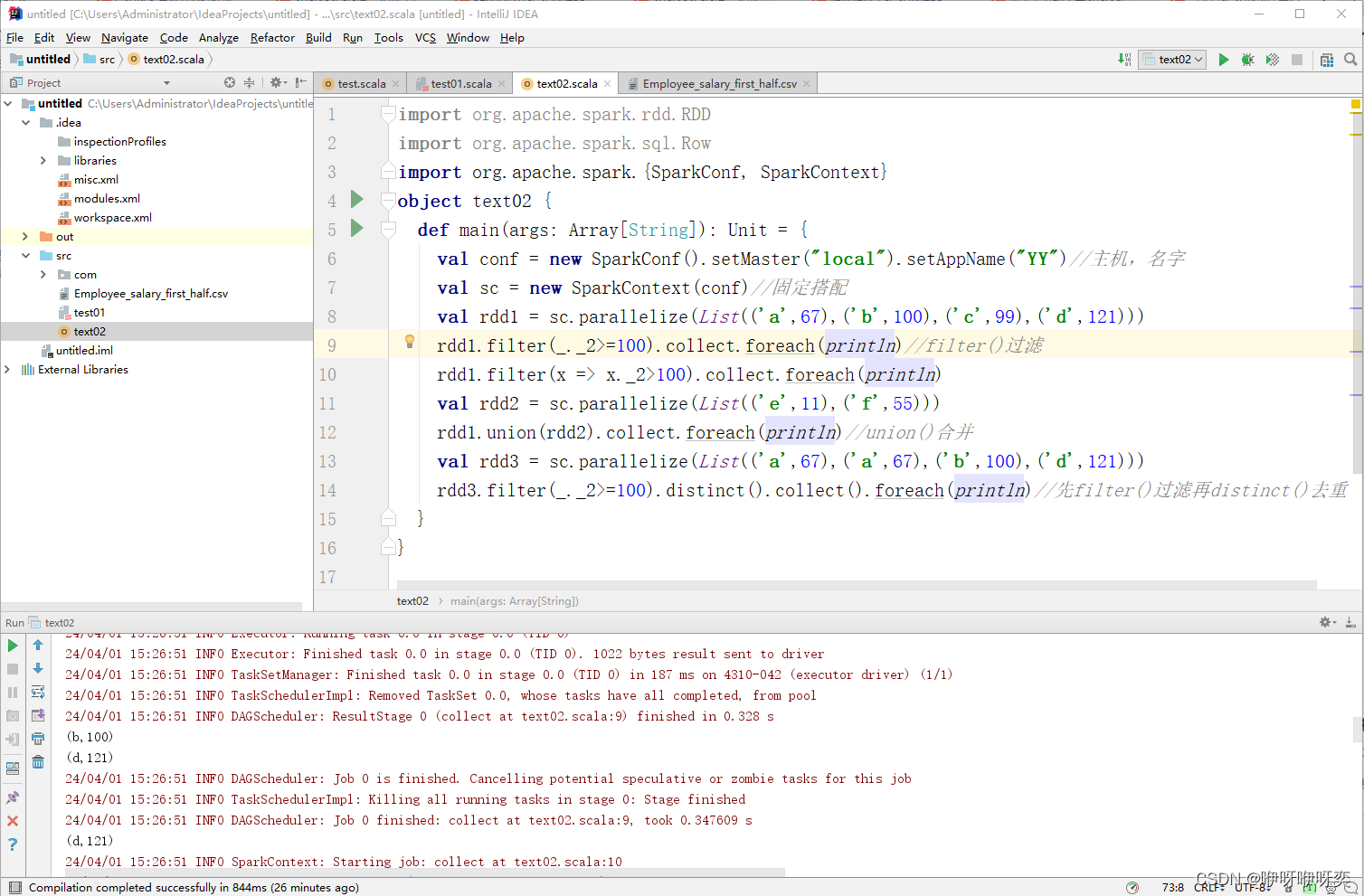
对RDD中的元素进行filter()过滤:
filter()方法是一种转换操作,用于过滤RDD中的元素。
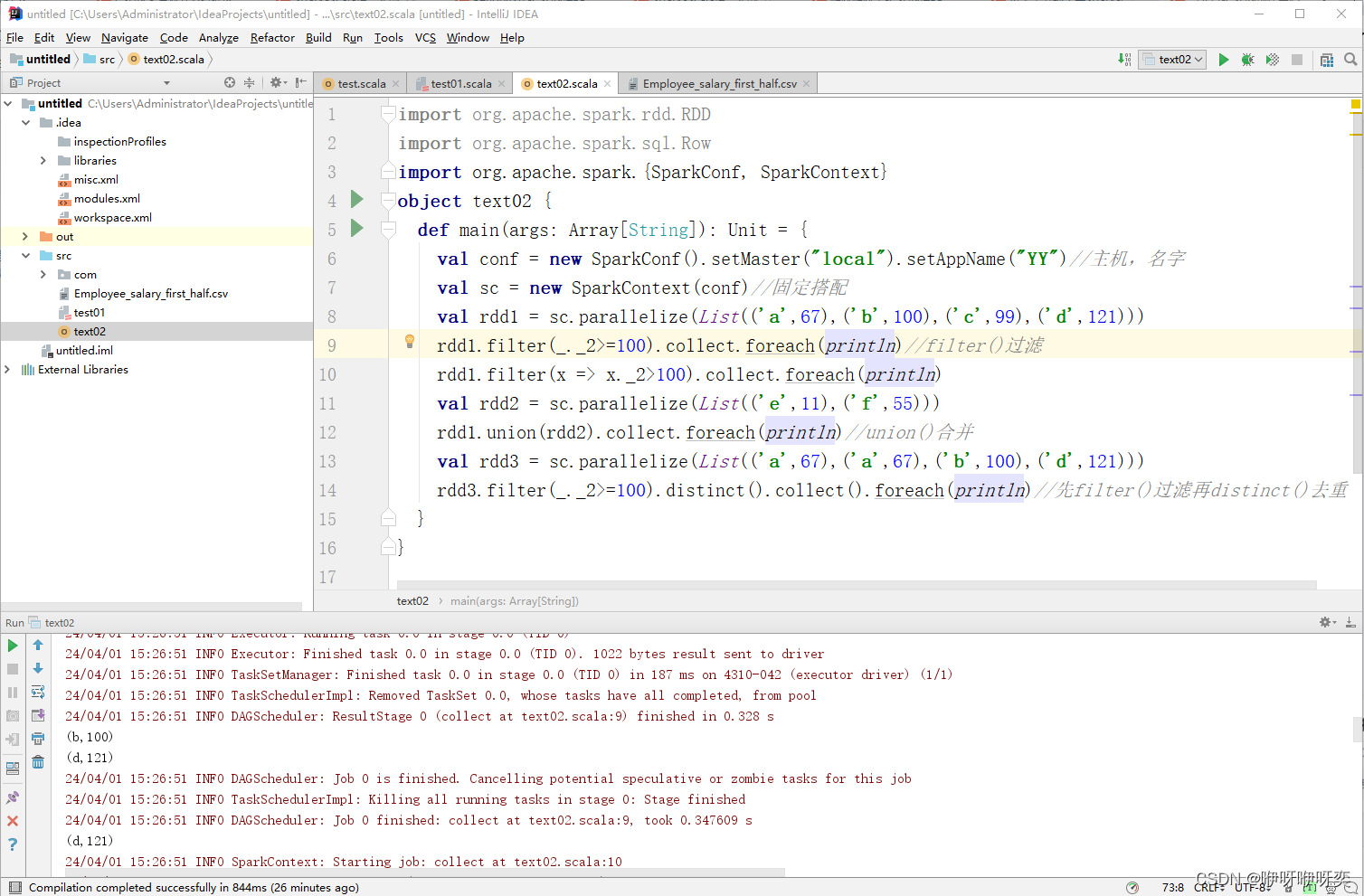
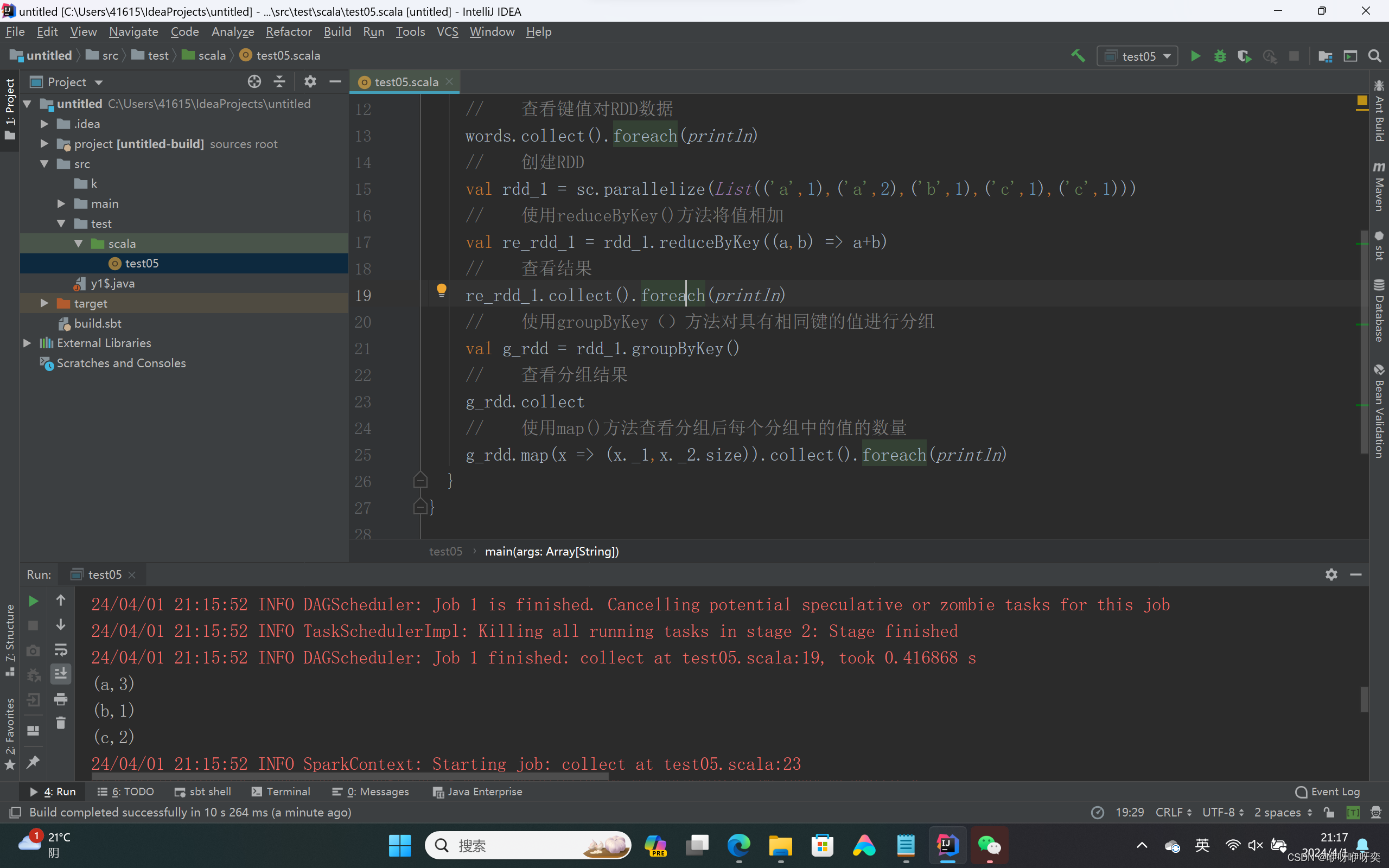
对RDD中的元素进行groupByKey()分组:
groupByKey()方法用于对具有相同键的值进行分组,可以对同一组的数据进行计数、求和等操作
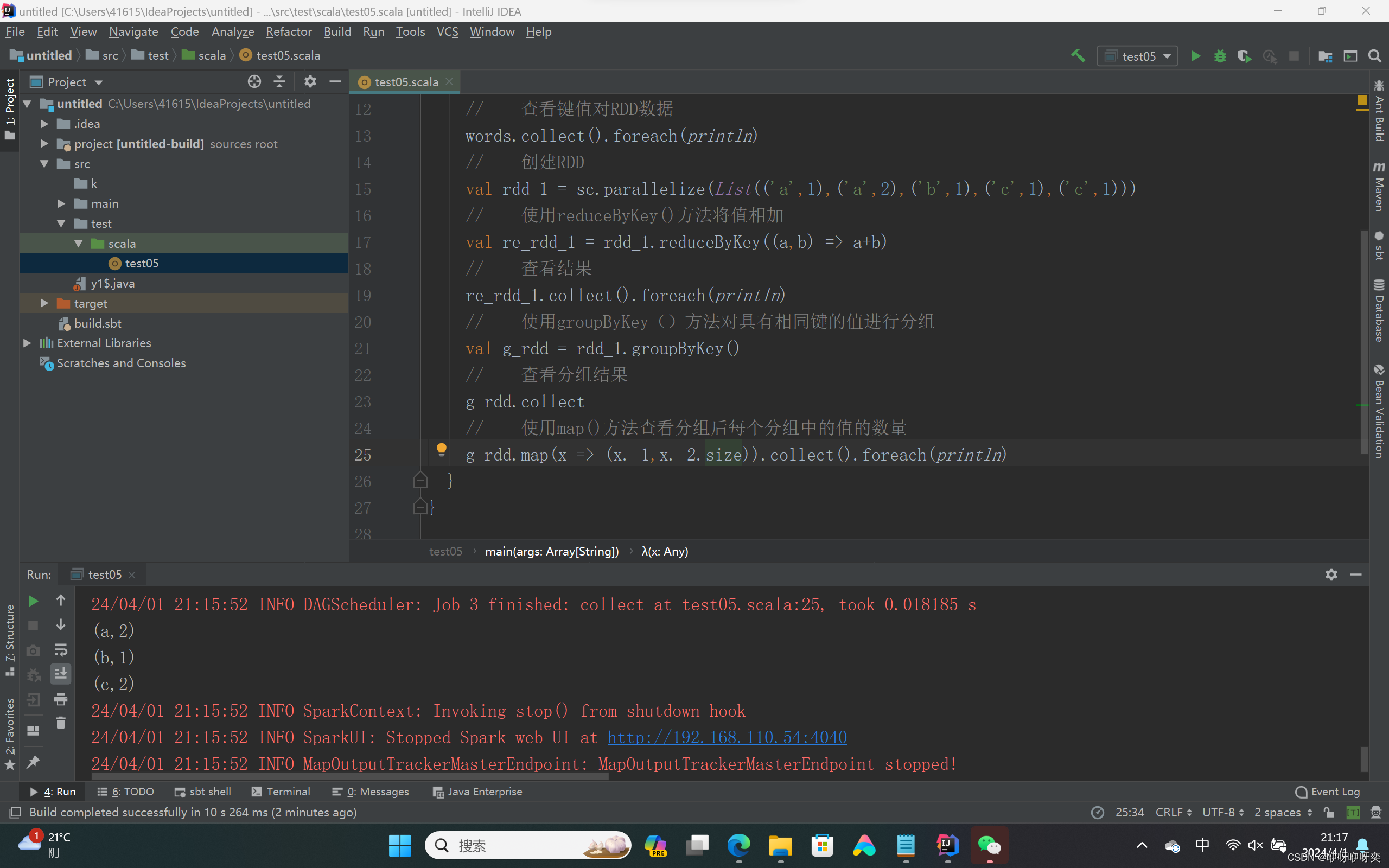
对RDD中的元素进行reduceByKey()合并:
reduceByKey()方法用于合并具有相同键的值,作用对象是键值对,并且只对键的值进行处理。
对RDD中的元素进行union()合并:
union()方法是一种转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的个数、数据类型需要保持一致。
对RDD中的元素进行distinct()去重:
distinct()方法是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,没有参数。
val distinctRDD = rdd.distinct()
对RDD中的元素进行subtract()删除:
subtract()方法用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。
distinct()方法和subtract()方法的区别:
distinct是不同的意思,即RDD中相同的去掉,不同的留下。
subtract是减去的意思,两个RDD求某一RDD的范围内的补集。
对RDD中的元素进行聚合:
val sum = rdd.reduce((x, y) => x + y)
对RDD中的元素进行排序:
val sortedRDD = rdd.sortBy(x => x, ascending = false)
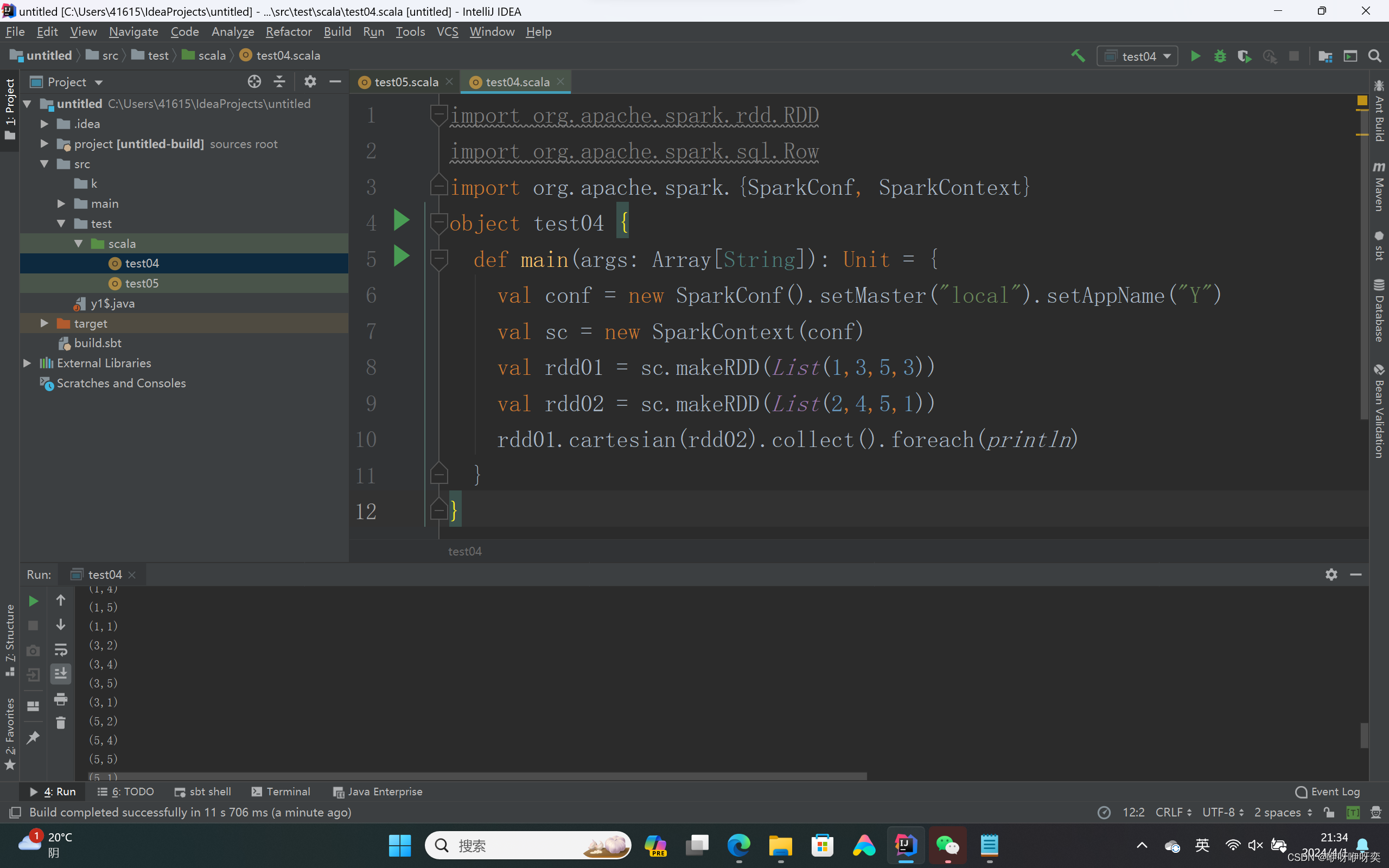
对两个RDD进行笛卡尔积操作:
val cartesianRDD = rdd1.cartesian(rdd2)
使用join()方法连接两个RDD:
对两个RDD进行内连接。
val rdd1 = sc.parallelize(List(('a',1),('b',2),('c',3)))
val rdd2 = sc.parallelize(List(('a',1),('d',4),('e',5)))
val j_rdd = rdd1.join(rdd2)
使用rightOuterJoin()方法连接两个RDD:
对两个RDD进行连接操作,确保第二个RDD的键必须存在(右外连接)。
val right_join = rdd1.rightOuterJoin(rdd2)
使用leftOuterJoin()方法连接两个RDD:
对两个RDD进行连接操作,确保第一个RDD的键必须存在(左外连接)。
val left_join = rdd1.leftOuterJoin(rdd2)
使用fullOuterJoin()方法连接两个RDD:
对两个RDD进行全外连接。
val full_join = rdd1.fullOuterJoin(rdd2)
使用zip()方法组合两个RDD:
zip()方法用于将两个RDD组合成键值对RDD,要求两个RDD的分区数量以及元素数量相同,否则会抛出异常。
var rdd1 = sc.makeRDD(1 to 5,2)
var rdd2 = sc.makeRDD(Seq("A","B","C","D","E"),2)
rdd1.zip(rdd2).collect
rdd2.zip(rdd1).collect
使用take()方法查询某几个值:
take(N)方法用于获取RDD的前N个元素,返回数据为数组。
val data = sc.parallelize(1 to 10)
data.take(5)
计算RDD中元素的数量:
val count = rdd.count()
对RDD中的元素进行缓存:
rdd.cache()
将RDD保存到文件:
rdd.saveAsTextFile("path/to/output")
更详细请参考上一篇文章(都是精华。。。)
二、Spark SQL
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象结构叫做DataFrame的数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrames API和Datasets API三种方式实现对结构化数据的处理。
创建DataFrame的两种基本方式:
已存在的RDD调用toDF()方法转换得到DataFrame。
通过Spark读取数据源直接创建DataFrame。

创建DataFrame:
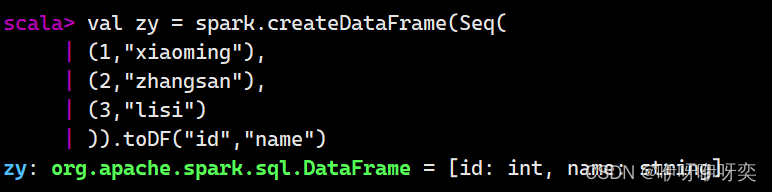
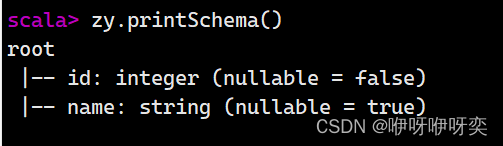
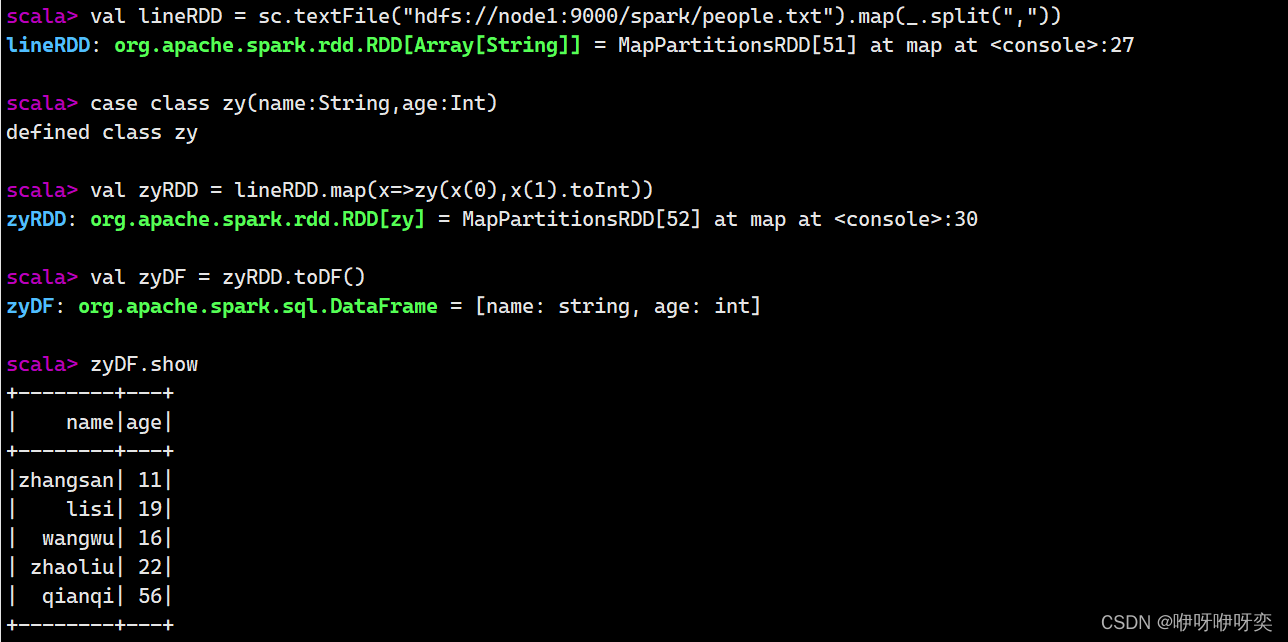
显示DataFrame的结构:
zy.printSchema()
显示DataFrame的内容:
zy.show()

读文件:
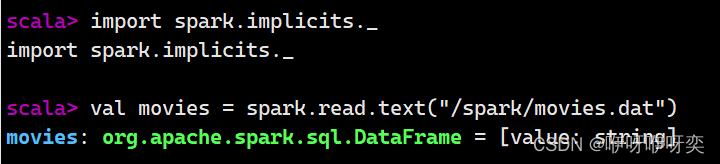
show():显示前20条记录
show(numRows:Int):显示numRows条记录
show(truncate:Boolean):是否最多只显示20个字符,默认为true
show(numRows:Int,truncate:Boolean):显示numRows条记录并设置过长字符串的显示格式
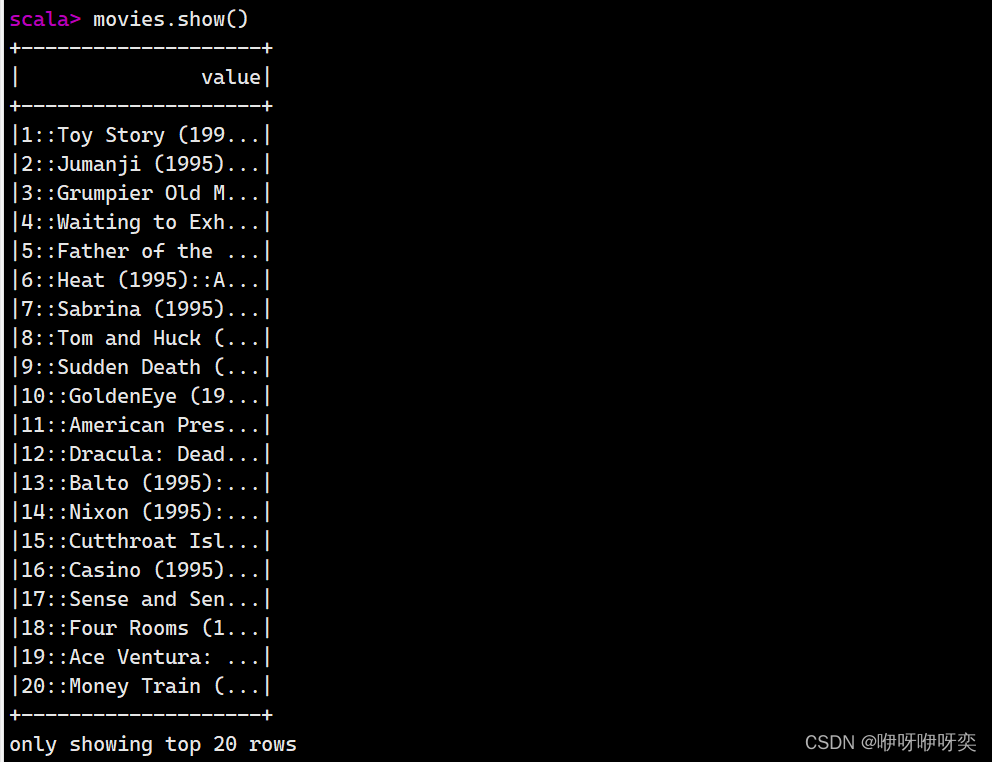
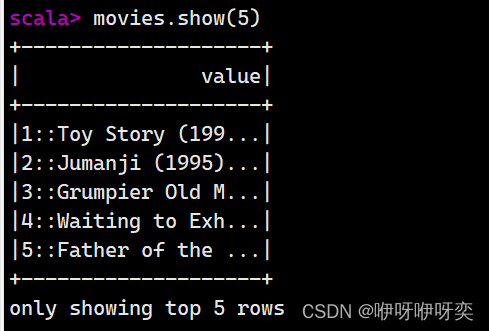
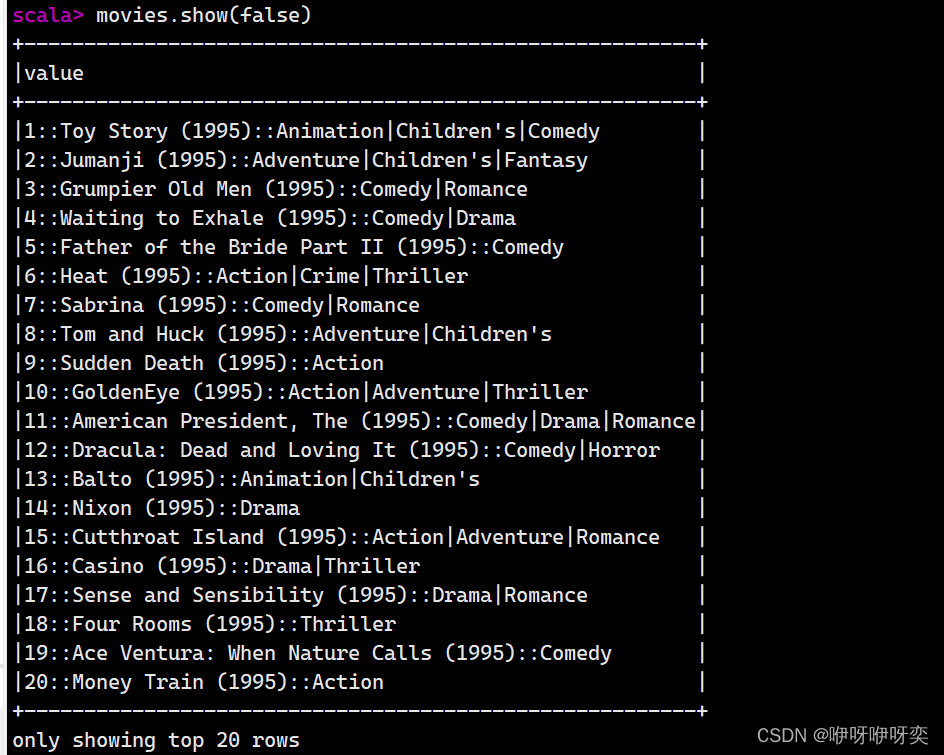
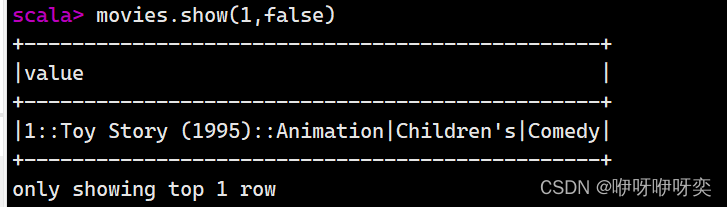
first():获取第一条记录
head(n:Int):获取前n条记录
take(n:Int):获取前n条记录
takeAsList(n:Int):获取前n条记录,并以列表的形式展现




collect()/collectAsList():获取所有数据

 定义样例类zy
定义样例类zy

读取movies.dat数据创建RDD movieData

将movieData转换成DataFrame

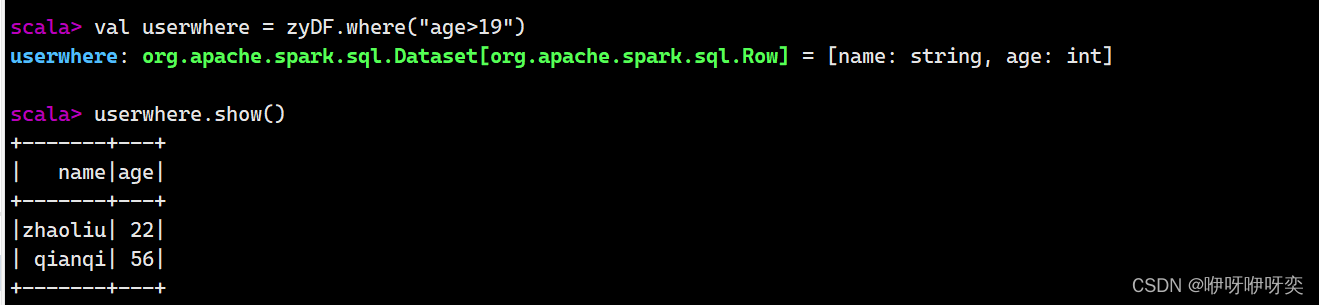
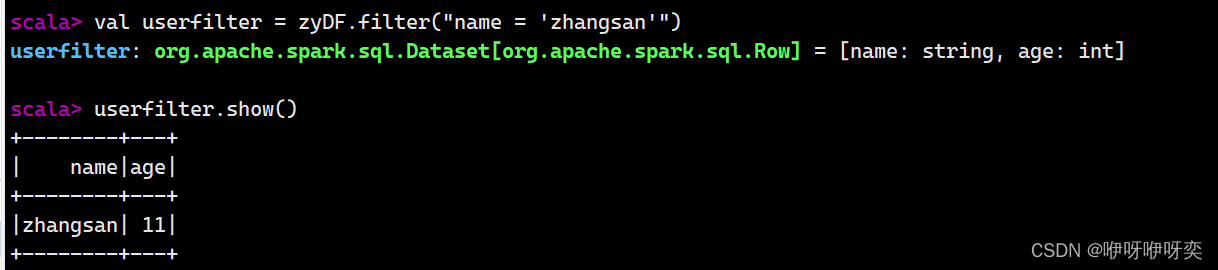
where()/filter():条件查询
select()/selectExpr()/col()/apply():查询指定字段的数据信息
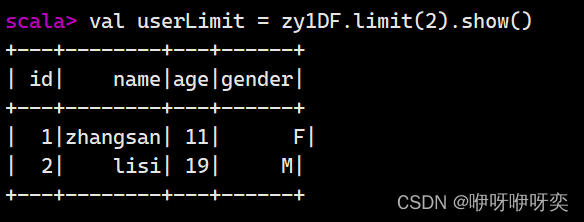
limit():查询前n条记录
order By()/sort():排序查询
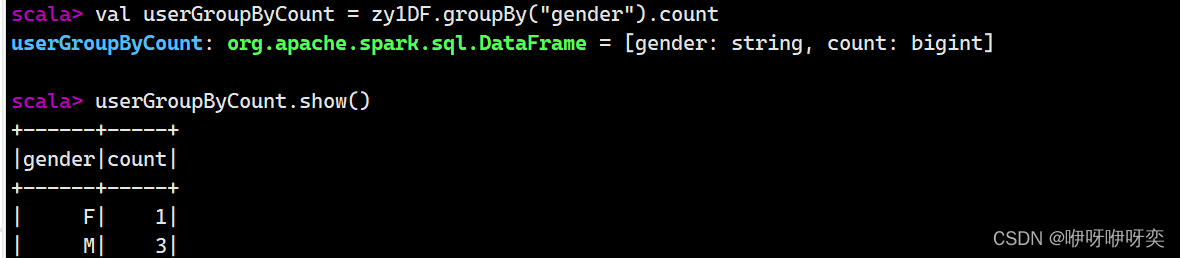
groupBy():分组查询
join():连接查询

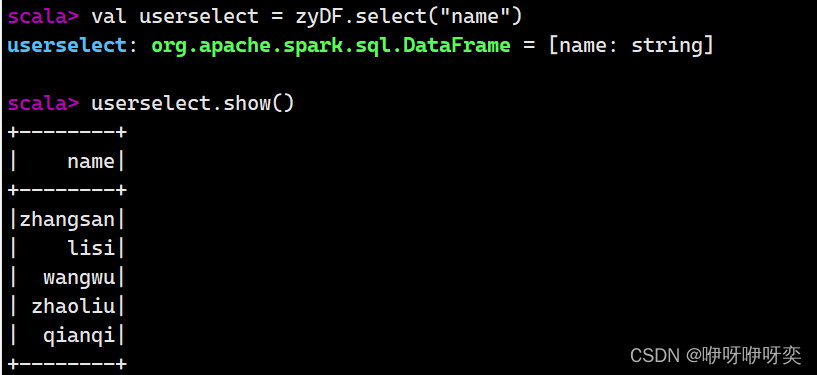
select():获取指定字段值
selectExpr():对指定字段进行特殊处理
- spark.udf.register("replace",(x:String) => {
- x match{
- case "M" => 0
- case "F" => 1
- }
- })
- val userSelectExpr = user.selectExpr(
- "userId","replace(gender) as sex","age")
- userSelectExpr.show(3)
max(colNames:String):获取分组指定字段或所有的数值类型字段的最大值
min(colNames:String):获取分组指定字段或所有的数值类型字段的最小值
mean(colNames:String):获取分组指定字段或所有的数值类型字段的平均值
sum(colNames:String):获取分组指定字段或所有的数值类型字段的值的和
count():获取分组中的元素个数
join(right:DataFrame):返回两个表的笛卡尔积
join(right:DataFrame,joinExprs:Column):根据两表中相同的某个字段进行连接
join(right:DataFrame,joinExprs:Column,joinType:String):根据两表相同的某个字段进行连接并指定连接类型

