
热门标签
热门文章
- 120200922 001_经典算法面试题1——字符串匹配之KMP算法_kmp面试题
- 2基于配置文件 SSM 和 Bootstrap 的熊猫书屋系统_ssm配置bootstrap
- 3ubuntu22.04 DNSSEC(加密DNS服务) configuration_ubuntu 22.04 systemd-resolved
- 4Android 监听网络状态变化(无切换中间态版)
- 5chatgpt赋能python:Python在线模拟器:让编程变得更加轻松_python模拟器
- 6模糊C均值聚类(Fuzzy C-means,FCM)算法(Python3实现)_模糊c均值聚类算法
- 7用git下载代码、切换分支、切换版本_git切换分支下载代码
- 8微软服务器离线补丁工具包,wsus offline update
- 9命令行--git--多次commit如何合并成一个commit_合并commit
- 10鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Image图片组件_鸿蒙 image判断远程图片是否加载完成
当前位置: article > 正文
.net 百度纠偏_大厂开源真香,百度开源的超轻量级OCR工具库强大且实用
作者:知新_RL | 2024-05-19 15:37:00
赞
踩
百度 飞浆 ocr c#

项目名称:PaddleOCR
项目作者:PaddlePaddle
开源许可协议:Apache-2.0
项目地址:https://gitee.com/paddlepaddle/PaddleOCR
项目简介
PaddleOCR 旨在打造一套丰富、领先、且实用的 OCR 工具库,助力使用者训练出更好的模型,并应用落地。
PaddleOCR 是基于飞桨的 OCR 工具库,包含总模型仅8.6M的超轻量级中文 OCR,单模型支持中英文数字组合识别、竖排文本识别、长文本识别。同时支持多种文本检测、文本识别的训练算法。
项目特性
- 超轻量级中文OCR模型,总模型仅8.6M
- 单模型支持中英文数字组合识别、竖排文本识别、长文本识别
- 检测模型DB(4.1M)+识别模型CRNN(4.5M)
- 使用通用中文OCR模型
- 多种预测推理部署方案,包括服务部署和端侧部署
- 多种文本检测训练算法,EAST、DB
- 多种文本识别训练算法,Rosetta、CRNN、STAR-Net、RARE
- 可运行于Linux、Windows、MacOS等多种系统
效果展示



算法介绍
1.文本检测算法
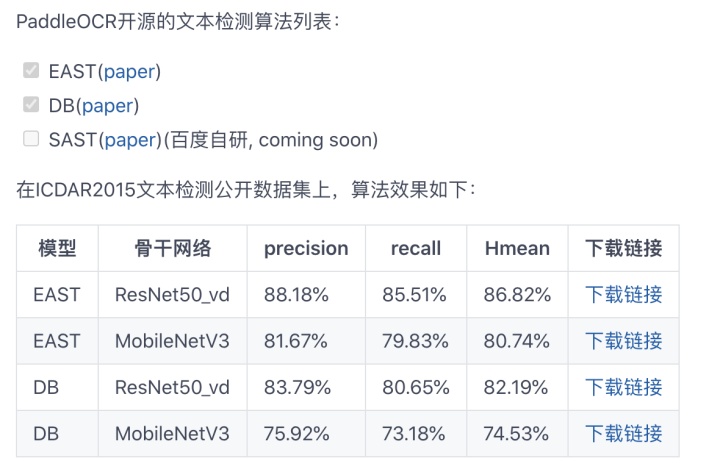
2.文本识别算法
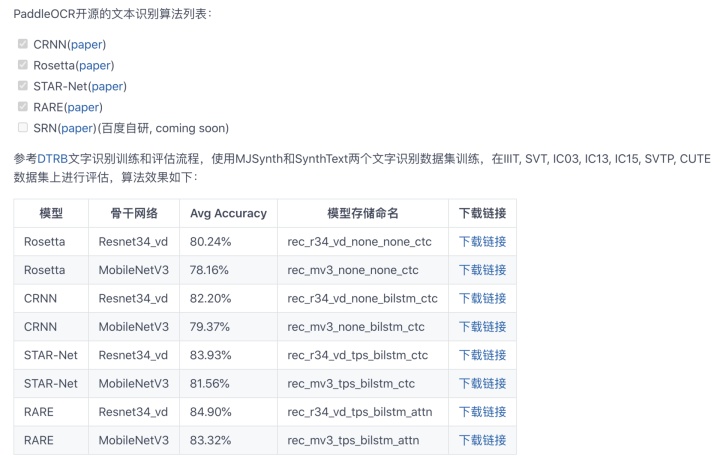
3.端到端 OCR 算法
数据集
PaddleOCR 还为开发者们提供了多种数据集和工具供大家选择使用
- 通用中英文OCR数据集
- 手写中文OCR数据集
- 垂类多语言OCR数据集
- 常用数据标注工具
- 常用数据合成工具
有一说一,这次百度开源的这款 OCR 工具集确实非常不错,如果你对它也感兴趣,想要了解更多信息的话,那么就点击后面的链接前往项目主页看看吧:https://gitee.com/paddlepaddle/PaddleOCR
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/593550
推荐阅读
相关标签

