
- 1Java 开源中文分词器Ansj 学习教程_ansj分词依赖
- 2卡尔曼滤波获取MPU6050欧拉角_卡尔曼滤波mpu6050角度
- 3【HarmonyOS 4.0 应用开发实战】如何配置环境、创建并运行项目_鸿蒙设备开发环境配置教程
- 4php使用curl库进行ssl双向认证_curl 库 sslkeytype der
- 5Java 5个开源免费的项目_=开源 java项目
- 6设计模式在项目中的应用场景_项目中哪里用到设计模式
- 7Python爬虫入门教程30:爬取拉勾网招聘数据信息,Python校招面试指南_招聘网站 爬虫
- 806|ChatGPT来了,让我们快速做个AI应用_gr.chatbot() 复制
- 9SpringBoot整合MyBatis-Plus
- 10彻底禁止postman更新_postman 禁用更新 hosts 配置
使用自有数据集微调ChatGLM2-6B_chatglm微调自己的数据集
赞
踩
1 ChatGLM2-6B介绍
ChatGLM是清华技术成果转化的公司智谱AI研发的支持中英双语的对话机器人。ChatGLM基于GLM130B千亿基础模型训练,它具备多领域知识、代码能力、常识推理及运用能力;支持与用户通过自然语言对话进行交互,处理多种自然语言任务。比如:对话聊天、智能问答、创作文章、创作剧本、事件抽取、生成代码等等。
代码地址:https://github.com/THUDM/ChatGLM2-6B

1.1 ChatGLM诞生
2022年8月,清华背景的智谱AI基于GLM框架,正式推出拥有1300亿参数的中英双语稠密模型 GLM-130B(论文地址、代码地址,论文解读之一,GLM-130B is trained on a cluster of 96 DGX-A100 GPU (8×40G) servers with a 60-day,可以较好的支持2048个token的上下文窗口)
其在一些任务上的表现优于GPT3-175B,是国内与2020年5月的GPT3在综合能力上差不多的模型之一(即便放到23年年初也并不多),这是它的一些重要特点

1.2 ChatGLM2-6B介绍
ChatGLM2-6B是第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,又增加许多新特性:
-
更强大的性能:基于ChatGLM初代模型的开发经验,全面升级了ChatGLM2-6B的基座模型。ChatGLM2-6B使用了GLM的混合目标函数,经过了1.4T中英标识符的预训练与人类偏好对齐训练。评测结果显示,与初代模型相比,ChatGLM2-6B在MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
-
更长的上下文:基于 FlashAttention 技术,研究人员将基座模型的上下文长度由 ChatGLM-6B 的2K扩展到了32K,并在对话阶段使用8K的上下文长度训练,允许更多轮次的对话。但当前版本的ChatGLM2-6B对单轮超长文档的理解能力有限,会在后续迭代升级中着重进行优化。
-
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B有更高效的推理速度和更低的显存占用。在官方的模型实现下,推理速度相比初代提升了42%,INT4量化下,6G显存支持的对话长度由1K提升到了8K。
-
更开放的协议:ChatGLM2-6B权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。
相比于初代模型,ChatGLM2-6B在数理逻辑、知识推理、长文档理解等多个维度的能力上,都取得了巨大的提升。
2 P-Tuning V2介绍
论文地址:https://arxiv.org/pdf/2110.07602.pdf
代码地址:https://github.com/THUDM/P-tuning-v2
2.1 背景
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
第一,缺乏模型参数规模和任务通用性。
-
缺乏规模通用性:Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。
-
缺乏任务普遍性:尽管Prompt Tuning和P-tuning在一些 NLU 基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
第二,缺少深度提示优化,在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。
- 由于序列长度的限制,可调参数的数量是有限的。
- 输入embedding对模型预测只有相对间接的影响。
考虑到这些问题,作者提出了Ptuning v2,它利用深度提示优化(如:Prefix Tuning),对Prompt Tuning和P-Tuning进行改进,作为一个跨规模和NLU任务的通用解决方案。
P-Tuning v2是对prefix-tuning和p-tuning进行的优化。prefix-tuning等存在一些问题:
- 是针对于生成任务而言的,不能处理困难的序列标注任务、抽取式问答等,缺乏普遍性。【解决方法,分类还是使用CLS或者token。】
- 当模型规模较小,特别是小于100亿个参数时,它仍然不如微调法。【解决方法:在每一层都加上prompt。】
2.2 技术原理
P-Tuning v2是一个用于改进预训练语言模型(Pre-trained Language Model,PLM)偏见的方法。其原理可以总结如下:
-
样本选择:首先,从一个大规模的文本语料库中选择一部分样本作为训练集。这些样本应当具有多样性,包括不同的文化、背景和价值观。
-
PLM预训练:在选定的样本上进行预训练,生成一个初始的PLM模型。这个模型包含了很多词语的上下文信息,以及它们之间的关联性。
-
特征定义:定义一个特征函数,用来指示某个词对于特定偏见的敏感程度。这些特征函数可以包括词语的含义、出现上下文的频次等等。
-
偏见调整:通过修改样本中某些词语的上下文,缩小其与偏见之间的相关性。具体来说,对于某个特定的偏见,可以通过修改相关的样本以降低这个偏见对PLM的影响。
-
约束优化:为了控制偏见调整的程度,引入一个约束函数来度量样本的平衡性。这个约束函数可以包括不同群体的样本分布、词语的多样性等等。
-
迭代训练:在约束优化的框架下,反复调整样本和PLM模型,直到达到平衡的状态。这样可以在尽量保持语言模型质量的同时,尽量减小偏见。
P-Tuning v2的原理是通过定义特征函数和约束函数,以及调整样本和PLM模型的方法,来优化预训练语言模型的偏见问题。这个方法可以用于改进PLM的性别、种族、政治观点等各种偏见。
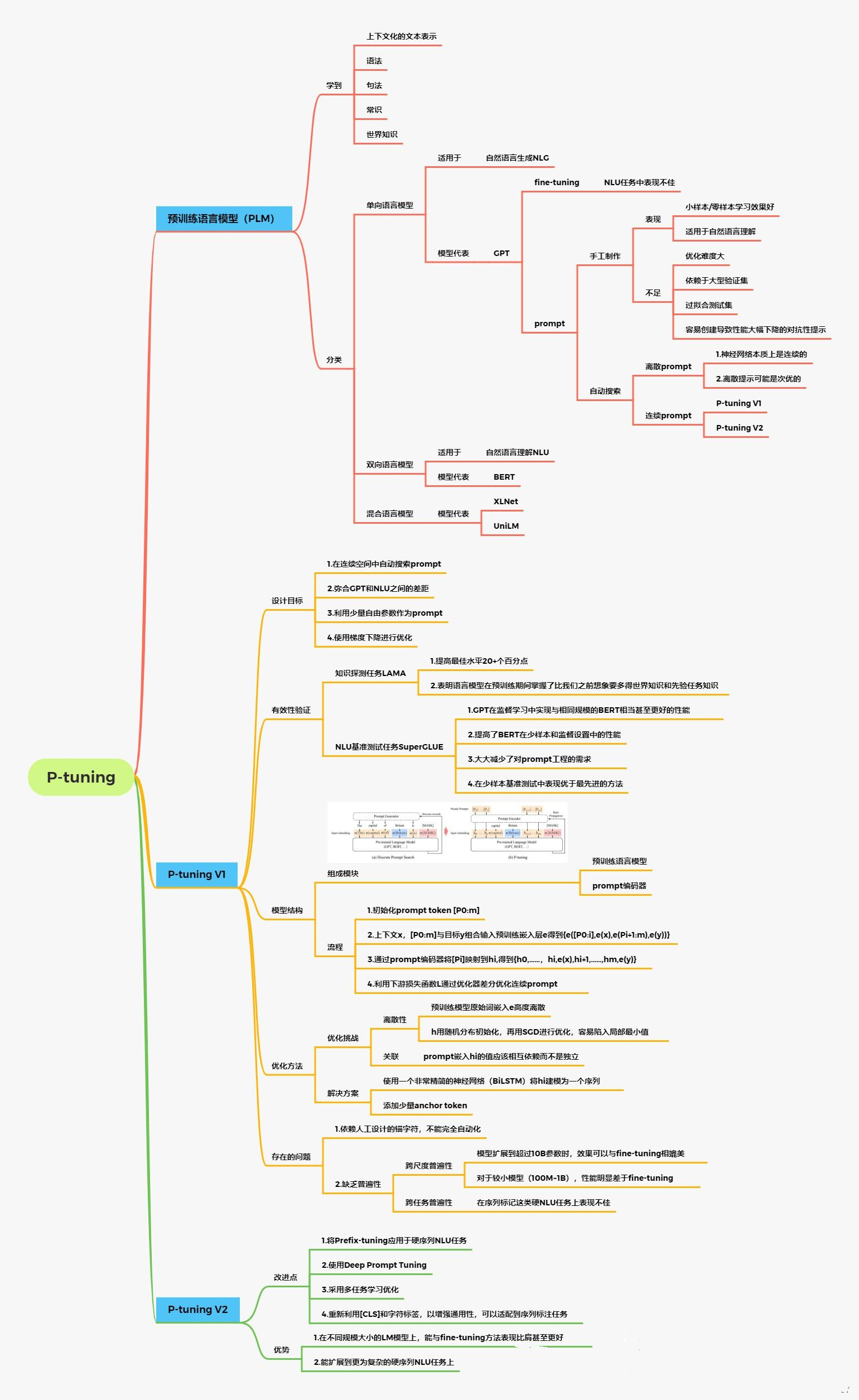
2.3 P-Tuning v2的优点
-
P-tuning v2在不同的模型规模(从300M到100B的参数)和各种困难的NLU任务(如问答和序列标注)上的表现与微调相匹配。
-
与微调相比,P-tuning v2每个任务的可训练参数为0.1%到3%,这大大降低了训练时间的内存消耗和每个任务的存储成本
官方的P-Tuning v2 与Lora微调笔记:
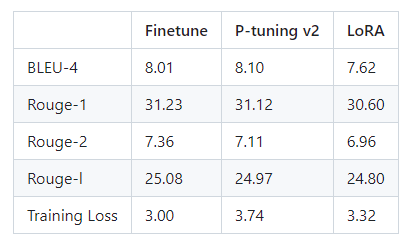
看上去效果顺位:Fineture > P-tuning V2 > loRA
P-Tuning v2提升小模型上的Prompt Tuning,最关键的就是引入Prefix-tuning[2]技术。
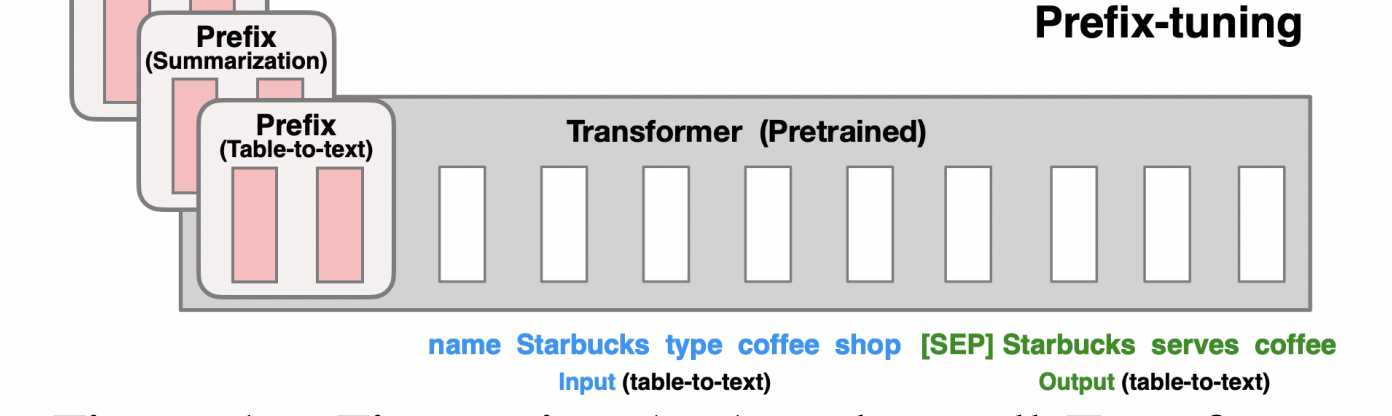
Prefix-tuning(前缀微调)最开始应用在NLG任务上,由[Prefix, x, y]三部分构成,如上图所示:Prefix为前缀,x为输入,y为输出。Prefix-tuning将预训练参数固定,Prefix参数进行微调:不仅只在embedding上进行微调,也在TransFormer上的embedding输入每一层进行微调。
P-Tuning v2将Prefix-tuning应用于在NLU任务,如下图所示:

那么,P-tuning v2哪些参数需要训练?
P-tuning v2在实际上就是Prefix-tuning,在Prefix部分,每一层transformer的embedding输入需要被tuned。而P-tuning v1只有transformer第一层的embedding输入需要被tuned。
假设Prefix部分由50个token组成,则P-tuning v2共有 50X12=600个参数需要tuned。
在Prefix部分,每一层transformer的输入不是从上一层输出,而是随机初始化的embedding(需要tuned)作为输入。
此外,P-Tuning v2还包括以下改进:
- 移除了Reparamerization加速训练方式;
- 采用了多任务学习优化:基于多任务数据集的Prompt进行预训练,然后再适配的下游任务。
- 舍弃了词汇Mapping的Verbalizer的使用,重新利用[CLS]和字符标签,跟传统finetune一样利用cls或者token的输出做NLU,以增强通用性,可以适配到序列标注任务。
P-Tuning v2的原理是通过对已训练好的大型语言模型进行参数剪枝,得到一个更加小巧、效率更高的轻量级模型。具体地,P-Tuning v2首先使用一种自适应的剪枝策略,对大型语言模型中的参数进行裁剪,去除其中不必要的冗余参数。然后,对于被剪枝的参数,P-Tuning v2使用了一种特殊的压缩方法,能够更加有效地压缩参数大小,并显著减少模型微调的总参数量。
总的来说,P-Tuning v2的核心思想是让模型变得更加轻便、更加高效,同时尽可能地保持模型的性能不受影响。这不仅可以加快模型的训练和推理速度,还可以减少模型在使用过程中的内存和计算资源消耗,让模型更适用于各种实际应用场景中。
- from transformers import AutoConfig, AutoModel, AutoTokenizer
-
- # 载入Tokenizer
- tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
-
- config = AutoConfig.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, pre_seq_len=128)
- model = AutoModel.from_pretrained("THUDM/chatglm-6b", config=config, trust_remote_code=True)
- prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin"))
- new_prefix_state_dict = {}
- for k, v in prefix_state_dict.items():
- if k.startswith("transformer.prefix_encoder."):
- new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
- model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
-
- # 之后根据需求可以进行量化
- # Comment out the following line if you don't use quantization
- model = model.quantize(4)
- model = model.half().cuda()
- model.transformer.prefix_encoder.float()
- model = model.eval()
- response, history = model.chat(tokenizer, "你好", history=[])

其中 CHECKPOINT_PATH 就是刚刚训练之后的文件,'output/adgen-chatglm-6b-pt-128-2e-2/checkpoint-1500'
注意你可能需要将pre_seq_len改成你训练时的实际值。如果你是从本地加载模型的话,需要将THUDM/chatglm-6b改成本地的模型路径(注意不是checkpoint路径)。
3 ChatGLM2-6B训练
3.1 训练参数解读
- PRE_SEQ_LEN=128 # soft prompt 长度
- LR=2e-2 # 训练学习率
- NUM_GPUS=2 # GPU卡的数量
-
- torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
- --do_train \ # 执行训练功能,还可以执行评估功能
- --train_file AdvertiseGen/train.json \ # 训练文件目录
- --validation_file AdvertiseGen/fval.json \ # 验证文件目录
- --prompt_column content \ # 训练集中prompt提示名称,对应训练文件,测试文件的"content"
- --response_column summary \ # 训练集中答案名称,对应训练文件,测试文件的"summary"
- --overwrite_cache \ # 缓存,重复训练一次的时候可删除
- --model_name_or_path THUDM/chatglm-6b \ # 加载模型文件目录,也可修改为本地模型的路径
- --output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \ # 保存训练模型文件目录
- --overwrite_output_dir \ # 覆盖训练文件目录
- --max_source_length 64 \ # 最大输入文本的长度
- --max_target_length 128 \
- --per_device_train_batch_size 1 \ # batch_size 训练批次根据显存调节
- --per_device_eval_batch_size 1 \ # 验证批次
- --gradient_accumulation_steps 16 \ # 梯度累加的步数
- --predict_with_generate \
- --max_steps 3000 \ # 最大训练模型的步数
- --logging_steps 10 \ # 多少步打印日志一次
- --save_steps 1000 \ # 多少步保存模型一次
- --learning_rate $LR \ # 学习率
- --pre_seq_len $PRE_SEQ_LEN \
- --quantization_bit 4 # 量化,也可修改为int8
训练配置参数具体解释
# prompt 长度和 学习率
–PRE_SEQ_LEN 是 soft prompt 长度,可以进行调节以取得最佳的效果。
–LR 是训练的学习率
# 本地数据,训练集和测试集的路径
–train_file AdvertiseGen/train.json
–validation_file AdvertiseGen/dev.json \
# 模型目录。
如果你想要从本地加载模型,可以将THUDM/chatglm2-6b 改为你本地的模型路径。
–model_name_or_path THUDM/chatglm-6b
# 最大训练步数
–max_steps 3000
# 模型量化,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。在默认配置 quantization_bit=4
–quantization_bit 4 # 量化,也可修改为int8
# 批次,迭代参数,在默认配置 per_device_train_batch_size=1、gradient_accumulation_steps=16 下,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
–per_device_train_batch_size 1 \ # batch_size 训练批次根据显存调节
–per_device_eval_batch_size 1 \ # 验证批次
–gradient_accumulation_steps 16 \ # 梯度累加的步数
Num examples = 114,599: 表示在训练集中有114,599个样本,即114,599个独立的训练数据用于训练。
Num Epochs = 100: 一个epoch指的是模型在训练过程中遍历整个训练集一次。因此,Num Epochs = 100意味着模型会遍历整个训练集100次。
Instantaneous batch size per device = 4: 在深度学习中,通常不会同时处理所有的训练样本,而是将它们分成“批次”进行处理。每个批次的大小就是每次模型训练的样本数量。在这个例子中,每个设备上的即时批量大小为4,意味着每个设备一次处理4个样本。
Total train batch size (w. parallel, distributed & accumulation) = 16: 表示在并行、分布式和积累情况下,总的训练批次大小为16。这可能意味着在多个设备上同时进行训练,每个设备处理一部分批次,然后把这些批次加起来,总和为16。
Gradient Accumulation steps = 4: 梯度累积是一种在内存不足的情况下训练大模型的技巧。它的工作原理是:在进行反向传播并更新模型权重之前,先计算并累积一定步数的梯度。在该例中,每4个批次后进行一次权重更新。
Total optimization steps = 3,000: 优化步数是模型训练过程中权重更新的总次数。在这个例子中,模型权重将被更新3000次。
Number of trainable parameters = 1,949,696: 这是模型中可以通过训练改变的参数的数量。深度学习模型的性能通常与其可训练参数的数量有关。但是,更多的参数并不总是意味着更好的性能,因为过多的参数可能导致过拟合,即模型过于复杂,不能很好地泛化到训练集之外的新数据。
模型配置信息
- "add_bias_linear": false,
- "add_qkv_bias": true,
- "apply_query_key_layer_scaling": true,
- "apply_residual_connection_post_layernorm": false,
- "architectures": [
- "ChatGLMModel"
- ],
- "attention_dropout": 0.0,
- "attention_softmax_in_fp32": true,
- "auto_map": {
- "AutoConfig": "configuration_chatglm.ChatGLMConfig",
- "AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
- "AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration"
- },
- "bias_dropout_fusion": true,
- "eos_token_id": 2,
- "ffn_hidden_size": 13696,
- "fp32_residual_connection": false,
- "hidden_dropout": 0.0,
- "hidden_size": 4096,
- "kv_channels": 128,
- "layernorm_epsilon": 1e-05,
- "model_type": "chatglm",
- "multi_query_attention": true,
- "multi_query_group_num": 2,
- "num_attention_heads": 32,
- "num_layers": 28,
- "original_rope": true,
- "pad_token_id": 2,
- "padded_vocab_size": 65024,
- "post_layer_norm": true,
- "quantization_bit": 0,
- "rmsnorm": true,
- "seq_length": 32768,
- "tie_word_embeddings": false,
- "torch_dtype": "float16",
- "transformers_version": "4.30.2",
- "use_cache": true
这些参数是深度学习模型配置的详细设置,特别是对于ChatGLM的模型。以下是每个参数的含义:
“add_bias_linear”: false: 表示是否在线性层中添加偏置项。
“add_qkv_bias”: true: 表示是否在注意力机制的查询(Q)、键(K)和值(V)计算中添加偏置项。
“apply_query_key_layer_scaling”: true: 表示是否对注意力机制中的查询和键进行缩放处理。
“apply_residual_connection_post_layernorm”: false: 表示是否在层归一化后应用残差连接。
“architectures”: [“ChatGLMModel”]: 表示该配置用于的模型架构。
“attention_dropout”: 0.0: 表示在注意力计算中应用的dropout的比率。Dropout是一种防止模型过拟合的技术。
“attention_softmax_in_fp32”: true: 表示是否在单精度浮点格式(FP32)中执行注意力机制的Softmax计算。
“auto_map”: 这部分将自动配置,模型映射到ChatGLM的配置和模型。
“bias_dropout_fusion”: true: 表示是否融合偏置和dropout。这通常用于优化和提高训练速度。
“eos_token_id”: 2: 定义结束符(End of Sentence)的标识符。
“ffn_hidden_size”: 13696: 表示前馈神经网络(Feedforward Neural Network,FFN)的隐藏层的大小。
“fp32_residual_connection”: false: 表示是否在单精度浮点格式(FP32)中应用残差连接。
“hidden_dropout”: 0.0: 隐藏层的dropout率。
“hidden_size”: 4096: 隐藏层的大小。
“kv_channels”: 128: 键值(Key-Value)的通道数。
“layernorm_epsilon”: 1e-05: 层归一化的epsilon值,为了防止除数为零。
“model_type”: “chatglm”: 模型类型。
“multi_query_attention”: true: 表示是否使用多查询注意力。
“multi_query_group_num”: 2: 在多查询注意力中的查询组数。
“num_attention_heads”: 32: 注意力机制的头数。
“num_layers”: 28: 模型的层数。
“original_rope”: true: 是否使用原始的ROPE模式。
“pad_token_id”: 2: 定义填充符的标识符。
“padded_vocab_size”: 65024: 表示经过填充后的词汇表大小。
“post_layer_norm”: true: 是否在层后应用层归一化。
“quantization_bit”: 0: 表示量化的位数。
“rmsnorm”: true: 表示是否使用RMS归一化。
“seq_length”: 32768: 序列长度。
“tie_word_embeddings”: false: 是否绑定输入和输出的词嵌入。
“torch_dtype”: “float16”: 使用的数据类型,这里是半精度浮点数。
“transformers_version”: “4.30.2”: 使用的Transformers库版本。
“use_cache”: true: 是否使用缓存以加快计算速度。
3.2 数据集处理
官方给出的数据处理格式:
- {
- "content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
- "summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
- }
{“content”:"","summary":""}形式,这里面我没可以处理自己的数据集成这种格式,我的是问答类数据,那么content就是问题,summary就是回答。
- 使用自己的数据集
用以上数据格式创建自己的train.json和dev.json文件,指定数据文件夹路径后期微调需要改成自己的路径名称。修改 train.sh 和 evaluate.sh 中的 train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将 prompt_column 和 response_column 改为 JSON 文件中输入文本和输出文本对应的 KEY。可能还需要增大 max_source_length 和 max_target_length 来匹配你自己的数据集中的最大输入输出长度。
- 两种数据增强的方法(扩展):
(1)simBert做相似文本生成。
这里给出苏神的代码:GitHub - ZhuiyiTechnology/simbert
(2)直接使用ChatGPT生成相似文本。

chatGPT生成20条相似文本,对比可以很明显的看出chatGPT生成的相似文本质量会更好。
如需要使用多轮对话数据对模型进行微调,可以提供聊天历史,例如以下是一个三轮对话的训练数据:
{"prompt": "长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "response": "用电脑能读数据流吗?水温多少", "history": []}
{"prompt": "95", "response": "上下水管温差怎么样啊?空气是不是都排干净了呢?", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"]]}
{"prompt": "是的。上下水管都好的", "response": "那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"], ["95", "上下水管温差怎么样啊?空气是不是都排干净了呢?"]]}
训练时需要指定 --history_column 为数据中聊天历史的 key(在此例子中是 history),将自动把聊天历史拼接。要注意超过输入长度 max_source_length 的内容会被截断。
3.3 模型部署
首先载入Tokenizer:
- from transformers import AutoConfig, AutoModel, AutoTokenizer
-
- # 载入Tokenizer
- tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
如果需要加载的 P-Tuning 的 checkpoint:
- config = AutoConfig.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, pre_seq_len=128)
- model = AutoModel.from_pretrained("THUDM/chatglm2-6b", config=config, trust_remote_code=True)
- prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin"))
- new_prefix_state_dict = {}
- for k, v in prefix_state_dict.items():
- if k.startswith("transformer.prefix_encoder."):
- new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
- model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
注意你可能需要将 pre_seq_len 改成你训练时的实际值。如果你是从本地加载模型的话,需要将 THUDM/chatglm2-6b 改成本地的模型路径(注意不是checkpoint路径)。
如果需要加载的是全参数微调的 checkpoint,则直接加载整个 checkpoint:
model = AutoModel.from_pretrained(CHECKPOINT_PATH, trust_remote_code=True)之后根据需求可以进行量化,也可以直接使用:
- # Comment out the following line if you don't use quantization
- model = model.quantize(4)
- model = model.cuda()
- model = model.eval()
-
- response, history = model.chat(tokenizer, "你好", history=[])
你也可以直接运行支持加载 P-Tuning v2 checkpoint 的 web_demo
bash web_demo.sh需要修改 web_demo.sh 的内容以符合你实际的 checkpoint 情况。
4 其它训练方式
4.1 Instruct-Tuning
https://github.com/thinksoso/ChatGLM-Instruct-Tuning
基于清华的 ChatGLM-6B + Alpaca 方式进行finetune.
数据集: 中文alpaca
数据样例参考:
- [
- {
- "instruction": "根据给定的坐标确定最近的机场。",
- "input": "40.728157, -73.794853",
- "output": "距给定坐标最近的机场是纽约市的拉瓜迪亚机场 (LGA)。"
- },
- {
- "instruction": "输出不同种类水果的列表",
- "input": "",
- "output": "1. 苹果\n2. 香蕉\n3. 橘子\n4. 芒果\n5. 草莓\n6. 葡萄\n7. 蓝莓\n8. 樱桃\n9. 猕猴桃\n10. 甜瓜\n11.菠萝\n12. 李子\n13.桃子"
- },
- {
- "instruction": "找出字串中隐藏的信息",
- "input": "业余咖啡",
- "output": "隐藏的消息是“咖啡因爱好者”。"
- }
- ]
4.2 DeepSpeed DP+Zero对ChatGLM-6B进行全参数微调
使用DeepSpeed/P-Tuning v2对ChatGLM-6B进行微调
我们使用DeepSpeed对ChatGLM-6B进行全参数微调。
首先,下载源代码,为确保代码的一致性切换到对应的commitid:
- git clone https://github.com/THUDM/ChatGLM-6B.git
- cd ChatGLM-6B
- git checkout 8633db1
- cd ptuning
修改ds_train_finetune.sh脚本使用DeepSpeed进行全参数微调。
- LR=1e-4
-
- MASTER_PORT=$(shuf -n 1 -i 10000-65535)
-
- deepspeed --num_gpus=8 --master_port $MASTER_PORT main.py \
- --deepspeed deepspeed.json \
- --do_train \
- --train_file /data/nfs/llm/data/AdvertiseGen/train.json \
- --test_file /data/nfs/llm/data/AdvertiseGen/dev.json \
- --prompt_column content \
- --response_column summary \
- --overwrite_cache \
- --model_name_or_path /data/nfs/llm/model/chatglm-6b \
- --output_dir /home/guodong.li/output/adgen-chatglm-6b-ft-$LR \
- --overwrite_output_dir \
- --max_source_length 64 \
- --max_target_length 64 \
- --per_device_train_batch_size 24 \
- --per_device_eval_batch_size 1 \
- --gradient_accumulation_steps 2 \
- --predict_with_generate \
- --num_train_epochs 2 \
- --logging_steps 10 \
- --save_steps 300 \
- --learning_rate $LR \
- --fp16
训练结束后没有保存模型权重,只保存了训练过程中的checkpoint,可在代码中添加trainer.save_model()进行保存。
使用DeepSpeed进行full finetuning,对于显存要求较高,且训练较慢。
输出文件包括:
- tree /home/guodong.li/output/adgen-chatglm-6b-ft-1e-4
- /home/guodong.li/output/adgen-chatglm-6b-ft-1e-4
- ├── all_results.json
- ├── checkpoint-300
- │ ├── config.json
- │ ├── configuration_chatglm.py
- │ ├── generation_config.json
- │ ├── global_step600
- │ │ ├── mp_rank_00_model_states.pt
- │ │ ├── zero_pp_rank_0_mp_rank_00_optim_states.pt
- │ │ ├── zero_pp_rank_1_mp_rank_00_optim_states.pt
- │ │ ├── zero_pp_rank_2_mp_rank_00_optim_states.pt
- │ │ ├── zero_pp_rank_3_mp_rank_00_optim_states.pt
- │ │ ├── zero_pp_rank_4_mp_rank_00_optim_states.pt
- │ │ ├── zero_pp_rank_5_mp_rank_00_optim_states.pt
- │ │ ├── zero_pp_rank_6_mp_rank_00_optim_states.pt
- │ │ └── zero_pp_rank_7_mp_rank_00_optim_states.pt
- │ ├── ice_text.model
- │ ├── latest
- │ ├── modeling_chatglm.py
- │ ├── pytorch_model-00001-of-00002.bin
- │ ├── pytorch_model-00002-of-00002.bin
- │ ├── pytorch_model.bin.index.json
- │ ├── quantization.py
- │ ├── rng_state_0.pth
- │ ├── rng_state_1.pth
- │ ├── rng_state_2.pth
- │ ├── rng_state_3.pth
- │ ├── rng_state_4.pth
- │ ├── rng_state_5.pth
- │ ├── rng_state_6.pth
- │ ├── rng_state_7.pth
- │ ├── special_tokens_map.json
- │ ├── tokenization_chatglm.py
- │ ├── tokenizer_config.json
- │ ├── trainer_state.json
- │ ├── training_args.bin
- │ └── zero_to_fp32.py
- ├── trainer_state.json
- └── train_results.json
-
- 2 directories, 36 files

