
人脸识别经历了早期算法,人工特征+分类器,深度学习三个阶段。
一.早期算法
1.基于几何特征的方法
每个人的面部器官例如眼睛、鼻子、嘴巴等都存在差异,因此每个人的面貌也千差万别。基于几何特征进行人脸识别的思想是将人脸的关键器官(例如眼睛,鼻子)的大小、形状以及相对位置构成一组几何特征,来表示人脸信息,从而根据特征矢量之间的匹配来进行人脸识别。
这种方法的优点是检测速度快。然而,它的缺点也是不可忽略的。因为人脸部位的提取通常借助边缘算子,光照,噪音,阴影极有可能破坏人脸的边缘,所以该方法对图片质量要求高,对光照和背景有较高的要求;其次,本方法对人脸表情,图片旋转不敏感。
2.基于模板匹配的方法
模板匹配指的是用某一模板图片去另一张图片中比对,寻找与该模板最相似的部分。
根据模板匹配层次不同,可以将匹配分为以下三种:基于点的方法、基于区域的方法、利用混合特征的方法。
例如,我们想从下面的图片中找出姚明头像的位置,并把它标记出来,这就是模板匹配需要做的事情。

原图

模板图片
模板匹配的思想就是用截取好的模板图片(姚明头像)去原图中从左到右,从上到下依次滑动,直到遇到某个区域的相似度低于我们设定的阈值,这就说明该区域与我们的模板相匹配,从而找到了姚明头像所处的位置。

识别结果
(参考自https://www.cnblogs.com/skyfsm/p/6884253.html)
该方法检测率,误检率都不是很高,但是仍然不能有效处理人脸尺度,表情等方面的变化。而且模板图片只能进行平行移动,当原图中的匹配目标发生旋转或者尺度变化时,该算法失效。
3.基于局部特征的方法
局部,指的是物体表面稳定出现且具有良好可区分性的一些特殊点。基于局部特征的方法就是指用物体上面一些特殊的点来代表物体,在物体不受到完全遮挡的情况下,这些局部特征仍然存在。
例如下面的图片,最左边的一列是完整的图像,中间一列是一些角点(局部特征),最右边的一类是除掉角点之后的线段。

显然,中间的一列与最右边的一列相比的话,中间那一列更容易与左边相对应。
(详见https://blog.csdn.net/qq_26898461/article/details/49885673)
局部图像特征描述子包括:SIFT(详见下一篇博客),SURF,DAISY,ASIFT,MROGH,BRIEF。
该类方法的优点在于用局部特征来代表物体,简化了模型,便于我们分析;其次,减少了图片原有的信息量,从而减少了计算量。最后,在物体受到干扰时,依然可以从未被遮挡的特征点还原重要信息。
文章链接:中国安防展览网 http://www.afzhan.com/Tech_news/detail/127453.html
局部特征点是图像特征的局部表达,它只能反映图像上具有的局部特殊性,所以他只适合于对图像进行匹配,检索等应用。对于图像理解则不太适合。后者更关心一些全局特征。例如颜色分布,纹理特征等。
4.子空间算法
思想:将人脸当成一个高维的向量,将该向量投影到低维空间中,得到低维向量。该低维向量对不同的人具有良好的区分度。
这里介绍两种降维方法:PCA(Principle Component Analysis)与LDA(Linear Discriminant Analysis)。
PCA(主成分分析法)
PCA的核心思想是在进行投影之后尽量多的保留原始数据的主要信息,减少冗余信息。
PCA是无监督的降维算法,计算出X变化最大的前N个方向并将X向这些方向投影,得到一个N维的向量Y。
LDA(线性判别分析)
LDA是有监督的算法,根据类别标记找到最大化类间差异,最小化类内差异的方向。即保证同一个人的不同人脸图像在投影之后聚集在一起,不同人的人脸图像在投影之后被用一个大的间距分开。
5.稀疏表达
稀疏表达的思想是:用较少的基本信号的线性组合来表达大部分或者全部的原始信号。
稀疏表达问题可以描述为:对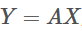 ,已知Y和A,求X。
,已知Y和A,求X。
稀疏表示解决的问题主要集中在:图像去噪(Denoise)和超分辨率重建(Super-Resolution OR Scale-Up)。
二.人工特征+分类器
描述图像的很多特征都先后被用于人脸识别问题,包括HOG(Histogram of Oriented Gradient, 方向梯度直方图),SIFT(Scale-invariant feature transform,尺度不变特征变化),Gabor,LBP(Local Binary Pattern,局部二值模式)等。
他们中的典型代表是 LBP(Local Binary Pattern,局部二值模式)。LBP是一种用来描述图像局部纹理特征的算子,它具有旋转不变性和灰度不变性等显著的优点。它在1994年被提出,用于纹理特征提取。
原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,把周围像素值中大于中心像素值的位置标记为1,小于中心像素值的标记为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即可得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。如下图所示:
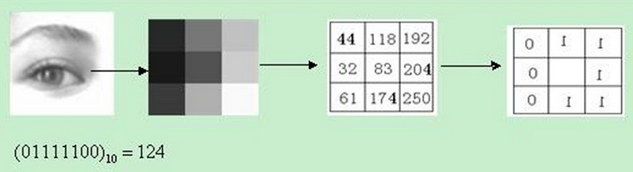
原始的LBP算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。后来,研究人员对其提出了很多改进和优化,提出了圆形LBP算子,LBP旋转不变模式,LBP等价模式。
分类器的常规任务是利用给定的类别,已知的训练数据来学习分类规则,然后对未知数据进行分类(或预测)。
常见的分类器有:softmax分类器,logistic分类器,boosting,Adaboost,SVM。其中逻辑回归(logistic回归),支持向量机(SVM)等常用于解决二分类问题;对于多分类问题,比如识别手写数字需要10个分类,常用的多分类方法有softmax。
SVM(support vector machines,支持向量机),是一个二分类的分类模型。分类思想是给定一个包含正例和反例的样本集合,其目的是寻找一个超平面将样本正例和反例分隔开,并且使所有点中离超平面最近的点距离超平面有更大的间距。
三.深度学习
DeepFace
DeepFace是CVPR2014上由Facebook提出的方法,是深度卷积神经网络在人脸识别领域的奠基之作。
在人脸对齐方面,DeepFace模型采用了3D对齐的方式,并且使用传统的LBP直方图进行图片纹理化并提取对应的特征。对提取出的特征使用SVR(support vector regression)处理以提取人脸及对应的六个基本点。根据六个基本点做仿射变换,再根据3D模型得到对应的67个面部关键点,根据这些点做三角划分,最终得出对应的3D人脸。
DeepFace在训练过程中采用的是一般的交叉熵损失函数,并且采用一般的softmax对训练的数据进行分类,只不过从特征向量产生到用来分类的过程中使用了一些内积、卡方距离或siamese的度量方式来计算相似度,用相似度来进行训练产生分类器。
具体对齐流程如下:
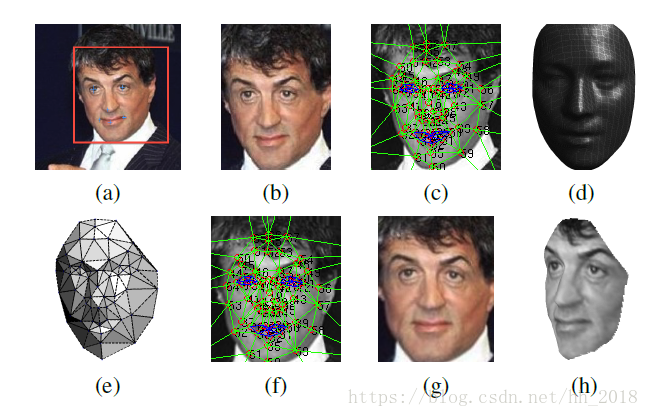
(a)检测出人脸和对应的六个基本点
(b)二维对齐后的人脸
(c)使用狄罗尼三角划分在2D人脸上划分出67个关键点,并在边缘处采用添加三角形的方式避免不连续
(d)标准3D人脸模型(转化为2D平面并和原始2D图片进行比较时所需要的)(通过标准3D人脸库USF生成的对应的平均人脸模型)
(e)标准3D脸转化为2D以及原有的2D做残差使用 时所需的变化,黑色部分表示不可见的三角形。对于不可见的三角形处理采用的是对称方式解决
(f )通过3D模型产生的67个基准点进行分段映射使人脸变弯曲,对人脸进行对齐处理
(g)处理生成的2D人脸
(h)根据处理生成的3D人脸
其中,c和f相比经过了标准3D人脸转化为2D人脸时的残差处理,此时主要是为保证在转化过程中特征的保留。e的作用是为了显示在处理过程中3D-2D转化为何是通过三角形的仿射变换进行的,由e可以看出处理后的人脸是一个个的三角形块。
该模型对对齐后的人脸采用CNN结构进行处理,具体网络结构如下: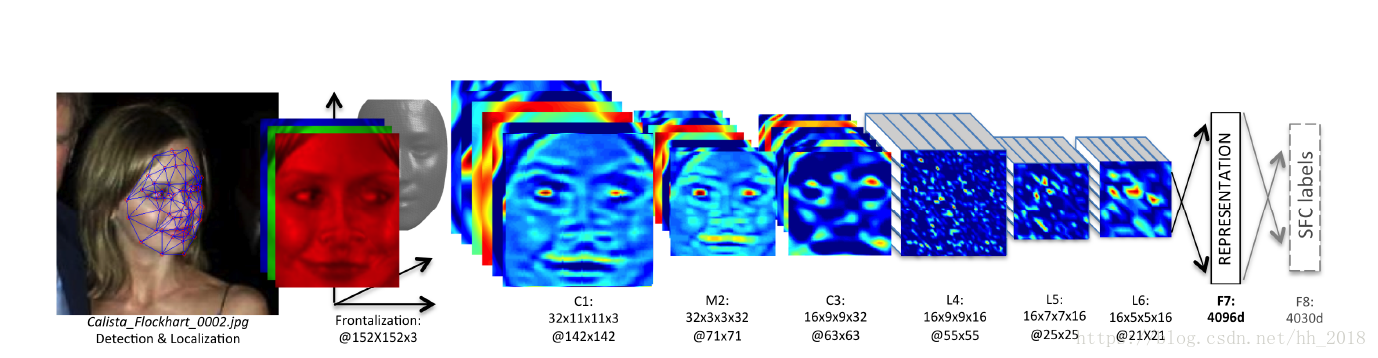
具体的卷积计算过程为:
c1:32个11X11的卷积核,参数共享
M2:3X3的池化层,stride=2
c2: 16个9X9的卷积核,参数共享
L4: 16个9X9的卷积核,参数不共享
L5: 16个7X7的卷积核,参数不共享
L6: 16个5X5的卷积核,参数不共享
F7: 全连接层4096维(提取出的人脸特征)
F8: softmax分类层。4030是因为训练采用的LFW数据中包含4030个people。
(参考自:https://blog.csdn.net/hh_2018/article/details/80576290)
FaceNet
FaceNet是Google公司提出的一种新的人脸识别的方法,该方法在LFW数据集上的准确度达到了99.6%。
FaceNet是直接学习图像到欧式空间上点的映射,其中,两张图像所对应特征在欧式空间上的点的距离直接对应着两个图像是否相似。
FaceNet结构如下图:

Batch:指输入的人脸图像样本,这里的样本已经经过人脸检测找到人脸并裁剪到固定尺寸。
Deep architecture:指的是采用一种深入学习架构,例如ZF网络、GoogleNet等。
L2:指特征归一化(使其特征的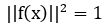 ,这样所有图像的特征都会被映射到一个超球面上)
,这样所有图像的特征都会被映射到一个超球面上)
Embedding:就是前面经过深度学习网络,L2归一化后生成的特征向量(这个特征向量就代表了输入的一张样本图片)
Triplet Loss:有三张图片输入的Loss,直接学习特征间的可分性:相同身份之间的特征距离要尽可能小,不同身份之间的特征距离要尽可能大。
对于Triple loss的示例:
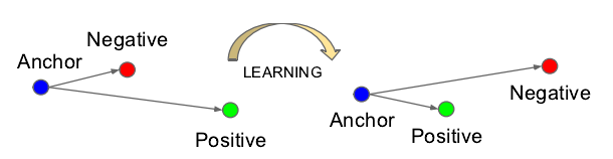
我们可以看出,通过学习,类间的距离比类内距离大得多。
DeepID
DeepID模型是人脸识别中主流的模型之一,DeepID所应用的领域是人脸识别的子领域——人脸验证,即判断两张图片是不是同一个人。
DeepID的结构图如下:
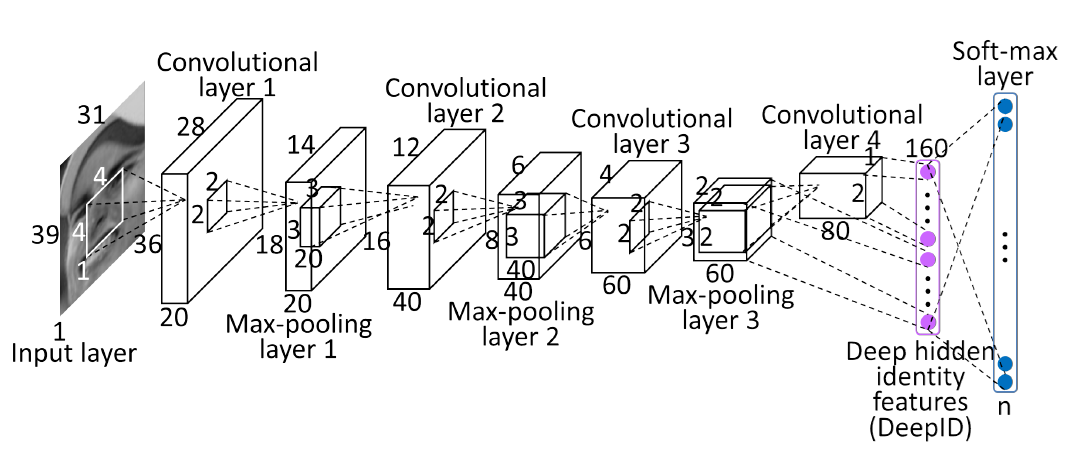
该结构与普通的卷积神经网络的结构相似,它采用4层卷积网络,3层池化层,1层全连接层,全连接层得到的是160维特征向量。但是在隐含层,也就是倒数第二层,与最后一层卷积层和最后一层池化层相连。鉴于卷积神经网络层数越高视野域越大的特性,这样的连接方式可以既考虑局部的特征,又考虑全局的特征。
DeepID2的结构图如下:
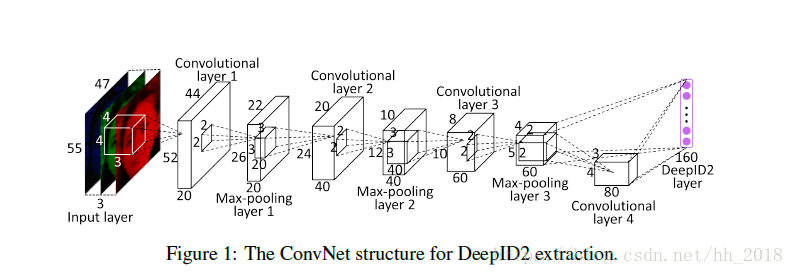
DeepID2的结构与DeepID相似,有4个卷积层,3个池化层,1个全连接层。全连接层得到的是160维特征向量。最后一个卷积层和最后一个池化层均和最后的全连接层直接相连。
DeepID与DeepID2两种网络的区别主要在于:
DeepID是根据结果(160维向量)直接进行分类训练,分类的目标向量(做比较的向量,真实值)采用0-1法生成。此时仅仅用到了身份的信息,利用分类结果来定义对应的损失函数并将数据按batch的方式传给训练过程。
DeepID2对损失函数进行了修改。除了根据分类结果定义损失函数外,还根据鉴定结果(两张图片是不是同一个人)定义对应的损失函数。两个损失函数按照比重叠加作为最终的函数进行训练。其训练方式也不再是按batch传入,而是按照随机选取对应的图片对进行训练和更新。
转载请注明出处。

