
- 1如何在Sublime Test中注册并去掉烦人的更新提示_sublime test 注册码
- 2【使用Neo4j进行图数据可视化】_neo4j 可视化动态
- 3当前最流行的架构设计模式
- 4爆肝三天,我整理了这份春招攻略【针对大三/研二】_大三春招和大四春招区别
- 5消息队列技术选型(Kafka + RocketMQ)_kafka和rocketmq可以同时用嘛
- 6动态规划最多任务工资java_五大常用算法之二:动态规划算法,会用的程序员工资都翻倍了...
- 7数据结构之链表详解_链表数据结构
- 8AliOS-Things--ESP8266 (10)OTA在线升级_alios fota升级版本号的更新
- 9px4在环仿真实践操作_如何用遥控器控制硬件在环仿真
- 10论Oracle 11g安装完成步骤及详解+干净卸载方法_oracle直接安装结束
BERT系列模型 在OCNLI 训练微调 3
赞
踩
0 资料
这是一个系列:
过去的内容:
Bert 在 OCNLI 训练微调
Bert 在 OCNLI 训练微调 2
arxiv:RoBERTa: A Robustly Optimized BERT Pretraining Approach
pytorch官方实现:https://pytorch.org/hub/pytorch_fairseq_roberta/
hugging face hfl chinese-roberta-wwm-ext:https://huggingface.co/hfl/chinese-roberta-wwm-ext/tree/main
1 项目搭建
1.1 环境安装
安装transformers
pip install transformers
- 1
pip install pandas
pip install wandb
- 1
- 2
- 3
1.2 项目源码
https://github.com/Whiffe/Bert-OCNLI/tree/main
1.3 模型下载
https://huggingface.co/junnyu/structbert-large-zh
1.4 目录结构
2 改进部分
相对于Bert 在 OCNLI 训练微调 2,我做了代码的更多改进。
改进如下:
1,可以实现更多模型的切换
2,固定随机种子,保证输出的数据一致
3,增加了另一个数据集进行联合训练
4,模型测试时选择最好的一个模型而非最后一个
2.1 可以实现更多模型的切换
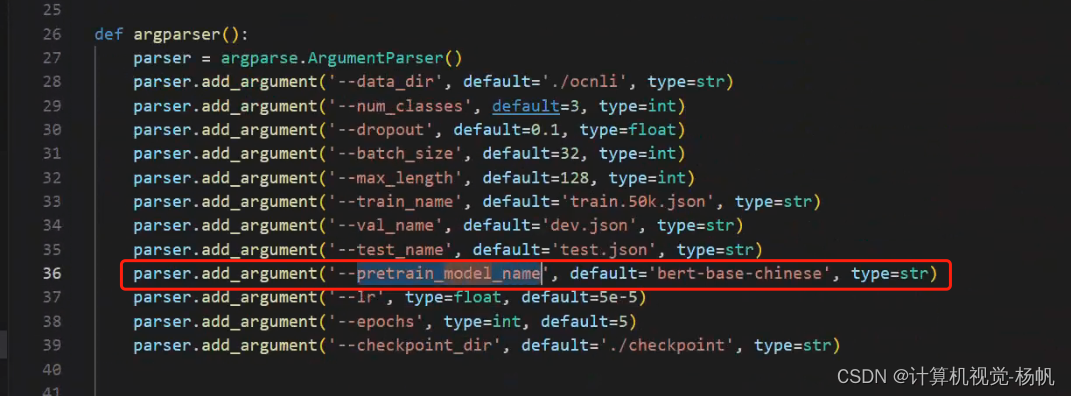
通过 --pretrain_model_name 来传递你的模型
2.2 固定随机种子,保证输出的数据一致
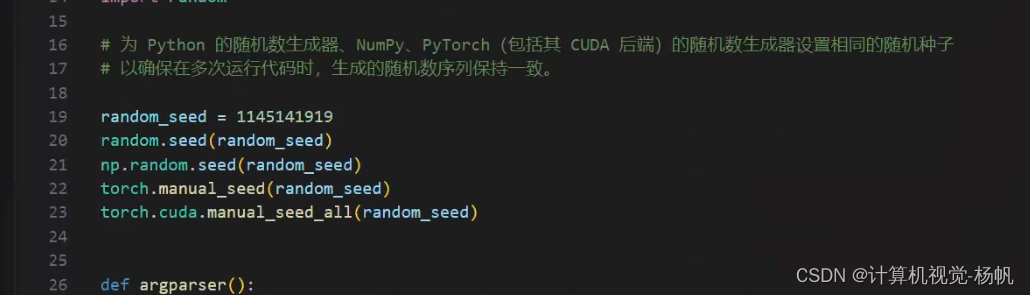
2.3 增加了另一个数据集进行联合训练

中文自然语言推理数据集(A large-scale Chinese Nature language inference and Semantic similarity calculation Dataset):https://github.com/pluto-junzeng/CNSD?tab=readme-ov-file

2.4 模型测试时选择最好的一个模型而非最后一个
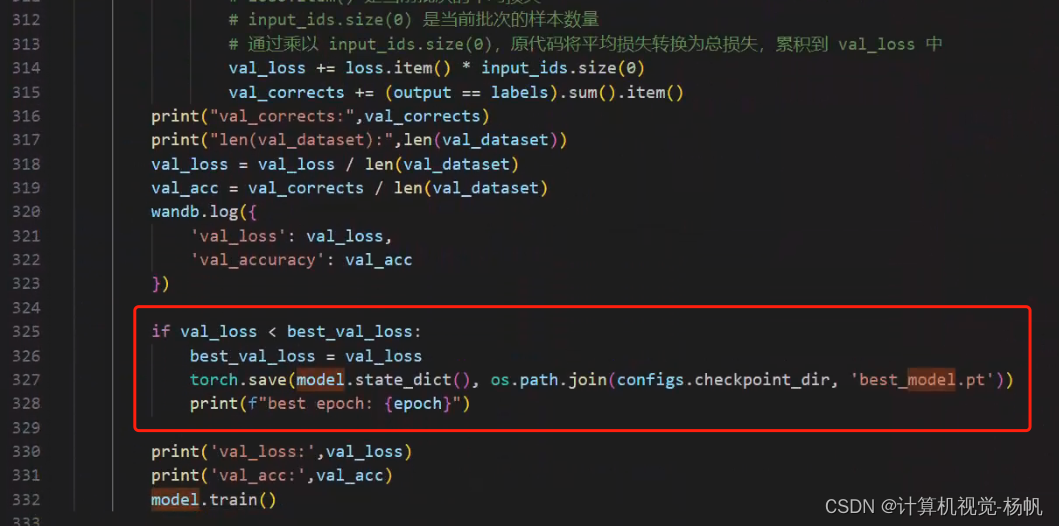
3 实验结果
参数设置:dropout=0.3、batch_size=32、max_length=128、lr=5e-5、epochs=5、train.50k.json
roberta模型:71.57%
Chinese-SNLI 550k到训练集中,共550+50=600k的数据
准确率:70.23%
Chinese-SNLI 550k按照5%的概率取样到训练集集中。共27.5+50=77.5k的数据
准确率:72.1%
Chinese-SNLI 550k按照10%的概率取样到训练集集中。共55+50=105k的数据
准确率:71.37%
MacBERT模型:73.23%
Chinese-SNLI 550k按照10%的概率取样到训练集集中。共55+50=105k的数据
准确率:71.6%
structbert-large-zh模型:76.83%
chinese-roberta-wwm-ext-large模型:

