
- 1[毕业设计源码]JAVA毕业设计楼宇管理系统(系统+LW) 环境项配置:_毕设系统环境配置
- 2git解决:remote: [session-ff44779b] 404 not found!fatal: repository ‘https://gitee.com/xhcg/group-ware_git remote: 404 page not found
- 3Docker-compose搭建kafka集群_docker-compose 单机kafka集群
- 4数学建模——管住嘴迈开腿——python实现_管住嘴迈开腿数学建模论文
- 5【开源学习】ThingsBoard -- 基本配置与使用
- 6【SQL】sqlite数据库损坏报错:database disk image is malformed(已解决)_sqlite database disk image is malformed
- 77-1 字符串排序
- 8PHP动态网站开发期末试卷,《PHP动态网站开发实例教程》课程考核方案
- 9数据中台建设(二):数据中台简单介绍
- 10解决无法访问OpenAI API的三种方式
Flink和Spark Streaming流式计算模型比较分析_flink sparkstreaming
赞
踩
一、Spark Streaming
1.1 Spark概述
Spark是UC Berkeley AMP Lab开源的类似于MapReduce的通用的并行计算框架,同时兼顾分布式的并行计算模型和基于内存计算的特点。
Spark优于MapReduce的最大的好处是作业计算的中间结果不需要再像MapReduce一样刷写到hdfs等外部存储,而是保存在内存中,因此不需要与外部存储来回读写,能极大提升性能。
下面为Spark的部署图:
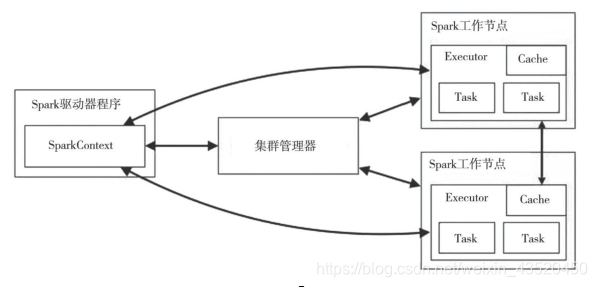
Spark的部署采用Master-Slave模型,运行时会在集群中启动Driver节点和多个Worker节点。Driver在接受客户端提交上来的作业后,建立RDD的血缘关系,记录血缘状态,分发任务到Worker节点上进行计算,并接受所有Worker节点的计算结果。
1.2 Spark Streaming 概述
Spark Streaming是建立在Spark之上的流式计算框架,通过Spark提供的API和基于内存的高速计算引擎,用户可以使用批处理进行micro-batch流式计算,做到代码逻辑上的重复使用。和Spark中的RDD非常相似,Spark Streaming中使用离散化流(Discretized Stream)作为抽象的表示,叫做DStream。
它是随时间推移而收集数据的序列,每个时间段收集到的数据在DStream内以一个RDD的形式存在。
Spark Streaming 的执行流程图:

Spark Streaming框架提供了良好的可扩展性和容错性。在对数据的处理模式上,Spark Streaming是处理某个时间窗口内的事件流,因此相对于Strom、Flink等处理独立事件的计算引擎,延迟相对较高。
二、Flink
2.1 Flink 概述
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算框架,能在同一个Flink运行时(Flink Runtime)支持分布式流处理和批处理两种类型功能应用,这里主要介绍Flink的流处理能力。它对流处理的支持是全面的。当作为流处理时,输入数据是无界的。批处理则可认为是一种特殊的流处理,即它的输入数据流被定义为有界。这与传统的一些方案完全不同,Flink将二者合二为一,分别提供了流处理和批处理的API,这些API为实现上层应用提供了选择。Flink在处理流数据时具有高吞吐、低延迟和高性能的特性,同时也支持带有事件时间的窗口(Window)操作、高度灵活的窗口操作以及基于轻量级分布式快照(Snapshot)实现的容错,Flink的内存管理是在JVM内部实现的。
2.2 Flink的基本架构
Flink系统也是基于Master-Slave风格的架构
如下图所示:
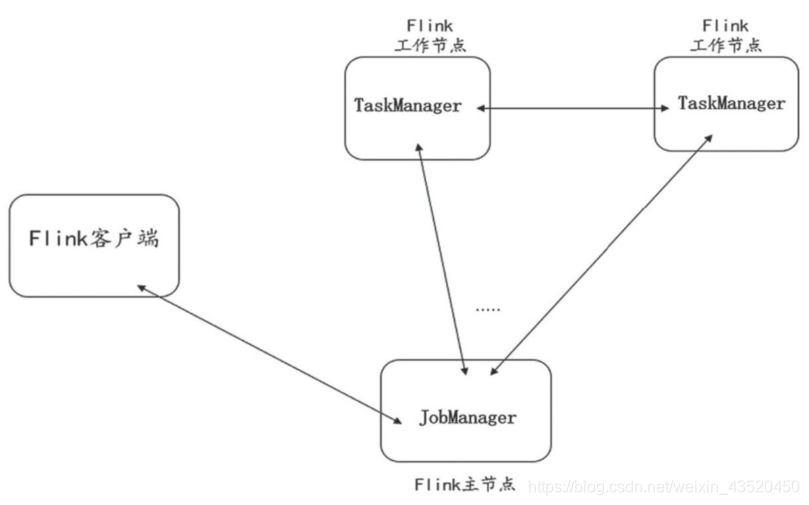
Flink运行时会同时启动JobManager节点和多个TaskManager节点,用户将Flink作业提交到客户端,客户端会对作业做第一步的预处理优化,并且以JobGraph拓扑图的形式提交给JobManager。JobManager会将作业分发到TaskManager节点上进行计算处理,最后将结果返回给客户端。Flink最大的特点是有状态的流式计算,从Source开始每一个算子或者每一次计算都会在State中记录其中间状态,这个中间状态在容错恢复或者迭代计算中起到很大的作用。
三、Flink和Spark Streaming流式计算对比分析
3.1 时间机制
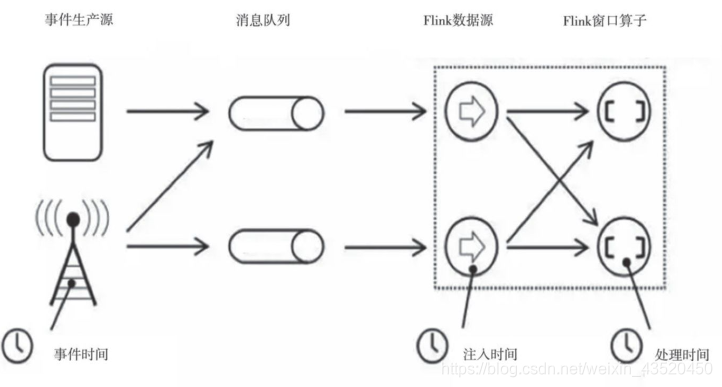
流处理程序在时间概念上共有3个时间概念,分别是:
处理时间(Processing time)
事件时间(Event time)
注入时间(Ingestion time)
其中,处理时间主要是指每台机器的系统时间不需要进行流与机器之间的协调,能提供最好的性能和最低的延迟,但是在分布式环境中难以提供时间的时序性保证。事件时间是指事件在其设备上发生的时间,可以在事件发生时将时间嵌入事件。基于事件时间进行处理的流式计算程序,可以保证事件的时序性。注入时间是指事件注入到计算引擎的时间。相对事件时间,注入时间没法处理无序事件和滞后事件。Flink支持所有的三种事件,且可以用waterMark机制处理滞后的数据,保证事件时间下的时序性。Spark Streaming只支持处理时间,最新的Structured streaming则可以支持处理时间和事件时间,同时与Flink一样支持waterMark机制处理滞后数据。
3.2 容错机制和一致性语义
流处理引擎通常会让用户指定处理语义级别来对程序中数据处理过程中提供对应级别的保障。程序运行中会因为各种内外因素而可能导致数据丢失,所以这个语义上的保障对于流式计算中意义重大。
流处理引擎通常提供三种数据处理语义:
最多一次(at most once)
至少一次(at least once)
精确一次(exactly once)
最多一次本质上是保证数据或事件最多由应用程序中的所有算子处理一次,缺点是数据在被程序完全处理前丢失将不会重发。
至少一次本质上是应用程序中所有算子都保证数据或事件至少被处理一次,缺点是会出现数据的重复处理。
精确一次(最好的处理方式),单条数据或者事件只会被精确处理一次,也是流处理引擎保证数据可靠性的重要特性。
Spark Streaming保证精确一次语义取决于上游数据源和下游输出的特性。上游数据源的特性取决于上游系统的特性。例如,从HDFS这类支持容错的文件系统中读取文件,能够直接支持精确的一次语义。Kafka消息系统是基于偏移量(Offset)的,它的Direct API可以提供精确一次语义。而Spark RDD在对数据进行处理转换时,天然获得精确一次语义,因为RDD本身是一种具备容错性、不变性以及计算确定性的数据结构。只要数据来源是可用的,且处理过程中没有副作用(Side effect),就能一直得到相同的计算结果。对于输出结果需要保证幂等或者事务更新的特点。
Flink内部通过Checkpoint机制实现精确一次的语义,Checkpoint机制是基于Chandy-Lamport算法的分布式一致性快照,通过在数据输入源发送Barrier同步全局状态,从而保证Flink内部的一致性语义。在Flink1.4版本之后,在sink function中增加了TwoPhaseCommitSinkFunction函数,通过两段提交构建从数据源到数据输出的一个端到端的精确一次语义的Flink作业。当然,输出端也必须要有事务回滚的特性,如Kafka0.11版本等。
四、分析总结
Spark和Flink都是通用计算引擎,支持大规模数据处理和各种类型的数据处理,每一个都有很多值得探索的地方,如SQL优化和机器学习集成。
Spark Streaming和Flink执行模型的最大区别在于对流处理的支持。最初,Spark Streaming流处理方法过于简单,导致在更复杂的处理中出现问题。Spark 2.0中引入结构化流,不再使用流语义,增加了对时间事件(event-time)的处理和端到端一致性的支持。而Flink从最开始的设计理念上就以流为核心,批处理只是流处理的一个特例,并致力于流批统一。

