
- 1高性能MySQL第四版-1_高性能mysql第四版电子书
- 2oracle数据库id字段自增长_oracle id自增
- 3带默认值的函数、内联函数和函数重载_内联函数,带默认值的函数,函数的重载有什么特点,请结合实例加以说明。
- 4怎样建立产品体系?(二)- 战略
- 5OriginBot智能机器人开源套件-Step10相机驱动与图像可视化
- 6在linux下使用git上传代码,在Linux下写一个进度条程序_git 进度条 zenmzuo
- 7SLF4J: Class path contains multiple SLF4J bindings.——Hbase启动输出
- 8PLSQL连接Oracle
- 9中兴新支点Linux桌面操作系统,中兴新支点Linux桌面操作系统,小白也能轻松上手...
- 10愿我能陪你颠沛流离
前端面试题带答案_京累真94ff16
赞
踩
- css的居中方式
答:
1.1 内联元素水平居中
利用 text-align: center 可以实现在块级元素内部的内联元素水平居中。此方法对内联元素(inline), 内联块(inline-block), 内联表(inline-table), inline-flex元素水平居中都有效。
代码如下:
-
center-text{ -
Text-aling:center; -
}
1.2 块级元素水平居中
通过把固定宽度块级元素的margin-left和margin-right设成auto,就可以使块级元素水平居中。
核心代码:
-
center-block{ -
margin: 0 auto; -
}
1.3 多块级元素水平居中
1.3.1 利用inline-block
如果一行中有两个或两个以上的块级元素,通过设置块级元素的显示类型为inline-block和父容器的text-align属性从而使多块级元素水平居中。
核心代码:
-
.container { -
text-align: center; -
} -
.inline-block { -
display: inline-block; -
}
1.3.2 利用display: flex
利用弹性布局(flex),实现水平居中,其中justify-content 用于设置弹性盒子元素在主轴(横轴)方向上的对齐方式,本例中设置子元素水平居中显示。
核心代码:
.
-
flex-center { -
display: flex; -
justify-content: center; -
}
2 垂直居中
2.1 单行内联(inline-)元素垂直居中
通过设置内联元素的高度(height)和行高(line-height)相等,从而使元素垂直居中。
核心代码:
#v-box {
height: 120px;
line-height: 120px;
}
2.2 多行元素垂直居中
2.2.1 利用表布局(table)
利用表布局的vertical-align: middle可以实现子元素的垂直居中。
核心代码:
.center-table {
display: table;
}
.v-cell {
display: table-cell;
vertical-align: middle;
}
2.2.2 利用flex布局(flex)
利用flex布局实现垂直居中,其中flex-direction: column定义主轴方向为纵向。因为flex布局是CSS3中定义,在较老的浏览器存在兼容性问题。
核心代码:
.center-flex {
display: flex;
flex-direction: column;
justify-content: center;
}
2.2.3 利用“精灵元素”
利用“精灵元素”(ghost element)技术实现垂直居中,即在父容器内放一个100%高度的伪元素,让文本和伪元素垂直对齐,从而达到垂直居中的目的。
核心代码:
.ghost-center {
position: relative;
}
.ghost-center::before {
content: " ";
display: inline-block;
height: 100%;
width: 1%;
vertical-align: middle;
}
.ghost-center p {
display: inline-block;
vertical-align: middle;
width: 20rem;
}
2.3 块级元素垂直居中
2.3.1 固定高度的块级元素
我们知道居中元素的高度和宽度,垂直居中问题就很简单。通过绝对定位元素距离顶部50%,并设置margin-top向上偏移元素高度的一半,就可以实现垂直居中了。
核心代码:
.parent {
position: relative;
}
.child {
position: absolute;
top: 50%;
height: 100px;
margin-top: -50px;
}
2.3.2 未知高度的块级元素
当垂直居中的元素的高度和宽度未知时,我们可以借助CSS3中的transform属性向Y轴反向偏移50%的方法实现垂直居中。但是部分浏览器存在兼容性的问题。
核心代码:
.parent {
position: relative;
}
.child {
position: absolute;
top: 50%;
transform: translateY(-50%);
}
3 水平垂直居中
3.1 固定宽高元素水平垂直居中
通过margin平移元素整体宽度的一半,使元素水平垂直居中。
核心代码:
.parent {
position: relative;
}
.child {
width: 300px;
height: 100px;
padding: 20px;
position: absolute;
top: 50%;
left: 50%;
margin: -70px 0 0 -170px;
}
3.2 未知宽高元素水平垂直居中
利用2D变换,在水平和垂直两个方向都向反向平移宽高的一半,从而使元素水平垂直居中。
核心代码:
.parent {
position: relative;
}
.child {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
3.3 利用flex布局
利用flex布局,其中justify-content 用于设置或检索弹性盒子元素在主轴(横轴)方向上的对齐方式;而align-items属性定义flex子项在flex容器的当前行的侧轴(纵轴)方向上的对齐方式。
核心代码:
.parent {
display: flex;
justify-content: center;
align-items: center;
}
3.4 利用grid布局
利用grid实现水平垂直居中,兼容性较差,不推荐。
核心代码:
.parent {
height: 140px;
display: grid;
}
.child {
margin: auto;
}
3.5 屏幕上水平垂直居中
屏幕上水平垂直居中十分常用,常规的登录及注册页面都需要用到。要保证较好的兼容性,还需要用到表布局。
核心代码:
.outer {
display: table;
position: absolute;
height: 100%;
width: 100%;
}
.middle {
display: table-cell;
vertical-align: middle;
}
.inner {
margin-left: auto;
margin-right: auto;
width: 400px;
}
2、px,em,rem,%
答:
1.px(像素)
px单位的名称为像素,它是一个固定大小的单元,像素的计算是针对(电脑/手机)屏幕的,一个像素(1px)就是(电脑/手机)屏幕上的一个点,即屏幕分辨率的最小分割。由于它是固定大小的单位,单独用它来设计的网页,如果适应大屏幕(电脑),在小屏幕(手机)上就会很不友好,做不到自适应的效果。
2.em(相对长度单位)
em单位用的也比较多,特别是国外;em单位的名称为相对长度单位,它是用来设置文本的字体尺寸的,相对于父级元素对象内文本的字体尺寸;如果没有人为设置当前对象内文本的字体尺寸,那么它相对的是浏览器默认的字体尺寸(16px)。
3.rem(css3新增的相对长度单位)
rem是css3新增的一个相对长度单位,它的出现是为了解决em的缺点,em可以说是相对于父级元素的字体大小,当父级元素字体大小改变时,又得重新计算。rem出现就可以解决这样的问题,rem只相对于根目录,即HTML元素。所以只要在html标签上设置字体大小,文档中的字体大小都会以此为参照标准,一般用于自适应布局。
4.%(百分比)
%也很常见,它和em差不多一样,都是相对于父级元素。但%可以在很多属性中使用,比如:width、height、font-size等。而em是用来设置字体大小(font-size)的单位,width、height等属性是没有em单位的。
px、em、rem和%的区别与总结:
1.px是固定长度单位,不随其它元素的变化而变化;
2.em和%是相对于父级元素的单位,会随父级元素的属性(font-size或其它属性)变化而变化;
3.rem是相对于根目录(HTML元素)的,所有它会随HTML元素的属性(font-size)变化而变化;
4.px和%用的比较广泛一些,可以充当更多属性的单位,而em和rem是字体大小的单位,用于充当font-size属性的单位
5.一般来说:1em = 1rem = 100% = 16 px
3.display的值和作用
答:

4、路由跳转的方式
答:
1. router-link
1. 不带参数
<router-link :to="{name:'home'}">
<router-link :to="{path:'/home'}"> //name,path都行, 建议用name
// 注意:router-link中链接如果是'/'开始就是从根路由开始,如果开始不带'/',则从当前路由开始。
2.带参数
<router-link :to="{name:'home', params: {id:1}}">
// params传参数 (类似post)
// 路由配置 path: "/home/:id" 或者 path: "/home:id"
// 不配置path ,第一次可请求,刷新页面id会消失
// 配置path,刷新页面id会保留
// html 取参 $route.params.id
// script 取参 this.$route.params.id
<router-link :to="{name:'home', query: {id:1}}">
// query传参数 (类似get,url后面会显示参数)
// 路由可不配置
// html 取参 $route.query.id
// script 取参 this.$route.query.id
2. this.$router.push() (函数里面调用)
1. 不带参数
this.$router.push('/home')
this.$router.push({name:'home'})
this.$router.push({path:'/home'})
2. query传参
this.$router.push({name:'home',query: {id:'1'}})
this.$router.push({path:'/home',query: {id:'1'}})
// html 取参 $route.query.id
// script 取参 this.$route.query.id
3. params传参
this.$router.push({name:'home',params: {id:'1'}}) // 只能用 name
// 路由配置 path: "/home/:id" 或者 path: "/home:id" ,
// 不配置path ,第一次可请求,刷新页面id会消失
// 配置path,刷新页面id会保留
// html 取参 $route.params.id
// script 取参 this.$route.params.id
4. query和params区别
query类似 get, 跳转之后页面 url后面会拼接参数,类似?id=1, 非重要性的可以这样传, 密码之类还是用params刷新页面id还在
params类似 post, 跳转之后页面 url后面不会拼接参数 , 但是刷新页面id 会消失
3. this.$router.replace() (用法同上,push)
4. this.$router.go(n) ()
this.$router.go(n)
向前或者向后跳转n个页面,n可为正整数或负整数
ps : 区别
this.$router.push
跳转到指定url路径,并想history栈中添加一个记录,点击后退会返回到上一个页面
this.$router.replace
跳转到指定url路径,但是history栈中不会有记录,点击返回会跳转到上上个页面 (就是直接替换了当前页面)
this.$router.go(n)
向前或者向后跳转n个页面,n可为正整数或负整数
5、vue生命周期的理解
答:
按照官方图解来理解,这里不得不提到钩子函数,那么钩子函数的定义如下
生命钩子函数:
我认为,钩子就是随时可能或者有需要时挂到什么东西上,从而引发一些流血事件的发生。显而易见,vue中的生命钩子函数,就是随时或者说在达到某一阶段或条件时去触发的函数,目的就是为了完成一些动作或者事件。需要注意的是,所有的生命周期钩子自动绑定 this 上下文到实例中,因此你可以访问数据,对属性和方法进行运算。
简单来说钩子函数其实和回调是一个概念,当系统执行到某处时,检查是否有hook,有则回调。说的更直白一点,每个组件都有属性,方法和事件。所有的生命周期都归于事件,在某个时刻自动执行。
在谈到Vue的生命周期的时候,我们首先需要创建一个实例,也就是在 new Vue ( ) 的对象过程当中,首先执行了init(init是vue组件里面默认去执行的),在init的过程当中首先调用了beforeCreate,然后在injections(注射)和reactivity(反应性)的时候,它会再去调用created。所以在init的时候,事件已经调用了,我们在beforeCreate的时候千万不要去修改data里面赋值的数据,最早也要放在created里面去做(添加一些行为)。

当created完成之后,它会去判断instance(实例)里面是否含有“el”option(选项),如果没有的话,它会调用vm.$mount(el)这个方法,然后执行下一步;如果有的话,直接执行下一步。紧接着会判断是否含有“template”这个选项,如果有的话,它会把template解析成一个render function ,这是一个template编译的过程,结果是解析成了render函数:
render (h) {
return h('div', {}, this.text)
}
解释一下,render函数里面的传参h就是Vue里面的createElement方法,return返回一个createElement方法,其中要传3个参数,第一个参数就是创建的div标签;第二个参数传了一个对象,对象里面可以是我们组件上面的props,或者是事件之类的东西;第三个参数就是div标签里面的内容,这里我们指向了data里面的text。
使用render函数的结果和我们之前使用template解析出来的结果是一样的。render函数是发生在beforeMount和mounted之间的,这也从侧面说明了,在beforeMount的时候,$el还只是我们在HTML里面写的节点,然后到mounted的时候,它就把渲染出来的内容挂载到了DOM节点上。这中间的过程其实是执行了render function的内容。
在使用.vue文件开发的过程当中,我们在里面写了template模板,在经过了vue-loader的处理之后,就变成了render function,最终放到了vue-loader解析过的文件里面。这样做有什么好处呢?原因是由于在解析template变成render function的过程,是一个非常耗时的过程,vue-loader帮我们处理了这些内容之后,当我们在页面上执行vue代码的时候,效率会变得更高。
beforeMount在有了render function的时候才会执行,当执行完render function之后,就会调用mounted这个钩子,在mounted挂载完毕之后,这个实例就算是走完流程了。
后续的钩子函数执行的过程都是需要外部的触发才会执行。比如说有数据的变化,会调用beforeUpdate,然后经过Virtual DOM,最后updated更新完毕。当组件被销毁的时候,它会调用beforeDestory,以及destoryed。
加分项
在这个过程当中,Vue为我们提供了renderError方法,这个方法只有在开发的时候它才会被调用,在正式打包上线的过程当中,它是不会被调用的。它主要是帮助我们调试render里面的一些错误。
renderError (h, err) {
return h('div', {}, err.stack)
}
有且只有当render方法里面报错了,才会执行renderError方法。
所以我们主动让render函数报个错:
render (h) {
throw new TypeError('render error')
}
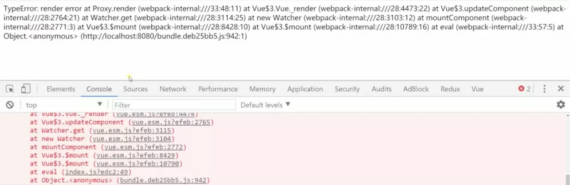
如图所示,渲染出来的就是Error信息了。还有一点,renderError只有在本组件的render方法报错的情况下它才会被调用。
6、vue数据双向绑定的原理,用了什么设计模式(web高级)
答:
什么是数据响应式?
数据响应式即数据双向绑定,就是把Model绑定到view,当我们通过js修改Model,View会自动更新;若我们更新了View,Model的数据也会自动更新,这就是双向绑定。
数据响应式原理
vue数据双向绑定是通过数据劫持结合发布者-订阅者模式的方式来实现的,
那么vue是如果进行数据劫持的???
1)vue2.0版本是利用了Object.defineProperty()这个方法重新定义对象获取属性值的get和设置属性值set的操作来实现的。
2)vue3.0版本采用了Es6的Proxy对象来实现。
我们先分别了解下defineProperty方法、Proxy对象。
什么是defineProperty?
defineProperty简言之,是定义对象的属性。它可以来控制一个对象属性的一些特有操作,比如读写权、是否可以枚举等。
它其实并不是核心的为一个对象做数据绑定,而是给对象做属性标签。定义对象的属性。只不过是属性的get和set实现了响应式。

接下来,我们先研究下它对应的两个描述属性get和set。在平常,我们很容易就可以打印出一个对象的属性数据:
var person = {
name: '小白'
};
console.log(person.name); // 小白
如果想要在执行console.log(person.name)的同时,直接给书名加个书名号,那要怎么处理呢?或者说要通过什么监听对象 person 的属性值。
这时候Object.defineProperty( )就派上用场了,代码如下:
var person = {
name: '小白'
}
var value = person.name
Object.defineProperty(person, 'name', {
set: function (newValue) {
value = newValue
return '名字是' + value;
},
get: function () {
return '***' + value + '***'
}
})

我们通过Object.defineProperty( )设置了对象person的name属性,对其get和set进行重写操作。
顾名思义,get就是在读取name属性这个值触发的函数,set就是在设置name属性这个值触发的函数。
实现一个简单完整版的mvvm双向绑定代码。
-
<!DOCTYPE html> -
<html> -
<head> -
<meta charset="utf-8"> -
<meta name="viewport" content="width=device-width, initial-scale=1.0, user-scalable=0, minimum-scale=1.0, maximum-scale=1.0"> -
<title>vuetest</title> -
</head> -
<body> -
<div id="app"> -
<input v-model="text" id="test"></input> -
<div id="show"></div> -
</div> -
<!-- built files will be auto injected --> -
</body> -
<script> -
var obj = { -
a:1, -
b:2 -
}; -
var _value = obj.a -
Object.defineProperty(obj,'a',{ -
get:function(){ -
console.log("get方法") -
return _value -
}, -
set:function(newValue){ -
console.log("set方法") -
_value = newValue -
document.getElementById('test').value =_value -
document.getElementById('show').innerHTML =_value -
return _value -
} -
}); -
document.getElementById('test').addEventListener('input',function(e){ -
obj.a = e.target.value; -
}) -
</script> -
</html>
Object.defineProperty的缺点:
无法监控到数组下标的变化,导致直接通过数组的下标给数组设置值,不能实时响应。
(详见此链接)https://www.cnblogs.com/YikaJ/p/4278255.html
所以vue才设置了7个变异数组(push、pop、shift、unshift、splice、sort、reverse)的 hack 方法来解决问题。
只能劫持对象的属性,因此我们需要对每个对象的每个属性进行遍历。如果能直接劫持一个对象,就不需要递归 + 遍历了
监听数组的改变
1)先拷贝一份数组原型链
2)定义一个方法总类
3)遍历数组,给数组原型链重新写方法,然后触发更新 dep.notify

proxy代理
Proxy对象用于定义基本操作的自定义行为,和defineProperty功能类似,只不过用法有些不同
上述例子,用Proxy来替换defineProperty进行数据劫持
var proxyObj = new Proxy(obj, {
get:function(target, key, receiver){ //我们在这里拦截到了数据
console.log("get方法",target,key,receiver)
return true
},
set:function(target,key,value, receiver){ //改变数据的值,拦截下来额
console.log("set方法",target,key,value, receiver)
target[key]= value
document.getElementById('test').value= value
document.getElementById('show').innerHTML=value
return true
}
})
document.getElementById('test').addEventListener('input',function(e){
proxyObj.a = e.target.value;
})
为什么vue3中改用proxy
1)defineProperty只能监听某个属性,不能对全对象监听,所以可以省去for in 提升效率
2)可以监听数组,不用再去单独对数组做操作
3)Proxy只是代理了原对象,不会污染原对象
那么,在vue中从一个数据到发生改变的过程是什么?
发布者-订阅者模式


Observer是个监听器,用来监听vue中的data中定义的属性。
通过Obeject.defineProperty()来监听数据的变动,通过递归方法遍历所有属性值。如果属性发上变化了,会通知给对应的dep。
Dep 在监听器Observer和订阅者Watcher之间进行统一管理的。
主要的作用就是收集观察者Watcher和通知观察者目标更新。每个属性拥有自己的消息订阅器dep,Dep实例里面存放所有订阅了该属性的观察者对象,
当数据发生改变时,会遍历订阅者列表(dep.subs),通过dep.notify()通知Watcher。
depend 实例方法用来收集依赖,notify 实例方法用来触发依赖的执行。经过了 depend => watcher.addDep => addSub (watcher 表示 Watcher 的一个实例)之后,subs 中收集的依赖实际上都是 Watcher 实例,再经过 notify => watcher.update 之后就可以触发实例化 Watcher 时的渲染函数和回调函数(如果有)的执行了。
Watcher类主要用来收集依赖和触发更新。 主要作用是为观察属性提供回调函数以及收集依赖(如计算属性computed,vue会把该属性所依赖数据的dep添加到自身的deps中),
Compile是指令解析器,解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数
被监听的数据进行取值操作时(getter),如果存在Dep.target(某一个观察者),则说明这个观察者是依赖该数据的(如计算属性中,计算某一属性会用到其他已经被监听的数据,就说该属性依赖于其他属性,会对其他属性进行取值),就会把这个观察者添加到该数据的订阅器subs里面,留待后面数据变更时通知(会先通过观察者id判断订阅器中是否已经存在该观察者),同时该观察者也会把该数据的订阅器dep添加到自身deps中,方便其他地方使用。
被监听的数据进行赋值操作时(setter)时,就会触发dep.notify(),循环该数据订阅器中的观察者,进行更新操作。
为什么要进行依赖收集?
-
new Vue({ -
data(){ -
return { -
name:'zane', -
sex:'男' -
} -
} -
})
假设页面只使用到了name,并没有使用sex,根据Object.defineProperty的转换,如果我们设置了this.sex='女',那么Vue也会去执行一遍虚拟DOM的比较,
这样就无形的浪费了一些性能,因此才需要做依赖收集,页面用到了就收集,没有用到就不收集。
首先根据上图实现整体的一个架构,用到订阅发布者的设计模式。
然后实现MVVM中的由M到V,把模型里面的数据绑定到视图。
最后实现V-M,当文本框输入文本,触发更改模型中的数据,及更新相对应的视图。
我们可以先来看一下通过控制台输出一个定义在vue初始化数据上的对象是个什么东西。
-
<div id="app"> -
<input v-model="text" id="test"></input> -
<div id="show"></div> -
</div> -
class Vue{ -
constructor(options){ -
console.log(options) -
} -
} -
const app = new Vue({ -
el: '#app', -
data:{ -
text: 'test' -
} -
})
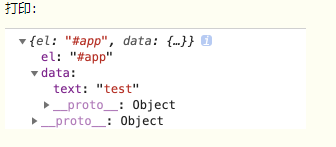
-
var Observer = function Observer (value) { -
this.value = value; -
this.dep = new Dep(); -
this.vmCount = 0; -
def(value, '__ob__', this); -
if (Array.isArray(value)) { -
if (hasProto) { -
protoAugment(value, arrayMethods); -
} else { -
copyAugment(value, arrayMethods, arrayKeys); -
} -
this.observeArray(value); -
} else { -
this.walk(value); -
} -
}; -
/** -
* Walk through all properties and convert them into -
* getter/setters. This method should only be called when -
* value type is Object. -
* 即浏览所有属性并将其转换为get/set。仅当值类型为“对象”时才应调用此方法。 -
*/ -
Observer.prototype.walk = function walk (obj) { -
var keys = Object.keys(obj); -
for (var i = 0; i < keys.length; i++) { -
defineReactive$$1(obj, keys[i]); -
} -
}; -
/** -
* Observe a list of Array items. -
* 即观察数组项列表 -
*/ -
Observer.prototype.observeArray = function observeArray (items) { -
for (var i = 0, l = items.length; i < l; i++) { -
observe(items[i]); -
} -
};
设计模式
1、装饰者模式
在不改变对象自身的基础上,在程序运行期间给对象动态的添加职责
2、观察者模式(有时也称为发布-订阅模式)
观察者模式是一种行为型模式,主要用于处理不同对象
之间的交互通信问题。观察者模式中通常会包含两类对象。
一个或多个发布者对象:当有重要的事情发生时,会通知订阅者。
一个或多个订阅者对象:它们追随一个或多个发布者,监听它们的通知,并作出
相应的反应
7、数组去重
答:一、利用ES6 Set去重(ES6中最常用)
-
function unique (arr) { -
return Array.from(new Set(arr)) -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {}, {}]
不考虑兼容性,这种去重的方法代码最少。这种方法还无法去掉“{}”空对象,后面的高阶方法会添加去掉重复“{}”的方法。
二、利用for嵌套for,然后splice去重(ES5中最常用)
-
function unique(arr){ -
for(var i=0; i<arr.length; i++){ -
for(var j=i+1; j<arr.length; j++){ -
if(arr[i]==arr[j]){ //第一个等同于第二个,splice方法删除第二个 -
arr.splice(j,1); -
j--; -
} -
} -
} -
return arr; -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
//[1, "true", 15, false, undefined, NaN, NaN, "NaN", "a", {…}, {…}] //NaN和{}没有去重,两个null直接消失了
三、利用indexOf去重
-
function unique(arr) { -
if (!Array.isArray(arr)) { -
console.log('type error!') -
return -
} -
var array = []; -
for (var i = 0; i < arr.length; i++) { -
if (array .indexOf(arr[i]) === -1) { -
array .push(arr[i]) -
} -
} -
return array; -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
// [1, "true", true, 15, false, undefined, null, NaN, NaN, "NaN", 0, "a", {…},{…}] //NaN、{}没有去重
新建一个空的结果数组,for 循环原数组,判断结果数组是否存在当前元素,如果有相同的值则跳过,不相同则push进数组。(个人认为对于初学者来讲这是目前最易懂的方法)
四、利用sort()
-
function unique(arr) { -
if (!Array.isArray(arr)) { -
console.log('type error!') -
return; -
} -
arr = arr.sort() -
var arrry= [arr[0]]; -
for (var i = 1; i < arr.length; i++) { -
if (arr[i] !== arr[i-1]) { -
arrry.push(arr[i]); -
} -
} -
return arrry; -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
// [0, 1, 15, "NaN", NaN, NaN, {…}, {…}, "a", false, null, true, "true", undefined] //NaN、{}没有去重
利用sort()排序方法,然后根据排序后的结果进行遍历及相邻元素比对。
五、利用对象的属性不能相同的特点进行去重
-
function unique(arr) { -
if (!Array.isArray(arr)) { -
console.log('type error!') -
return -
} -
var arrry= []; -
var obj = {}; -
for (var i = 0; i < arr.length; i++) { -
if (!obj[arr[i]]) { -
arrry.push(arr[i]) -
obj[arr[i]] = 1 -
} else { -
obj[arr[i]]++ -
} -
} -
return arrry; -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
//[1, "true", 15, false, undefined, null, NaN, 0, "a", {…}] //两个true直接去掉了,NaN和{}去重
六、利用includes
-
function unique(arr) { -
if (!Array.isArray(arr)) { -
console.log('type error!') -
return -
} -
var array =[]; -
for(var i = 0; i < arr.length; i++) { -
if( !array.includes( arr[i]) ) {//includes 检测数组是否有某个值 -
array.push(arr[i]); -
} -
} -
return array -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}] //{}没有去重
七、利用hasOwnProperty
-
function unique(arr) { -
var obj = {}; -
return arr.filter(function(item, index, arr){ -
return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true) -
}) -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}] //所有的都去重了
利用hasOwnProperty 判断是否存在对象属性
八、利用filter
-
function unique(arr) { -
return arr.filter(function(item, index, arr) { -
//当前元素,在原始数组中的第一个索引==当前索引值,否则返回当前元素 -
return arr.indexOf(item, 0) === index; -
}); -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
//[1, "true", true, 15, false, undefined, null, "NaN", 0, "a", {…}, {…}]
九、利用递归去重
-
function unique(arr) { -
var array= arr; -
var len = array.length; -
array.sort(function(a,b){ //排序后更加方便去重 -
return a - b; -
}) -
function loop(index){ -
if(index >= 1){ -
if(array[index] === array[index-1]){ -
array.splice(index,1); -
} -
loop(index - 1); //递归loop,然后数组去重 -
} -
} -
loop(len-1); -
return array; -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
//[1, "a", "true", true, 15, false, 1, {…}, null, NaN, NaN, "NaN", 0, "a", {…}, undefined]
十、利用Map数据结构去重
-
function arrayNonRepeatfy(arr) { -
let map = new Map(); -
let array = new Array(); // 数组用于返回结果 -
for (let i = 0; i < arr.length; i++) { -
if(map .has(arr[i])) { // 如果有该key值 -
map .set(arr[i], true); -
} else { -
map .set(arr[i], false); // 如果没有该key值 -
array .push(arr[i]); -
} -
} -
return array ; -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)) -
//[1, "a", "true", true, 15, false, 1, {…}, null, NaN, NaN, "NaN", 0, "a", {…}, undefined]
创建一个空Map数据结构,遍历需要去重的数组,把数组的每一个元素作为key存到Map中。由于Map中不会出现相同的key值,所以最终得到的就是去重后的结果。
十一、利用reduce+includes
-
function unique(arr){ -
return arr.reduce((prev,cur) => prev.includes(cur) ? prev : [...prev,cur],[]); -
} -
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}]; -
console.log(unique(arr)); -
// [1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}]
十二、[...new Set(arr)]
[...new Set(arr)] //代码就是这么少----(其实,严格来说并不算是一种,相对于第一种方法来说只是简化了代码)8、统计字符串中出现最多的字符
答:
let str = "aabbccdd", 统计字符串中出现最多的字母
方法一
关键方法为 String.prototype.charAt
核心理念为:先遍历字符串中所有字母,统计字母以及对应显示的次数,最后是进行比较获取次数最大的字母。
-
/** * 获取字符串中出现次数最多的字母 * @param {String} str */ -
function getChar(str) { if (typeof str !== 'string') return // 判断参数是否为字符串 -
const obj = new Object() // 键为字母,值为次数 -
for (let i = 0; i < str.length; i ++) { // 遍历字符串每一个字母 -
let char = str.charAt(i) // 当前字母 -
obj[char] = obj[char] || 0 // 保证初始值为0 -
obj[char] ++ // 次数加1 -
} -
let maxChar // 存储字母 -
let maxNum = 0 // maxChar字母对应的次数 -
for(let key in obj) { // 遍历obj -
if (obj[key] > maxNum) { maxChar = key // 比较后存储次数多的字母 -
maxNum = obj[key] // 以及它对应的次数 -
} -
} return maxChar // 返回结果 -
} let str = 'aabbbccdd' -
console.log('出现次数最多的字母为:' + getChar(str))
方法二
关键方法为 String.prototype.split
逻辑和方法一相同,只不过是通过 split 直接把字符串先拆成数组。效率上要比方法一差。
-
/** * 获取字符串中出现次数最多的字母 * @param {String} str */ -
function getChar(str) { if (typeof str !== 'string') return // 判断参数是否为字符串 -
const obj = new Object() // 键为字母,值为次数 -
const arr = str.split('') for (let i = 0; i < arr.length; i++) { // 遍历字符串每一个字母 -
let char = arr[i] // 当前字母 -
obj[char] = obj[char] || 0 // 保证初始值为0 -
obj[char]++ // 次数加1 -
} -
let maxChar // 存储字母 -
let maxNum = 0 // maxChar字母对应的次数 -
for (let key in obj) { // 遍历obj -
if (obj[key] > maxNum) { maxChar = key // 比较后存储次数多的字母 -
maxNum = obj[key] // 以及它对应的次数 -
} -
} return maxChar // 返回结果 -
} -
let str = 'aabbbccdd' console.log(getChar(str))
9、js垃圾回收机制
答:
一、引用计数
引用计数回收机制是通过对一个值的引用次数进行统计,当这个值被付给一个变量时会给这个值标记为引用一次,如果这个值在被付给另外一个变量,则会给这个变量标记为引用两次。当这个值的引用次数为0时,下次垃圾回收时会把这个值进行回收。
但是引用计数垃圾回收机制有个问题,就是循环引用,导致垃圾不能被回收。
-
function problem () { -
var objectA = new Object(); -
var objectB = new Object(); -
objectA.someOtherObject = objectB; -
objectB.anotherObject = objectA; -
} -
problem();
上面为《JavaScript 高级程序设计》中的一个例子。当执行problem 函数时创建一个objectA 变量指向一个空的Object、创建一个objectB 变量执行一个空的Object。
并将objectB 的引用赋值给objectA的someOtherObject 属性,将objectA 的引用赋值给objectB的anotherObject 属性。此时两个空对象的引用数量都为2。
因此在函数执行结束后objectA 和 objectB 所指向的空对象都不能被回收,如果多次执行problem函数会导致内存中有大量的对象无法被清除。
所以此垃圾回收机制被浏览器淘汰,各浏览器选择了使用另外一个垃圾回收机制进行垃圾回收--标记清除
二、标记清除
标记清除是通过变量进入环境(即在执行预编译的时候将变量放入到作用域中)时对变量进行标记(标记为进入进入),当变量离开环境时又会被标记为离开环境。当垃圾回收时会将内存中的所有变量标记为可回收,然后再将环境中的变量和被环境中变量引用的变量的标记清除,然后对被标记的变量进行销毁和回收。
10、原型、原型链
答:
一、原型
在JavaScript中,每当定义一个函数数据类型(普通函数、类)时候,都会天生自带一个prototype属性,这个属性指向函数的原型对象,并且这个属性是一个对象数据类型的值。
让我们用一张图表示构造函数和实例原型之间的关系:
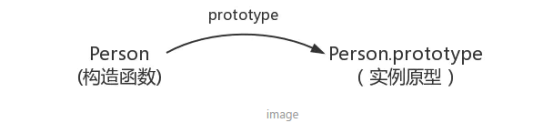
原型对象就相当于一个公共的区域,所有同一个类的实例都可以访问到这个原型对象,我们可以将对象中共有的内容,统一设置到原型对象中。
二、原型链
1.__proto__和constructor
每一个对象数据类型(普通的对象、实例、prototype......)也天生自带一个属性__proto__,属性值是当前实例所属类的原型(prototype)。原型对象中有一个属性constructor, 它指向函数对象。
-
function Person() {} -
var person = new Person() -
console.log(person.__proto__ === Person.prototype)//true -
console.log(Person.prototype.constructor===Person)//true -
//顺便学习一个ES5的方法,可以获得对象的原型 -
console.log(Object.getPrototypeOf(person) === Person.prototype) // true

2.何为原型链
在JavaScript中万物都是对象,对象和对象之间也有关系,并不是孤立存在的。对象之间的继承关系,在JavaScript中是通过prototype对象指向父类对象,直到指向Object对象为止,这样就形成了一个原型指向的链条,专业术语称之为原型链。
举例说明:person → Person → Object ,普通人继承人类,人类继承对象类
当我们访问对象的一个属性或方法时,它会先在对象自身中寻找,如果有则直接使用,如果没有则会去原型对象中寻找,如果找到则直接使用。如果没有则去原型的原型中寻找,直到找到Object对象的原型,Object对象的原型没有原型,如果在Object原型中依然没有找到,则返回undefined。
我们可以使用对象的hasOwnProperty()来检查对象自身中是否含有该属性;使用in检查对象中是否含有某个属性时,如果对象中没有但是原型中有,也会返回true
-
function Person() {} -
Person.prototype.a = 123; -
Person.prototype.sayHello = function () { -
alert("hello"); -
}; -
var person = new Person() -
console.log(person.a)//123 -
console.log(person.hasOwnProperty('a'));//false -
console.log('a'in person)//true
person实例中没有a这个属性,从 person 对象中找不到 a 属性就会从 person 的原型也就是 person.__proto__ ,也就是 Person.prototype中查找,很幸运地得到a的值为123。那假如 person.__proto__中也没有该属性,又该如何查找?
当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层Object为止。Object是JS中所有对象数据类型的基类(最顶层的类)在Object.prototype上没有__proto__这个属性。
console.log(Object.prototype.__proto__ === null) // true附上两张原型原型链的图解,看个人爱好那个容易理解用哪个


11.作用域链
作用域链用来在函数执行时求出标识符的值。该链中包含多个对象,在对标识符进行求值的过程中,会从链首的对象开始,然后依次查找后面的对象,直到在某个对象中找到与标识符名称相同的属性。如果在作用域链的顶端(全局对象)中仍然没有找到同名的属性,则返回 undefined 的属性值。
12.购物车的实现过程(包括怎么布局,可以用vue、react、jq等)
购物清单:全选、商品、数量、单价、金额、操作
删除所选商品、继续购物、去结算、绑定跟单员
Js实现淘宝购物车类似功能:
主要有添加商品
增加和减少商品数量
根据增加、减少或选择的商品获取金额
实现商品价格的计算
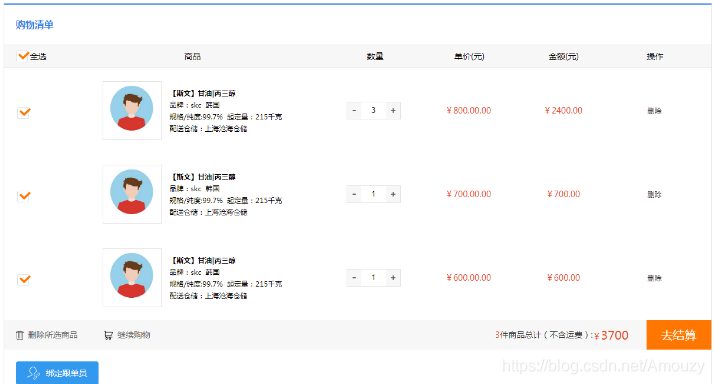
13.购物车详情页优化(用户商品加入太多导致页面卡顿)(懒加载、分页)
初始第一屏图片>获取滚动条的滚动距离和目录对象离 document 文档顶部的距离>若前者大于后者,滚动时执行加载图片的方法>按需加载图片
-
window.onload = function () { -
var lazyImg = document.getElementsByTagName("img"); -
var lazyImgLen = lazyImg.length; -
var lazyImgArray = []; -
var winowBroswerHeight = document.documentElement.clientHeight; -
// 初始第一屏图片 -
loadImg(); -
// 滚动时执行加载图片的方法 -
window.onscroll = loadImg; -
// 按需加载图片 -
function loadImg() { -
for (var i = 0; i < lazyImgLen; i++) { -
var getTD = getTopDistance(lazyImg[i]); -
var getST = getScrollTop(); -
if (!lazyImg[i].loaded && getST < getTD && getTD < (getST + winowBroswerHeight)) { -
lazyImg[i].src = lazyImg[i].getAttribute("_src"); -
lazyImg[i].classList.add("animated", "fadeIn"); -
lazyImg[i].loaded = true; // 标记为已加载 -
} -
} -
} -
// 获取目录对象离 document 文档顶部的距离 -
function getTopDistance(obj) { -
var TopDistance = 0; -
while (obj) { -
TopDistance += obj.offsetTop; -
obj = obj.offsetParent; -
} -
return TopDistance; -
} -
// 获取滚动条的滚动距离 -
function getScrollTop() { -
return document.documentElement.scrollTop || document.body.scrollTop; -
} -
}
14.页面渲染过程
渲染的流程大体是这样的:(解析html以构建dom树->解析CSS,得到CSSOM树->构建render树->布局render树->绘制render树)
详细的过程:
1:浏览器会将HTML解析成一个DOM树,DOM树的构建过程是一个深度遍历过程, 当前节点的所有子节点都构建好后才会去构建当前节点的下一个兄弟节点,
2:将CSS解析成CSS规则树;
3:根据DOM树和CSS来构造render树,渲染树不等于DOM树,像header和display:none; 这种没有具体内容的东西就不在渲染树中;
4:根据render树,浏览器可以计算出网页中有哪些节点,各节点的CSS以及从属关系, 然后可以计算出每个节点在屏幕中的位置;
5:遍历render树进行绘制页面中的各元素。
页面发生重排(回流)的话,会重新加载DOM树,影响页面加载速度。会导致页面重排的原因如下:
1:页面初始化;
2:操作DOM时;
3:某些元素的尺寸变了;
4:CSS的属性发生改变。
为什么script需要放在body的最后位置?
因为其他位置会推迟或者意外的进行预渲染。 具体原因:
解析到body中的第一脚本前,浏览器就会认为已经解析得差不多了,可以进行一次预渲染。所以script如果放在head里,会推迟预渲染。如果放在body的一开头,后面的一大堆标签还没解析,等于欺骗浏览器说已经“差不多了”,也就等于违背了设计预渲染的初衷,会影响页面的效果。放在body中间也是一样的道理,所以还是放在最尾巴上比较好。
15.闭包
函数和对其周围状态的引用捆绑在一起构成闭包。也就是说,闭包可以让你从内部函数访问外部函数作用域。在 JavaScript 中,每当函数被创建,就会在函数生成时生成闭包。
闭包很有用,因为它允许将函数与其所操作的某些数据(环境)关联起来。这显然类似于面向对象编程。因此,通常你使用只有一个方法的对象的地方,都可以使用闭包。
-
function makeAdder(x) { -
return function(y) { -
return x + y; -
}; -
} -
var add5 = makeAdder(5); -
var add10 = makeAdder(10); -
console.log(add5(2)); // 7 -
console.log(add10(2)); // 12 -
//add5 和 add10 都是闭包。它们共享相同的函数定义,但是保存了不同的词法环境。 -
在 add5 的环境中,x 为 5。而在 add10 中,x 则为 10。
16.http协议
http(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,常基于TCP的连接方式
http请求由三部分组成,分别是:请求行、消息报头、请求正文
HTTP消息报头包括普通报头、请求报头、响应报头、实体报头。
HTTP协议的主要特点可概括如下:
1.支持客户/服务器模式。
2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3.灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
5.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源
POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识
DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
17.http中的方法,除了get方法、post方法
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源 POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识 DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
18.数据结构(排序算法,冒泡以外的)
数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成 。常用的数据结构有:数组,栈,链表,队列,树,图,堆,散列表(哈希表)
十大经典算法排序总结对比:
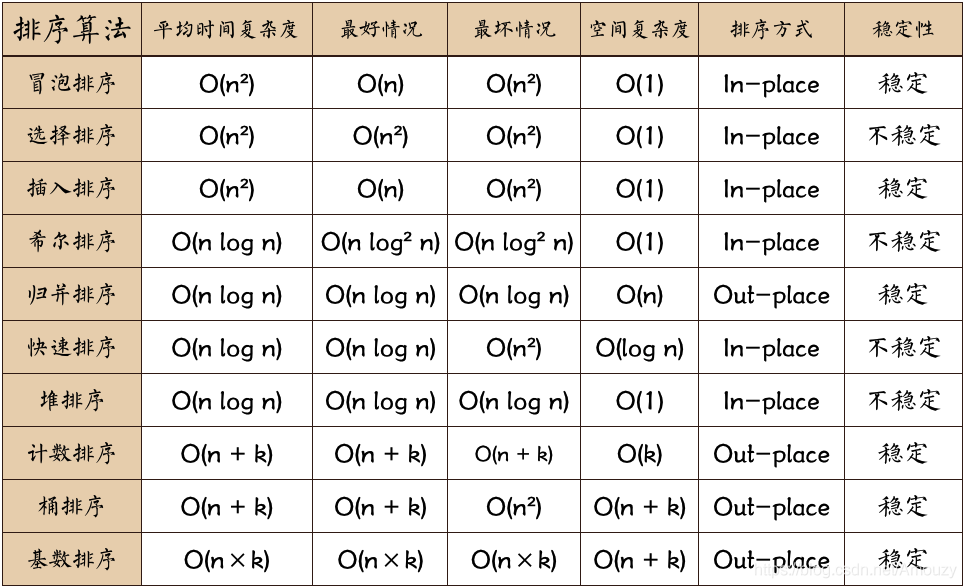
冒泡排序(正序最快,反序最慢):
-
function bubbleSort(arr) { -
var len = arr.length; -
for (var i = 0; i < len; i++) { -
for (var j = 0; j < len - 1 - i; j++) { -
if (arr[j] > arr[j+1]) { //相邻元素两两对比 -
var temp = arr[j+1]; //元素交换 -
arr[j+1] = arr[j]; -
arr[j] = temp; -
} -
} -
} -
return arr; -
}
选择排序
时间复杂度上表现最稳定的排序算法之一,因为无论什么数据进去都是O(n²)的时间复杂度
-
function selectionSort(arr) { -
var len = arr.length; -
var minIndex, temp; -
for (var i = 0; i < len - 1; i++) { -
minIndex = i; -
for (var j = i + 1; j < len; j++) { -
if (arr[j] < arr[minIndex]) { //寻找最小的数 -
minIndex = j; //将最小数的索引保存 -
} -
} -
temp = arr[i]; -
arr[i] = arr[minIndex]; -
arr[minIndex] = temp; -
} -
return arr; -
}
插入排序
-
function insertionSort(arr) { -
var len = arr.length; -
var preIndex, current; -
for (var i = 1; i < len; i++) { -
preIndex = i - 1; -
current = arr[i]; -
while(preIndex >= 0 && arr[preIndex] > current) { -
arr[preIndex+1] = arr[preIndex]; -
preIndex--; -
} -
arr[preIndex+1] = current; -
} -
return arr; -
}
希尔排序
希尔排序是插入排序的一种更高效率的实现。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列
-
function shellSort(arr) { -
var len = arr.length, -
temp, -
gap = 1; -
while(gap < len/3) { //动态定义间隔序列 -
gap =gap*3+1; -
} -
for (gap; gap > 0; gap = Math.floor(gap/3)) { -
for (var i = gap; i < len; i++) { -
temp = arr[i]; -
for (var j = i-gap; j >= 0 && arr[j] > temp; j-=gap) { -
arr[j+gap] = arr[j]; -
} -
arr[j+gap] = temp; -
} -
} -
return arr; -
}
快速排序
-
function quickSort(arr, left, right) { -
var len = arr.length, -
partitionIndex, -
left = typeof left != 'number' ? 0 : left, -
right = typeof right != 'number' ? len - 1 : right; -
if (left < right) { -
partitionIndex = partition(arr, left, right); -
quickSort(arr, left, partitionIndex-1); -
quickSort(arr, partitionIndex+1, right); -
} -
return arr; -
} -
function partition(arr, left ,right) { //分区操作 -
var pivot = left, //设定基准值(pivot) -
index = pivot + 1; -
for (var i = index; i <= right; i++) { -
if (arr[i] < arr[pivot]) { -
swap(arr, i, index); -
index++; -
} -
} -
swap(arr, pivot, index - 1); -
return index-1; -
} -
function swap(arr, i, j) { -
var temp = arr[i]; -
arr[i] = arr[j]; -
arr[j] = temp; -
}
19.vue和react的区别,用法区别
React与Vue存在很多相似之处,例如他们都是JavaScript的UI框架,专注于创造前端的富应用。最大的相似之处是虚拟DOM。Reat与Vue只有框架的骨架,其他的功能如路由、状态管理等是框架分离的组件。
1、监听数据变化的实现原理不同
Vue 通过 getter/setter 以及一些函数的劫持,能精确知道数据变化,不需要特别的优化就能达到很好的性能。 React 默认是通过比较引用的方式进行的,如果不优化(PureComponent/shouldComponentUpdate)可能导致大量不必要的VDOM的重新渲染。
2、数据流的不同
Vue中默认是支持双向绑定的。在Vue1.0中我们可以实现两种双向绑定:
1.父子组件之间,props 可以双向绑定(Vue2.x 中去掉了第一种)
2.组件与DOM之间可以通过 v-model 双向绑定
React 从诞生之初就不支持双向绑定,React一直提倡的是单向数据流,他称之为 onChange/setState()模式。
3、mixins 和 HoC
在 Vue 中我们组合不同功能的方式是通过 mixin,而在React中我们通过 HoC (高阶组件)。
4、组件通信的区别
在Vue 中有三种方式可以实现组件通信:
1.父组件通过 props 向子组件传递数据或者回调,虽然可以传递回调,但是我们一般只传数据,而通过 事件的机制来处理子组件向父组件的通信
2.子组件通过 事件 向父组件发送消息
3.通过 V2.2.0 中新增的 provide/inject 来实现父组件向子组件注入数据,可以跨越多个层级。
在 React 中,也有对应的两种方式:
1.父组件通过 props 可以向子组件传递数据或者回调
2.可以通过 context 进行跨层级的通信,这其实和 provide/inject 起到的作用差不多。
可以看到,React 本身并不支持自定义事件,Vue中子组件向父组件传递消息有两种方式:事件和回调函数,而且Vue更倾向于使用事件。但是在 React 中我们都是使用回调函数的,这可能是他们二者最大的区别。
5、模板渲染方式的不同
在表层上, 模板的语法不同
Vue是通过一种拓展的HTML语法进行渲染。
React 是通过JSX渲染模板(表面现象,毕竟React并不必须依赖JSX。);
在深层上,模板的原理不同,这才是他们的本质区别:
Vue是在和组件JS代码分离的单独的模板中,通过指令来实现的,
比如条件语句就需要 v-if 来实现。
React是在组件JS代码中,通过原生JS实现模板中的常见语法,
比如插值,条件,循环等,都是通过JS语法实现的;
React的好处:
react中render函数是支持闭包特性的,所以我们import的组件在render中可以直接调用。但是在Vue中,由于模板中使用的数据都必须挂在 this 上进行一次中转,所以我们import 一个组件完了之后,还需要在 components 中再声明下,这样显然是很奇怪但又不得不这样的做法。
6、Vuex 和 Redux 的区别
从表面上来说,store 注入和使用方式有一些区别。
在 Vuex 中,$store 被直接注入到了组件实例中,因此可以比较灵活的使用:
使用 dispatch 和 commit 提交更新;
通过 mapState 或者直接通过 this.$store 来读取数据。
在 Redux 中,我们每一个组件都需要显示的用 connect 把需要的 props 和 dispatch 连接起来。另外 Vuex 更加灵活一些,组件中既可以 dispatch action 也可以 commit updates,而 Redux 中只能进行 dispatch,并不能直接调用 reducer 进行修改。
从实现原理上来说,最大的区别是两点:
1.Redux 使用的是不可变数据,而Vuex的数据是可变的。Redux每次都是用新的state替换旧的state,而Vuex是直接修改
2.Vuex其实和Vue的原理一样,是通过 getter/setter来比较的(如果看Vuex源码会知道,其实他内部直接创建一个Vue实例用来跟踪数据变化)Redux 在检测数据变化的时候,是通过 diff 的方式比较差异的,而相比之下,Vue更偏向于简单迅速的解决问题,更灵活,不那么严格遵循条条框框。因此也会给人一种大型项目用React,小型项目用 Vue 的感觉。
20.网页上哪里可以看到请求的所有信息
审查元素>network
21.继承方法
1. 原型链继承
将构造函数的原型设置为另一个构造函数的实例对象,这样就可以继承另一个原型对象的所有属性和方法,可以继续往上,最终形成原型链。
-
// 1.原型链继承 -
/* -
缺点:所有属性被共享,而且不能传递参数 -
*/ -
function Person(name,age){ -
this.name = name -
this.age = age -
} -
Person.prototype.sayName = () =>{ -
console.log(this.name) -
} -
function Man(name){ -
} -
Man.prototype = new Person() -
Man.prototype.name = 'zhangsan' -
var zhangsan = new Man('zhangsan') -
console.log(zhangsan.name) //zhangsan
2.构造函数继承(经典继承)
-
// 构造函数继承(经典继承) -
/* -
优点:可以传递参数 -
缺点:所有方法都在构造函数内,每次创建对象都会创建对应的方法,大大浪费内存 -
*/ -
function Perent(name,age,sex){ -
this.name = name -
this.age = age -
this.sex = sex -
this.sayName = function(){ -
console.log(this.name) -
} -
} -
function Child(name,age,sex){ -
Perent.call(this,name,age,sex) -
} -
let child = new Child('lisi' , 18, '男') -
console.log(child) //Child { name: 'lisi', age: 18, sex: '男', sayName: [Function] }
3.组合方式继承(构造函数 + 原型链)
-
// 3.组合模式(构造函数 + 原型链) -
/* -
这种方式充分利用了原型链与构造函数各自的优点,是JS中最常用的继承方法 -
*/ -
function Animal(name,age){ -
this.name = name -
this.age = age -
} -
Animal.prototype.sayName = function () { -
console.log(this.name) -
} -
function Cat(name,age,color){ -
Animal.call(this,name,age) -
this.color = color -
} -
Cat.prototype = Animal.prototype //将Cat的原型指向Animal的原型 -
Cat.prototype.constructor = Cat //将Cat的构造函数指向Cat -
let cat = new Cat('xiaobai',3,'white') -
console.log(cat) //Cat { name: 'xiaobai', age: 3, color: 'white' } -
cat.sayName() //xiaobai
4.es6方法继承
-
// 4.es6继承方法 -
class Per { -
constructor(name){ -
this.name = name -
} -
sayName(){ -
console.log(this.name) -
} -
} -
class Son extends Per{ -
constructor(name,age){ -
super(name) -
this.age = age -
} -
} -
let son = new Son('zhangsan',18) -
console.log(son) //Son { name: 'zhangsan', age: 18 } -
son.sayName() //zhangsan
22.团队合作的经验
做技术和做管理这两种角色的区别
暂且抛开技能层面的东西不说,我认为要成为优秀的技术人员,最重要的是要知道和善于发挥自己的长处,很多优秀的技术牛人熟知并且善于此道,所以牛人往往有个性,因为他们的特点和长处鲜明。而作为合格的管理者呢?最重要的不是发挥自己的长处和宣扬自己的个性,而是要看到自己的短处,要磨圆自身,在此之上,要知道和善于发挥他人的长处,容忍他人之短。从上面这一点来比较,可以看出技术和管理其实不是同一个维度的东西,并且也可以知道,很多优秀的技术人员有机会转为管理角色时,为什么有一段艰难的时期 —— 因为思维没能转换过来,从而技能点加得不对。
23.通宵经历
当真正进入状态的时候会很爽,但是熬夜过后的虚弱是不可忽略的,不管是对身体的伤害还是心灵,但是我只能说这真的是一个痛并快乐的体验,当然前提是有成果,不然只能是累傻小子,当代码完美运行没有bug的时候,整个人的都舒畅了。
24.课外项目
做过小的后台管理程序,什么网页的布局一些很多,做的时候很多自己的兴趣,五子棋啦飞机大战之类的
25.为什么学前端?
第一我觉得前段未来的发展前景比较不错。
第二我也很想搭建一个自己的网站,所以来进行这一方面的学习。
第三就是前段我个人认为入门的难度会低一点,想我大学学了四年的C语言C++这个东西真的是好难搞。
26.有没有参赛或者除了学校课程内容外的经验?
个人参加过全国的电子竞技大赛,获得了一个省内的名次,当时是做了一个小的机器人,来实现简单的拉伸搬运的的功能。
27.辗转相除法
辗转相除法, 又名欧几里德算法(Euclidean algorithm),是求最大公约数的一种方法。它的具体做法是:用较小数除较大数,再用出现的余数(第一余数)去除除数,再用出现的余数(第二余数)去除第一余数,如此反复,直到最后余数是0为止。如果是求两个数的最大公约数,那么最后的除数就是这两个数的最大公约数。
js代码
-
<script type="text/javascript"> -
function remainder(m,n){ -
var r = 0;//定义变量存储余数 -
while (m % n != 0){ -
r = m % n; -
m = n;//把除数 n 当做下一轮的被除数 -
n = r;//把余数 r 当做下一轮的除数 -
} -
//当余数为0时,最后一个除数就是所求的最大公约数 -
return n; -
} -
console.log(remainder(350,505)); -
</script>
28数组转字符串
示例1
下面使用 toString() 方法读取数组的值。
数组中 toString() 方法能够把每个元素转换为字符串,然后以逗号连接输出显示。
-
var a = [1,2,3,4,5,6,7,8,9,0]; //定义数组 -
var s = a.toString(); //把数组转换为字符串 -
console.log(s); //返回字符串“1,2,3,4,5,6,7,8,9,0” -
console.log(typeof s); //返回字符串string,说明是字符串类型
当数组用于字符串环境中时,JavaScript 会自动调用 toString() 方法将数组转换成字符串。在某些情况下,需要明确调用这个方法。
-
var a = [1,2,3,4,5,6,7,8,9,0]; //定义数组 -
var b = [1,2,3,4,5,6,7,8,9,0]; //定义数组 -
var s = a + b; //数组连接操作 -
console.log(s); //返回“1,2,3,4,5,6,7,8,9,01,2,3,4,5,6,7,8,9,0” -
console.log(typeof s); //返回字符串string,说明是字符串类型
toString() 在把数组转换成字符串时,首先要将数组的每个元素都转换为字符串。当每个元素都被转换为字符串时,才使用逗号进行分隔,以列表的形式输出这些字符串。
-
var a = [1,[2,3],[4,5]],[6,[7,[8,9],0]]]; //定义多维数组 -
var s = a.toString(); //把数组转换为字符串 -
console.log(S); //返回字符串“1,2,3,4,5,6,7,8,9,0”
示例2
下面使用 toLocalString() 方法读取数组的值。
toLocalString() 方法与 toString() 方法用法基本相同,主要区别在于 toLocalString() 方法能够使用用户所在地区特定的分隔符把生成的字符串连接起来,形成一个字符串。
-
var a = [1,2,3,4,5]; //定义数组 -
var s = a.toLocalString(); //把数组转换为本地字符串 -
console.log(s); //返回字符串“1,2,3,4,5,6,7,8,9,0”
示例3
下面使用 join() 方法可以把数组转换为字符串。
join() 方法可以把数组转换为字符串,不过它可以指定分隔符。在调用 join() 方法时,可以传递一个参数作为分隔符来连接每个元素。如果省略参数,默认使用逗号作为分隔符,这时与 toString() 方法转换操作效果相同。
-
var a = [1,2,3,4,5]; //定义数组 -
var s = a.join("=="); //指定分隔符 -
console.log(s); //返回字符串“1==2==3==4==5”
示例4
下面使用 split() 方法把字符串转换为数组。
split() 方法是 String 对象方法,与 join() 方法操作正好相反。该方法可以指定两个参数,第 1 个参数为分隔符,指定从哪儿进行分隔的标记;第 2 个参数指定要返回数组的长度。
-
var s = "1==2== 3==4 ==5"; -
var a = s.split("=="); -
console.log(a); -
console.log(a.constructor == Array);
.29、二级下拉菜单
-
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" -
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> -
<html xmlns="http://www.w3.org/1999/xhtml"> -
<head> -
<title>简洁大方的二级下拉菜单</title> -
<meta http-equiv="content-type" content="text/html;charset=gb2312"> -
<style type="text/css"> -
*{margin:0;padding:0;font-style:normal;font-family:宋体;} -
body{text-align:center;font-size:14px;} -
#content{margin:0 auto;width:600px;} -
#content #nav{background:#006400;height:32px;margin-top:10px;} -
#content #nav ul{list-style:none;} -
#content #nav ul li{float:left;width:100px;line-height:32px;position:relative;} -
#nav div{width:100px;position:absolute;left:0px;padding-bottom:0px;background:#006400;float:left;height:0;overflow:hidden;} -
#content #nav li .a{text-decoration:none;color:#00CD00;line-height:32px;display:block;border-right:1px solid #009800;} -
#nav div a{text-decoration:none;color:#00CD00;line-height:26px;display:block;} -
#nav div a:hover{background:#005400;} -
</style> -
</head> -
<body> -
<div id="content"> -
<div id="nav"> -
<ul id="supnav"> -
<li><a href="#" class="a">菜单项1</a> -
<div> -
<a href="#">菜单测试1</a> -
<a href="#">菜单测试1</a> -
<a href="#">菜单测试1</a> -
</div> -
</li> -
<li><a href="#" class="a">菜单项2</a> -
<div> -
<a href="#">菜单测试2</a> -
<a href="#">菜单测试2</a> -
<a href="#">菜单测试2</a> -
</div> -
</li> -
<li><a href="#" class="a">菜单项3</a> -
<div> -
<a href="#">菜单测试3</a> -
<a href="#">菜单测试3</a> -
<a href="#">菜单测试3</a> -
<a href="#">菜单测试3</a> -
<a href="#">菜单测试3</a> -
</div> -
</li> -
<li><a href="#" class="a">菜单项4</a> -
<div> -
<a href="#">菜单测试4</a> -
<a href="#">菜单测试4</a> -
<a href="#">菜单测试4</a> -
</div> -
</li> -
<li><a href="#" class="a">菜单项5</a> -
<div> -
<a href="#">菜单测试5</a> -
<a href="#">菜单测试5</a> -
<a href="#">菜单测试5</a> -
<a href="#">菜单测试5</a> -
</div> -
</li> -
<li><a href="#" class="a">菜单项6</a> -
<div> -
<a href="#">菜单测试6</a> -
<a href="#">菜单测试6</a> -
<a href="#">菜单测试6</a> -
</div> -
</li> -
</ul> -
</div> -
</div> -
<script type="text/javascript"> -
var supnav=document.getElementById("supnav"); -
var nav=document.getElementById("nav"); -
var btns=document.getElementsByTagName("li"); -
var subnavs=nav.getElementsByTagName("div"); -
var paddingbottom=20; -
var defaultHeight=0; -
function drop(obj,ivalue){ -
var a=obj.offsetHeight; -
var speed=(ivalue-obj.offsetHeight)/8; -
a+=Math.floor(speed); -
obj.style.height=a+"px"; -
} -
window.onload=function(){ -
for(var i=0;i<btns.length;i++){ -
btns[i].index=i; -
btns[i].onmouseover=function(){ -
var osubnav=subnavs[this.index]; -
var sublinks=osubnav.getElementsByTagName("a"); -
if(osubnav.firstChild.tagName==undefined){ -
var itarheight=parseInt(osubnav.childNodes[1].offsetHeight)*sublinks.length+paddingbottom; -
}else{ -
var itarheight=parseInt(osubnav.firstChild.offsetHeight)*sublinks.length+paddingbottom; -
} -
clearInterval(this.itimer); -
this.itimer=setInterval(function(){drop(osubnav,itarheight);},30); -
} -
btns[i].onmouseout=function(){ -
var osubnav=subnavs[this.index]; -
clearInterval(this.itimer); -
this.itimer=setInterval(function(){drop(osubnav,defaultHeight);},30); -
} -
} -
} -
</script> -
</body> -
</html>
30.bind() apply()
call()、apply()、bind() 都是用来重定义 this 这个对象的
call
- fn.call(所要指向的对象,参数1,参数2,…) 调用fn函数并修改this指向
apply
- fn.apply(所要指向的对象,[参数1,参数2,…]) 调用fn函数。修改this指向
bind
- bind不会直接调用函数 返回一个新的函数 修改了this指向,传参和call一样
-
let obj1={ -
name:'小明', -
age:20, -
hobby:['唱歌','跳舞'], -
score(math,english,chinese){ -
console.log(`${this.name}今年${this.age},爱好是${this.hobby[0]}和${this.hobby[1]},他的成绩是${math},${english},${chinese}`); -
} -
} -
let obj2={ -
name:'小红', -
age:18, -
hobby:['打游戏','睡觉'], -
score(math,english,chinese){ -
console.log(this.name+math); -
} -
} -
obj1.score.call(obj2,100,100,100); -
obj1.score.apply(obj2,[88,88,88]); -
let obj3=obj1.score.bind(obj2,60,60,60); -
obj3();
31.const用法
-
// 声明的是常量,值是不可以改变的(不能重新赋值),其余语法和let一样 -
const a=5000; -
// a=100; -
// stu是对象,在内存中以地址的形式存储, -
const stu={ -
name:'zs' -
} -
// 修改了数据。所以地址没有变化。不会报错 -
stu.name='ls'; -
// 重新赋值会报错。 -
stu={ -
name:'ls' -
} -
// es6中 变量的扩展 let const
32.Utf-8编码汉字占多少个字节
英文字母:
·字节数 : 1;编码:GB2312
字节数 : 1;编码:GBK
字节数 : 1;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 1;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
中文汉字:
字节数 : 2;编码:GB2312
字节数 : 2;编码:GBK
字节数 : 2;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 3;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
拓展:
为了使各国语言在更好的流通unicode码应运而生,它将世界上所有的符号都纳入其中,每一个符号都给予一个独一无二的编码,现在unicode可以容纳100多万个符号,每个符号的编码都不一样,这下可统一了,所有语言都可以互通,一个网页页面里可以同时显示各国文字。
unicode虽然统一了全世界字符的二进制编码,但没有规定如何存储啊。x86和amd体系结构的电脑小端序和大端序都分不清,别提计算机如何识别到底是unicode还是acsii了。如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,文本文件的大小会因此大出二三倍,这对于存储来说是极大的浪费。这样导致一个后果:出现了Unicode的多种存储方式。
互联网的兴起,网页上要显示各种字符,必须统一。utf-8就是Unicode最重要的实现方式之一。另外还有utf-16、utf-32等。UTF-8不是固定字长编码的,而是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。这是种比较巧妙的设计,如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
33.Vue的钩子函数
1.computed 计算属性
计算属性将被混入到 Vue 实例中。所有 getter 和 setter 的 this 上下文自动地绑定为 Vue
-
1..aPlus: { -
get: function () { -
return this.a + 1 -
}, -
set: function (v) { -
this.a = v - 1 -
} -
}2.. aPlus(){ return this.$router.params }
这两种方法都可以,平时我们可以只写get,可以写成2形式,省略set方法,但是如果我们相对我们的计算属性进行修改,这个set方法不能省略。
2.methods 方法
这里只提一下它和computed的区别
methods 和 computed 看起来可以做同样的事情,单纯看结果两种方式确实是相同的。
然而,不同的是计算属性是基于它们的依赖进行缓存的。计算属性只有在它的相关依赖发生改变
时才会重新求值。这就意味着只要 message 还没有发生改变,多次访问 reversedMessage 计算属性会
立即返回之前的计算结果,而不必再次执行函数。相比而言,只要发生重新渲染,method 调用总会执行
该函数。
3.watcher
一个对象,键是需要观察的表达式,值是对应回调函数。值也可以是方法名,或者包含选项的对象。Vue 实例将会在实例化时调用 $watch(),遍历 watch 对象的每一个属性。
-
watch: { -
a: function (val, oldVal) { -
console.log('new: %s, old: %s', val, oldVal) -
}, -
// 方法名 -
b: 'someMethod', -
// 深度 watcher -
c: { -
handler: function (val, oldVal) { /* ... */ }, -
deep: true -
}, -
// 该回调将会在侦听开始之后被立即调用 -
d: { -
handler: function (val, oldVal) { /* ... */ }, -
immediate: true -
}, -
e: [ -
function handle1 (val, oldVal) { /* ... */ }, -
function handle2 (val, oldVal) { /* ... */ } -
], -
}
这里主要说深度watcher 加一个 deep:true,类似于深拷贝的深,可以监听数组和对象。
4.生命周期函数
在vue做表格的时候,一般在操作完之后,要更新列表刷新数据。但是我们本地做一些表格的变换,不想发请求怎么办?我们可以利用nextTick,比如,<templeate v-if="tab === 'a' "></template> ,在我们更新完数据,这个表格因为没有更新数据,所以它没有变化,我们可以 this.tab = ' ' this.$nextTick(() => this.tab = 'a')
在 Vue 生命周期的 created() 钩子函数进行的 DOM 操作一定要放在 Vue.nextTick() 的回调函数中。原因是什么呢,原因是
1.在 created() 钩子函数执行的时候 DOM 其实并未进行任何渲染,而此时进行 DOM 操作无异于徒劳,所以此处一定要将 DOM 操作的 js 代码放进 Vue.nextTick() 的回调函数中。与之对应的就是 mounted 钩子函数,因为该钩子函数执行时所有的 DOM 挂载和渲染此时在该钩子函数中进行任何DOM操作都不会有问题 。
2.在数据变化后要执行的某个操作,而这个操作需要使用随数据改变而改变的 DOM 结构的时候,这个操作都应该放进 Vue.nextTick() 的回调函数中。
常用的钩子函数
beforeCreate
这个时候,this变量还不能使用,在data下的数据,和methods下的方法,watcher中的事件都不能获得到;
-
beforeCreate() { -
console.log(this.page); // undefined -
console.log{this.showPage); // undefined -
}, -
data() { -
return { -
page: '第一页' -
} -
}, -
methods: { -
showPage() { -
console.log(this.page); -
} -
}
created
这个时候可以操作vue实例中的数据和各种方法,但是还不能对"dom"节点进行操作;
-
..., -
created() { -
let btn = document.querySelector('button') -
console.log(btn.innerText) //此时找不到button节点,打印不出来button的值 -
}
mounted
这个时候挂载完毕,这时dom节点被渲染到文档内,一些需要dom的操作在此时才能正常进行。
注意:mounted在整个实例的生命周期中只执行一次。
-
..., -
mounted() { -
let btn = document.querySelector('button') -
console.log(btn.innerText) //此时可以打印出来button的值 -
}
computed
是把所有需要依赖其他值计算的值写成对象的key值。
-
data() { -
return { -
count: 1 -
} -
}, -
computed: { -
//是最后需要计算的值,而这个值依赖this.count -
//那么这个值要写在对象的key值的位置 -
countDouble: { -
get: function() { -
return this.count * 2 -
}, -
set: function(newValue) { -
this.countDouble = newValue -
} -
} -
}
这时候模板渲染的{{countDouble}}这个值是2
注意:通过计算的countDouble这个变量不需要在data里面声明,如果声明了就会报错
watch
把监听的值写成对象的key值
-
data() { -
return { -
count: 1 -
} -
}, -
watch: { -
count: (val, oldVal) => { -
console.log('new: %s, old: %s', val, oldVal) -
} -
}
这时候如果this.count发生了改变,那么监听count变量发生变化的function就会被执行
注意:需要监听的这个变量需要在data里面声明,如果不声明就会报错
34、http和https的区别
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加 密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信 息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基 础上加入了SSL/TLS协议,SSL/TLS依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
HTTPS协议是由SSL/TLS+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
HTTPS和HTTP的主要区别
https协议需要到CA申请证书,一般免费证书较少,因而需要一定费用。
http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl/tls加密传输协议。
http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
http的连接很简单,是无状态的;HTTPS协议是由SSL/TLS+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
35、前端开发工具webstorm
WebStorm是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
36、Vue基于什么语言
JavaScript
37、Vue的第三方组件库ivew
View 是一套基于 Vue.js 的 UI 组件库,主要服务于 PC 界面的中后台产品。
特性
-
高质量、功能丰富
-
友好的 API ,自由灵活地使用空间
-
使用单文件的 Vue 组件化开发模式
-
基于 npm + webpack + babel 开发,支持 ES2015
安装
使用 npm
$ npm install iview --save
或使用 <script> 全局引用
<script type="text/javascript" src="iview.min.js"></script>
-
<template> -
<Slider :value.sync="value" range></Slider> -
</template> -
<script> -
export default { -
data () { -
return { -
value: [20, 50] -
} -
} -
} -
</script>
38、HTML5的新特性
(1)语义标签
语义化标签使得页面的内容结构化,见名知义
| 标签 | 描述 |
| <hrader></header> | 定义了文档的头部区域 |
| <footer></footer> | 定义了文档的尾部区域 |
| <nav></nav> | 定义文档的导航 |
| <section></section> | 定义文档中的节(section、区段) |
| <article></article> | 定义页面独立的内容区域 |
| <aside></aside> | 定义页面的侧边栏内容 |
| <detailes></detailes> | 用于描述文档或文档某个部分的细节 |
| <summary></summary> | 标签包含 details 元素的标题 |
| <dialog></dialog> | 定义对话框,比如提示框 |
(2)增强型表单
HTML5 拥有多个新的表单 Input 输入类型。这些新特性提供了更好的输入控制和验证。
| 输入类型 | 描述 |
| color | 主要用于选取颜色 |
| date | 从一个日期选择器选择一个日期 |
| datetime | 选择一个日期(UTC 时间) |
| datetime-local | 选择一个日期和时间 (无时区) |
| | 包含 e-mail 地址的输入域 |
| month | 选择一个月份 |
| number | 数值的输入域 |
| range | 一定范围内数字值的输入域 |
| search | 用于搜索域 |
| tel | 定义输入电话号码字段 |
| time | 选择一个时间 |
| url | URL 地址的输入域 |
| week | 选择周和年 |
HTML5 也新增以下表单元素
| 表单元素 | 描述 |
| <datalist> | 元素规定输入域的选项列表 使用 <input> 元素的 list 属性与 <datalist> 元素的 id 绑定 |
| <keygen> | 提供一种验证用户的可靠方法 标签规定用于表单的密钥对生成器字段。 |
| <output> | 用于不同类型的输出 比如计算或脚本输出 |
HTML5 新增的表单属性
-
- placehoder 属性,简短的提示在用户输入值前会显示在输入域上。即我们常见的输入框默认提示,在用户输入后消失。
- required 属性,是一个 boolean 属性。要求填写的输入域不能为空
- pattern 属性,描述了一个正则表达式用于验证<input> 元素的值。
- min 和 max 属性,设置元素最小值与最大值。
- step 属性,为输入域规定合法的数字间隔。
- height 和 width 属性,用于 image 类型的 <input> 标签的图像高度和宽度。
- autofocus 属性,是一个 boolean 属性。规定在页面加载时,域自动地获得焦点。
- multiple 属性 ,是一个 boolean 属性。规定<input> 元素中可选择多个值。
(3)视频和音频
- HTML5 提供了播放音频文件的标准,即使用 <audio> 元素
-
<audio controls> -
<source src="horse.ogg" type="audio/ogg"> -
<source src="horse.mp3" type="audio/mpeg"> -
您的浏览器不支持 audio 元素。 -
</audio>
control 属性供添加播放、暂停和音量控件。
在<audio> 与 </audio> 之间你需要插入浏览器不支持的<audio>元素的提示文本 。
<audio> 元素允许使用多个 <source> 元素. <source> 元素可以链接不同的音频文件,浏览器将使用第一个支持的音频文
目前, <audio>元素支持三种音频格式文件: MP3, Wav, 和 Ogg
HTML5 规定了一种通过 video 元素来包含视频的标准方法。
-
<video width="320" height="240" controls> -
<source src="movie.mp4" type="video/mp4"> -
<source src="movie.ogg" type="video/ogg"> -
您的浏览器不支持Video标签。 -
</video>
-
control 提供了 播放、暂停和音量控件来控制视频。也可以使用dom操作来控制视频的播放暂停,如 play() 和 pause() 方法。
同时 video 元素也提供了 width 和 height 属性控制视频的尺寸.如果设置的高度和宽度,所需的视频空间会在页面加载时保留。如果没有设置这些属性,浏览器不知道大小的视频,浏览器就不能再加载时保留特定的空间,页面就会根据原始视频的大小而改变。
与 标签之间插入的内容是提供给不支持 video 元素的浏览器显示的。
video 元素支持多个source 元素. 元素可以链接不同的视频文件。浏览器将使用第一个可识别的格式( MP4, WebM, 和 Ogg)
(4)Canvas绘图
标签只是图形容器,必须使用脚本来绘制图形。
-
Canvas - 图形
- 创建一个画布,一个画布在网页中是一个矩形框,通过 <canvas> 元素来绘制。默认情况下 元素没有边框和内容。
<canvas id="myCanvas" width="200" height="100" style="border:1px solid #000000;"></canvas>-
标签通常需要指定一个id属性 (脚本中经常引用), width 和 height 属性定义的画布的大小,使用 style 属性来添加边框。你可以在HTML页面中使用多个 <canvas> 元素
- 使用Javascript来绘制图像,canvas 元素本身是没有绘图能力的。所有的绘制工作必须在 JavaScript 内部完成
-
<script> -
var c=document.getElementById("myCanvas"); -
var ctx=c.getContext("2d"); -
ctx.fillStyle="#FF0000"; -
ctx.fillRect(0,0,150,75); -
</script>
getContext("2d") 对象是内建的 HTML5 对象,拥有多种绘制路径、矩形、圆形、字符以及添加图像的方法。
设置 fillStyle 属性可以是CSS颜色,渐变,或图案。fillStyle默认设置是#000000(黑色)。fillRect(x,y,width,height) 方法定义了矩形当前的填充方式。意思是:在画布上绘制 150x75 的矩形,从左上角开始 (0,0)。
-
Canvas - 路径
在Canvas上画线,我们将使用以下两种方法:
moveTo(x,y) 定义线条开始坐标
lineTo(x,y) 定义线条结束坐标
绘制线条我们必须使用到 "ink" 的方法,就像stroke()。
-
<script> -
var c=document.getElementById("myCanvas"); -
var ctx=c.getContext("2d"); -
ctx.moveTo(0,0); -
ctx.lineTo(200,100); -
ctx.stroke(); -
</script>
定义开始坐标(0,0), 和结束坐标 (200,100). 然后使用 stroke() 方法来绘制线条
-
Canvas - 文本
使用 canvas 绘制文本,重要的属性和方法如下:
font - 定义字体
fillText(text,x,y) - 在 canvas 上绘制实心的文本
strokeText(text,x,y) - 在 canvas 上绘制空心的文本
使用 fillText():
| 1 2 3 4 |
|
使用 "Arial" 字体在画布上绘制一个高 30px 的文字(实心)
-
Canvas - 渐变
渐变可以填充在矩形, 圆形, 线条, 文本等等, 各种形状可以自己定义不同的颜色。
以下有两种不同的方式来设置Canvas渐变:
createLinearGradient(x,y,x1,y1) - 创建线条渐变
createRadialGradient(x,y,r,x1,y1,r1) - 创建一个径向/圆渐变
当我们使用渐变对象,必须使用两种或两种以上的停止颜色。
addColorStop()方法指定颜色停止,参数使用坐标来描述,可以是0至1.
使用渐变,设置fillStyle或strokeStyle的值为渐变,然后绘制形状,如矩形,文本,或一条线。
| 1 2 3 4 5 6 7 8 9 10 11 |
|
创建了一个线性渐变,使用渐变填充矩形
-
Canvas - 图像
把一幅图像放置到画布上, 使用 drawImage(image,x,y) 方法
| 1 2 3 4 |
|
把一幅图像放置到了画布上
(5)SVG绘图
SVG是指可伸缩的矢量图形
SVG 与 Canvas两者间的区别
SVG 是一种使用 XML 描述 2D 图形的语言。
Canvas 通过 JavaScript 来绘制 2D 图形。
SVG 基于 XML,这意味着 SVG DOM 中的每个元素都是可用的。您可以为某个元素附加 JavaScript 事件处理器。
在 SVG 中,每个被绘制的图形均被视为对象。如果 SVG 对象的属性发生变化,那么浏览器能够自动重现图形。
Canvas 是逐像素进行渲染的。在 canvas 中,一旦图形被绘制完成,它就不会继续得到浏览器的关注。如果其位置发生变化,那么整个场景也需要重新绘制,包括任何或许已被图形覆盖的对象。
(6)地理定位
HTML5 Geolocation(地理定位)用于定位用户的位置。
-
window.navigator.geolocation { -
getCurrentPosition: fn 用于获取当前的位置数据 -
watchPosition: fn 监视用户位置的改变 -
clearWatch: fn 清除定位监视 -
}
获取用户定位信息:
-
navigator.geolocation.getCurrentPosition( -
function(pos){ -
console.log('用户定位数据获取成功') //console.log(arguments); console.log('定位时间:',pos.timestamp) console.log('经度:',pos.coords.longitude) console.log('纬度:',pos.coords.latitude) console.log('海拔:',pos.coords.altitude) console.log('速度:',pos.coords.speed) -
}, //定位成功的回调 -
function(err){ -
console.log('用户定位数据获取失败') //console.log(arguments); -
} //定位失败的回调 -
)
(7)拖放API
拖放是一种常见的特性,即抓取对象以后拖到另一个位置。在 HTML5 中,拖放是标准的一部分,任何元素都能够拖放。
拖放的过程分为源对象和目标对象。源对象是指你即将拖动元素,而目标对象则是指拖动之后要放置的目标位置。
拖放的源对象(可能发生移动的)可以触发的事件——3个:
dragstart:拖动开始
drag:拖动中
dragend:拖动结束
整个拖动过程的组成: dragstart*1 + drag*n + dragend*1
拖放的目标对象(不会发生移动)可以触发的事件——4个:
dragenter:拖动着进入
dragover:拖动着悬停
dragleave:拖动着离开
drop:释放
整个拖动过程的组成1: dragenter*1 + dragover*n + dragleave*1
整个拖动过程的组成2: dragenter*1 + dragover*n + drop*1
dataTransfer:用于数据传递的“拖拉机”对象;
在拖动源对象事件中使用e.dataTransfer属性保存数据:
e.dataTransfer.setData( k, v )
在拖动目标对象事件中使用e.dataTransfer属性读取数据:
var value = e.dataTransfer.getData( k )
(8)Web Worker
当在 HTML 页面中执行脚本时,页面的状态是不可响应的,直到脚本已完成。
web worker 是运行在后台的 JavaScript,独立于其他脚本,不会影响页面的性能。您可以继续做任何愿意做的事情:点击、选取内容等等,而此时 web worker 在后台运行。
首先检测浏览器是否支持 Web Worker
| 1 2 3 4 5 6 |
|
下面的代码检测是否存在 worker,如果不存在,- 它会创建一个新的 web worker 对象,然后运行 "demo_workers.js" 中的代码
| 1 2 3 4 |
|
然后我们就可以从 web worker 发送和接收消息了。向 web worker 添加一个 "onmessage" 事件监听器:
| 1 2 3 |
|
当 web worker 传递消息时,会执行事件监听器中的代码。event.data 中存有来自 event.data 的数据。当我们创建 web worker 对象后,它会继续监听消息(即使在外部脚本完成之后)直到其被终止为止。
如需终止 web worker,并释放浏览器/计算机资源,使用 terminate() 方法。
(9)Web Storage
使用HTML5可以在本地存储用户的浏览数据。早些时候,本地存储使用的是cookies。但是Web 存储需要更加的安全与快速. 这些数据不会被保存在服务器上,但是这些数据只用于用户请求网站数据上.它也可以存储大量的数据,而不影响网站的性能。数据以 键/值 对存在, web网页的数据只允许该网页访问使用。
客户端存储数据的两个对象为:
-
- localStorage - 没有时间限制的数据存储
- sessionStorage - 针对一个 session 的数据存储, 当用户关闭浏览器窗口后,数据会被删除。
在使用 web 存储前,应检查浏览器是否支持 localStorage 和sessionStorage
-
if(typeof(Storage)!=="undefined") -
{ -
// 是的! 支持 localStorage sessionStorage 对象! -
// 一些代码..... -
} -
else -
{ -
// 抱歉! 不支持 web 存储。 -
}
不管是 localStorage,还是 sessionStorage,可使用的API都相同,常用的有如下几个(以localStorage为例):
-
- 保存数据:localStorage.setItem(key,value);
- 读取数据:localStorage.getItem(key);
- 删除单个数据:localStorage.removeItem(key);
- 删除所有数据:localStorage.clear();
- 得到某个索引的key:localStorage.key(index);
(10)WebSocket
WebSocket是HTML5开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。在WebSocket API中,浏览器和服务器只需要做一个握手的动作,然后,浏览器和服务器之间就形成了一条快速通道。两者之间就直接可以数据互相传送。浏览器通过 JavaScript 向服务器发出建立 WebSocket 连接的请求,连接建立以后,客户端和服务器端就可以通过 TCP 连接直接交换数据。当你获取 Web Socket 连接后,你可以通过 send() 方法来向服务器发送数据,并通过 onmessage 事件来接收服务器返回的数据。
-
<!DOCTYPE HTML> -
<html> -
<head> -
<meta charset="utf-8"> -
<title>W3Cschool教程(w3cschool.cn)</title> -
<script type="text/javascript"> -
function WebSocketTest() -
{ -
if ("WebSocket" in window) -
{ -
alert("您的浏览器支持 WebSocket!"); -
// 打开一个 web socket -
var ws = new WebSocket("ws://localhost:9998/echo"); -
ws.onopen = function() -
{ -
// Web Socket 已连接上,使用 send() 方法发送数据 -
ws.send("发送数据"); -
alert("数据发送中..."); -
}; -
ws.onmessage = function (evt) -
{ -
var received_msg = evt.data; -
alert("数据已接收..."); -
}; -
ws.onclose = function() -
{ -
// 关闭 websocket -
alert("连接已关闭..."); -
}; -
} -
else -
{ -
// 浏览器不支持 WebSocket -
alert("您的浏览器不支持 WebSocket!"); -
} -
} -
</script> -
</head> -
<body> -
<div id="sse"> -
<a href="javascript:WebSocketTest()">运行 WebSocket</a> -
</div> -
</body> -
</html>
39、ajax
Ajax 即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指一种创建交互式、快速动态网页应用的网页开发技术,无需重新加载整个网页的情况下,能够更新部分网页的技术。
通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
40.js对数组的操作,包括向数组中插入删除数据
-
var user=[]; -
1、向数组添加元素: -
user.push($(this).attr('userid')); -
push() 方法可向数组的末尾添加一个或多个元素,并返回新的长度。 -
2、删除数组中的某个元素: -
首先可以给JS的数组对象定义一个函数,用于查找指定的元素在数组中的位置,即索引 -
Array.prototype.indexOf = function(user) { -
for (var i = 0; i < this.length; i++) if (this[i] == user) return i; -
return -1; -
}; -
然后使用通过得到这个元素的索引,使用js数组自己固有的函数去删除这个元素 -
Array.prototype.remove = function(user) { -
var index = this.indexOf(user); -
if (index > -1) this.splice(index, 1); -
}; -
要删除其中的元素 -
user.remove($(this).attr('userid'));
splice() 方法用于插入、删除或替换数组的元素。
语法
arrayObject.splice(index,howmany,element1,.....,elementX)
-
<script type="text/javascript"> -
var arr = new Array(6) -
arr[0] = "A" -
arr[1] = "B" -
arr[2] = "C" -
arr[3] = "D" -
arr[4] = "E" -
document.write(arr + "<br />") -
arr.splice(2,1,"F") -
document.write(arr) -
</script> -
输出: -
A,B,C,D,E -
A,B,F,D,E

