
- 1SQL——游标_sql 游标
- 2git pull 报错 “error: The following untracked working tree files would be overwritten by merge“ 解决
- 3PMP的考试流程是怎么样的_pmpkaoshiliucheng
- 4算法与数据结构—习题5_算法与数据结构练习题
- 5解决多卡加载预训练模型时,卡0总会比其他卡多占用显存,多卡占用显存不均_多卡训练为什么占的内存多
- 6Android - 修改Jar包里面的代码_android studio 如何修改jar 包代码
- 7探索未来数据之门:AkShare - 全面开源的数据接口库
- 8sketch入门闭坑指南,UI高效设计不在话下_ui sketch
- 9我(阿朱)再说两句新零售
- 10病理切片的相关文章总结_mulgt: multi-task graph-transformer with task-awar
MySQL内存泄漏_mysql 内存泄露
赞
踩
MySQL多个版本中,包括5.7和8.0,均存在内存泄漏问题,内存持续飙高,目前尚无良好的解决方式,在线上一般安排低峰时切换后重启处理,目前可通过以下简单方式判断:
1.使用/top/free/ps在系统级确定是否有内存泄露。如有,可以从top输出确定哪一个process。
2.使用pmap工具确定process是否有memory leak。确定memory leak的原则:writeable/private (‘pmap –d’输出)如果在做重复的操作过程中一直保持稳定增长,那么一定有内存泄露。
目前暂无时间和精力详细分析内存分配相关源码,等待后续补上!
补充:
MySQL内存分配与管理(1)
MySQL的内存分配、使用、管理的模块较多,本篇文章主要针对InnoDB的内存管理、SQL层内存分配管理器MEM_ROOT和8028内存限制的新特性进行分析,同时对现阶段存在的部分问题和优化方案进行简单的描述。代码版本主要基于8025,第四部分内存限制新特性基于8028。
一、InnoDB基础内存申请
1.1 ut_allocator
在非UNIV_PFS_MEMORY模式下,UT_NEW等都是调用原始的new、delete、malloc、free等接口进行内存的申请和释放,在UNIV_PFS_MEMORY编译模式下,采用内部封装的ut_allocator分配器进行管理,加入了内存追踪等信息,可以通过PFS表进行展示。
ut_allocator可以作为std容器的内存分配(如std::map<K, V, CMP, ut_allocator>),让容器内部的内存通过innodb提供的**内存可追踪**的方式进行分配。下面分别就ut_allocator提供的不同内存分配方式作进一步介绍。
#ifdef UNIV_PFS_MEMORY#define UT_NEW(expr, key) ::new (ut_allocator<decltype(expr)>(key).allocate(1, NULL, key, false, false)) expr...#define ut_malloc(n_bytes, key) static_cast<void *>(ut_allocator<byte>(key).allocate(n_bytes, NULL, UT_NEW_THIS_FILE_PSI_KEY, false, false))...#else/* UNIV_PFS_MEMORY */#define UT_NEW(expr, key) ::new (std::nothrow) expr...#define ut_malloc(n_bytes, key) ::malloc(n_bytes)...#endif1.1.1 单块内存分配
allocate
内存申请时多分配了一块ut_new_pfx_t数据(开启PFS_MEMORY),其中保存了key、size、owner等信息
- // 比实际申请多出一块pfx的内存
- total_bytes+=sizeof(ut_new_pfx_t)
- // 申请内存
- ...
- // 返回实际内存开始的地址return (reinterpret_cast<pointer>(pfx + 1));
加入了内存分配重试机制
- for (size_t retries = 1;; retries++) {
- // 内存分配malloc/callocmalloc(); // calloc()...if (ptr != nullptr || retries >= alloc_max_retries) break;
- std::this_thread::sleep_for(std::chrono::seconds(1));
- }
deallocate
先释放pfx、再释放实际内存数据
- deallocate_trace(pfx);
- free(pfx);
reallocate
类似allocate,重新计算size、换入新的ut_new_pfx_t(pfx_old–pfx_new)
1.1.2 large内存分配
allocate_large
申请大块内存(used in buf_chunk_init())、添加pfx信息
mmap的方式没有消耗实际的物理内存,该部分的内存无法通过jemalloc等方式追踪
- pointer ptr = reinterpret_cast<pointer>(os_mem_alloc_large(&n_bytes));
- |->mmap()/shmget()、shmat()、shmctl()
- ...
- allocate_trace(n_bytes, PSI_NOT_INSTRUMENTED, pfx);
deallocate_large
释放pfx指针,释放large内存
- deallocate_trace(pfx);
- os_mem_free_large(ptr, pfx->m_size);
- |->munmap()/shmdt()
1.1.3 aligned_memory分配
在代码中实际上aligned_memory系列(aligned_pointer、aligned_array_pointer、)是做了单独的封装的,但其底层依旧是ut_alloc和ut_free,此处就不展开了。例如在log_t结构的构建中采用此方法,对齐的内存方式在IO写操作时能够和sector size匹配,提高IO效率。
1.2 mem_heap_allocator
类似ut_allocator,mem_heap_allocator也可以作为stl的allocator来使用。但要要注意的是,该类型的分配器只提供mem_heap_alloc函数进行内存的申请,没有内存的释放、复用和合并等操作。
- class mem_heap_allocator {
- ...
- pointer allocate(size_type n, const_pointer hint = nullptr){
- return (reinterpret_cast<pointer>(mem_heap_alloc(m_heap, n * sizeof(T)))); // 内存申请调用mem_heap_alloc
- }
- voiddeallocate(pointer p, size_type n){}; // 内存释放等为空操作
- ...
- }
1.2.1 mem_heap_t
数据结构
该结构结构是一个非空的内存块链表,由一个个的大小不一的mem_block_t线性连接。重点关注free_block和buf_block,某种程度上来说,这两个指针定义了实际数据存放的位置。根据申请类型的不同,数据存放在两者之一指向的内存。利用mem_heap_t进行内存分配的方式可以将多次的内存分配合并为单次进行,之后的内存请求就可以在InnoDB引擎内部进行,从而减小了频繁调用函数malloc和free带来的时间与性能的开销。
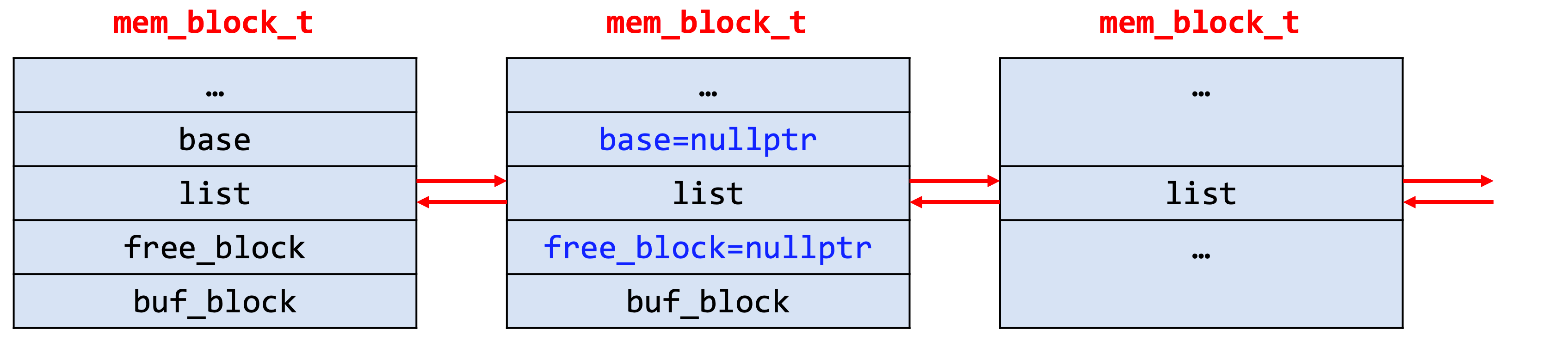
- typedefstruct mem_block_info_t mem_block_t;
- typedef mem_block_t mem_heap_t;
-
- ...
- /** The info structure stored at the beginning of a heap block */struct mem_block_info_t {
- ...
- UT_LIST_BASE_NODE_T(mem_block_t) base; /* 链表基节点,只在第一个block定义 */
- UT_LIST_NODE_T(mem_block_t) list; /* block链表 */
- ulint len; /*!< 当前block大小 */
- ulint total_size; /*!< 所有block总大小 */
- ulint type; /*!< 分配类型 */
- ulint free; /*!< 当前block的可用位置 */
- ulint start; /*!< block构建时free的起始位置(没看到较多的用途) */void *free_block; /* 包含有 MEM_HEAP_BTR_SEARCH 类型的heap中,
- heap root挂着free_block用以申请更多的空间,其他类型该指针为空 */void *buf_block; /* 内存从buffer pool申请,保存buf_block_t指针,否则为空 */
- };
内存类型
根据申请的内存来源,mem_heap_t可以分为下面几种类型:
#define MEM_HEAP_DYNAMIC 0 /* 原始申请,调用innodb内存申请ut_allocator相关 */#define MEM_HEAP_BUFFER 1 /* 从buffer_pool获取内存 */#define MEM_HEAP_BTR_SEARCH 2/* 使用free_block中的内存 */ 在此基础上,组合定义了更多的分配方式,让内存的分配更加灵活。
/** Different type of heaps in terms of which data structure is using them */#define MEM_HEAP_FOR_BTR_SEARCH (MEM_HEAP_BTR_SEARCH | MEM_HEAP_BUFFER)#define MEM_HEAP_FOR_PAGE_HASH (MEM_HEAP_DYNAMIC)#define MEM_HEAP_FOR_RECV_SYS (MEM_HEAP_BUFFER)#define MEM_HEAP_FOR_LOCK_HEAP (MEM_HEAP_BUFFER)1.2.2 mem_heap_t的构建:mem_heap_create_func
根据传入的size和heap类型,构建一个memory heap结构,size最小为64。实际上在内部的构建逻辑中可以知道单个mem_block最大的size和定义的page_size相同(一般为16K)。
创建mem_heap_t首先需要构建一个root节点,即前文所提到的链表根节点。通过控制block创建函数 mem_heap_create_block传入的第一个参数heap=nullptr,表明该block为mem_heap_t中的第一个节点。在type包含MEM_HEAP_BTR_SEARCH操作位的情况下,可能会出现构建失败的情况,详细的逻辑和失败原因会在后文提出。
创建完第一个block后,将其置为base节点,同时更新链表信息,完成mem_heap_t (根结点)的创建。

1.2.3 mem_heap_t的释放:mem_heap_free
前文提及,若type包含MEM_HEAP_BTR_SEARCH的操作位,则数据有可能保存在free_block对应的内存单元中。此时需要单独释放创建的free_block,然后由后往前,逐个释放mem_heap_t链表上的各个block。
1.2.4 block的构建:mem_heap_create_block
1. block的申请
这个函数是整个mem_heap_t内存分配的核心,针对不同的type,实现了不同策略的内存分配。具体为:
case 1 - MEM_HEAP_DYNAMIC或是size较小时:使用ut_malloc_nokey
case 2 - 包含MEM_HEAP_BTR_SEARCH且当前block不为根block,从free_block指向的内存块分配
case 3 - 其他情况:使用buf_block,由buf_block_alloc从buffer pool中分配
这段代码做了以下几件事:
控制了单个block的上限值UNIV_PAGE_SIZE
heap->free_block = nullptr确保root节点的free_block不会再次被使用,同时也解释了为什么在type存在MEM_HEAP_BTR_SEARCH位的时候可能引起内存分配的失败,原因有两个:
当前block类型和mem_heap_t->base的类型不兼容:原始的根结点申请时若不包含MEM_HEAP_BTR_SEARCH位,则构建时free_block是nullptr,在line 12就会获得空指针而直接返回;
当前block依托的mem_heap_t->base对应的free_block已被使用:从line 13可以看到,只要是用过一次,free_block就会被标志为空,而真正的数据转移到了buf_block上。
2. block的初始化
这一步主要包括block几mem_heap_t节点对象中的各个参数的设置,简单的包括len、type、free的设置,重点分析一下buf_block、和free_block的设置,同样十分精妙。
- UNIV_MEM_FREE(block, len);
- UNIV_MEM_ALLOC(block, MEM_BLOCK_HEADER_SIZE);
-
- block->buf_block = buf_block;
- block->free_block = nullptr;
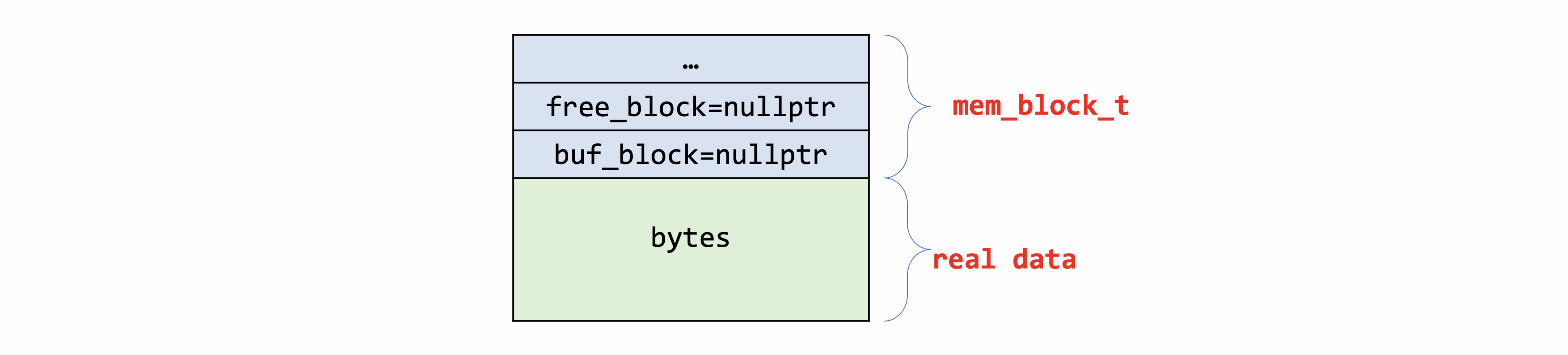
前面两句是将block对应的数据置为free状态,同时初始化头部的数据,为后面的len等数据的初始化做准备;后两句的设置分几种情况一一说明:
case 1 - type为MEM_HEAP_DYNAMIC:此时block->buf_block=nullptr,block->free_block=nullptr符合mem_heap_t对该类型的定义,此时block的内存结构如下(头部已经被初始化)。
case 2 - type为MEM_HEAP_BTR_SEARCH:block的内存从free_block中分配,此时free_block中的内存就转移到了buf_block中,并从buf_block构造了block所需的数据。

case 3 - type为MEM_HEAP_BUFFER:内存由buf_block_alloc从buffer pool中分配。
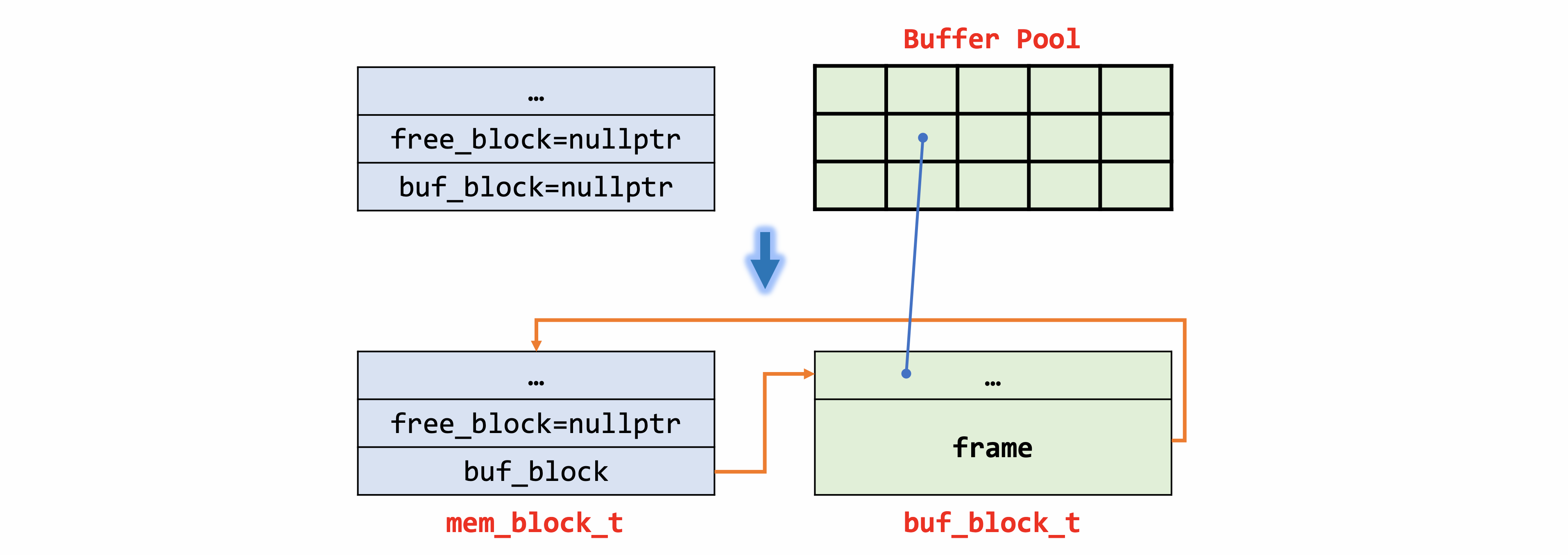
case 2/3内存结构最终形态是一致的,区别在于case2是从free_block转换得到buf_block,而case3是从BP中直接申请得到。其中free_block一般在构建mem_heap_t时由外部指定。
可以看到无论是case1、case2、case3或是多种case的组合,buf_block和free_block的修改都能达到正确设置数据的目的。
1.2.5 block的释放:mem_heap_block_free
获取buf_block(alloc方式获取的将会是nullptr)
从mem_heap_t链表移除、修改total_size
ut_alloc方式申请的block,则调用ut_free方式释放block;否则初始化block数据(因为在从bP/free_block获取之后,block除头部之外的部分可能是是free的状态)并用buf_block_free方式释放,使之成为BP中直接可用的free page。
1.2.6 从mem_heap_t申请内存:mem_heap_alloc
获取最后一个block,从最后一个block分配
申请给定大小的内存区域,不够则调用mem_heap_add_block添加新的block,MEM_HEAP_BTR_SEARCH下可能会失败,原因同上
更新free值(申请后可用空间变小了),初始化内存区域并返回数据指针buf(block+free偏移)
1.2.7 block添加策略:mem_heap_add_block
每次新添加的block size是上一个block的2倍,到达上限则保持不变
调用mem_heap_create_block并添加新的block到链表尾部
最后返回新的block
1.3 小结
ut_allocator在最新的80版本中已经删去,对应的内存申请和释放代码修改为模版函数。
ut_allocator在开启PFS_MEMORY下会引入多的内存,但可以控制该部分内存的使用,取决于监控这部分内存与否。
mem_heap_t有效减少了内存碎片,比较适用于短周期多次分配小内存的场景。但其在使用过程中不会free内存,当单个block出现空闲较大的情况时,会有一定程度的内存浪费。
二、InnnDB内存结构
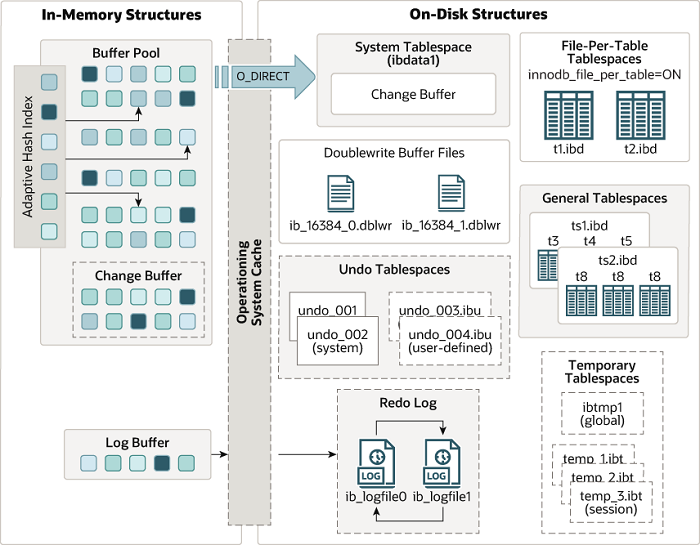
图源:https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
2.1 Buffer Pool
Buffer Pool(BP)简单来说就是innodb主内存中的一块区域,主要用于缓存数据页和索引页,也包括undo页、自适应哈希索引、锁信息等。读取数据时,若数据存在BP中则可以直接读取,避免IO而提升性能;数据页面修改时,也是先修改BP中的数据页,再使用一定的频率进行刷脏。
一般来说,BP size会配置成机器可用物理内存的 50% 到 75%,数据库再启动时就会提前分配好这部分的虚拟内存,真正的物理内存映射会在实际使用中进行。BP的内存在数据库关闭时统一释放。
2.1.1 数据结构
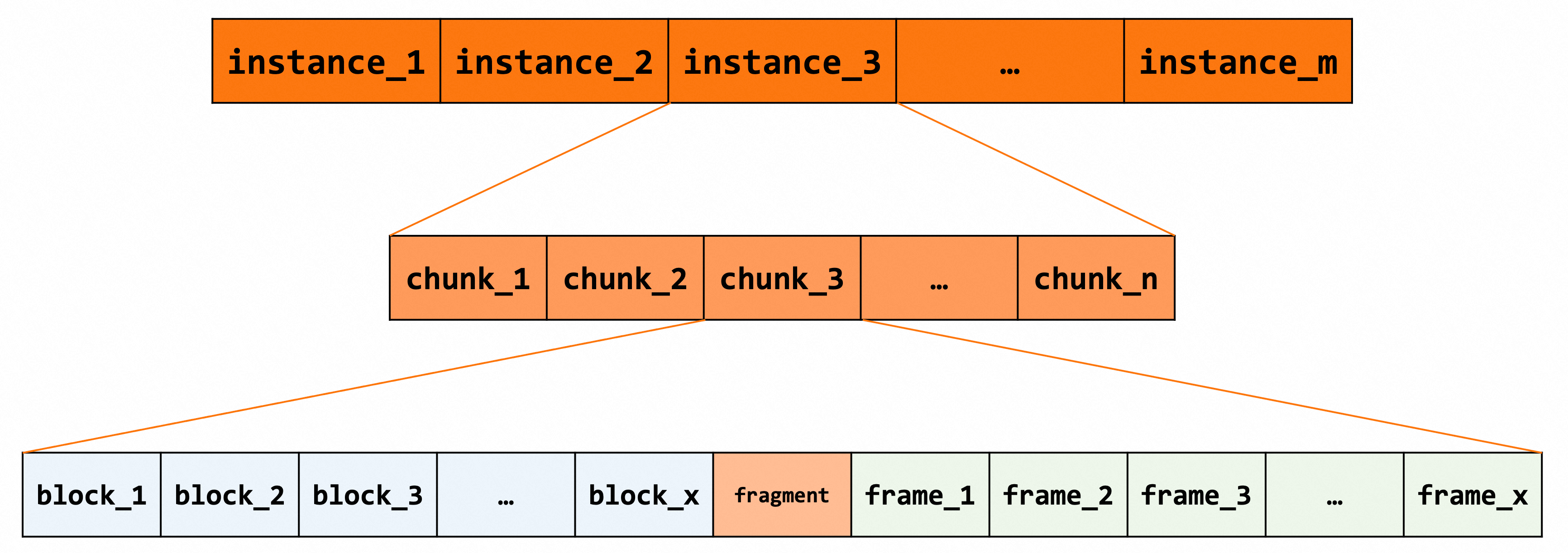
在BP中主要的数据结构包括buf_pool_t、buf_chunk_t、buf_block_t等,各结构之间的主要关系如下图所示。一个BP可以设置多个buf_pool_t实例,即BP instance,减少缓冲池内部的资源竞争以提高引擎整体的性能;每个BP instance包含了一个以上的chunk,每个chunk在初始化时会划分出数据页控制体buf_block_t和实际的数据页帧frame。数据页由LRU、free、flush等链表进行管理。
buf_pool_t
该结构中包含了诸多的信息,如实例号、size、chunk列表、各个链表(free、LRU、flush)及其互斥锁、哈希表及其互斥锁等,还包括了zip_free这个链表数组,用于伙伴系统的内存分配。通过buf_pool_t可以直接获取各个链表的根结点。
此外,buf_pool_t中还包含了ut_alloctor,用于为chunks分配内存;xxx_old用来记录resize前的旧数据;风险指针用于标记链表位置。
buf_chunk_t
chunk是物理内存分配的基本单位,instance由一块一块的chunk组成。每个chunk被切分成block串和frame串,block串在前,frame串在后,两者之间可能存在不圆整的内存碎片。
- struct buf_chunk_t {
- ulint size; /*!< frames[]/blocks[]的数量 */unsignedchar *mem; /*!< frame内存区域指针 */
- ut_new_pfx_t mem_pfx; /*!< 监控信息 */
- buf_block_t *blocks; /*!< 控制块数组 */uint32_t chunk_no; /*! chunk号 */
- UT_LIST_BASE_NODE_T(buf_page_t) chunk_page_list; /*!< chunk list根结点 */
- ...
- };
buf_block_t
控制块,主要的数据包括buf_page_t格式的page,该数据必须为第一个字段以便进行指针的强转(例如buf_pool->page_hash可以访问到block/page信息);还包括实际的数据帧frame,大小为UNIV_PAGE_SIZE;还有frame和block的mutex,需要注意的是,buf_page_t中的部分数据也是由block中的这个mutex进行保护的。
- struct buf_block_t {
- buf_page_t page; //放在第一个位置,以便于block和page进行强制转换
- BPageLock lock; //frame的读写锁byte *frame; //实际数据
- ...
- BPageMutex mutex; // block锁:state、io_fix、buf_fix_count、accessed
- };
buf_page_t
page包含了id、size、lsn等信息,io_fix和buf_fix_count用于控制并发状态,判断该page是否处于被访问的状态。此外,page中还包含了很多bool变量,主要用于判断该page是否处于对应链表或哈希表中。
- struct buf_page_t {
- ...
- page_id_t id; // page id
- page_size_t size; // page 大小
- ib_uint32_t buf_fix_count; // 用于并发控制
- buf_io_fix io_fix; // 用于并发控制
- buf_page_state state; // 页状态
- lsn_t newest_modification; // 最新 lsn,即最近修改的 lsn
- lsn_t oldest_modification; // 最老 lsn,即第一条修改 lsn
- ...
- }
2.1.2 初始化过程
step-1 buf_pool_init():
这个过程主要做三件事,一是bp instance指针数组的初始化(没有分配实际的内存);二是多线程并发使用buf_pool_create去构建实际的内存空间;三是在bp初始化完成后开启AHI的初始化。
- // 构建bp instance指针数组
- buf_pool_ptr =
- (buf_pool_t *)ut_zalloc_nokey(n_instances * sizeof *buf_pool_ptr);
-
- // 多线程并发初始化for (ulint id = i; id < n; ++id) {
- threads.emplace_back(std::thread(buf_pool_create, &buf_pool_ptr[id], size,
- id, &m, std::ref(errs[id]))); }
- // AHI的初始化
- btr_search_sys_create(buf_pool_get_curr_size() / sizeof(void *) / 64);
在buf_pool_create函数中主要做了几件事:
初始化各个锁:包括chunks mutex链表、LRU链表锁、free链表锁、zip_free链表锁、哈希表锁等等
计算chunks数量,申请chunk指针数组
初始化上述的链表
调用buf_chunk_init初始化chunk
设置instances相关的参数(size、instance_no等)
构建哈希表和相关的锁
初始化flush相关数据,如hp指针、链表包含关系等
step-2 buf_chunk_init
该函数主要做了以下几件事:
alloc chunk需要的内存(通过large的方式)
分割chunk,将其分为blocks和frames
调用buf_block_init初始化block(初始化block/page中的变量,如state、chunk_no还有是否处于链表的各个标志位等,构建mutex和rwlock)并将其加入free链表
注册chunk
step-3 page_hash初始化
- buf_pool->page_hash =
- ib_create(2 * buf_pool->curr_size, LATCH_ID_HASH_TABLE_RW_LOCK,
- srv_n_page_hash_locks, MEM_HEAP_FOR_PAGE_HASH);
-
- buf_pool->page_hash_old = nullptr;
-
- buf_pool->zip_hash = hash_create(2 * buf_pool->curr_size);
这里可以看到page_hash和zip_hash的构建方式有所差异,page_hash在完成create后还对heap结构和对应的锁进行了初始化(ib_create函数相比hash_create还做了heaps和锁初始化的工作)。
2.1.3 页面管理链表
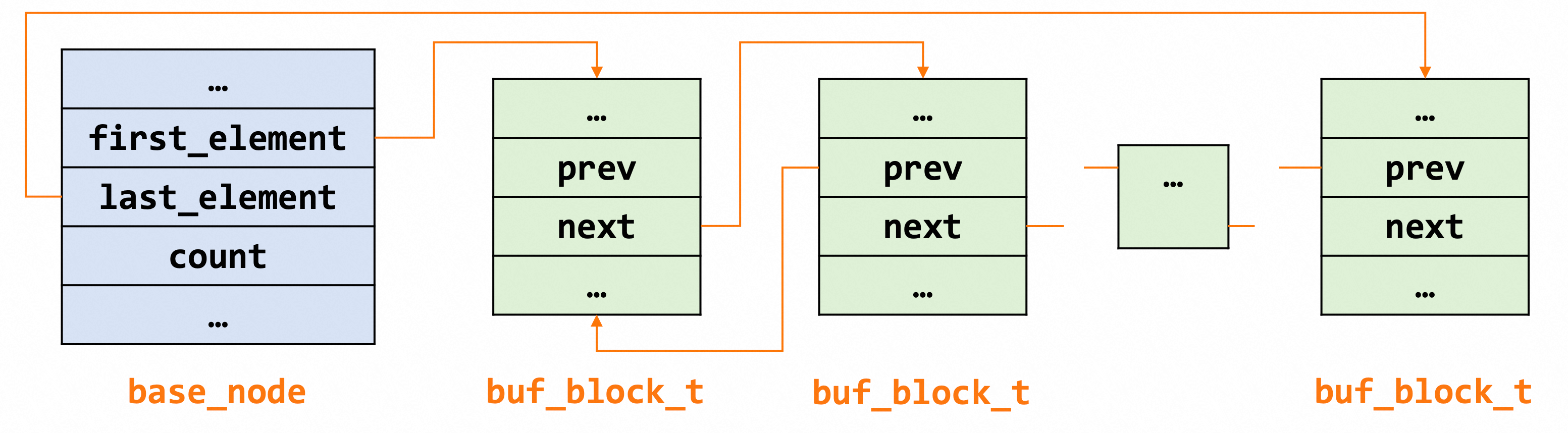
每个链表都是双向链表,节点都是buf_block_t,基节点中保存了首尾节点信息和链表长度等。buffer pool中的页面使用情况和双向链表结构如下所示。
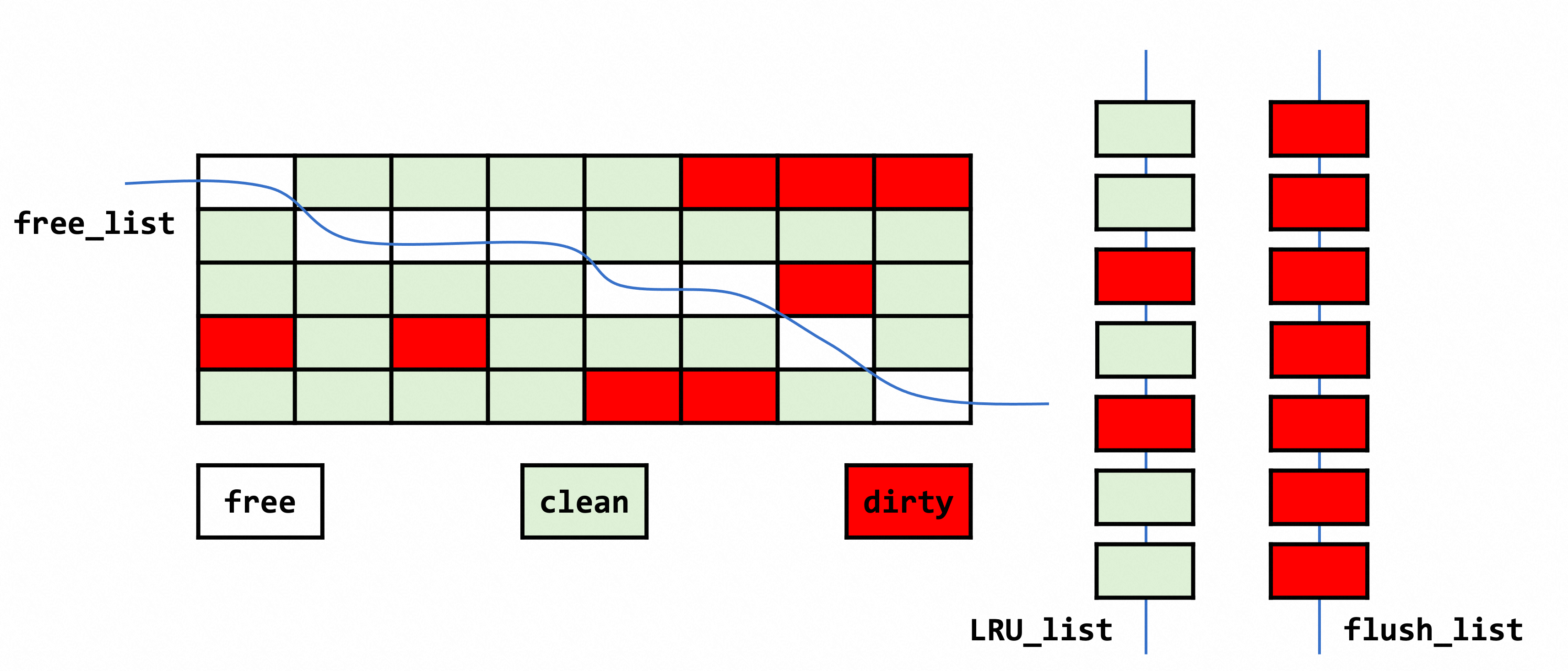
free list
block初始化后会直接加入到free链表。缓冲池中如果需要使用数据页,直接从空闲链表中获取。当空闲节点不足时,将采用一定的策略从 LRU List 和 Flush List 中淘汰一定量的节点以补充库存。
LRU list
LRU List 是缓冲池中最重要的数据结构,基本所有读入的数据页都缓冲于其上。LRU 链表顾名思义根据最近最少使用算法 Least Recently Used 对节点进行淘汰。InnoDB对 LRU 算法进行了以下优化,解决“预读失效”与“缓冲池污染”的问题。
LRU优化
LRU分为了Old Sublist和New Sublist两段,加载数据首先会加载到Old位置,只有当满足一定的条件时,数据才会从Old段转移到New段。当发生类似全表扫描的操作时,LRU的淘汰就不会影响到真正的热点数据,从而保证缓存的热度。
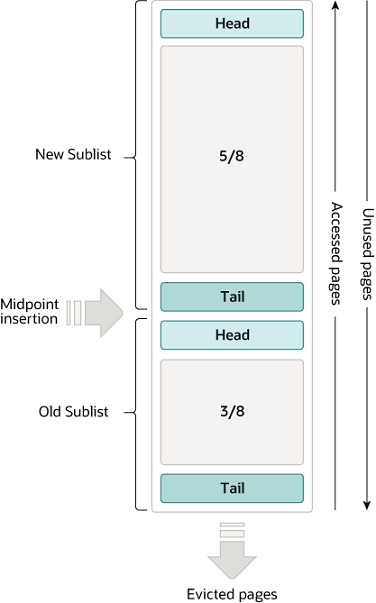
图源:https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
响应时间优化
先设定一个间隔时间innodb_old_blocks_time,然后将old区域数据页的第一次访问时间在其对应的控制块中记录下来。
如果后续的访问时间与第一次访问的时间小于innodb_old_blocks_time,则不将该缓存页从 Old区域移动到 New 区域。
如果后续的访问时间与第一次访问的时间大于innodb_old_blocks_time,才会将该缓存页移动到 New 区域的头部。
Flush List
缓冲池中所有脏页都会挂载在 Flush List 中,以等待数据落盘。在数据更改被刷入磁盘前,数据很有可能会被修改多次,在数据页控制体中记录了最新修改的 lsn(newset_modification) 和最老修改的 lsn(newest_modification)。进入 Flush list 的节点按照进入的顺序进行排序,最新加入的数据页放在链表头部,刷数据时从链表尾开始写入。
zip_free
是由 5 个链表构成的二维数组,分别是 1K、2K、4K、8K 和 16K 的碎片链表,专门用于存储从磁盘读入的压缩页,引擎使用 Buddy 伙伴系统专门管理该结构。
2.2 Change buffer
change buffer是一颗通用B+树,当页面不在buffer pool中时将其对应的修改缓存在change buffer中可有效地减少磁盘的随机访问。索引页大小16k,内存使用buffer pool,可以通过参数来设置最大的大小占比(innodb_change_buffer_max_size),默认25%,最多50%。
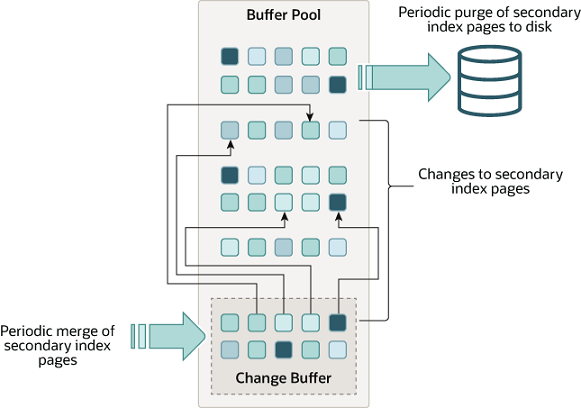
图源:https://dev.mysql.com/doc/refman/8.0/en/innodb-change-buffer.html
其结构为ibuf_t,内包含的都是基本的size、max_size、free_list_len、merge操作次数等信息,全局只有一个ibuf_t结构体,在数据库启动的时候构建。
change buffer创建和初始化过程在ibuf_init_at_db_start完成,主要包括:
相关互斥量的构建
ibuf参数的初始化,包括max_size、index等相关的数据
root的获取
ibuf_insert操作底层调用了ibuf_insert_low,主要做了以下几件事:
根据数据构建,在数据记录的基础上增加page.no等信息
选择合适的block插入(数据插入在rec中,而block则包含有rec的数据)
视情况进行merge
change buffer本身没有很多额外的内存申请,依赖buffer pool中的block进行操作。大部分都是申请了一些临时的heap,使用完毕后立即释放,不会在内存中长时间驻留。
2.3 AHI
innodb的索引组织结构为btree,当查询的时候会根据条件一直索引到叶子节点,为了减少寻路的开销,AHI使用索引键的前缀建立了一个哈希索引表,在实现上就是多个hash_tables(分片)。哈希索引是为那些频繁被访问的索引页而建立的,可以理解为btree上的索引。初始创建的数组大小为buf_pool_get_curr_size() / sizeof(void *) / 64,使用malloc分配。数组大小最终对应了hash_table的cell/bucket总数,这个数量实际上还要进行一个质数化的处理。
2.3.1 数据结构
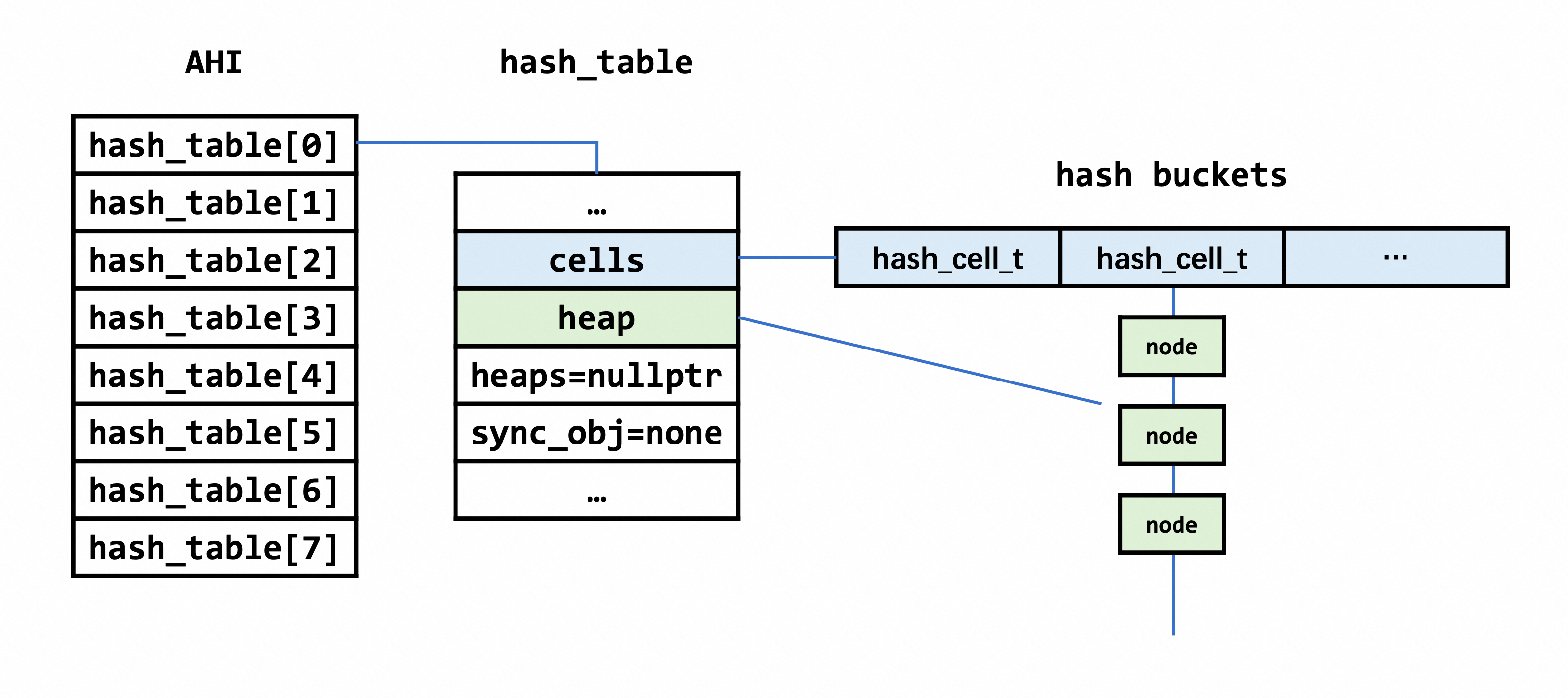
2.3.2 内存初始化
在AHI构建的时候,分成了8个part,每个part负责不同的bucket,拥有各自部分的锁。构建和初始化主要分为以下几个步骤:
锁的初始化,锁的数量和part数量挂钩
hash_table的初始化,底层调用ib_create,注意这里传入的type是MEM_HEAP_FOR_BTR_SEARCH,这直接决定了hash_table中heap的类型,即其后内存的来源。其中table->type在这里是HASH_TABLE_SYNC_NONE。
进一步地,ib_create中主要做2件事:
调用hash_create创建hash_table
hash_table函数主要做的事将大部分hash table结构中的参数初始化为0/nullptr,最最重要的是构建hash_table->cells,即哈希桶。哈希桶通过malloc & memset方式进行构建,这也是AHI耗时最久的步骤。
初始化table->heap
这里初始化type选择MEM_HEAP_FOR_BTR_SEARCH类型,heap的构建为后续的哈希桶指向的哈希链的内存分配做准备。
2.5 log buffer
log buffer是日志未写到磁盘的缓存,大小由参数innodb_log_buffer_size指定,一般来说这块内存都比较小,默认是16M,有max和min的限制。
log buffer的内存申请/释放底层调用的是ut_allocate/ut_free,参数srv_log_buffer_size就是所需的大小。
- // 内存申请staticvoidlog_allocate_buffer(log_t &log){
- ...
- log.buf.create(srv_log_buffer_size);
- }
- //内存释放staticvoidlog_deallocate_buffer(log_t &log){ log.buf.destroy(); }
2.6 table cache
MySQL中对内存中打开表的数量和表结构数量做了限制。open_table的过程涉及到sever层和引擎层,这里针对innodb中涉及的动作。
InnoDB层的开表动作从函数ha_innobase::open开始,主要包括了dict_table_t的构建和row_prebuilt_t这个结构的建立。ib_table的获取顺序是session_cache、dict_sys->hash_table、dd_open_table
下面分别就ib_table的来源内存进行说明
session_table_cache
每个THD内部保存了thread_local的数据,通过该数据可以获取session下的m_open_tables映射表。该表的插入删除查找都是基于std::map进行。
- classinnodb_session_t {
- table_cache_t m_open_tables;
- ...
- };
dict_sys->table_hash
dicy_sys中table_hash的构造实际上是在数据字典初始化的时候完成的,主要包括:lock的构建、table_LRU链表的构建、table_hash的构建,也是通过hash_create这个结构进行构建,这部分内存是在dict_init中完成分配的。
- void dict_init(void) {
- ...
- dict_sys->table_hash = hash_create(
- buf_pool_get_curr_size() / (DICT_POOL_PER_TABLE_HASH * UNIV_WORD_SIZE));
- dict_sys->table_id_hash = hash_create(
- buf_pool_get_curr_size() / (DICT_POOL_PER_TABLE_HASH * UNIV_WORD_SIZE));
- ...
- }
dd_open_table
在试图获取缓存表失败后,最终会通过dd_open_table接口构造dict_table_t,底层的调用是dict_mem_table_create,通过heap的方式对dict_table_t的所有结构进行构造,构造完成后,会把最新的table保存在dict的hash_table中。
server层中的总的table cache和打开表数量、字段长度都有关系,每个table cache占据的内存从几十k ~ 几百k不等,可以参考 这篇文章。
2.7 lock_sys_t
锁系统也是在innodb start/create的时候构建的,主要的数据内容包括行锁哈希表、Predicate Locks哈希表、predicate page locks哈希表等,主要的构建和销毁操作如下。
主要的内存消耗都是在三个hash_table的构造上,并且是“裸”构造,没有涉及heap/heaps的初始化,所有的内存都是通过malloc的方式去构造。各个hash_table的需要的内存和srv_lock_table_size相关,其值在innodb启动时被指定(srv_lock_table_size = 5 * (srv_buf_pool_size / UNIV_PAGE_SIZE))。
2.8 os_event_t
大多数锁、互斥量的构建和初始化最终都会相应到os_event_t的构造,但是零散的、临时的mutex等并不会造成很大的内存压力。在前文提到的在buf_block_t的初始化中就有mutex和rw_lock的初始化,其生命周期和bp相当,数量和buf_block_t相等,会占据很大一部分内存。
buf_block_init:
- /** Initializes a buffer control block when the buf_pool is created. */staticvoidbuf_block_init(
- buf_pool_t *buf_pool, /*!< in: buffer pool instance */
- buf_block_t *block, /*!< in: pointer to control block */byte *frame, /*!< in: pointer to buffer frame */
- buf_chunk_t *chunk, /*!< in: pointer to chunk */bool sync_init_nolock){
- ...
- mutex_create(LATCH_ID_BUF_BLOCK_MUTEX, &block->mutex); // or mutex_create_nolock
- ...
- rw_lock_create(PFS_NOT_INSTRUMENTED, &block->lock, SYNC_LEVEL_VARYING); // or rw_lock_create_nolock
- ...
- }
mutex_create
- mutex_create()
- |->mutex_init()
- |->TTASEventMutex::init()
- |->os_event_create()
rw_lock_create
- rw_lock_create()
- |->pfs_rw_lock_create_func()
- |->rw_lock_create_func()
- |->os_event_create()
os_event_create的底层实现是调用了malloc的方式,最终由系统分配这部分的内存。
- os_event_t os_event_create() {
- os_event_t ret = (UT_NEW_NOKEY(os_event()));
- return ret;
- }
2.9 内存占用
对象 | 来源 | 详细 | 大小 | 分配方式 |
Buffer Pool | buf_pool_create | chunk | BP + BP/16k * 440 (round) | ut_allocator.allocate_large |
buf_pool_create | page_hash | 2 * BP/16k * 8 (prime) | ut_allocator.allocate | |
buf_pool_create | zip_hash | 2 * BP/16k * 8 (prime) | ut_allocator.allocate | |
AHI | buf_pool_init | hash_tables | BP / 8 / 64 * 8 (prime) | ut_allocator.allocate mem_heap_allocator (from BP) |
log buffer | log_allocate_buffer | buf | srv_log_buffer_size | ut_allocator.allocate |
DD cache | dict_init | table_hash | BP / 4096 * 8 (prime) | ut_allocator.allocate |
table_id_hash | BP / 4096 * 8 (prime) | ut_allocator.allocate | ||
lock system | lock_sys_create | rec_hash | 5 * BP / 16k * 8 (prime) | ut_allocator.allocate |
rec_hash | 5 * BP / 16k * 8 (prime) | ut_allocator.allocate | ||
rec_hash | 5 * BP / 16k * 8 (prime) | ut_allocator.allocate | ||
osevent | buf_block_init | mutex | 112 * BP / 16k (round) | ut_allocator.allocate |
rw_lock | 2 * 112 * BP / 16k (round) | ut_allocator.allocate |
round代表分配的大小需要做圆整对齐处理、prime代表需要做质数化处理。
2.10 小结
bp指定的size最终体现了chunk的内存中,实际内存和指定的size可能存在差异。
AHI结构中采用malloc的方式申请了cells,但实际的数据都保存在heap中,该部分内存从bp中获取。在AHI中存在多个hash_table,目前是采用loop方式构建,可以考虑并行初始化;减少哈希冲突进而减少mem_heap的内存使用。
很多内存结构都和hash_table相关,hash_table实际的内存占用需要做质数化处理。
绝大多数的os_event_t在buf_block_t的初始化中产生,该部分的内存占用也是比较大的。
在实际的内存分配中,除了指定的bp大小之外,系统还会产生额外的内存,本节只是列举了一部分。Oracle的分配内存的方式对用户更加友好,指定固定的内存,具体的分配在内部完成,可以很好控制内存总量。
三、SQL层内存分配管理器MEM_ROOT
sql层的内存分配管理除了基础的alloc/free的形式外,主要应用了MEM_ROOT这一结构,降低了内存操作的时间和资源的损耗。本文中主要针对MEM_ROOT的相关内容进行介绍。
MEM_ROOT作为一种通用的内存管理对象,大量使用于sql层,如在THD、TABLE_SHARE等结构中都包含了其作为内存分配器。事实上,MEM_ROOT只是负责管理内存,实际分配的内存来源是其结构成员Block,MEM_ROOT中只包含一块Block且只对当前唯一的Block负责,Block则是含有指向前一Block节点的指针,串成一条链表。
和1.2.1小结提到的mem_heap_t不同,MEM_ROOT主要负责sql层相关的内存分配,mem_heap_t在innodb中单独实现,负责innodb相关的内存分配,但两者的结构和实现模式上是类似的。
3.1 MEM_ROOT数据结构
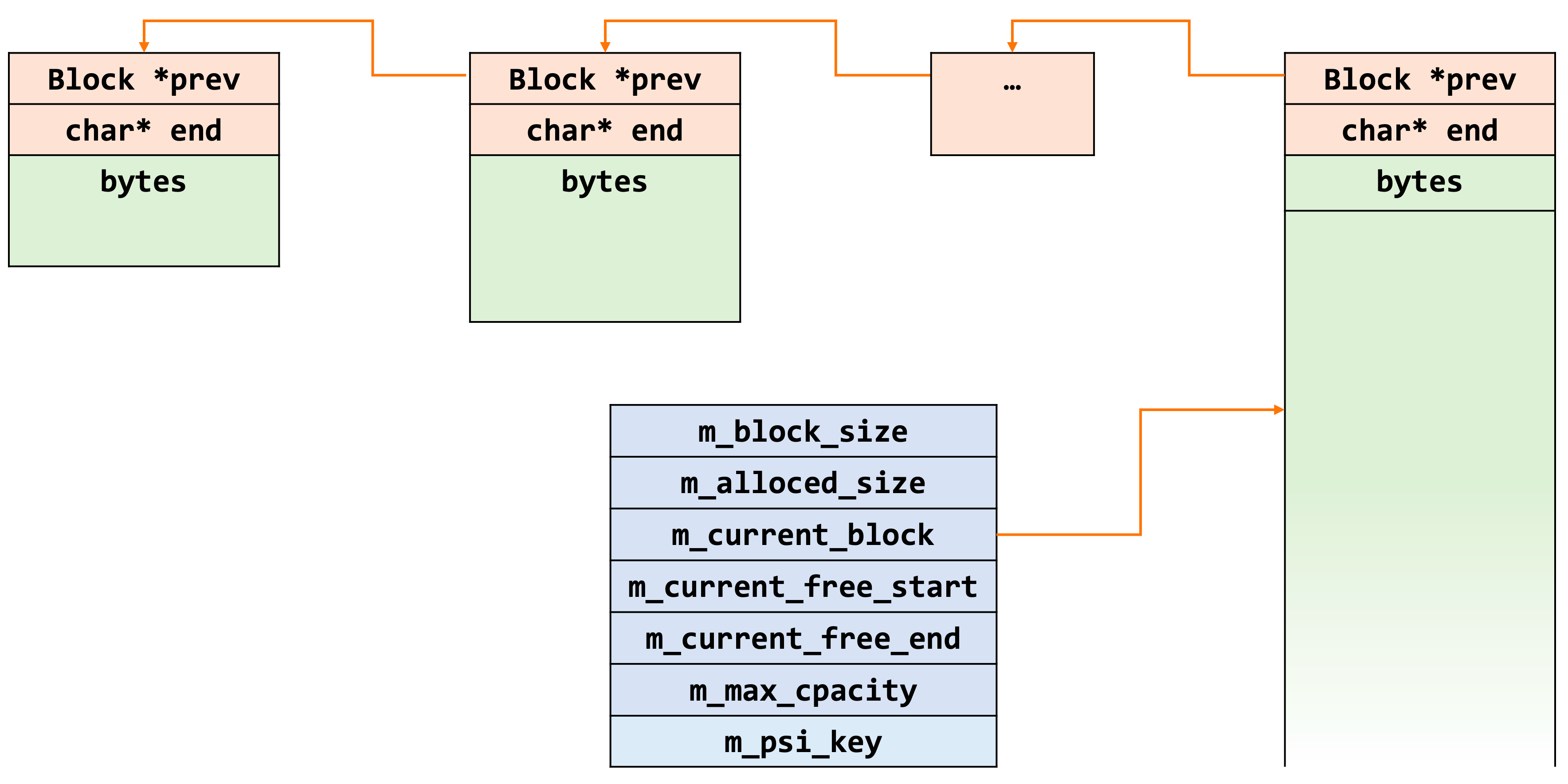
Block是其核心结构,所有的内存分配都源自于此。Block中包含了指向前1Block的指针prev,同时保留了end作为地址范围的标志,表明Block所管理的内存范围。
m_block_size记录了MEM_ROOT下一次要分配和管理的Block内存块的总大小,当申请新的Block块时,该值都会更新为原值的1.5倍。
m_allocated_size记录了MEM_ROOT从OS分配出的内存总量,每次分配新的Block时该值也会进行更新。
m_current_block、m_current_free_start、m_current_free_end分别记录了当前管理block的起始地址、空闲地址和结束地址。
m_max_capacity定义了MEM_ROOT的管理的最大内存,m_error_for_capacity_exceeded是内存超出最大限制的控制开关,m_error_handler是内存超出的错误处理函数指针;m_psi_key是PFS内存监测点。
3.2 MEM_ROOT关键接口
3.2.1 构造函数 && 赋值操作
MEM_ROOT的原始构造方式内容很简单,只对m_block_size、m_orig_block和m_psi_key进行赋值,同时MEM_ROOT采用了移动构造和移动赋值的方式,对持有的MEM_ROOT进行接管,主要逻辑如下:
// 移动构造函数MEM_ROOT(MEM_ROOT&&other)noexcept:m_xxx(other.m_cxxx),...{other.m_xxx=nullptr/0/origin_value;...}// 移动赋值MEM_ROOT&operator=(MEM_ROOT&&other)noexcept{Clear();::new(this)MEM_ROOT(std::move(other));return*this;}3.2.2 Alloc
该函数是根据传入的所需内存空间大小从当前所管理的、已有的Block块上返回一块新的起始地址,同时对内存使用信息进行更新。当MEM_ROOT所管理的Block大小不满足要求时,则会调用AllocSlow函数进行新Block的分配和管理。同时需要注意的是,返回的地址总是8-aligned。
3.2.3 AllocSlow
该函数用于申请新的Block,根据使用场景的差异,底层调用了两种分配模式,返回的内存地址同样是对齐的。
当所需的内存很大时或是有独占一块内存的需求时,在申请完新的内存块后,并不会将新生请的Block置为当前所管理的Block(除非是MEM_ROOT首次申请),而是将其置为链表中的倒数第2块(即current_block的前一节点)。设计者不希望大内存申请和独占内存的形式对后续的内存分配造成干扰,大内存的申请会导致后续分配Block时x1.5的基数变大,难以控制内存申请量的增长;同时,若后续的内存分配和有独占内存需求的内存块相接,会导致内存的控制复杂。通过保持原有的current_block的方式,能够很好地避免上述问题的发生。
在非上述的情况下,优先使用追加内存块到current_block尾部并更新current_block的方式进行分配。
3.2.4 AllocBlock
该函数是Block分配的基础函数,底层是调用my_malloc函数进行内存的申请,根据PSI的信息和PFS开关等会对数据进行统计。my_malloc和my_free函数在后续会做简单的介绍,此处不再赘述。
在设置了内存超出限制的错误标志下,大内存的申请可能会导致失败。同时AllocBlock支持传入wanted_length和minium_length参数,在某些情况下能够分配出minium_length的内存大小。在每次分配完毕后,m_block_size都会调整为当前的1.5倍,避免后续频繁的调用alloc。
3.2.5 ForceNewBlock
该函数对应上文AllocSlow的第二种内存分配方式,直接调用AllockBlock进行内存块的申请,然后将其挂在Block链表的尾部,并设置其为MEM_ROOT所管理的当前Block。
3.2.6 Clear
Clear函数执行的逻辑较为简单,主要做了两件事:
将MEM_ROOT的所有状态置为初始状态
遍历Block链表节点并释放
3.2.7 ClearForReuse
当此前使用的内存不再需要试图释放,但又不想再MEM_ROOT再次被使用时重新走一遍Alloc…的流程时,ClearForReuse起了很大的作用。和Clear函数free所有Block不同,ClearForReuse会保持当前的Block,,而释放其他节点。换言之,经过ClearForReuse操作后,Block链表中只留下了最后的节点。但是在独占内存的场景下,代码逻辑依旧会走到Clear()。
3.2.8 其他
MEM_ROOT的内存分配方式都是字节对齐的,处理方式是在上层的Alloc等接口中对所需要的内存length进行圆整操作。但同时MEM_ROOT提供了“非标”操作的接口,提供了Peek、RawCommit等函数,支持直接对底层的Block进行操作,需要注意的是,这类操作的发生频率不高,并且下一次使用Alloc等操作时,会重新将内存做圆整处理。
3.3 MEM_ROOT在THD中的应用
MEM_ROOT在sql层的使用十分频繁,常用在THD、THD::transactions、Prepared_statement:、TABLE_SHARE、sp_head、sp_head、table_mapping等结构中,下面以最常见的使用场景THD为例,简要介绍MEM_ROOT在sql层中的应用。
THD中包括了三个MEM_ROOT(包括对象和指针),main_mem_root,user_var_events_alloc和mem_root。
3.3.1 main_mem_root
MEM_ROOT对象,随THD结构析构,主要用于执行sql过程中涉及的解析、运行时数据的存储。
This memory root is used for two purposes: - for conventional queries, to allocate structures stored in main_lex during parsing, and allocate runtime data (execution plan, etc.) during execution. - for prepared queries, only to allocate runtime data. The parsed tree itself is reused between executions and thus is stored elsewhere.
THD::THD(bool enable_plugins) : Query_arena(&main_mem_root, STMT_REGULAR_EXECUTION), ... lex_returning(new im::Lex_returning(false, &main_mem_root)), ... { main_lex->reset(); set_psi(nullptr); mdl_context.init(this); init_sql_alloc(key_memory_thd_main_mem_root, &main_mem_root, global_system_variables.query_alloc_block_size, global_system_variables.query_prealloc_size); ... }
3.3.2 mem_root
当前mem_root的指针,在THD初始化时指向main_mem_root,但在实际应用时会发生变化,通过临时改变mem_root指向的方式使用其他对象的MEM_ROOT来申请内存,使用完毕后再将mem_root指向初始内存地址(main_mem_root)。
问:为什么要把mem_root设计成可变动的对象?为什么要把mem_root的内存指针嵌入到THD?
答:方便控制内存大小,若thd->mem_root始终指向main_mem_root,相应的内存会一直存在直到THD析构,改变mem_root指向可以更好地控制内存生存周期,让临时的内存占用得以释放,和长期存在的内存分离。嵌入到THD(实际上是其父类Query_arena)中,可以让THD占用的内存统计信息更清晰、管理过程更简洁,即尽管该部分内存不是直接由THD产生,而是在执行语句的过程中产生的,同样需要把“责任”归属在THD上。简化函数传参,减少一个MEM_ROOT的参数,传入THD即可。 ```CPP THD::THD(bool enable_plugins) : Query_arena(&main_mem_root, STMT_REGULAR_EXECUTION), …
MEM_ROOT* old_mem_root = thd->mem_root; // 保存原来的mem_root(main_mem_root) thd->mem_root = xxx_mem_root; // mem_root大多是临时性的MEM_ROOT // do something using memory … thd->mem_root = old_mem_root; // 恢复成原来的mem_root(main_mem_root)
3.3.3 user_var_events_alloc
memroot指针,用于分配THD中的Binlog_user_var_event数组元素,通常和thd->mem_root指向相同。
3.4 小结
MEM_ROOT是MySQL-sql层中使用最多的内存分配器,类似mem_heap_t,其同样存在Block碎片问题,但其在设计时提供了ClearForReuse这样的接口,可以及时释放前面所占用的内存;此外,MEM_ROOT在设计中考虑了独占内存和大内存的场景,降低了一次后续申请的内存大小。同时在THD结构中,MEM_ROOT指针的灵活使用给内存的运用提供了新的思路,值得借鉴。
四、8028新特性 - Global and session memory allocation limits
4.1 功能改动
8028引入,该WL主要对session和global级别的内存申请做了限制,降低出现OOM的风险。
4.1.1 添加variables
| variable_name | 含义 | | — | — | | global_connection_memory_limit | 全局connection的内存限制 [1, 18446744073709551615] | | connection_memory_limit | 单个connection的内存限制 [1, 18446744073709551615] | | connection_memory_chunk_size | 内存统计的最小变更单位,用于控制更新频率 [1, 1024*1024*512],默认8912 | | global_connection_memory_tracking | 开关,用于控制全局内存计数器的启用和追踪 |
MySQL[(none)]>showvariableswherevariable_namein('global_connection_memory_limit','connection_memory_limit','connection_memory_chunk_size','global_connection_memory_tracking');+-----------------------------------+----------------------+|Variable_name|Value|+-----------------------------------+----------------------+|connection_memory_chunk_size|8912||connection_memory_limit|18446744073709551615||global_connection_memory_limit|18446744073709551615||global_connection_memory_tracking|OFF|+-----------------------------------+----------------------+MySQL[(none)]>showstatuslike"Global_connection_memory";+--------------------------+-------+|Variable_name|Value|+--------------------------+-------+|Global_connection_memory|0|+--------------------------+-------+4.1.2 修改PFS_thread、PSI_thread_service_v5、THD
m_cnt_thd是负责更新内存计数信息的THD,在组提交等操作中会存在THD转换的问题,该成员可以确保转换时内存统计信息的正确性。
接口set_mem_cnt_THD是协助完成THD转换的函数,分别对m_thd和m_cnt_thd进行设置,大部分情况下两者是相同的。
THD结构中新增的mem_cnt在初始化时为Thd_mem_cnt_noop(空操作计数器),在connnection的prepare阶段通过调用enable_mem_cnt创建为Thd_mem_cnt_conn(真正具备计数功能);在THD析构阶段调用disable_mem_cnt释放该计数器。
- // Thd_mem_cnt_conn创建
- thd_prepare_connection()
- | thd->enable_mem_cnt() {
- | | Thd_mem_cnt *tmp_mem_cnt = new Thd_mem_cnt_conn(this);
- | | mem_cnt = tmp_mem_cnt;
- | }
- // Thd_mem_cnt_conn释放
- ~THD()
- | THD::release_resources()
- | | disable_mem_cnt() {
- | | | mem_cnt->flush(); // 清空当前THD的内存计数信息并扣除对应的gloabl数据
- | | | delete mem_cnt;
- | | }
4.1.3 添加class Thd_mem_cnt_conn
数据结构
在介绍类之前,首先需要知道引入的计数模式,通过位运算可以实现多种模式的组合。
- enum enum_mem_cnt_mode {
- MEM_CNT_DEFAULT = 0U, // 不计数
- MEM_CNT_UPDATE_GLOBAL_COUNTER = (1U << 0), //更新global信息
- MEM_CNT_GENERATE_ERROR = (1U << 1), // 产生OOM错误信息
- MEM_CNT_GENERATE_LOG_ERROR = (1U << 2) // 产生OOM错误信息写入日志
- };
Thd_mem_cnt_conn的关键数据结构如下:

mem_count、max_conn_mem、glob_mem_counter分别对应已申请的内存、最大内存(该值并不是一个指定值,会随mem_count变化)和传递给global计数的值。
问:为什么还需要一个glob_mem_counter呢,直接将当前的mem_count累加到全局内存计数器不可以吗?
答:每次对全局计数器进行操作会影响并发度。还记得参数connection_memory_chunk_size吗,这个参数的意义是每次汇总到总内存计数的size是chunk_size的整数倍,也就是说glob_mem_counter = connection_memory_chunk_size * n。提前汇总足够多数量的内存计数到global中可以避免每次增加零散内存数量带来的全局数据的频繁改动,只有mem_count > glob_mem_counter时才对global数据进行写入,同时将glob_mem_counter加上m * connection_memory_chunk_size。因此说, connection_memory_chunk_size能够控制全局计数器更新的频率。同时,这个操作也会引发提前OOM的发生,因此connection_memory_chunk_size不宜设置的太大。
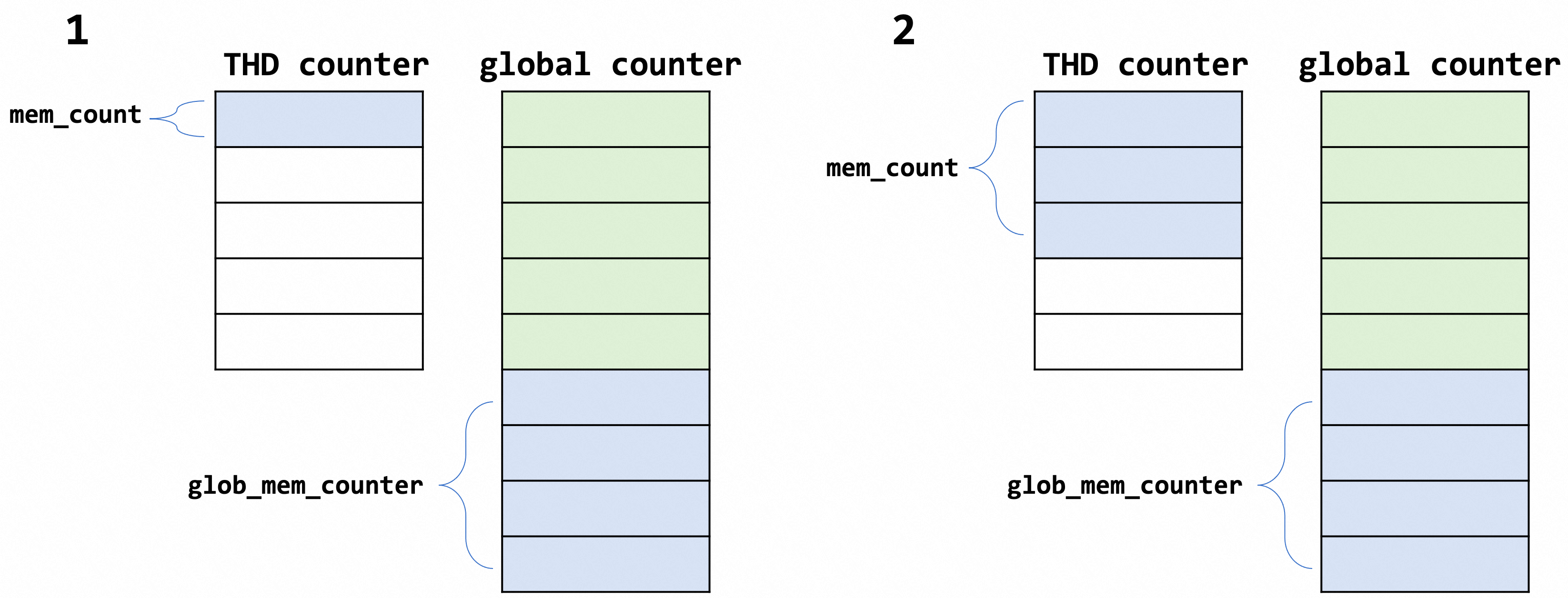

mode参数枚举类型enum_mem_cnt_mode中的组合,例如SUPER用户在连接建立时的mode是MEM_CNT_UPDATE_GLOBAL_COUNTER,而普通的用户的mode则是MEM_CNT_UPDATE_GLOBAL_COUNTER | MEM_CNT_GENERATE_ERROR | MEM_CNT_GENERATE_LOG_ERROR。在进行内存计数时会使用这个判断位,决定是否产生错误并kill connection。换言之,SUPER用户在执行查询等操作时是不会受到limit参数的限制的,而普通用户则会收到varibales的影响。
- staticvoidprepare_new_connection_state(THD *thd){
- ...
- thd->mem_cnt->set_orig_mode(is_admin_conn ? MEM_CNT_UPDATE_GLOBAL_COUNTER
- : (MEM_CNT_UPDATE_GLOBAL_COUNTER |
- MEM_CNT_GENERATE_ERROR |
- MEM_CNT_GENERATE_LOG_ERROR));
- ...
- }
关键接口
alloc_cnt
该函数的功能是对thd和global级别的内存计数信息进行更新。主要做了以下几件事:
修改mem_counter、max_conn_mem、glob_mem_counter,这里可以看出max值是随mem_counter更新的,glob_mem_counter也是lazy添加到全局内存计数器中的,只有满足(max_conn_mem > glob_mem_counter)才会重新插值delta到全局计数器。由于访问全局计数器需要加锁,因此这样的操作可以避免每次的访问都加锁。
产生错误信息,包括connection级别的和global级别的错误信息。generate_error会报错传入的错误信息给thd赋予 THD::KILL_CONNECTION,随后连接会因此而killed
free_cnt
该函数的功能单一,只对connection级别的mem_counter做减法,全局数据的修改在reset函数中完成,目的同样是为了减少全局资源的竞用。
- voidThd_mem_cnt_conn::free_cnt(size_t size) {
- mem_counter -= size;
- }
reset
free_cnt操作只是减去了thd级别的内存计数,全局的计数数据更新在reset函数中完成,该函数保证了当前的thd和global处于最新的状态。主要做了以下几件事:
重置mode,此前的一些操作可能会将计数器的mode进行修改(例如在prepare connection阶段),这里要确保更新前counter处于正确的模式,避免出现不同权限操作出错(如此前的super和普通用户等)。
更新三个计数数据,当glob_mem_counter > mem_counter时,表明此前有free_cnt操作减少了mem_counter,此处对glob_mem_counter和全局数据进行更新;反之表明存在未加入全局内存的thd级别内存,也需要将差值补全。在reset过程中也可能出现内存不足的情况,同样需要调用错误产生函数对错误信息进行报告,设置kill标志。
flush
该函数清空当前连接的内存计数,同时扣除全局的内存计数。在删除计数器对象前,必须要先调用此函数,确保计数正确。
- void Thd_mem_cnt_conn::flush() {
- max_conn_mem = mem_counter = 0;
- if (glob_mem_counter > 0) {
- MUTEX_LOCK(lock, &LOCK_global_conn_mem_limit);
- global_conn_mem_counter -= glob_mem_counter;
- }
- glob_mem_counter = 0;
- }
4.2 内存限制过程
4.2.1 执行流程
以最简单的handle_connection为例(非线程池模型),连接建立到执行语句到连接关闭过程对应的内存限制操作如下图所示:
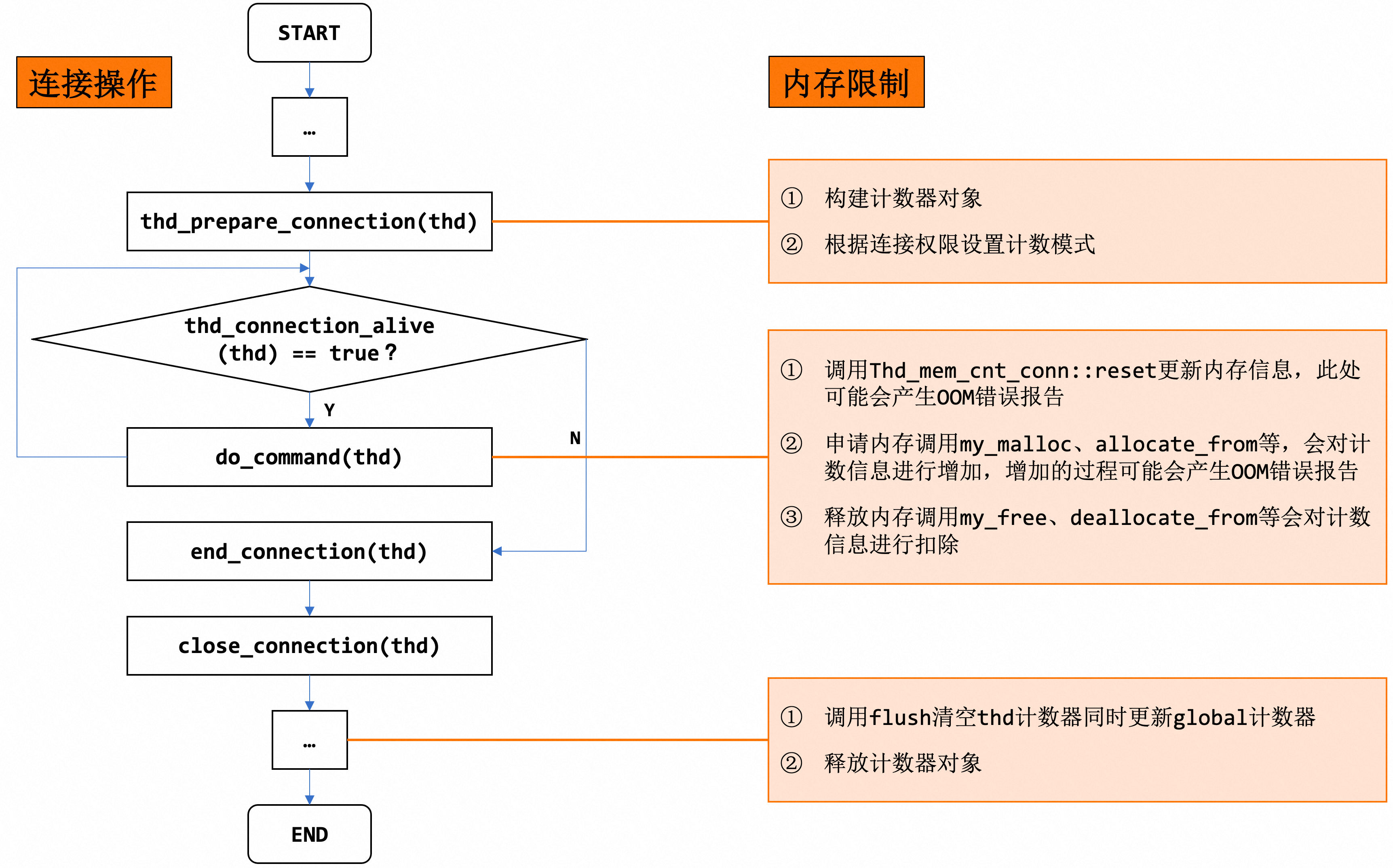
- ...
- if (thd_prepare_connection(thd))
- handler_manager->inc_aborted_connects();
- else {
- while (thd_connection_alive(thd)) {
- if (do_command(thd)) break;
- }
- end_connection(thd);
- }
- close_connection(thd, 0, false, false);
- ...
4.2.2 关键函数
计数器的构建、销毁、计数信息的加减更新等操作在3.1中做了说明,此处针对内存申请时添加计数器的处理逻辑进行说明。
在connection建立和query执行的过程涉及的内存基本通过my_malloc(结构数据、sort buffer等)和allocate_from(临时表)这两个接口进行,对应的释放函数为my_free和deallocate_from。两种内存申请方式中对于计数器的处理是相同的逻辑,这里以my_malloc/my_free为例对其中涉及的计数器操作逻辑做进一步说明。
my_malloc
my_malloc中主要做了两件事:
构建内存块头部,其中保存了size、magic、psi_memory_key等信息
调用PSI_thread_service_v5服务中的pfs_memory_alloc_vc接口对key进行赋值,实际的计数器更新就在这个接口中进行。
pfs_memory_alloc_vc
这个函数是计数数据增加的入口,主要工作如下:
根据key找到对应的PFS_memory_class
获取PFS_thread,在启用了计数器的情况下,对统计数据进行更新。PFS_memory_key类型只要执行了注册memory_class逻辑(register_memory_class),就会启用计数器对象。
返回key值,若启用计数器,此时的key值是经过PSI_MEM_CNT_BIT(1 « 31)标记的。
my_free && pfs_memory_free_vc
和上述的两个函数功能相反,my_free中首先调用pfs_memory_free_vc对key进行释放,包括了计数器的信息的扣除更新等,然后对包含header在内的整块内存区域进行释放。
问:那些内存会被计数器进行统计呢?
答:在psi_memory_key.cc中,新特性引入的PSI_FLAG_MEM_COLLECT标志位,对all_server_memory数组中需要进行限制的内存打上了标签。
4.3 简单测试
4.3.1 测试准备
创建普通用户RDS_test
构建大数据记录
设置较小的connection_memory_limit
create user RDS_test identified by 'RDS_test';grant select on test.* to RDS_test;use test;create table t(id int primary key, c longtext);insert t values (1, lpad('RDS', 6000000, 'test'));set global connection_memory_limit=1024 * 1024 * 2;set connection_memory_limit=1024 * 1024 * 2;4.3.2 测试
普通用户执行
# $mysql -uRDS_test -h127.0.0.1 -P3017 -pMySQL[test]>showvariableslike"connection_memory_limit";+-------------------------+---------+|Variable_name|Value|+-------------------------+---------+|connection_memory_limit|2097152|+-------------------------+---------+MySQL[test]>selectcount(c)fromtgroupbyc;ERROR4082(HY000):Connectionclosed.Connectionmemorylimit2097152bytesexceeded.Consumed7079568bytes.SUPER用户执行
MySQL[test]>showvariableslike"connection_memory_limit";+-------------------------+---------+|Variable_name|Value|+-------------------------+---------+|connection_memory_limit|2097152|+-------------------------+---------+MySQL[test]>selectcount(c)fromtgroupbyc;+----------+|count(c)|+----------+|1|+----------+4.3.3 测试结果
引入了这个功能后,对普通用户的内存使用被限制,直接被kill,但super用户还是不受限制的。
4.4 小结
对于SUPER用户和普通用户,内存限制有差别,前者不做限制。
connection_memory_chunk_size的引入能够控制全局计数器的更新频率,减少锁的争用,但在该变量值设置的较大的情况下,容易提前报告OOM错误导致connection被kill。
计数器数据操作中session和global数据减少是分离的,global数据的更新总是滞后于session,这同样也可以减少锁的争用,但存在单个do_command操作多次的alloc_cnt和free_cnt导致提前报告OOM错误的可能性(只执行free_cnt,但没有其他session做reset操作)。
OOM仍旧有可能在connnecion操作中产生,my_malloc/allocate_from阶段提前映射很小部分的物理内存,也可能刚好触发OOM。此外,super用户的操作没有做内存限制,可能也会引发OOM。
内存统计和限制操作依赖于PFS_thread,计数器数据的更新首先通过该对象传递。
五、总结展望
MySQL/InnoDB在内存的分配、使用、管理上做了很多工作和优化,各模块单独抽离出来也是一套内存分配管理系统,其设计方式和使用策略都有值得学习的地方。
不难发现,在InnoDB中内存实际上还是基本可控的,因为大多数的内存都由指定的size进行控制,额外产生的内存也能粗略的推断出。在MySQL服务工作工程中,特别是在sql层,还有许多无法准确估量的内存损耗,如果没有很好地对其进行控制,可能就会引发OOM。官方引入的connection/global的内存使用限制对这个情况进行了优化,降低了实例发生OOM的风险,但与此同时,OOM的问题还无法完全避免,有待进一步优化。
sql层中其它内存的使用如net_buffer、join_buffer、sort_buffer等也会在运行中占据不小内存,同时在Server启动的阶段也会产生许多临时性的内存如recovery、初始化等所需的内存等等,相关的内容会在后续的文章中介绍。

