
- 1java数据结构——红黑树简介_java 红黑树数据结构
- 2【全志T113-S3_100ask】16-1 linux系统驱动四线电阻屏(tpadc、tslib)
- 3玩转#ChatGPT之“用Chat GPT 做出行攻略”_gpt设计行程
- 4数据挖掘实战-基于内容协同过滤算法的电影推荐系统_协同过滤算法 sklearn 电影推荐
- 5Git 克隆仓库 – git clone
- 6如果你也23岁(1)_23岁能做什么知乎
- 7IDC发布AI训练数据市场分析最新报告_ai数据训练市场
- 8taro微信小程序跳转另一个小程序(参数接收、销毁,清除缓存)_taro小程序跳转唯品会小程序
- 9gitcode 上传文件报错文件太大has exceeded the upper limited size_start git hooks checking error: deny by project ho
- 10R语言社区发现算法检测心理学复杂网络:spinglass、探索性图分析walktrap算法与可视化...
Spark - 一文搞懂 Partitioner_spark partitioner
赞
踩
一.引言
spark 处理 RDD 时提供了 foreachPartition 和 mapPartition 的方法对 partition 进行处理,一个 partition 内可能包含一个文件或者多个文件的内容,Partitioner 可以基于 pairRDD 的 key 实现自定义 partition 的内容。

Partitioner 函数最基本的两个方法是 numPartitions 和 getPartition(key: Any):
A.numPartitions: 获取总的分区数
B.getPartition:
根据 key 获取当前 partition 对应的分区数目,范围在 [0, numPartitions-1],这里的 partitionId 与 TaskContext.getPartitionId 的值一致,通过 hash(key) 得到 int 的 partitionNum 变量,相同 partitonNum 的 key 对应的 paidRDD 将分到同一个 partition 内处理
常见的 Partition 分区类型有如下几种:
| 分区函数 | 分区方法 |
| HashPartitioner | 根据 hash(key) 分区 |
| RangePartitioner | 根据 Range 边界分区 |
| Partitioner | 根据自定义规则分区 |
二.HashPartitioner
1.源码分析
hashPartitioner 基于 Object.hashcode % partitionNum 进行分区,需要注意 partitionNum 的值是需要 >= 0 的,partiionNum 的获取通过 getPartition 函数内的 nonNegativeMod 函数实现
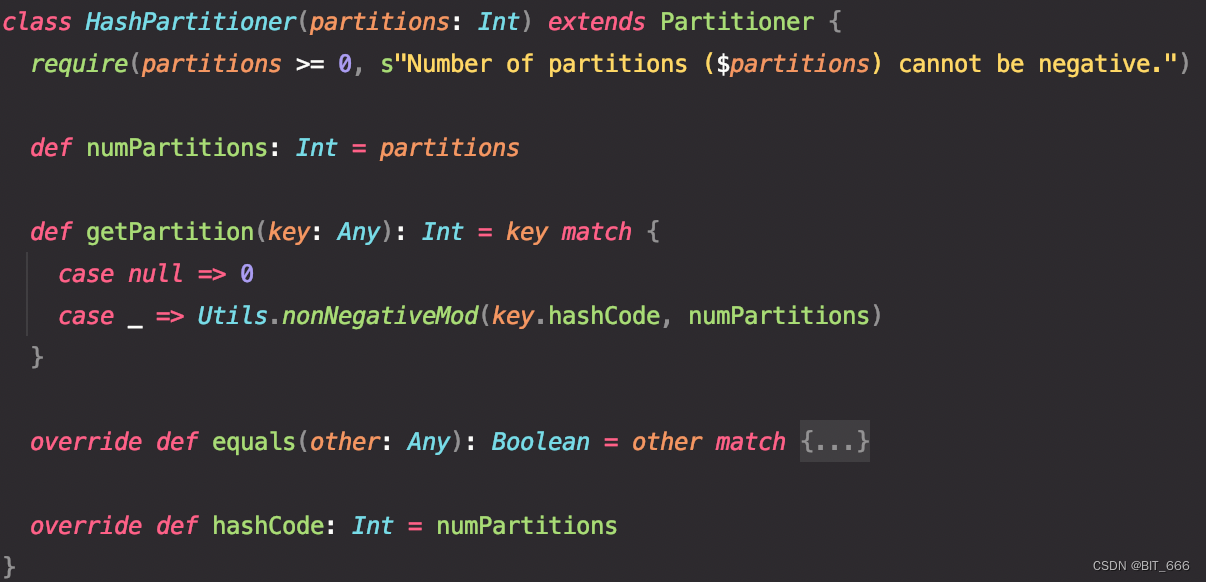
nonNegativeMod 在实现 hashCode % partitionNum 的基础上增加了非负性的要求,因为 partitionNum 是大于等于 0 的数目:

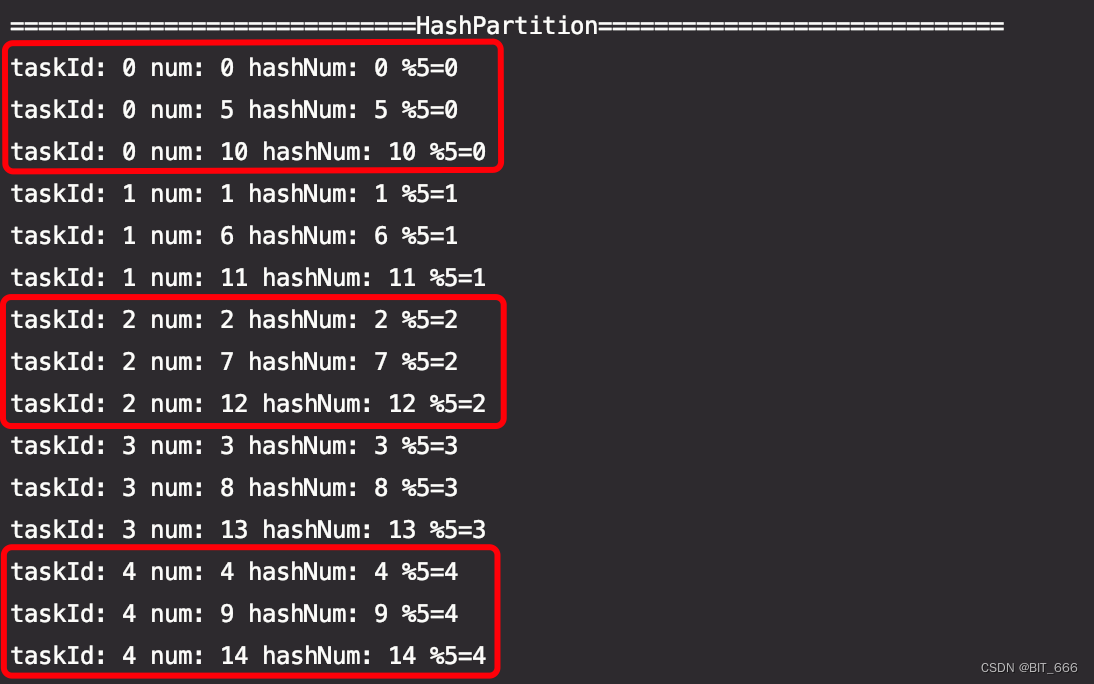
2.代码测试
- val testRdd = sc.parallelize((0 until 500).toArray.zipWithIndex)
- val partitionNum = 5
-
- testRdd.partitionBy(new HashPartitioner(partitionNum)).foreachPartition(partition => {
- if (partition.nonEmpty) {
- val info = partition.toArray.map(_._1)
- val taskId = TaskContext.getPartitionId()
- info.take(3).map(num => println(s"taskId: $taskId num: $num hashNum: ${num.hashCode()} %$partitionNum=${num.hashCode() % 5}"))
- }
- })
这里将 0-499 共 500 个数字 zipWithIndex 生成 pairRdd 并通过 HashPartitioner 生成 5 个 Partition,通过 TaskContext 获取 partitionId,为了日志一一打印,这里采用 local[1] 的配置 :
val conf = new SparkConf().setAppName("PartitionTest").setMaster("local[1]")
可以看到红框内同一个 TaskId 对应的 partition 内的 key 都具有相同的 mod 值,所以被分到同一分区。
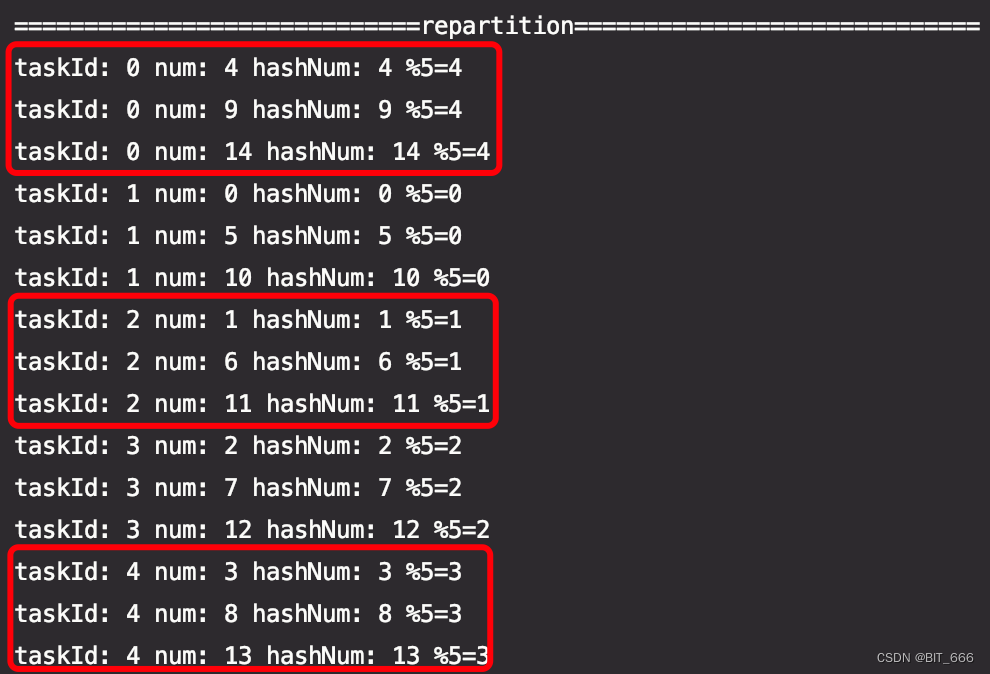
3.repartition
正常使用的 repartition 函数采用 HashPartitioner 函数作为默认分区函数,下面尝试一下:
- println("=============================repartition=============================")
- testRdd.repartition(5).foreachPartition(partition => {
- if (partition.nonEmpty) {
- val info = partition.toArray.map(_._1)
- val taskId = TaskContext.getPartitionId()
- info.take(3).map(num => println(s"taskId: $taskId num: $num hashNum: ${num.hashCode()} %$partitionNum=${num.hashCode() % 5}"))
- }
- })
与上面不同的是 taskId 有区别,但是相同 mod 的 key 仍然会分到同一分区:
三.RangePartitioner
1.源码分析
RangePartitioner 根据范围将元素大致均匀的分配至不同分区 partition,范围通过传入 RDD 的内容采样来确定。
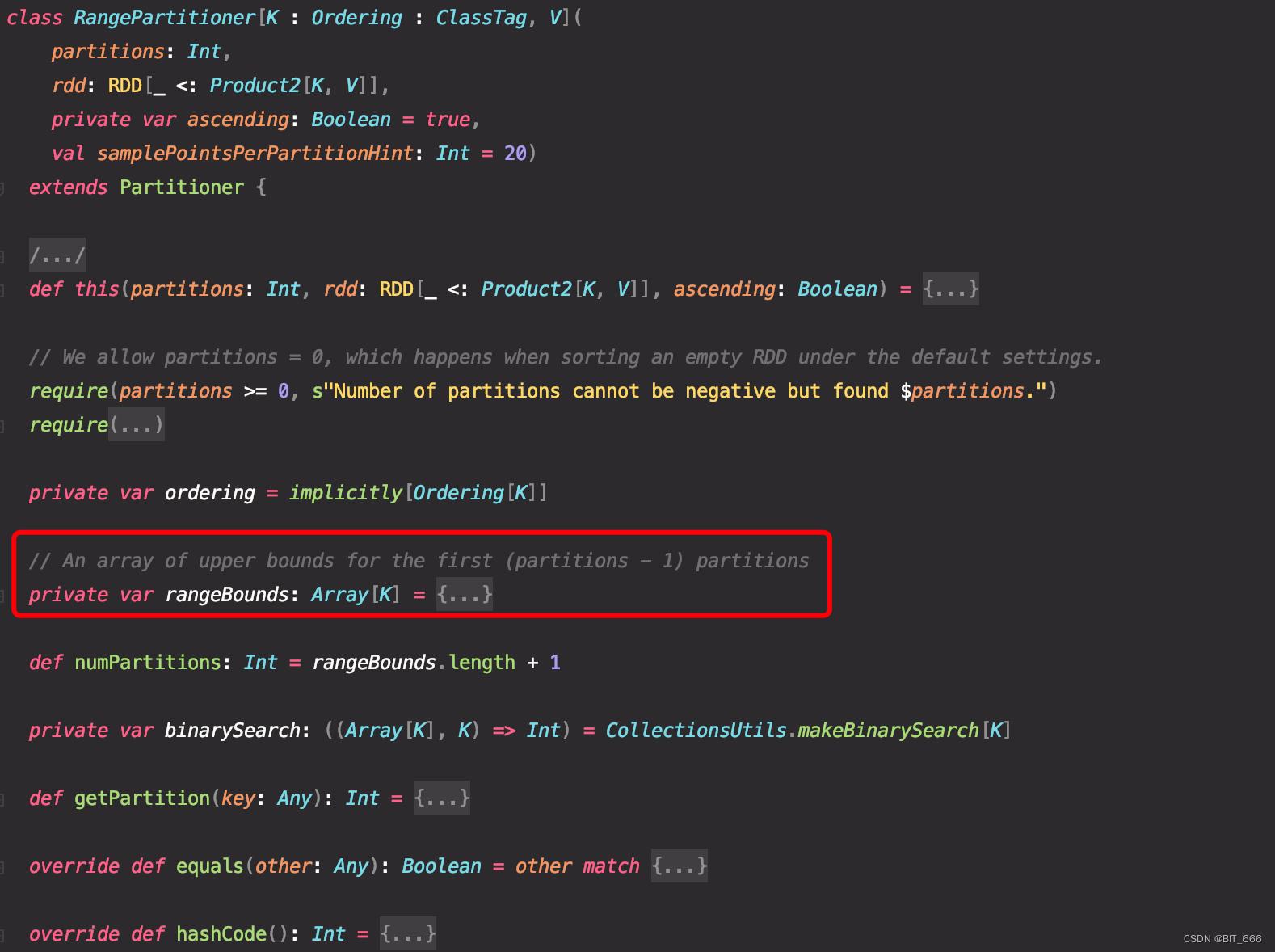
除了 partitions 的参数外,RangePartitioner 还需要将待分区的 rdd 传入供随机采样生成 rangeBounds 使用,相比于 HashPartition 直接 hashCodes % partitionNum 的操作,RangePartitioner 分区共分两步:
A.获取分区 Boundary
需要采样的分区样本大小上线为 1m,转换为 double 避免精度溢出,第一个 else 逻辑内考虑如果一个分区内包含的项目数远远超过平均数,则从中重新采样,以确保该分区能够收集到足够的采样数目,最下面的 if 函数使用所需的采样概率对不平衡分区重新采样,最终得到分区的边界,这里可以抽空单独拎出来研究一下。举个例子大致理解下,假如所有 partition 内的 key 的范围是 0-500,随机生成5个分区,则生成 101-203-299-405 这样的区间,每一个数字代表其分区的上界,例如分区0的上界为 101,分区1的上界为 203,依次类推,最终生成 5 个分区。
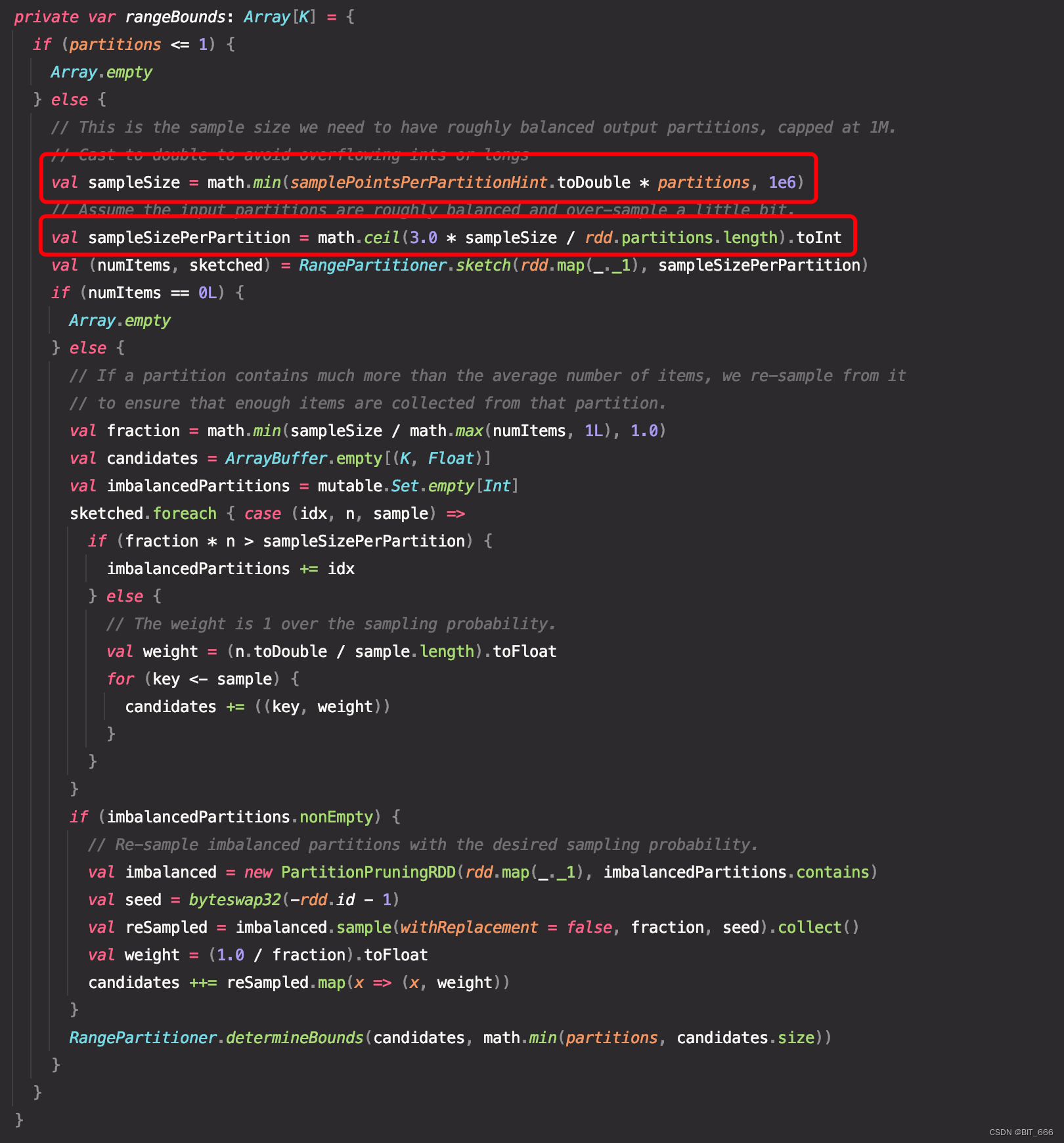
B.根据Boundary获取分区
如果分区数组长度不大于 128,则进行简单的暴力循环搜索,如果超过 128,则进行二分查找,同时提供根据 ascending 参数决定 partitionId 的顺序或逆序。这与之前 Spark-Scala 数据特征分桶时采用的优化策略一致,有兴趣可以看看:Scala - 数值型特征分桶。
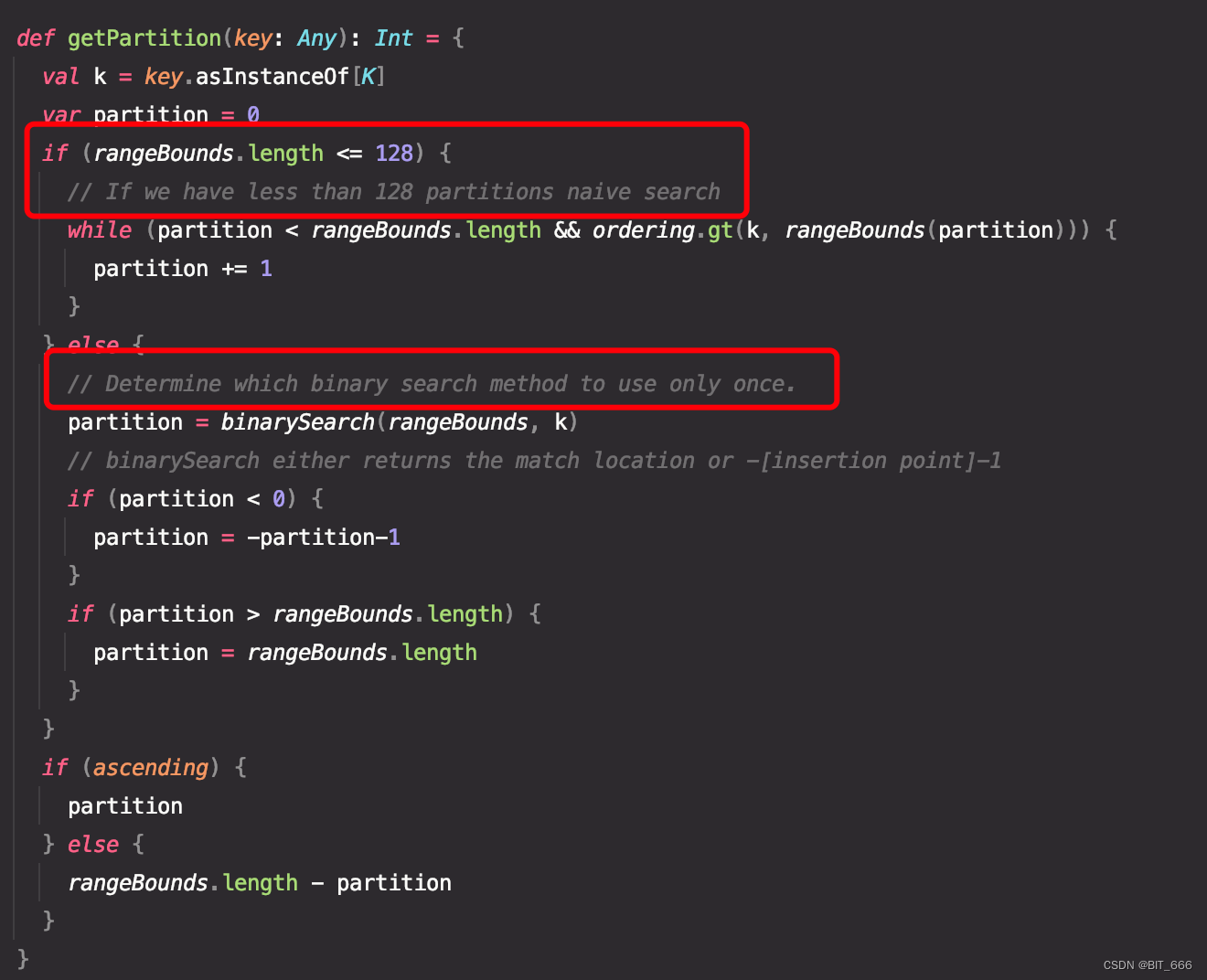
2.代码测试
- val testRdd = sc.parallelize((0 until 500).toArray.zipWithIndex)
-
- testRdd.partitionBy(new RangePartitioner(5, testRdd)).foreachPartition(partition => {
- if (partition.nonEmpty) {
- val info = partition.toArray.map(_._1)
- val taskId = TaskContext.getPartitionId()
- info.take(3).map(num => println(s"taskId: $taskId num: $num hashNum: ${num.hashCode()} length: ${info.length}"))
- }
- })
依然使用 500 个纯数字 RDD 进行 range 分区的测试,为了验证大致均分的思想,这里最后不再打印 mod 结果,转而打印每个 partition 内元素的数量,可以看到这次每组数量不像之前 HashPartitioner 得到的一样均匀,而是介于 500/5=100 的上下,但是总数为 500。
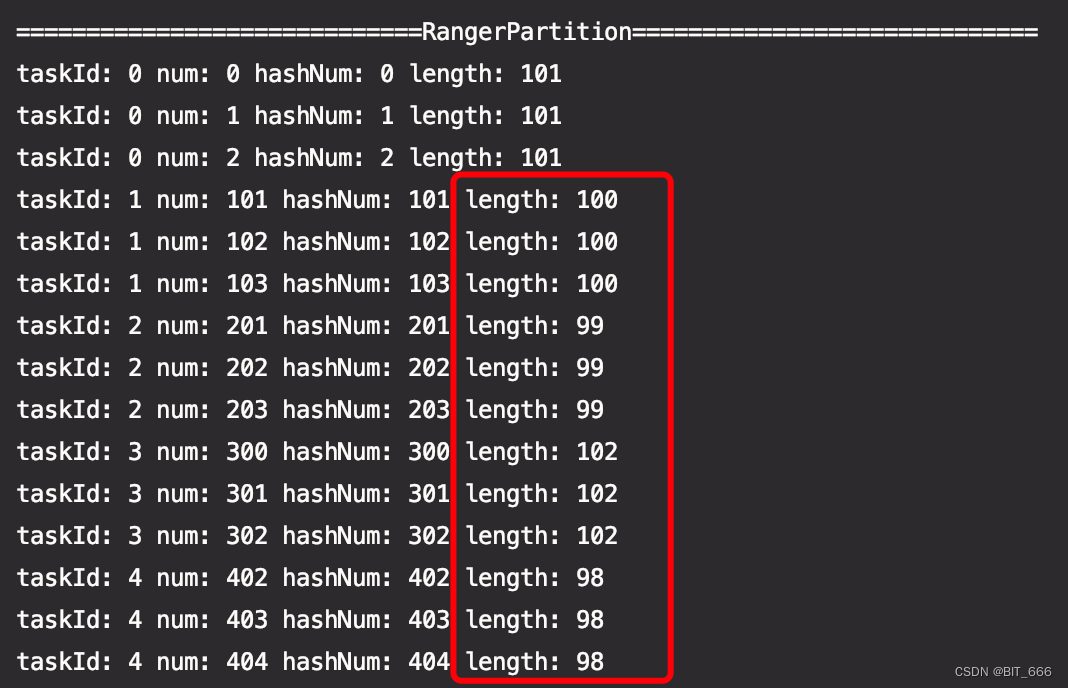
四.SelfPartitioner
1.源码分析
自定义 Partitioner 主要实现下述两个功能,上面也提到了,再简单补充下:
numPartitions: 获取总的分区数
getPartition: 获取 key 对应的分区 id
2.代码实现
A.SelfPartitioner
基于上面 RangePartitioner 分区不均匀的情况,我们采用 SelfParitioner 自定义分区的方式实现均匀分区,这里偷懒直接生成了对应的上界 boundary,实际场景中 boundary 应该基于 partitionNum 的数量动态生成,getPartition 函数内引入了 break 机制,不熟悉的同学可以移步:Scala - 优雅的break,随后就是基础的暴力循环,如果找到上界则返回上界对应的 index 作为分区 id。
- import scala.util.control.Breaks._
- class SelfPartition(partitionNum: Int) extends Partitioner {
-
- val boundary: Array[(Int, Int)] = Array(100, 200, 300, 400, 500).zipWithIndex
-
- override def numPartitions: Int = partitionNum
-
- override def getPartition(key: Any): Int = {
- val keyNum = key.toString.toInt
- var partitionNum = 0
- breakable(
- boundary.foreach(bound => {
- if (keyNum < bound._1) {
- partitionNum = bound._2
- break()
- }
- })
- )
- partitionNum
- }
- }

B.运行结果
- val testRdd = sc.parallelize((0 until 500).toArray.zipWithIndex)
-
- testRdd.partitionBy(new SelfPartition(5)).foreachPartition(partition => {
- if (partition.nonEmpty) {
- val info = partition.toArray.map(_._1)
- val taskId = TaskContext.getPartitionId()
- info.take(3).map(num => println(s"taskId: $taskId num: $num hashNum: ${num.hashCode()} length: ${info.length}"))
- }
- })
通过 SelfPartitioner 分区后可以看到 0-499 共 500 个元素被均匀分配到 5 个 Partition 内,除了最简单的 boundary 方法分区外,也可以自定义 hash 方法,key 的类型默认为 Any,如果 key 不是 scala 的基本数据类型,则使用 key.asInstanceOf[T] 转换即可。
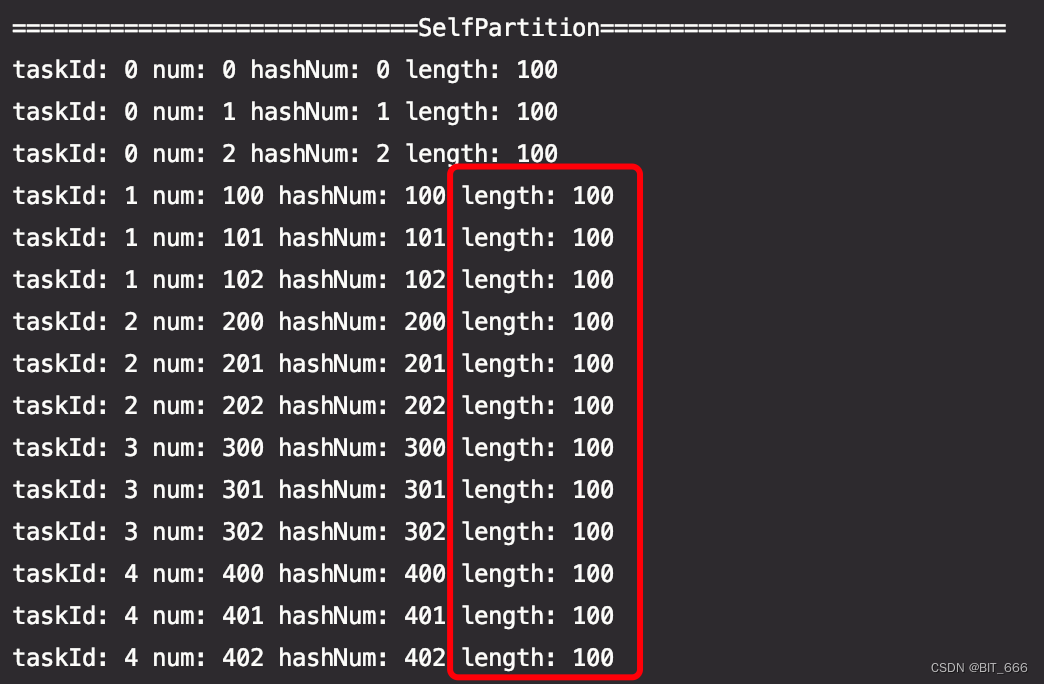
五.repartitionAndSortWithinPartitions
1.函数分析

除了正常的分区需求外,spark 还提供 repartitionAndSortWithinPartitions 函数,该函数根据给定的分区器 Partitioner 进行分区划分得到新的 RDD,并根据每个键进行排序,使得 RDD 中的数据保持一定顺序,该方法比 repartition + sorting 更加高效,因为它把排序机制放入了 shuffle 的过程中。

源码中该方法位于 OrderedRddFunctions 类内,只支持传入分区函数 Partitioner,ordering 排序规则需要使用 implict 传入隐函数的方法定义:
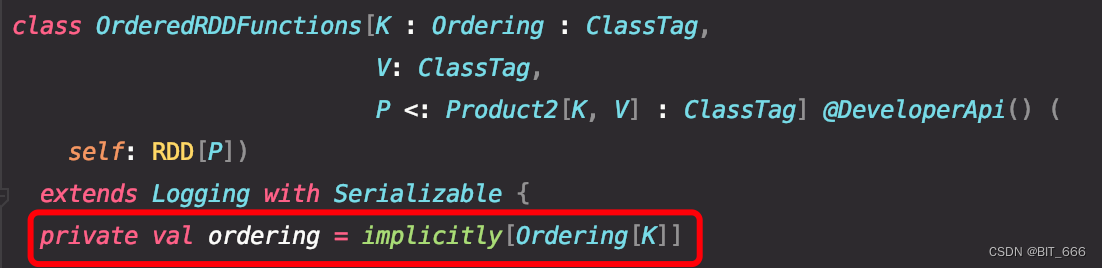
对于需要分区的 key: Any,需要定义隐函数保证其实现 Ordering 接口才能实现分区后排序,否则只能分区没有排序。
2.代码实现
A.分区排序依据
在分区函数的基础上,增加了 Ordering 隐函数,这里 Partitioner 函数仍然负责根据 key 得到分区 Id,和上面不同的时,分区的同时对 rdd 进行 shuffle,其中 order 的规则由隐函数给出,这里通过比较二者的分数进行排序,如果想要逆序只需要添加负号即可 -(x.score - y.score)。
- // 学生类
- case class Student(name: String, score: Int)
-
- // 隐函数-Ordering
- implicit object StudentOrdering extends Ordering[Student] {
- override def compare(x: Student, y: Student): Int = {
- x.score - y.score
- }
- }
-
- class SelfSortPartition(partitionNum: Int) extends Partitioner {
-
- val boundary: Array[(Int, Int)] = Array(100, 200, 300, 400, 500).zipWithIndex
-
- override def numPartitions: Int = partitionNum
-
- override def getPartition(key: Any): Int = {
- val stuKey = key.asInstanceOf[Student]
- val keyNum = stuKey.name.toInt
- var partitionNum = 0
- breakable(
- boundary.foreach(bound => {
- if (keyNum < bound._1) {
- partitionNum = bound._2
- break()
- }
- })
- )
- partitionNum
- }
- }
B.主函数
这里使用 0-499 的 String 类型作为学生的编号,Score 则采取 math.random x 100 进行模拟,分区使用 Student 的 name id,所以每个元素的分区不变,变的是每个元素的顺序。
- println("=============================SortPartition=============================")
- val studentRdd = sc.parallelize((0 until 500).toArray.map(num => (Student(num.toString, (math.random * 100).toInt), true)))
- studentRdd.take(5).foreach(println(_))
-
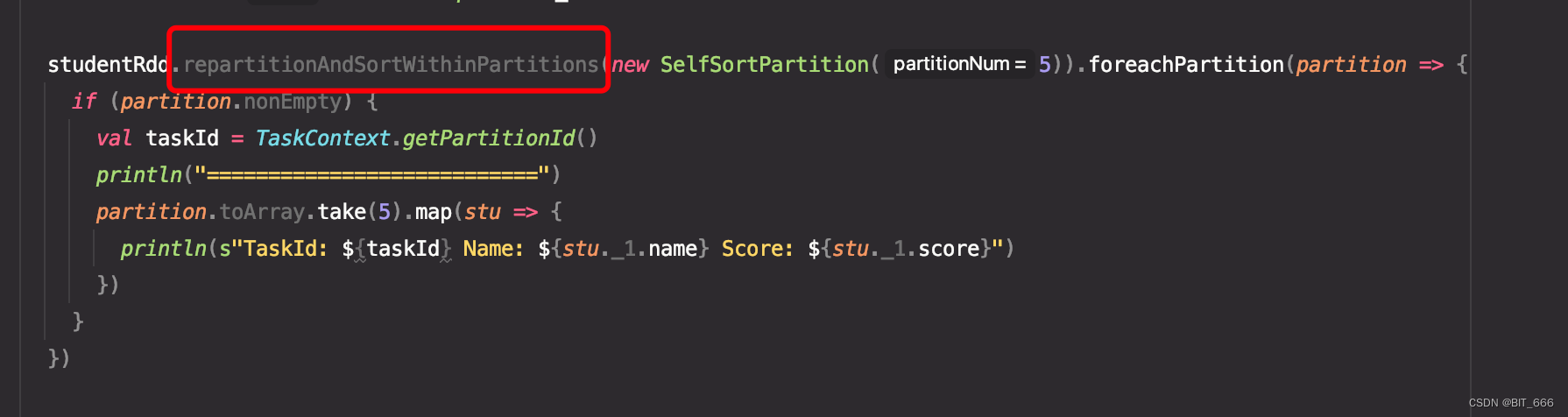
- studentRdd.repartitionAndSortWithinPartitions(new SelfSortPartition(5)).foreachPartition(partition => {
- if (partition.nonEmpty) {
- val taskId = TaskContext.getPartitionId()
- println("===========================")
- partition.toArray.take(5).map(stu => {
- println(s"TaskId: ${taskId} Name: ${stu._1.name} Score: ${stu._1.score}")
- })
- }
- }
由于使用 x.score - y.score 顺序计数,所以按分数从小到大排序:
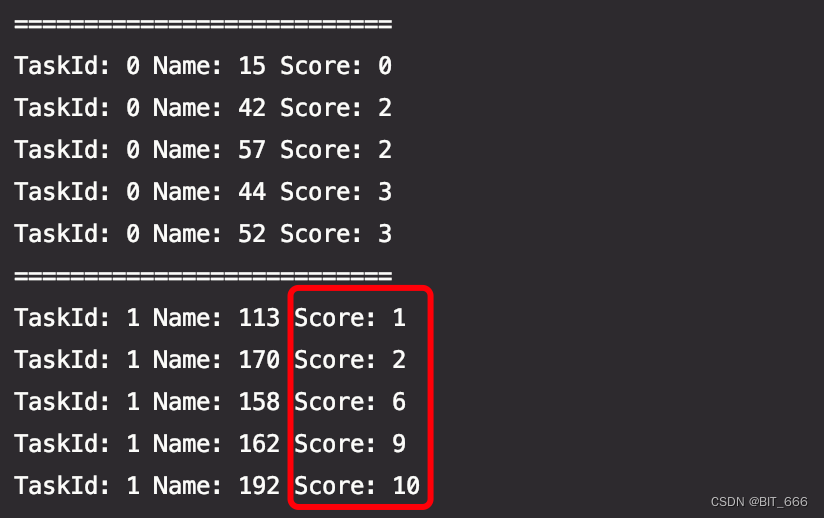
这一届是带过最差的学生,咋还能考0分。
C.其他写法
除了 StudentOrdering 的写法,也可以采用直接 Object Student 的写法,这里 A <: Student 表示任何 A 的子类都支持该隐式调用,关于 <: 相关知识可以参考:Scala Generic 泛型类详解 - T
- object Student {
- implicit def orderingByGradeStudentScore[A <: Student]: Ordering[A] = {
- Ordering.by(stu => stu.score)
- }
- }
-
-
- implicit object StudentOrdering extends Ordering[Student] {
- override def compare(x: Student, y: Student): Int = {
- x.score - y.score
- }
- }
如果想要支持多重排序,可以在元祖内增加多个字段,会优先比较 name 再比较 score,以此类推,同理如果想要逆序,例如根据分数逆序排列,则改为 (stu.name,-1 * stu.score)
- object Student {
- implicit def orderingByGradeStudentScore[A <: Student]: Ordering[A] = {
- Ordering.by(stu => (stu.name, stu.score))
- }
- }
如果对应的分区 key 没有实现 implict 的比较隐函数,则函数会直接报灰,无法编译:
六.总结
Partitioner 的一般用法大致就这些,除了三种 HashPartitioner 函数外,Spark 也可以通过 repartitionAndSortWithinPartitions 实现分区 + 排序的需求,总体来说,Partitioner 支持用户自定义分区规则去规划任务的 task 需要处理什么样的 partition 数据,对于精细化处理和区域化定制的需求十分方便,除此之外,一些需要顺序处理的数据或者顺序存储的数据,通过 SortWithinPartitions 的方法也可以提高效率,非常奈斯
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

