
- 1【TensorFlow深度学习】状态值函数Vπ与最优策略π∗的求解方法
- 2Android Broadcast 和 BroadcastReceiver的权限限制_android:关闭broadcast receiver 组件导 出权限
- 3大模型日报3月19日_clarity upscaler
- 4电脑显示未安装任何音频输出设备_这款直播神器你知道么?(附详细安装教程)...
- 5【C++】stringstream_使用 stringstream 实现整数排序。要求把输入保存到在一个stringstream对象中,
- 6十分钟安装Tensorflow-gpu2.6.0+本机CUDA12 以及numpy+matplotlib各包版本协调问题_tensorflow cuda12
- 7校园网组建 (基于Packet tracer)
- 8git下载安装及clone出现错误的解决方法_git clone couldn't connect to server
- 904_服务注册Eureka_服务注册到eureka
- 10ADS仿真工具使用_ads仿真软件
网页数据提取 -- 正则表达式_用正则表达式获取网页指定数据
赞
踩
目录
1. 概述
Regular Expression,译作正则表达式或正规表示法,表示有规则的表达式,意思是说,描述一段文本排列规则的表达式。
>
正则表达式并不是Python的一部分。而是一套独立于编程语言,用于处理复杂文本信息的强大的高级文本操作工具。正则表达式拥有自己独特的规则语法以及一个独立的正则处理引擎,我们根据正则语法编写好规则(模式)以后,引擎不仅能够根据规则进行模糊文本查找,还可以进行模糊分割,替换等复杂的文本操作,能让开发者随心所欲地处理文本信息。正则引擎一般由编程语言提供操作,像python就提供了re模块或regex模块来调用正则处理引擎。
>
正则表达式在处理文本的效率上不如系统自带的字符串操作,但功能却比系统自带的要强大许多。
>
最早的正则表达式来源于Perl语言,后面其他的编程语言在提供正则表达式操作时基本沿用了Perl语言的正则语法,所以我们学习python的正则以后,也可以在java,php,go,javascript,sql等编程语言中使用。
>
★ 于爬虫而言,正则是最基础的一个数据解析工具
● 正则是基于对字符串或文本的处理:无非是分割、匹配、查找和替换。
● 正则在线测试工具 http://tool.chinaz.com/regex/
2. 元字符
元字符(Metacharacters),元字符是具有特殊含义的字符。
Python提供了处理正则表达式的模块有标准库的re模块和第三方模块regex。
导入`re`模块后,可以开始使用正则表达式了。
基础元字符:
| 元字符 | 描述 |
| . | 叫通配符、万能通配符或通配元字符,匹配1个除了换行符\n以外任何原子 |
| [] | 匹配一个中括号中出现的任意原子 |
| [^原子] | 匹配一个没有在中括号出现的任意原子 ,字符取反/非 |
使用示例如下:
- import re
-
- # 通配符:.也叫万能通配符或通配元字符,匹配1个除了换行符\n以外任何原子
- ret = re.findall(".", "a,b,c,d,e")
- ret1 = re.findall("a.b","a,b,c,d,e,acb,abb,a\nb,a\tb")
- print("ret:",ret)
- print("ret1:",ret1)
- print("*" * 40)
-
- #字符集:[] 匹配一个中括号中出现的任意原子
- ret3 = re.findall("[ace]", "a,b,c,d,e")
- ret4 = re.findall("a[ace]f", "af,abbf,acef,aef")
- print("ret3:",ret3)
- print("ret4:",ret4)
- ret5 = re.findall("[a-z]", "a,b,c,d,e") #提取所有小写字母
- ret6 = re.findall("[0-9]", "1,2,3,4,5") #提取所有数字
- ret7 = re.findall("[a-zA-Z]", "a,b,c,d,e,A,B,C") #提取所有小写和大写字母
- ret8 = re.findall("[a-z0-9A-Z]", "a,b,c,d,e,1,2,3,4,E,F,G") #提取所有大/小写字母+数字
- print("ret5:",ret5)
- print("ret6:",ret6)
- print("ret7:",ret7)
- print("ret8:",ret8)
- print("*" * 40)
-
-
- #\d取所有数字,,只能匹配一个符号
- ret9 = re.findall("\d", "a,b,c,d,e,1,2,3,4,E,F,G")
- print("ret9:",ret9)
- #\w取所字符,只能匹配一个符号
- ret10 = re.findall("\w", "a,b,c,d,e,1,2,3,4,E,F,G")
- print("ret10:",ret10)
-
- #字符集取反,不包含的意思:取不包含0-9的字符
- ret11 = re.findall("[^0-9]", "a,b,c,d,e,1,2,3,4,E,F,G")
- print("ret11:",ret11)
-
-
- #输出:
- ret: ['a', ',', 'b', ',', 'c', ',', 'd', ',', 'e']
- ret1: ['a,b', 'acb', 'abb', 'a\tb']
- ****************************************
- ret3: ['a', 'c', 'e']
- ret4: ['aef']
- ret5: ['a', 'b', 'c', 'd', 'e']
- ret6: ['1', '2', '3', '4', '5']
- ret7: ['a', 'b', 'c', 'd', 'e', 'A', 'B', 'C']
- ret8: ['a', 'b', 'c', 'd', 'e', '1', '2', '3', '4', 'E', 'F', 'G']
- ****************************************
- ret9: ['1', '2', '3', '4']
- ret10: ['a', 'b', 'c', 'd', 'e', '1', '2', '3', '4', 'E', 'F', 'G']
- ret11: ['a', ',', 'b', ',', 'c', ',', 'd', ',', 'e', ',', ',', ',', ',', ',', 'E', ',', 'F', ',', 'G']

重复元字符:
| 元字符 | 描述 |
| + | 叫加号贪婪符,指定左边原子出现1次或多次 |
| * | 叫星号贪婪符,指定左边原子出现0次或多次 |
| ? | 叫非贪婪符,指定左边原子出现0次或1次 |
| {n,m} | 叫数量范围贪婪符,指定左边原子的数量范围,有{n},{n, }, {,m}, {n,m}四种写法,其中n与m必须是非负整数。 |
代码示例如下:
- import re
-
- # 重复元字符: + * {} ?
- #取出所有完整的数字:
- ret = re.findall("\d", "a,b,234,D,6,888")
- print("ret:",ret) #结果是234/888都被拆分了
-
- # +:表示1~无穷次(默认贪婪),所以结果符合取出所有数字的预期
- ret1 = re.findall("\d+", "a,b,234,D,6,888")
- print("ret1:",ret1)
- print("*" * 50)
-
- '''
- ?的两个功能:
- 1、取消贪婪:只需要再+后面写一个?
- 2、表示:0次或1次
- '''
- ret2 = re.findall("\d+?", "a,b,234,D,6,888") #取消贪婪匹配(等同\d效果)
- print("ret2:",ret2)
- ret3 = re.findall("abc?","abc,abcc,abe,ab")
- print("ret3:",ret3)
- print("*" * 50)
-
- # *:表示0~多次
- ret4 = re.findall("\w+", "apple,banana,orange,melon")
- print("ret4:",ret4)
- ret5 = re.findall("\w?", "apple,banana,orange,melon") #等同\w
- print("ret5:",ret5)
- ret6 = re.findall("\w*", "apple,banana,orange,melon") #0次会包含空值
- print("ret6:",ret6)
- print("*" * 50)
-
- '''
- {m,n}:表示从多少次~多少次,固定区间
- 也可以单写一个数:取出6个字符的单词
- '''
- ret7 = re.findall("\w{6}?", "apple,banana,orange,melon")
- print("ret7:",ret7)
- ret8 = re.findall("\w{1,5}?", "abc,abcc")
- print("ret8:",ret8)
-
-
- #输出:
- ret: ['2', '3', '4', '6', '8', '8', '8']
- ret1: ['234', '6', '888']
- **************************************************
- ret2: ['2', '3', '4', '6', '8', '8', '8']
- ret3: ['abc', 'abc', 'ab', 'ab']
- **************************************************
- ret4: ['apple', 'banana', 'orange', 'melon']
- ret5: ['a', 'p', 'p', 'l', 'e', '', 'b', 'a', 'n', 'a', 'n', 'a', '', 'o', 'r', 'a', 'n', 'g', 'e', '', 'm', 'e', 'l', 'o', 'n', '']
- ret6: ['apple', '', 'banana', '', 'orange', '', 'melon', '']
- **************************************************
- ret7: ['banana', 'orange']
- ret8: ['a', 'b', 'c', 'a', 'b', 'c', 'c']
位置元字符:
| 元字符 | 描述 |
| ^ | 叫开始边界符或开始锚点符,匹配一行的开头位置 |
| $ | 叫结束边界符或结束锚点符,匹配一行的结束位置 |
代码示例如下:
- import re
-
- # 位置元字符: ^ $
- #取最开始的数字字符,第一个字符不是数字,则返回空列表
- ret = re.findall("^\d+", "34,banana,255,orange,65536")
- print("ret:",ret)
-
- #取末尾的字符
- ret1 = re.findall("\w+$", "peach,34,banana,255,orange,65536")
- print("ret1:",ret1)
-
- #举个栗子:取网页数据,前面规则定好,不论后面数字是多少都可以取到
- ret2 = re.findall("/goods/food/\d+","/goods/food/1003")
- print("ret2:",ret2)
-
- #只要符合"/goods/food/\d+"规则的,都可以取到
- ret3 = re.findall("/goods/food/\d+","server/app01/goods/food/1003")
- print("ret3:",ret3)
-
- #加开头和结尾,限制了完整性,返回空列表
- ret4 = re.findall("^/goods/food/\d+$","server/app01/goods/food/1003")
- print("ret4:",ret4)
-
-
-
- #输出:
- ret: ['34']
- ret1: ['65536']
- ret2: ['/goods/food/1003']
- ret3: ['/goods/food/1003']
- ret4: []
其他元字符
| 元字符 | 描述 |
| | | 指定原子或正则模式进行二选一或多选一 |
| () | 对原子或正则模式进行捕获提取、分组划分整体操作 |
代码示例如下:
- import re
-
- '''其他元素符:
- |:指定原子或正则模式进行二选一、或者多选一
- ():具备模式捕获的能力,也就是优先提取数据的能力,通过(?:) 可以取消模式捕获
- '''
- #提取5个字母组成的单词,不同方式对比:
- #筛选出5个字符的单词,前后带逗号
- ret = re.findall(",\w+,", ",apple,banana,peach,orange,melon,")
- print('ret:',ret)
-
- # 筛选出5个字符的单词,前后带逗号
- ret1 = re.findall(",\w{5},", ",apple,banana,peach,orange,melon,")
- print('ret1:',ret1)
-
- # 筛选出5个字符的单词,不带逗号,仅单词;最优方式
- ret2 = re.findall(",(\w{5}),", ",apple,banana,peach,orange,melon,")
- print('ret2:',ret2)
-
- #输出:
- ret: [',apple,', ',peach,', ',melon,']
- ret1: [',apple,', ',peach,', ',melon,']
- ret2: ['apple', 'peach', 'melon']
-
-
-
-
- #提取邮箱,不同方式对比:
- # 筛选出所有邮箱
- ret3 = re.findall("\w+@\w+\.com", "123abc@163.com,....234xyz@qq.com,....")
- print('ret3:',ret3)
-
- #筛选邮箱中的qq号
- ret4 = re.findall("(\w+)@qq\.com", "123abc@163.com,....234xyz@qq.com,....")
- print('ret4:',ret4)
-
- #筛选所有qq邮箱和163邮箱,最优
- ret5 = re.findall("(?:\w+)@(?:qq|163)\.com", "123abc@163.com,....234xyz@qq.com,....")
- print('ret5:',ret5)
-
-
- #输出:
- ret3: ['123abc@163.com', '234xyz@qq.com']
- ret4: ['234xyz']
- ret5: ['123abc@163.com', '234xyz@qq.com']
转义符:
● 转义符(/)的两个功能:
1、将一些普通符号赋予特殊功能
2、将特符号取消取特殊功能
● 加上不同的字母后,作用不同
汇总如下:
| 元字符 | 描述 |
| \d | 匹配一个数字原子,等价于`[0-9] |
| \D | 匹配一个非数字原子。等价于`[^0-9]`或`[^\d] |
| \w | 匹配一个包括下划线的单词原子。等价于`[A-Za-z0-9_] |
| \W | 匹配任何非单词字符。等价于`[^A-Za-z0-9_]` 或 `[^\w] |
| \n | 匹配一个换行符 |
| \s | 匹配一个任何空白字符原子,包括空格、制表符、换页符等等。等价于`[ \f\n\r\t\v] |
| \S | 匹配一个任何非空白字符原子。等价于`[^ \f\n\r\t\v]`或 `[^\s] |
| \b | 匹配一个单词边界原子,也就是指单词和空格间的位置 |
| \B | 匹配一个非单词边界原子,等价于 `[^\b] |
| \t | 匹配一个制表符,tab键 |
取一个有点绕的"\b"转义符示例:
- import re
-
- '''
- 转义符(/) :
- 两个功能:
- 1、将一些普通符号赋予特殊功能
- 2、将特符号取消取特殊功能
- '''
- #\b:单词边界效果:
- txt = "my name is nana.nihao,nana"
- ret = re.findall(r"\bna",txt)
- print(ret)
- ret1 = re.findall(r"\bna\w+",txt)
- print(ret1)
-
-
- #输出:
- ['na', 'na', 'na']
- ['name', 'nana', 'nana']
3. 常用正则表达式
● raw-string翻译为:原生字符串;
使用正则时,可以加不加r,也不会报错,但是保险起见还是加上r
● 工作中,正则一般用于验证数据、校验用户输入的信息、爬虫、运维日志分析等。
其中如果是验证用户输入的数据:
| 场景 | 正则表达式 |
| 用户名 | ^[a-z0-9_-]{3,16}$ |
| 密码 | ^[a-z0-9_-]{6,18}$ |
| 手机号码 | ^(?:\+86)?1[3-9]\d{9}$ |
| 颜色的十六进制值 | ^#?([a-f0-9]{6}|[a-f0-9]{3})$ |
| 电子邮箱 | ^[a-z\d]+(\.[a-z\d]+)*@([\da-z](-[\da-z])?)+\.[a-z]+$ |
| URL | ^(?:https:\/\/|http:\/\/)?([\da-z\.-]+)\.([a-z\.]+).\w+$ |
| IP 地址 | ((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?) |
| HTML 标签 | ^<([a-z]+)([^<]+)*(?:>(.*)<\/\1> |
| utf-8编码下的汉字范围 | ^[\u2E80-\u9FFF]+$ |
4. re模块的方法
python本身没有内置正则处理的,python中的正则就是一段字符串,我们需要使用python模块中提供的函数把字符串发送给正则引擎,正则引擎会把字符串转换成真正的正则表达式来处理文本内容。
`re`模块提供了一组正则处理函数,使我们可以在字符串中搜索匹配项:
| 函数 | 描述 |
| findall | 按指定的正则模式查找文本中所有符合正则模式的匹配项,以列表格式返回结果。 |
| search | 在字符串中**任何位置**查找首个符合正则模式的匹配项,存在则返回re.Match对象, 不存在返回None |
| match | 判定字符串**开始位置**是否匹配正则模式的规则,匹配则返回re.Match对象, 不匹配返回None |
| split | 按指定的正则模式来分割字符串,返回一个分割后的列表 |
| sub/subn | 把字符串按指定的正则模式来查找符合正则模式的匹配项,并可以替换一个或多个匹配项成其他内容 |
| compile | 编译:编译一个具体的查找规则,后续相同规则时直接调用 |
代码示例如下:
- import re
- #findall方法:
- ret = re.findall("\d+","apple 122 peach 34")
- print("ret:",ret)
- #输出:
- ret: ['122', '34']
-
-
- #search:返回的是符合的匹配对象的位置
- ret1 = re.search("\d+","apple 122 peach 34")
- print("ret1:",ret1)
- print("ret1:",ret1.group())
- #输出:
- ret1: <re.Match object; span=(6, 9), match='122'>
- ret1: 122
-
-
-
- #search结合有名分组:将要去提取的手机号、邮箱都取个名
- rel = re.search("(?P<tel>1[3-9]\d{9}).*?(?P<email>\d+@qq.com)", "我的手机号码是13928835900,我的邮箱是123@qq.com")
- print("rel:",rel)
- print(rel.group("tel"))
- print(rel.group("email"))
- #输出:
- rel: <re.Match object; span=(7, 34), match='13928835900,我的邮箱是123@qq.com'>
- 13928835900
- 123@qq.com
-
-
- # match方法:比search多一个起始判断^
- #rel2不满足起始为1,所有返回None
- rel2 = re.match("^1[3-9]\d{9}.*?", "我的手机号码是13928835900,我的另一个手机号是13711112255")
- print("rel2:",rel2)
-
- #满足起始为1
- rel3 = re.match("^1[3-9]\d{9}.*?", "13928835900,我的另一个手机号是13711112255")
- print("rel3:",rel3.group())
-
-
- #输出:
- rel1: None
- rel2: 13928835900
- import re
- #split方法:字符串分割
- txt = "my name is moluo"
- ret = re.split("\s", txt)
- print(ret)
- #输出:
- ['my', 'name', 'is', 'moluo']
-
-
- #sub/subn:函数用选择的文本替换匹配
- s = "12 23 45 67 "
- #将所有数字都替换为hello world
- ret1 = re.sub("\d+","hello",s)
- print("ret1:",ret1)
-
-
- #只替换前2个数字
- ret2 = re.sub("\d+","hello",s,2)
- print("ret2:",ret2)
- #输出:
- ret1: hello hello hello hello
- ret2: hello hello 45 67
-
-
- #compile方法:编译
- s1 = "12 apple 34 peach 77 banana"
- rl = re.findall("\d+",s1)
-
- s2 = "18 apple 39 peach 99 banana"
- rl2 = re.findall("\d+",s2)
- '''
- 可以看出每次都重新写了一遍findall查找规则
- 所以,我们可以直接把规则做个定义,直接引用,简单省力
- '''
- reg = re.compile(r"\d+") #定义规则
- print("rl:",reg.findall(s1)) #调用编译好的规则
- print("rl2:",reg.findall(s2))
- #输出:
- rl: ['12', '34', '77']
- rl2: ['18', '39', '99']
5. 正则进阶使用
.*?
.*?:这三个符号凑在一起,威力无穷~
通过以下代码示例感受下:
- import re
-
- '''
- 正则进阶:.*?
- '''
- #需要提取txt中的所有内容,效果对比:
- text = '<12> <xyz> <!@#$%> <1a!#e2> <>'
- ret = re.findall("<.+>", text)
- print("ret:",ret)
-
- ret1 = re.findall("<.+?>", text)
- print("ret1:",ret1)
-
- ret2 = re.findall("<.*?>", text)
- print("ret2:",ret2)
-
-
- #输出:
- ret: ['<12> <xyz> <!@#$%> <1a!#e2> <>']
- ret1: ['<12>', '<xyz>', '<!@#$%>', '<1a!#e2>']
- ret2: ['<12>', '<xyz>', '<!@#$%>', '<1a!#e2>', '<>']
模式修正符
模式修正符,也叫正则修饰符,模式修正符就是给正则模式增强或增加功能的
| 修正符 | re模块提供的变量 | 描述 |
| i | re.I | 使模式对大小写不敏感,也就是不区分大小写 |
| m | re.M | 使模式在多行文本中可以多个行头和行位,影响 ^ 和 $ |
| s | re.S | 让通配符. 可以代码所有的任意原子(包括换行符\n在内) |
代码示例如下:
- import re
-
- '''
- 正则进阶:模式修正符
- .*?搭配re.S
- '''
- #提取所有<>里的内容:
- text = """
- <12
- >
- <x
- yz>
- <!@#$%>
- <1a!#
- e2>
- <>
- """
-
- ret = re.findall("<.*?>", text)
- print("ret:",ret)
- ret1 = re.findall("<.*?>", text, re.S)
- print("ret1:",ret1)
-
- #输出:
- ret: ['<!@#$%>', '<>']
- ret1: ['<12\n>', '<x\n yz>', '<!@#$%>', '<1a!#\n e2>', '<>']
6. 正则解析数据demo
以豆瓣电影top250为例,进行正则表达式的学以致用,进行提取第一页的25部电影名字
可以看出,电影名被嵌套在多个div标签中
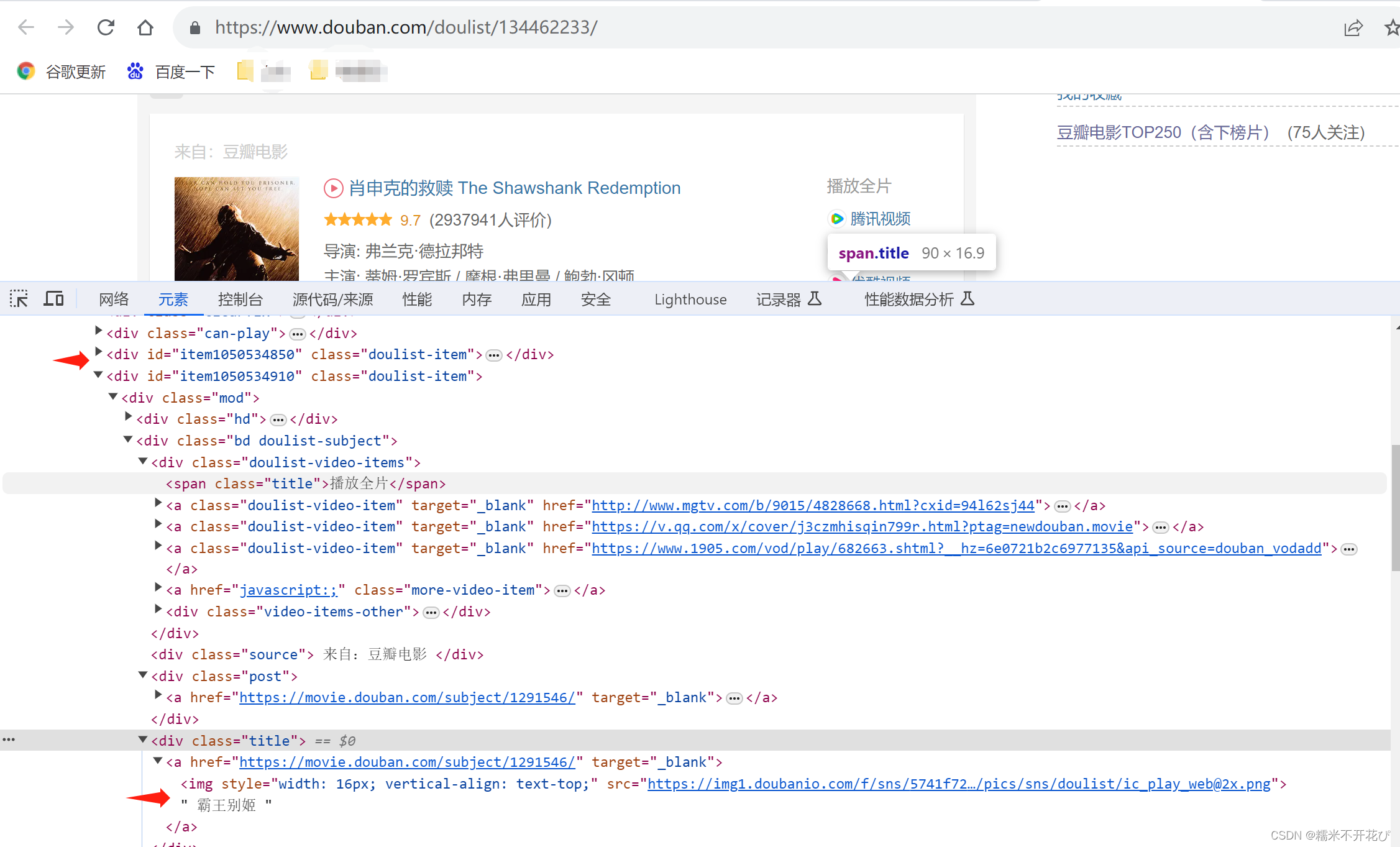
初级水平,简单处理步骤:
1. 将所有的返回html内容,黏贴在html文件中
2. 新建一个py文件,进行导入html文件,然后开始电影名提取
- import re
- with open("douban.html",encoding="utf-8") as f:
- s = f.read()
- #提取所有的电影名
-
- ret = re.findall('<div class="title">\s+<a.*?>(.*?)</a>', s, re.S)
- for movie in ret:
- movie_name = re.sub(r'<.*?>', '', movie)
- print(movie_name.strip())
- print(len(ret))
-
-
- #输出:
- 肖申克的救赎 The Shawshank Redemption
- 霸王别姬
- 阿甘正传 Forrest Gump
- 泰坦尼克号 Titanic
- 这个杀手不太冷 Léon
- 美丽人生 La vita è bella
- 千与千寻 千と千尋の神隠し
- 辛德勒的名单 Schindler's List
- 盗梦空间 Inception
- 忠犬八公的故事 Hachi: A Dog's Tale
- 星际穿越 Interstellar
- 楚门的世界 The Truman Show
- 海上钢琴师 La leggenda del pianista sull'oceano
- 三傻大闹宝莱坞 3 Idiots
- 机器人总动员 WALL·E
- 放牛班的春天 Les choristes
- 无间道 無間道
- 疯狂动物城 Zootopia
- 大话西游之大圣娶亲 西遊記大結局之仙履奇緣
- 熔炉 도가니
- 教父 The Godfather
- 控方证人 Witness for the Prosecution
- 当幸福来敲门 The Pursuit of Happyness
- 怦然心动 Flipped
- 触不可及 Intouchables
- 25

