
- 1【博学谷学习记录】超强总结,用心分享| 拉链表_拉链表查询
- 2Pycharm+Git 配置 Github与Gitee的项目管理_pycharm gitee配置
- 3Windows靶机应急响应(一)_应急响应靶机
- 4c++按位运算
- 5Go 程序的文件名、标识符、关键字和包
- 6Hadoop 3.x(入门搭建+安装调优)(二-HDFS)_hadoop3 blockplacementpolicydefault找不到
- 7资管新政:真正干资管的时代来了!_资产管理业务csdn
- 8c++ string类构造函数(string变量与字符相结合)_c++如何把一个字符串和一个string变量连接
- 9第一章 信息化与信息系统 (2)_数据准备、存储与管理、计算处理、数据分析、知识展示
- 10Spark特征工程_特征工程商品种类最多spark
革命性新网络KAN【第二篇-相比MLP,KAN胜在哪?】_kan注意力架构在低维回归任务上的收敛速度较传统mlp更快
赞
踩
目录
本文承接【第一篇-base】,展开讲解KAN与MLP的对比。原文从不同角度给出了KAN相比MLP的优越性,同时也给出了KAN目前的一些限制。
下面就让我们从6个方面走进KAN。希望大家有所收获!
导言
与传统的MLP 相比,KAN 有4个主要特点:
1)激活函数位于“边”而不是节点(Node)上;
2)激活函数是可学习的而不是固定的;
3)可使用非线性核函数来替代MLP“边”(Edge)上的线性函数;
4)可设定细粒度的结点(Knot)来提高逼近精度。

在数学中,样条曲线是由多项式分段定义的函数。一般的Spline可以是特定区间的3阶多项式。
在插值问题中,样条插值通常优于多项式插值,因为即使使用低次多项式,也能产生类似的精度结果,同时避免了高次多项式的Runge's phenomenon(在一组等距插值点上使用高次多项式进行多项式插值时出现的区间边缘振荡问题)。

简化KANs并使它们具有交互式意义

研究人员设计了一个简单的回归实验,以展现用户可以在与KAN的交互过程中,获得可解释性最强的结果。
假设用户对于找出符号公式感兴趣,总共需要经过5个交互步骤。
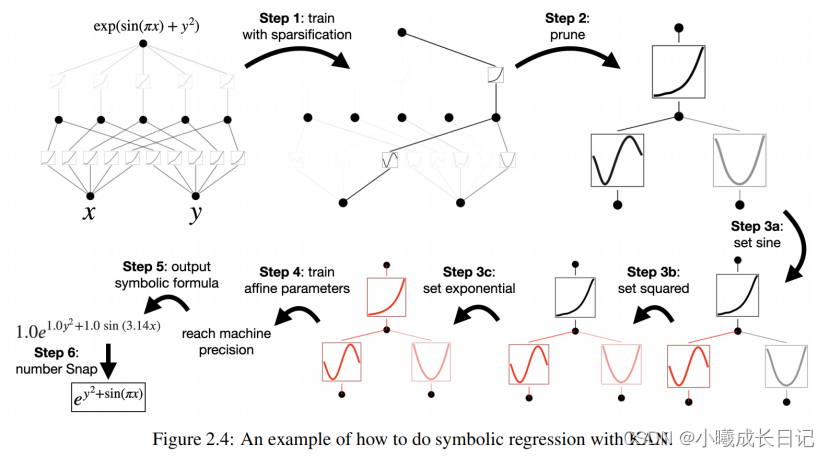
步骤 1:带有稀疏化的训练。
从全连接的KAN开始,通过带有稀疏化正则化的训练可以使网络变得更稀疏,从而可以发现隐藏层中,5个神经元中的4个都看起来没什么作用。
步骤 2:剪枝
自动剪枝后,丢弃掉所有无用的隐藏神经元,只留下一个KAN,把激活函数匹配到已知的符号函数上。
步骤 3:设置符号函数
假设用户可以正确地从盯着KAN图表猜测出这些符号公式,就可以直接设置:

如果用户没有领域知识或不知道这些激活函数可能是哪些符号函数,研究人员提供了一个函数suggest_symbolic来建议符号候选项。
步骤 4:进一步训练
在网络中所有的激活函数都符号化之后,唯一剩下的参数就是仿射参数;继续训练仿射参数,当看到损失降到机器精度(machine precision)时,就能意识到模型已经找到了正确的符号表达式。
步骤 5:输出符号公式
使用Sympy计算输出节点的符号公式,验证正确答案。
为什么不符号回归?

性能更强
作为合理性检验,研究人员构造了五个已知具有平滑KA(柯尔莫哥洛夫-阿诺德)表示的例子作为验证数据集,通过每200步增加网格点的方式对KANs进行训练,覆盖G的范围为{3,5,10,20,50,100,200,500,1000}。使用不同深度和宽度的MLPs作为基线模型,并且KANs和MLPs都使用LBFGS算法总共训练1800步,再用RMSE作为指标进行对比。
从结果中可以看到,KAN的曲线更抖,能够快速收敛,达到平稳状态;并且比MLP的缩放曲线更好,尤其是在高维的情况下。同时,三层KAN的性能要远远强于两层,表明更深的KANs具有更强的表达能力,符合预期。
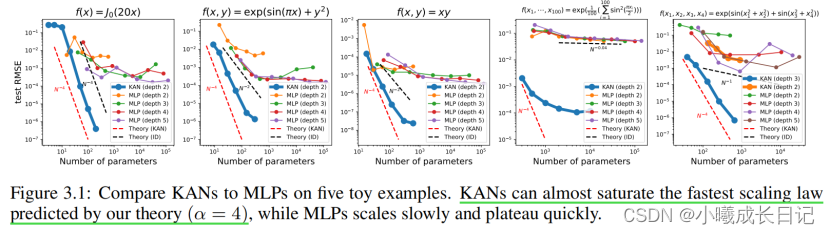
帕累托最优
通过拟合特殊函数,作者展示了KAN和MLP在由模型参数数量和RMSE损失跨越的平面中的Pareto Frontier。在所有特殊函数中,KAN始终比MLP具有更好的Pareto Frontier。

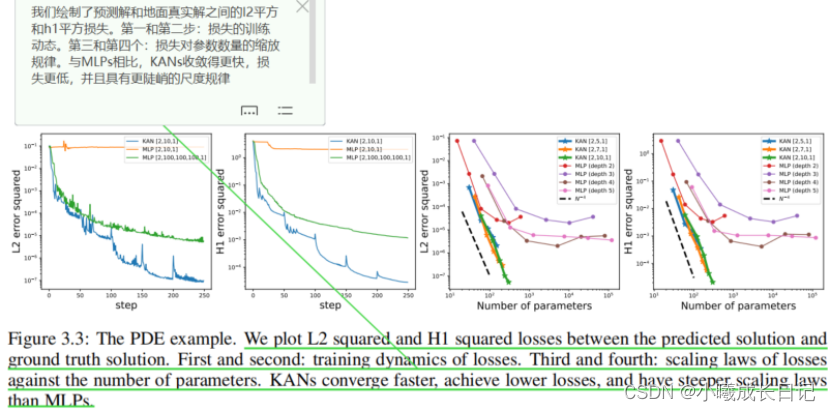
求解偏微方程
在求解偏微方程任务中, 研究人员绘制了预测解和真实解之间的L2平方和H1平方损失。下图中,前两个是损失的训练动态,第三和第四是损失函数数量的扩展定律(Sacling Law)。如下结果所示,与MLP相比,KAN的收敛速度更快,损失更低,并且具有更陡峭的扩展定律。

持续学习
灾难性遗忘是当前机器学习中的一个严重问题。

而研究证明了,KAN具有局部可塑性,并且可以利用样条(splines)局部性,来避免灾难性遗忘。相比之下,由于MLP通常使用全局激活(如ReLU/Tanh/SiLU),因此,任何局部变化都可能不受控制地传播到远处的区域,从而破坏存储在那里的信息。

文中采用了一维回归任务(由5个高斯峰组成)——每个峰值周围的数据按顺序(而不是一次全部)呈现给KAN和MLP。结果显示,KAN仅重构当前阶段存在数据的区域,而使之前的区域保持不变。而MLP在看到新的数据样本后会重塑整个区域,从而导致灾难性的遗忘。

可解释性验证
研究人员首先在一个有监督的玩具数据集中,设计了六个样本,展现KAN网络在符号公式下的组合结构能力。

可以看到,KAN成功学习到了正确的单变量函数,并通过可视化的方式,可解释地展现出KAN的思考过程。
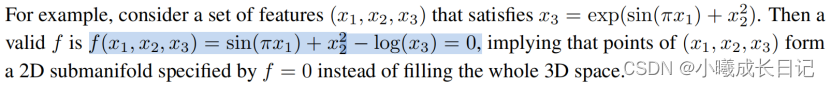
在无监督的设置下,数据集中只包含输入特征x,通过设计某些变量(x1, x2, x3)之间的联系,可以测试出KAN模型寻找变量之间依赖关系的能力。

从结果来看,KAN模型成功找到了变量之间的函数依赖性,但作者也指出,目前仍然只是在合成数据上进行实验,还需要一种更系统、更可控的方法来发现完整的关系。
Life is a journey. We pursue love and light with purity.
你的 “三连” 是小曦持续更新的动力!
下期将推出 “Application to Mathematics&Physics 分析” or "代码对比解析",零距离解读KAN的应用前景和MLP-KAN的源码对比。

