
- 1Perplexity CEO 最新四万字访谈:杀死谷歌,成为 AI 时代的搜索皇帝!
- 2Parallels Desktop 19 for Mac(PD19虚拟机)无需关闭SIP
- 3小白必备Stable diffusion30个插件,stable diffusion最全插件大全,新手必备指南!_stable diffusion 物品数量
- 4MySQL创建用户与授权_mysql 创建用户并授权
- 5nglview ipython/jupyter插件查看分子结构可视化效果;nglview加载蛋白和小分子示例
- 6Java+SSM+JSP在线云音乐系统源码+论文+答辩PPT_基于java的音乐网站系统的设计与实现答辩ppt
- 7【uniapp】跨域代理及一些常见问题:_uniapp pathrewrite
- 8[职场] 数据架构师求职简历工作经历范文(精选5篇) #职场发展#学习方法_大数据 架构师 简历
- 9实验场:在几分钟内使用 Bedrock Anthropic Models 和 Elasticsearch 进行 RAG 实验
- 10公告栏轮播效果
大数据入门-数仓超详细介绍
赞
踩
前言:
很多小伙伴私信想要学习大数据需要什么技能?那今天开始我会把一些关于大数据的基本知识以及可能会涉及到的面试题,和问题在这里进行总结,从数仓再到大数据核心详细讲述,为新手提供一个好的参考,希望大家多多支持
目录
数据仓库介绍
-
概念 : 存储数据的仓库, 主要是面向于【主题】, 进行数据【分析】工作, 主要是存储【历史】过去的数据, 通过对过去历史数据分析从而对未来提供【决策】支持
-
数仓最大的特点: 既不生产数据, 也不消耗数据, 数据来源于各个数据源
-
数仓的特征:
-
1) 面向【主题】: 每个需求和表都属于一个主题,可以用主题来对数仓的表分门别类
-
2) 【集成】性: 数据的种类 来源比较多【比如各业务系统OA管理系统,人力资源系统,MySQL,Oracle。。】, 需要将各个来源的数据全部的集中在一起 3) 【非易失】性: 对历史的所有数据的存储需要稳定性,使用非易失的介质来保存,用【HDFS 】 4) 【时变】性: 随着时间的推移, 原有分析方案可能无法满足分析要求, 需要更新分析手段 以及数据也会进行新增操作
-
ETL
-
Extract-Transform-Load
-
是将数据从来源端经过【抽取】、【转换】、【装载】至目的端的过程。从数据源抽取出所需要的原始数据,经过数据清洗,最终将清洗后的数据加载到数据仓库中去。
-
狭义上ETL: 从ODS层将数据抽取出来, 对数据进行清洗转换处理, 将处理后数据加载到DW层过程
-
宽泛上ETL: 整个数仓全过程 包含从 数据源到 ODS , 从ODS到DW ,从DW到DA过程 ,DA到业务库过程....
-

-
ETL【不能】解决所有数据仓库的问题,因为零散的ETL需求,将结果堆彻到数据仓库,会造成数据库杂乱无章,管理混乱。需要合理的数据治理以及数仓分层。
数据仓库和数据集市
-
数据仓库是面向企业的,数据的粒度一般是细的明细数据
-
数据集市是面向部门的,数据的粒度一般是粗的聚合的主题数据
-
可以认为数据仓库是由多个数据集市组成的。
-
一般倾向于自下向上的方式去逐步完善数据仓库。
OLAP 和 OLTP
| 对比项目 | OLTP | OLAP |
|---|---|---|
| 功能 | 面向【交易】的事务处理 | 面向【分析】查询 |
| 设计 | 面向【业务】 | 面向【主题】 |
| 数据 | 最新数据,二维数据 | 历史数据,多维数据 |
| 存储 | M,G ( 存储单位 ) | T、P、E |
| 响应时间 | 【快】 | 【慢】 |
| 用户 | 业务操作人员 | 管理决策人员 |
维度分析基本介绍
-
比如领导提的需求:统计各年份,各城市,各用户类型,各年龄群体(10-20岁、20-30岁、30-40岁)的订单数,退单率。
- select year,city,user_type,age_type,
- count(order_id) as `订单数`,
- count(if(flag=1,order_id,null))/count(order_id) as `退单率`
- from order_detail
- group by year,city,user_type,age_type;
维度:
-
意思:分析问题的角度, 当面对一个主题进行分析的时候, 可以从不同的角度来分析, 而这些角度其实就是维度
-
通常放在SQL语句的group by后
-
维度分为【定性维度】和【定量维度】
-
定性:比如上面需求里的【各城市,各用户类型】
-
定量:主要指的求某一个具体值的相关内容, 或者某个范围的维度。比如上面需求里的【各年份,年龄群体(10-20岁、20-30岁、30-40岁)】
-
-
维度还可以分为【层】和【 级】
-
时间维度
-
一个层次的4个级别:年、月、日、小时
-
-
地区维度
-
按行政层次分3个级别:省、市、县
-
按经纬线的层分4级:温带,热带,寒带,亚热带
-
-
-
上卷和下钻
-
是上面【不同的级别】之间的粗细转换。
-
比如已经得到了每天的课程访问量
-
可以将最近30天左右数据进行汇总,形成每月的访问量,这个是【上卷】
-
如果再细化到每个小时的访问量,那么就是【下钻】。
-
-
不管分层分级 还是下钻和上卷, 其实都是增加了细化维度而已, 统计维度变多了而已
指标:
-
指标:就是业务数值的度量,分为
-
绝对数值:sum() count() max() min() avg() ,比如上面需求里的【订单数】
-
相对数值:比率, 同比增长,比如上面需求里的【退单率】
-
数仓建模
数仓建模主要作用提供对数仓中表构建进行理论支持
数仓建模有2种方式,【三范式】建模,【维度】建模
-
三范式
-
第一范式,1NF,【原子】性,字段不可分;
-
第二范式,2NF,【唯一】性, 有主键,非主键字段依赖主键;一个表只说明一个事物;
-
第三范式,3NF,非主键字段【不能】相互依赖;
-
-
对于三范式来说,尽量一个表只侧重一个实体类的属性,尽量不要有冗余的信息
-
对于维度建模来说
-
主要是应用OLAP数据库中(数仓环境中)
-
允许一定的字段信息冗余,避免了再join,以【空间】换【时间】
-
宽表的数据可以复用,避免重复的join
-
维度建模的两个核心概念:事实表和维度表。
事实表
-
可以粗暴理解为,事实表 = 维度列+数值(指标)列。其中维度列可以是多个外键组成。
维度表
-
上述事实表中的某个维度列,可能只是一个外键,他的更详细的维度信息,在维度表中.
-
可以分为
-
【高基数】维度数据:一般是用户资料表,商品资料表类似的资料表,数据量可能是千万级或上亿级
-
【低基数】维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维度,地理维度,数据量可能只有个位数或者几千条。
-
-
维度退化操作
-
指的: 将维度表详细信息冗余到事实表中, 这个过程称为维度退化
-
举例
订单事实表 orderid userid payment prod_id area_id create_time status 1 1 100元 001 01 2022-01-01 已支付 2 2 100元 002 02 2022-01-01 已发货 用户维度表 userid name age 1 张三 20 2 李四 30 维度退化为: orderid userid name age payment prod_id area_id create_time status 1 1 张三 20 100元 001 01 2022-01-01 已支付 2 2 李四 30 100元 002 02 2022-01-01 已发货
-
数仓发展模型
星型模型:
-
中心是事实表,四周是维度表。
-
事实表的每个维度值,来自于【1】个维度表
-
例如下面的课程id只来自1个课程维度表
-
这种模型, 一般是数仓发展初期的时候最容易产生模型
-

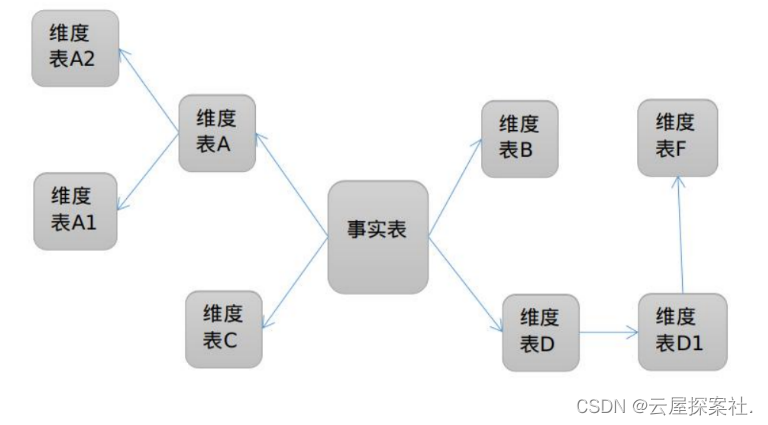
雪花模型:
-
在上述星形模型基础上,每个维度表,可能又需要关联【多】个子维度表。
-
例如下面的【事实表需要join 表A join 表A1 join 表A2 】。join次数越多,则可能shuffle越多,性能越差。
-
这种模型 一般是数仓发展走歪了, 尽量的避免出现。
-
星座模型:
-
当多个星型模型都有同样的维度时,可以共享同一个【维度表】
-
星形模型自然发展成星座模型。属正常现象。
-
比如下面全国31个省市县表,多个事实表共用一份就行

缓慢渐变维
-
以有的事实表的数据变化为例,比如电商订单,当公司成熟时,一般很猛烈的新增,订单一旦产生就不变。
-
维度表数据的变化则没那么猛,比如用户维度,当公司成熟时,一般很温和的新增,产生后可能会偶尔修改,比如住址,手机号。
-
这就是缓慢的逐渐变化的维度。slowly changing dimension (SCD).
-
如何处理缓慢渐变维
-
第一种:SCD1, 新行直接覆盖旧行, 仅适合于错误数据处理工作
-
第二种【推荐】:SCD2(又称为拉链表)
-
在原有表增加2个字段(start_time, end_time), 通过这两个字段,管理数据的多个历史版本。
-
使用时要where指定某具体时刻,它只会介于1个历史时段中。
-
比如下面where '2012-02-01' >Valid_from and '2012-02-01' < Valid_to 只会筛选出Beijing这条数据。
-
如果数据当前及未来都生效,则ValidTo可以写成9999-99-99或者9999-12-31
-

-
-
第三种:SCD3
-
对表新增一列, 用于记录变更数据即可
-
缺点:无法维护太多历史版本(3、 5个左右), 实现较为繁琐, 不利于维护
-

-
-
建议用SCD2拉链表方案,SCD1、SCD3都不好用。
-

