
- 1全国大学生数据统计与分析竞赛2021年【研究生组】-A题:硕士学位评价数据的统计与分析(附优秀论文和python代码实现)_研究生数据分析大赛
- 2Linux命令-cp_cp 多个文件
- 3fw150rm刷openwrt固件_N1刷openwrt固件至eMMC详细教程,非常适合小白!!!
- 4Apache Flink介绍、架构、原理以及实现
- 5Hive之MySQL安装与卸载_hive卸载
- 6深度学习系列12:目标检测模型
- 7【Unity】Transform、Rigidbody、CharacterController移动_transform、rigidbody、 character controller 组件
- 82023秋招nlp笔试题-太初_太初笔试
- 9毕设项目 大数据电商用户行为分析及可视化(源码+论文)_基于大数据分析的erp系统用户行为研究论文
- 10智能编程助手CodeGeeX使用评测_codegeex使用感受
ElasticSearch搜索引擎入门到精通
赞
踩
ES 是基于 Lucene 的全文检索引擎,它会对数据进行分词后保存索引,擅长管理大量的数据,相对于 MySQL 来说不擅长经常更新数据及关联查询。这篇文章就是为了进一步了解一下它,到底是如何做到这么高效的查询的。
在学习其他数据库的时候我们知道索引是一个数据库系统极其重要的部分,它直接决定着查询的效率。ES之所以快,是因为其底层的Lucene采用倒排索引的方式,并且还有很多的优化点,
倒排索引
何谓倒排索引?
——先看正排索引,如下表:
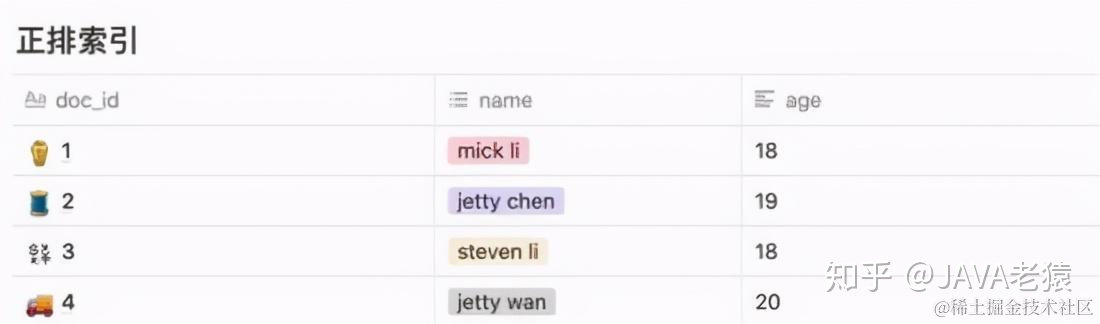
上图就是一个简单的正排索引。即将doc_id作为主键索引key,去查询到对应的一行数据value。
而倒排索引就有些反其道而行之的概念了。我们先将每句话按照单词分成一个一个的,而后看看对应的doc_id有哪些:
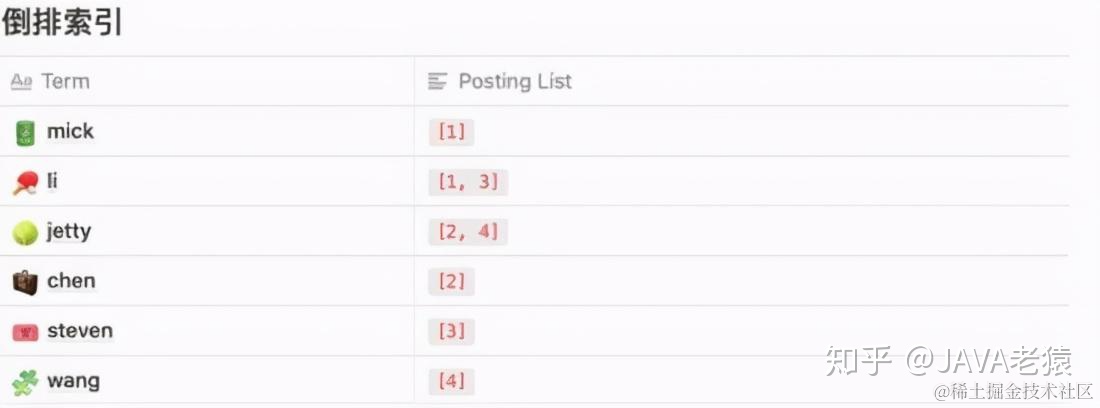
当要查询 包含 li 的数据时,只需要通过这个索引结构查询到 Posting List 中所包含的数据,再通过映射的方式查询到最终的数据。
就相当于由value去找出可能的key,再利用key去获取完整的数据。这种索引结构就是所谓的倒排索引。
虽然上面这种方式,可以实现查询数据到Position LIst(理解为行id等都可以)的快速查找,但是,使用什么数据结构来存储Term呢?
Term Index
我们将所有 Term 合并在一起就是一个 Term Dictionary,也可以叫做单词词典。英文的分词相对简单,只需要通过空格、标点符号将文本分隔便能拆词,中文则相对复杂,但也有许多开源工具做支持。
现在要解决一个问题,我们如何保存Term呢?
比如现在有多个Term:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
我们需要从中找出某个特定的Term,只能遍历,那么时间复杂度平均为O(n),这在单词数众多的时候很慢,而如果我们能够按照某种规则将其排序,那么利用二分查找的方式就可以将时间复杂度降到O(logN):
Ada,Carla,Elin,Kate,Patty,Sara,Selena
当我们的文本量巨大时,分词后的 Term 也会很多,这样一个倒排索引的数据结构如果存放于内存那肯定是不够存的,但如果像 MySQL 那样存放于磁盘,去访问磁盘获取数据效率也没那么高。
为了尽可能减小磁盘IO的次数,所以我们可以使用一个折中的方式——既然内存中无法放入整个Term Dictionary,那我就为Term Dictionary创建一个索引Term Index,将这个索引放到内存里。
term index 有点像一本字典的大的章节表。比如:
A 开头的 term ……………. Xxx 页
C 开头的 term ……………. Yyy 页
E 开头的 term ……………. Zzz 页
如果所有的 term 都是英文字符的话,可能这个 term index 就真的是 26 个英文字符表构成的了。
但是实际的情况是,term 未必都是英文字符,term 可以是任意的 byte 数组。而且 26 个英文字符也未必是每一个字符都有均等的 term,比如 x 字符开头的 term 可能一个都没有,而 s 开头的 term 又特别多。实际的 term index 是一棵 trie 树:
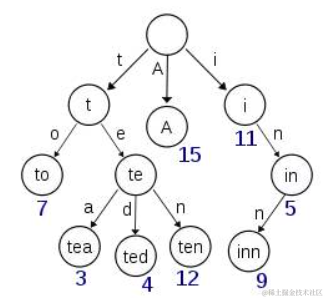
例子是一个包含 “A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, 和 “inn” 的 trie 树。这棵树不会包含所有的 term,它包含的是 term 的一些前缀。通过 term index 可以快速地定位到 term dictionary 的某个 offset,然后从这个位置再往后顺序查找。再加上一些压缩技术( Finite State Transducers) term index 的尺寸可以只有所有 term 的尺寸的几十分之一,使得用内存缓存整个 term index 变成可能。整体上来说就是这样的效果。
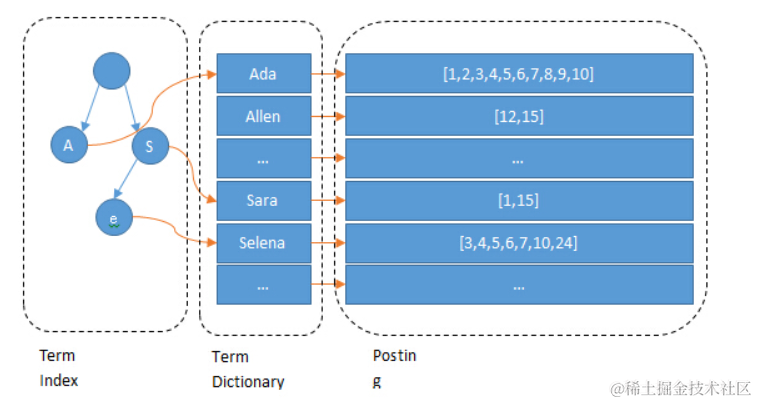
现在我们可以回答“为什么 Elasticsearch/Lucene 检索可以比 mysql 快了” 。
Mysql 只有 term dictionary 这一层,是以 b-tree 排序的方式存储

