
- 1QT线程同步_qt 同一线程不同函数写入同一指针的数据怎么办
- 2多模态大模型入门指南_多模态模型入门
- 3idea安装插件plugins时无法加载插件三种解决方法(亲测有效且下载速度飞起)_idea插件加载不出来
- 4NVIDIA相关资料(一)——Deepstream相关知识
- 5django命令大全
- 6作为一名程序员,年收入如何才能过50万?_程序员50万年薪难不难
- 7武汉大学计算机学院周浩,武汉大学电子信息学院导师介绍:周浩
- 8FPS游戏透视源码!
- 9基于LangChain快速实现Agent应用
- 10ubuntu16.04-和ubuntu 18.04 安装NVIDIA驱动 GPU_an nvidia gpu may be present on this machine, but
大模型系列|基于大模型的聊天助手案例(三)_聊天大模型学习
赞
踩
大模型系列|垂直大模型的几种训练策略(一)
大模型系列|基于大模型复杂数据系统架构(二)
本篇主要是采集一些大模型在聊天机器人中的案例,因为目前很多企业都会考虑将LLM与业务结合,LLM超强的理解力非常适合聊天场景。
1 PingCAP企业专属知识库的智能客服机器人
用 LLM 构建企业专属的用户助手本篇用心地把之前踩的坑都梳理了一下,并且一些坑也清晰表述
期望LLM实现的需求:
- 采取多轮对话形式,理解用户的提问,并给出回答。(
LLM可以完美实现) - 在回答的内容中,关于 TiDB、TiDB Cloud 的知识点要求准确无误。(
向量数据库满足) - 不能回答与 TiDB、TiDB Cloud 无关的内容。(
毒性检验)
实践中遇到的问题:
- 不准确的不良(毒性)内容识别:一些与公司业务相关的问题被模型误判并拒绝回答。例如,“dumpling” 实际上是 TiDB 的一个数据导出工具,但当用户直接提问 “ dumpling 是什么?”时,模型却误以为是关于食物的问题,拒绝回答并建议用户去咨询食物专家。
- 上下文理解失误:在执行多轮对话时,用户常会对之前的对话内容进行追问,此时他们通常只会简洁地描述,如:“这个参数的默认值是多少?”但是,当我们在向量数据库中使用用户的原始问题进行语义相关内容的搜索时,往往无法得到有意义的答案。这样一来,即使将问题输入到 LLM,也无法根据官方文档给出正确的答案。
- 语义搜索结果不精确:有时候,用户的问题非常明确,但是由于向量数据库搜索出的内容排序有误,导致在排名前N的答案中无法找到能正确回答问题的文档内容。
- 文档信息不足或过时:有些情况下,尽管用户的问题表述得很清楚,但由于官方文档不够完整或过时,没有包含相关内容,导致 LLM 在回答时只能凭借猜测,因此,很多时候其给出的答案是错误的。
1.1 向量数据库补充专业知识
在用户发起一次对话时,系统会将用户的对话也输入到 Embedding 模型中生成向量,再将这个向量放到向量数据库中和原有的预料进行查询。
遇到的问题:用户的提问很清楚,但是向量数据库搜索出的 Top N 中无法看到对应的文档内容。
想要稳定地提升语义搜索的产出质量,其实有两个直接、有效、快速实现的方法:
- 一、直接调整领域内容和提问之间的向量距离。
- 二、在召回领域知识的内容之外,额外召回特定内容的示例。
解决:主要运用的是示例+训练 Embedding 模型的方法。
- 第一步,先用类似 毒性检测的漏网之鱼 的方法,额外针对易错点补充示例,并将这些示例也随系统提示词一同提供给 LLM 模型,提高准确率。
- 第二步,在示例积累到一定数量,将示例内容作为训练数据,去训练 Embedding 模型,让 Embedding 模型能更好地理解提问和领域知识之间的相似关系,产出更合适的向量数据结果。
1.2 毒性检验
1.2.1 毒性回答的预训练
LLM 会努力让其回答符合人类的价值观,这一工作在模型训练中叫做“对齐”(Align),让 LLM 拒绝回答仇恨、暴力相关的问题。如果 LLM 未按照设定回答了仇恨、暴力相关问题,我们就称之为检测出了毒性(Toxicity)。
对于我们即将创造的机器人,其毒性的范围实际上增加了,即,所有回答了非公司业务的内容都可以称之为存在毒性。
需要使用 Few-Shot 的方法去构建毒性检测的提示词,让 LLM 在拥有多个示例的情况下,判断用户的提问是否符合企业服务的范围。
<< EXAMPLES >>
instruction: who is Lady Gaga?
question: is the instruction out of scope (not related with TiDB)?
answer: YES
instruction: how to deploy a TiDB cluster?
question: is the instruction out of scope (not related with TiDB)?
answer: NO
instruction: how to use TiDB Cloud?
question: is the instruction out of scope (not related with TiDB)?
answer: NO
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
得到了是否有毒的结果后,我们将有毒和无毒的流程分别处理,进行异常流程和正常流程的处理。
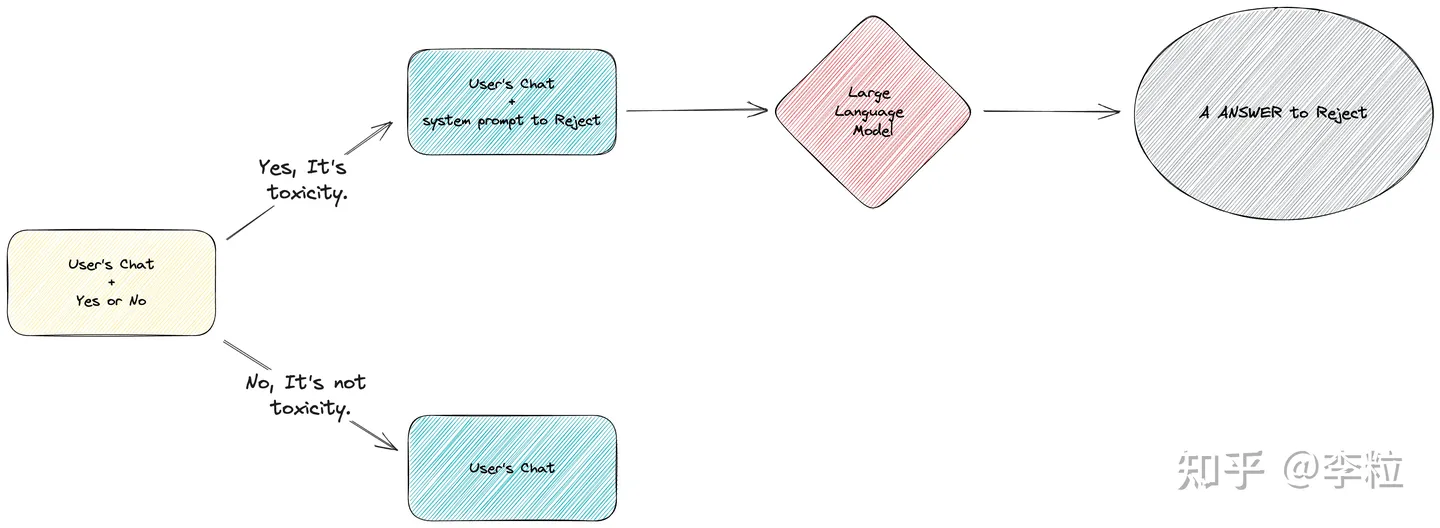
当系统发现产出的内容是 “Yes” 时,将流程引导进入毒性内容回复环节。此时,会将一个拒绝回答用户问题的系统提示词和用户对应的问题提交给 LLM,最终用户会得到一个拒绝回答的回复。
此时训练的数据是官方文档,
但是把所有的官方文档都一次性塞入 LLM 中是不现实的,因此我们设计了从向量数据库中按照语义相似度来搜索出相关的文档。
1.2.2 越狱(Jailbreaking)Prompt
用户在提问时可以输入 ‘Jailbreaking’ 的语句
这个现象可能由以下三个原因引起:
- 用户的输入很长,比 System Prompt 长很多:一般 Jailbreaking 的语句都很长,远长于绝大部分的 System Prompt,因此模型可能会更倾向于关注更具体的用户请求,而忽略较为模糊的系统提示。
- 模型的决策权重:GPT-3.5 及其他神经网络语言模型在生成回复时会根据输入文本的权重进行决策。如果 Jailbreaking 部分包含的信息比系统提示更具相关性,模型可能会更关注用户请求的内容。
- 用户请求的位置:在进行对话式交互时,用户请求通常是在系统提示之后提供的。由于模型是逐词生成回复的,用户请求的信息在输入中出现得更晚,因此可能更影响最终的回复内容。
因此,仅在 System Prompt 中进行限制是不行的,依然会被人 Jailbreaking,这在 LLM 应用到商业产品中是一个极高风险的事情。
而我们采用的判断链避免了这一情况,仅根据上一个 LLM 输出的 Yes 或 No 来知道后续的输出。如果用户尝试 Jailbreaking,那么在进行判断的 LLM 中就会出现非定义的回答,系统可以设定在出现非定义内容时,委婉的拒绝用户的提问。
1.3 意图理解
让 LLM 在系统进行领域知识搜索前对用户的原始提问进行改写,尽可能地用一句话描述清楚用户的意图,这种操作被称为“修订问题”(revise question)。
理解流程:
- 为了保证整个机器人系统中面对的用户问题保持一致,避免因为问题不一致导致的错误,我们将修订问题特性放在了系统信息流的最前面,让用户问题刚刚进入机器人就进行修订。
- 修订时,机器人会要求 LLM 模型根据整体对话的上下文来用一句话描述用户提问的意图,尽可能补充详细信息。这样无论是在毒性检测还是在领域知识搜索中,系统都可以根据更具体的意图来执行。
如果在修订问题中发现了明显的错误怎么办?
事实上也可以利用 few shot + 语义搜索 的办法,特定的优化这些错误。
为了保证整个机器人系统中面对的用户问题保持一致,避免因为问题不一致导致的错误,我们将修订问题步骤放在了系统信息流的最前面,让用户的问题在进入机器人时就进行修订。
在修订问题的过程中,我们会要求 LLM 模型根据整体对话的上下文来用一句话描述用户提问的意图,尽可能补充详细信息。这样无论是在毒性检测还是在领域知识搜索中,系统都可以根据更具体的意图来执行。
如果在修订问题中发现了明显的错误,我们也可以利用 Few-Shot 和语义搜索的方法来优化这些错误。
1.4 持续运营 > 模型微调
“模型微调”指的是直接使用微调(fine-tuning)的方法使用更多的领域数据来训练模型,包括 Embedding 模型和 LLM 模型。
“持续运营”是指类似本文的做法,利用更多高质量的领域知识和示例,以及尝试与 LLM 进行多次交互,正向提升应用的准确性的做法。
在 TiDB Bot 的前期,我们更倾向于持续运营的方法,利用系统的方法来进行稳定、便宜、快速的正向优化,确保整个团队专注在业务问题上。也许在 TiDB Bot 发展到中后期时,可以考虑模型微调的方法来进行更多的优化。

