
热门标签
热门文章
- 1py实战项目进度甘特图绘制_python 甘特图 多个进度
- 2区块链产业研究:物联网+区块链的应用落地_区块链 物联网 落地
- 3Docker 教程_启动docker
- 4【Kubernetes 企业项目实战】06、基于 Jenkins+K8s 构建 DevOps 自动化运维管理平台(中)_devops自动化运维平台
- 5DP-状态压缩DP(解释+典例)
- 6STM32+esp8266实现单片机与服务器的WiFi通信_基于stm32、esp8266及ov7670的无线图传下位机源码
- 7C语言实现面向对象编程 | 干货_c语言对象编程
- 8高效的Http客户端 OkHttp3使用_okhttp3 form 文件二进制
- 9tomcat最大线程数、最大等待数和最大连接数
- 10认识SOAR-安全事件编排自动化响应
当前位置: article > 正文
火车头采集:高效数据采集工具的介绍
作者:知新_RL | 2024-02-15 21:57:18
赞
踩
火车头采集
火车头采集是一款基于Python语言开发的网络爬虫工具,用于快速高效地从互联网上采集数据并存储到本地或远程数据库。它简单易用且功能强大,在各行各业广泛应用。
1、设置chatgpt自定义key
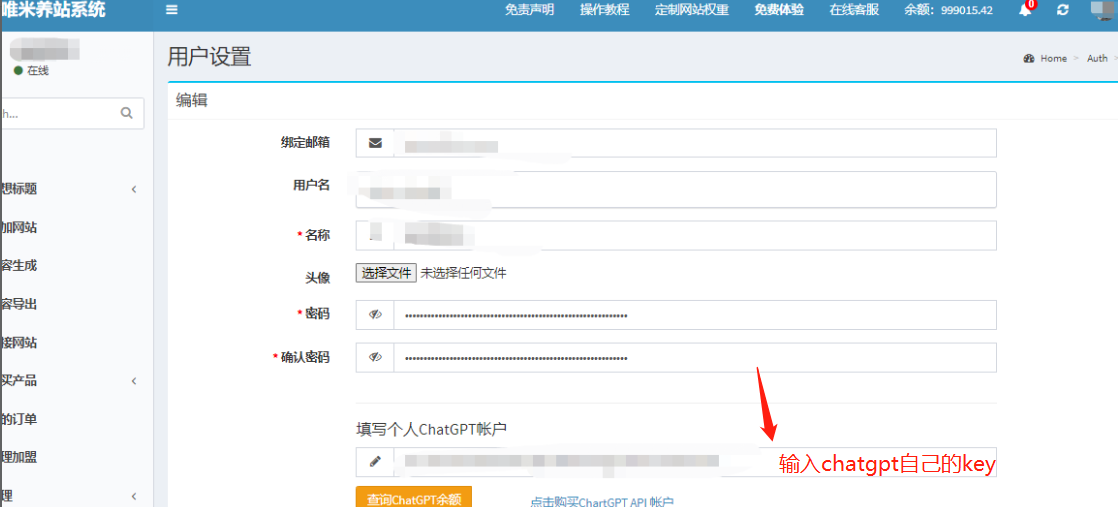
- 添加网站

- 通过关键词批量生成原创文章
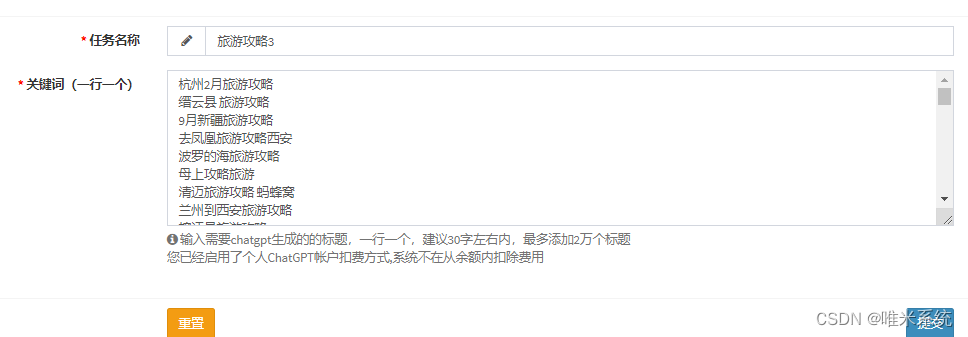

- 设置发布网站

发布成功
相比其他工具,火车头采集具有以下优势:
1. 支持多种类型的网页:能够轻松识别和采集静态和动态网页。
2. 采集速度快:利用Python语言的高效处理能力、多线程和异步IO技术,能快速采集所需数据。
3. 数据清洗功能强大:可在采集过程中进行数据清洗和筛选,保证数据质量。
4. 支持多种存储方式:支持本地、远程数据库和云端存储,提高数据的安全性和可靠性。
使用火车头采集需要以下步骤:
1. 安装Python环境(建议Python3.x版本)。
2. 安装相关库文件,如requests、lxml、beautifulsoup4等。
3. 编写爬虫代码,可参考官方文档或在线教程。
4. 运行爬虫程序,可通过命令行或IDE等方式启动数据采集。
一个简单的案例演示了火车头采集的使用方法和效果,通过编写爬虫程序从网页表格中提取商品名称、价格和库存等信息。
火车头采集适用于各行各业的数据采集工作,特别适用于需要大量采集表格数据的企业和机构。典型应用场景包括电商行业(采集商品信息)、金融行业(采集市场和股票数据)、政府机构(采集社会经济数据)等。
在使用火车头采集时,需要遵守法律法规,避免触发反爬机制,并进行数据清洗和筛选,确保采集到的数据质量。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/87361
推荐阅读
相关标签

