
热门标签
热门文章
- 1史上最全!考研考公视频在某度云倍速 | 敲重点!_gwy 学习 视频加速
- 2PMP一般要提前多久备考?_pmp需要准备多久
- 3elasticsearch-java api之搜索(二)——聚合_getaggregations
- 47-22龟兔赛跑/PTA基础编程题目集_乌龟与兔子进行赛跑,跑场是一个矩型跑道,跑道边可以随地进行休息。乌龟每分钟可以
- 5Linux系统中运行.sh文件的几种方法_.sh文件如何运行
- 6frida学习及使用
- 7React之Props,及与state的区别_react props和state区别用法
- 81.Vue概念_用于封装与应用程序的业务逻辑相关的数据
- 9ts:使用ts-node执行ts文件_node 运行ts
- 10CrossOver 23.7 for Mac中文破解版软件安装图文激活教程
当前位置: article > 正文
Segment Anything_segment anything csdn
作者:知新_RL | 2024-02-16 10:47:04
赞
踩
segment anything csdn
项目主页:Segment Anything
简介
将prompt learning 引入至视觉任务中,设计了图像分割任务预训练模型。提示词可以是位置点、矩形框、文本和掩码等。
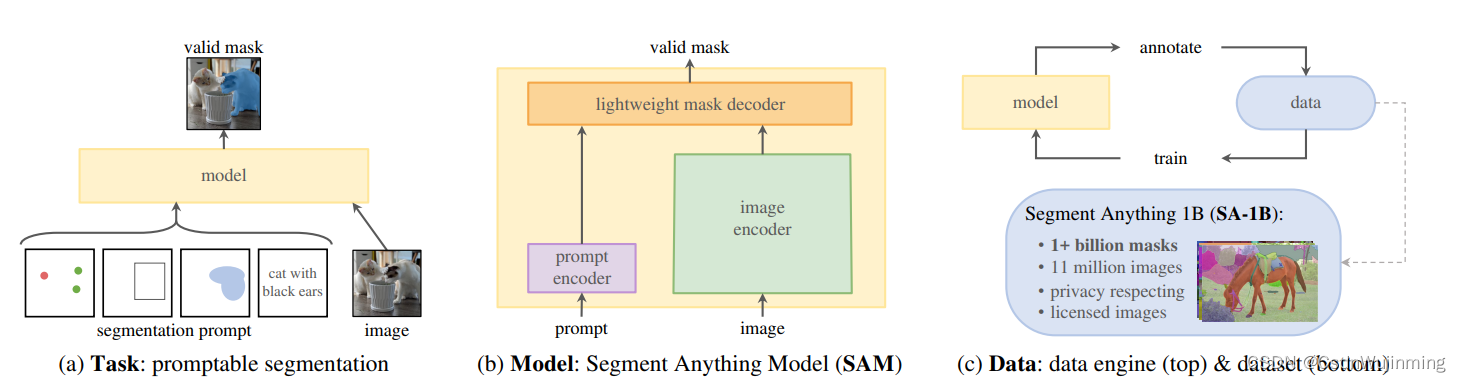
图1:方法主要部分。(图来自论文)
task: 为能避免歧义,对于每个prompt输出三个mask,分别对应整体、部分和更小的部分。
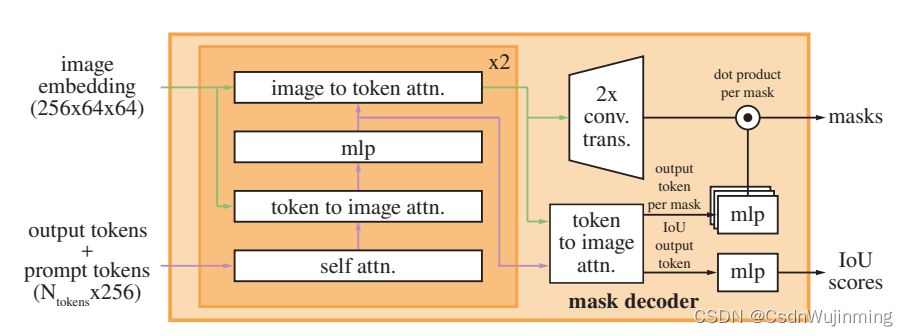
model: 一个大的image enocder,不同类型prompt的encoder,然后mask decoder (包含自注意力和交叉注意力)预测。
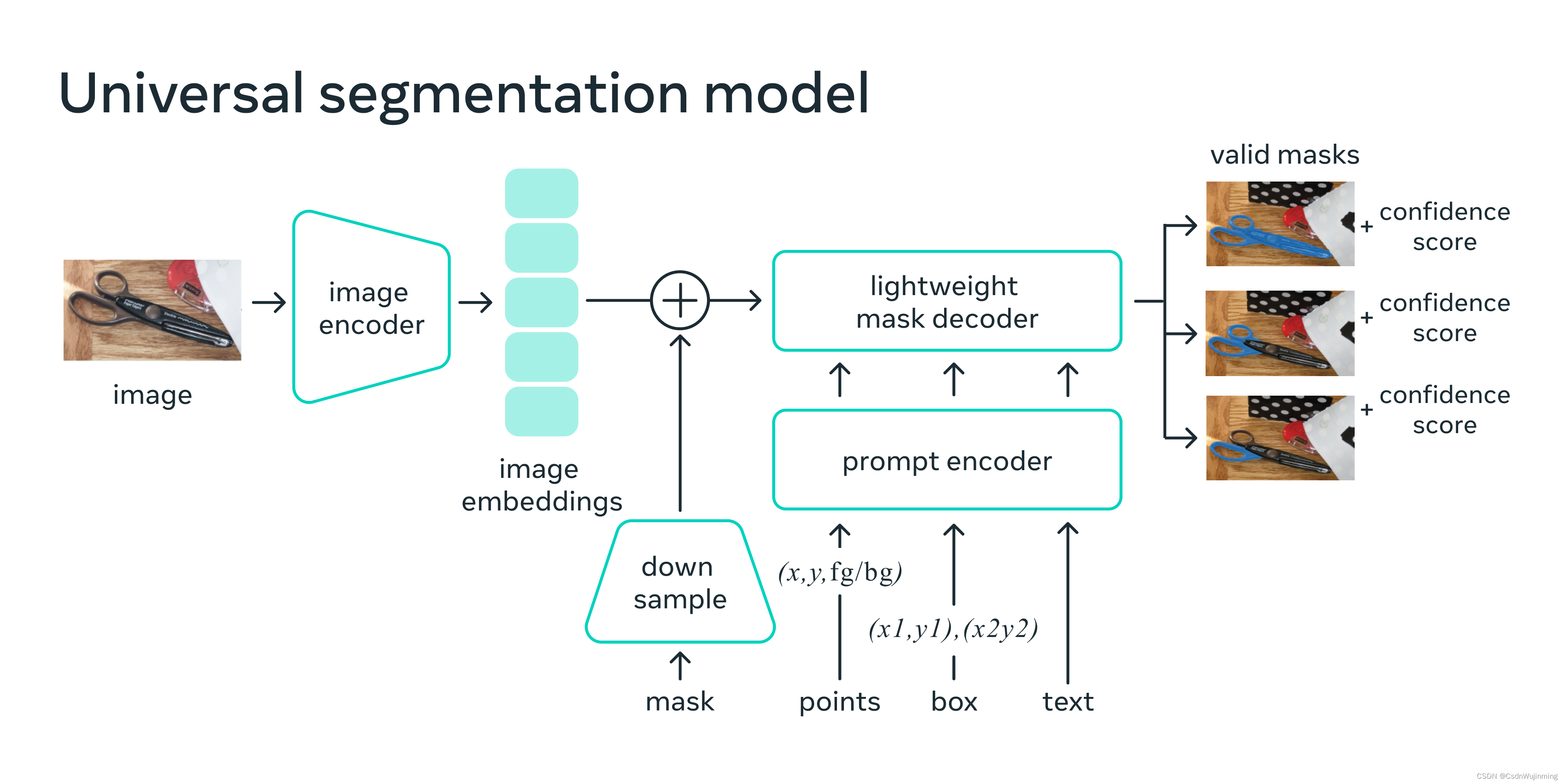
图2:模型结构。(图来自论文的博客)
data: 三阶段生成了1.1B高质量masks的大规模数据集SA-1B。(1)人工自由标注,但无需给出label。(2)训练好的模型先给出部分高可信的mask,再人工补充。另外训练一个bounding box detector判断是否为可信的mask。(3)全自动地在新图像中生成masks。 IoU prediction module筛选可信的masks,NMS过滤重复masks。相应地,模型也是分阶段训练。
Demo: 给出的测试Demo中,image embedding 是服务端计算完传输至用户端,而在用户端给出不同类型的prompt ,在浏览器中使用cpu计算prompt embedding 和mask decoder 推理。下面视频来自项目主页说明。
segment_anything_demo
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/92363
推荐阅读
相关标签

