
- 1如何培养程序员的领导力?_程序员如何培养自己的管理能力
- 2【1】MongoDB的安装以及连接_mongodb怎么连接
- 3Linux 安装 Gitblit_gitblit linux 安装
- 42022卡塔尔世界杯互动游戏|运营策略_世界杯 运营 活动 游戏
- 5vivado的RTL设计与联合modelsim仿真_vivado可以生成rtl
- 6目前常见的Linux操作系统_linux操作系统分类
- 7京东软件测试岗:不忍直视的三面,幸好做足了准备,月薪18k,已拿offer_京东测开三面
- 8视觉应用线扫相机速度反馈(倍福CX7000PLC应用)
- 9GPT3.5、GPT4、GPT4o的性能对比_gpt3.5和gpt4o
- 10【C语言题解】1、写一个宏来计算结构体中某成员相对于首地址的偏移量;2、写一个宏来交换一个整数二进制的奇偶位
大数据知识总结_大数据基础知识总结
赞
踩
同人工智能一样,在此简单记录一下大数据的重点。
关联规则:
支持度:支持度揭示了A与B同时出现的概率
置信度:置信度揭示了A出现时,B是否也会出现或有多大概率出现
支持度计算:
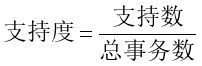
置信度计算:
A->B的置信度={A,B}的支持数/A的支持数
算法过程:自己看
频繁项集:对于一个项集,它出现在若干事务中 。
算法改进:
事务压缩:不包含任何频繁k-项集的事务,不可能包含任何频繁(k+1)-项集
划分:
选样:
动态项集计数:
FP Growth:
思想:将数据库的信息压缩成一个描述频繁项相关信息的频繁模式树。
基于划分的聚类:
距离:
欧氏距离(欧几里得距离):
明氏距离:

明氏距离的缺点:

模型评价:
泛化误差:在未来样本上的误差
经验误差:在训练集上的误差,也称训练误差
泛化误差越小越好,但是经验误差并不是越小越好,因为会出现过拟合现象。
获得测试集的三种方法:
留出法,交叉验证法,自助法
调参:
超参数:算法的参数,一般由人工设定
模型的参数:一般由学习确定
训练集:用于模型拟合的数据样本。在训练过程中对训练误差进行梯度下降,进行学习,可训练的权重参数
测试集:用于测试结果,模型性能
验证集:是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估
算法参数选定后,要用“训练集+验证集”重新训练最终模型
性能度量:
回归任务常用均方误差:
分类问题:
查准率/准确率:预测正确的正例占预测正例的比例
查全率/召回率:预测正确的正例占实际正例的比例
PR图,BEP(平衡点):

F1指标:
对于多分类:
macro-F1(宏): P,R取平均值
micro-F1(微): TP,FP,FN取平均值

ROC,AUC:
y轴:TPR:预测对的正例占所有实际正例的比例
x轴:FPR:预测错误的正例占所有反例的比例
AUC的面积越接近于1越好
如何画图
决策树:
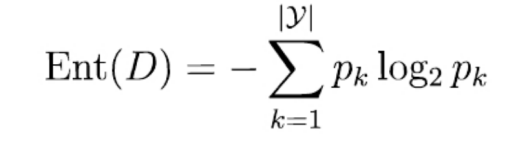
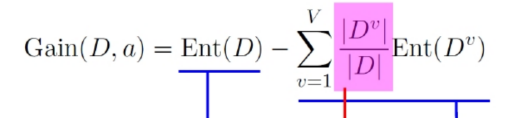
增益率:

基尼系数:选最小

G 越大,数据的不确定性越高;
G 越小,数据的不确定性越低;
G = 0,数据集中的所有样本都是同一类别
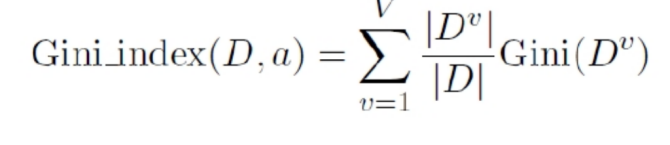
剪枝概念:
主动去掉一些分支来降低过拟合的风险
基本策略:
预剪枝 (pre-pruning): 提前终止某些分支的生长
对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
降低了过拟合风险,但是增加了欠拟合风险
后剪枝 (post-pruning): 生成一棵完全树,再“回头”剪枝
先从训练集生成一棵完整的决策树,然后自底向上对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
剪枝过程
对比预剪枝与后剪枝生成的决策树,可以看出,后剪枝通常比预剪枝保留更多的分支,其欠拟合风险很小,因此后剪枝的泛化性能往往由于预剪枝决策树。但后剪枝过程是从底往上裁剪,因此其训练时间开销比前剪枝要大
贝叶斯:
Dc为类别为c的样本数,D为总样本数,N为可能有的类别数
Ni为属性i的可能取值个数
后验概率:
半朴素贝叶斯:
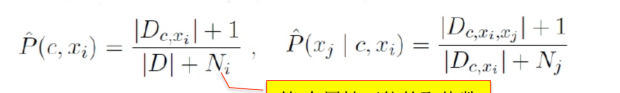
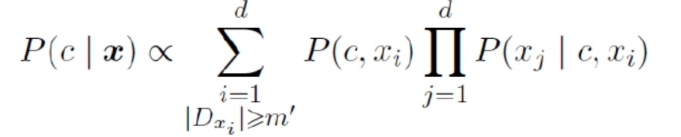
综合题:
如果是数据题(使用BP网络):
数据清洗:
1.可以画出每个特征的分布图,如果发现有的特征具有偏态,可以进行纠偏操作
2.可以画出每个特征的箱线图,观察有无离群点,去除离群点操作
3.求每个特征的缺失值比例,以决定是否留下该特征
4.对于数值型特征,可以进行标准化
5.对象型特征,可以用01序列转化为数值型
6.可以利用原始数据生成新的维度,如计算比例、平均值等,当作新的特征。
7.如果维数过多,可以进行PAC降维
8.如果每类的样本数目不均匀,可以进行过采样或者欠采样
特征选择:
9.选择合适的特征
10.使用10折交叉验证来生成验证集
11.选择合适的评价指标:如果是多分类可以使用macro-F1,
模型建立:
12.建立BP神经网络,输入层的节点个数为样本的特征数,激活函数初步选择sigmoid,给权值、偏置赋值为0,步长初步选择0.5.
模型优化:
如果结果不理想,可以尝试以下方法:
1.调整超参数,如步长,多次运行结果
2.增加神经元数量
3.增大深度
如果发现有过拟合现象,可以采用以下方法:
1.换用relu激活函数
2.早停:当训练误差连续几次小于某个设定阈值时,就停止训练/当训练误差变小,验证集误差升高时,就停止训练
3.在误差目标函数中加入正则项
如果是图像分类题(CNN网络):
1.如果样本数太少,就进行数据增强,通过平移,旋转,加噪声等操作来增强数据
2.也可以通过将图片灰度化、腐蚀膨胀等操作,使得图片的某些特征更加突出。
3.可以寻找类似本问题,且已经实现的网络应用到本模型中。如:去掉其全连接层,作为本模型的特征提取器,或者固定其前几层,用新数据库去微调后几层的参数。
4.评价标准可以选用准确率和召回率
优化:
1.使用10折交叉验证来生成验证集
2.利用网格搜索寻找合适的学习率
3.对于卷积层,可以通过卷积核小型化,1x1 卷积,Network In Network来优化
4.对于池化层,可以改用L-P 池化,混合池化,随机池化等
5.激活函数可以选用relu,防止过拟合和梯度爆炸等问题
6.有过拟合倾向的话,可以在损失函数上加入正则项
7.批量归一化:对神经网络每一层的输入数据进行归一化,防止由于上一层的参数改变了数据的分布,防止梯度爆炸或梯度消失。

