
- 1【分布式websocket】IM系统中为什么要做心跳!Netty中如何做心跳,客户端如何做断线重连!_netty websocket心跳
- 2erlang rabbitmq源码解析_RabbitMQ面试宝典,赶紧收藏!
- 3〖Python零基础入门篇㉘〗- Python中不同数据类型间的转换_python不同类型数据转换
- 4flowable表梳理
- 5TensorFlow vs PyTorch:深度学习框架的比较研究_tensorflow和pytorch哪个好
- 6hadoop 3.x 无法访问hdfs(50070,8088)的web界面
- 7大模型安全测试入门指南
- 8chatgpt赋能python:Python中出现NaN的原因及相关处理方法_python nan
- 9k-means聚类算法详解_kmeans算法_应用k-means算法解决聚类问题
- 10Android开发者必看避坑指南,字节跳动Android面试全套真题解析在互联网火了
基于CNN的股票预测方法【卷积神经网络】
赞
踩
基于机器学习方法的股票预测系列文章目录
一、基于强化学习DQN的股票预测【股票交易】
二、基于CNN的股票预测方法【卷积神经网络】
本文探讨了利用卷积神经网络(CNN)进行股票预测的建模方法,并详细介绍了模型的搭建、参数选择以及数据处理方法。尽管序列建模通常与递归神经网络(如LSTM和GRU)相关,但本文展示了如何使用CNN进行时间序列数据的预测,完整代码放在GitHub上——Stock-Prediction-Using-Machine-Learing.
一、CNN建模原理
深度学习背景下的序列建模主题主要与递归神经网络架构(如LSTM和GRU)有关,但事实上CNN也可以用于对序列数据的建模。与处理图像所用的二维卷积不同,处理时间序列可以使用一维卷积,用多个以前的数据序列预测下一时刻。如下图所示,Input_length是指定用几个以前的数据来预测下一天的股票价格,用一个一个卷积核来滑动提取特征,最后通过一个线性层得到输出的预测值,具体网络搭建见下一小节。
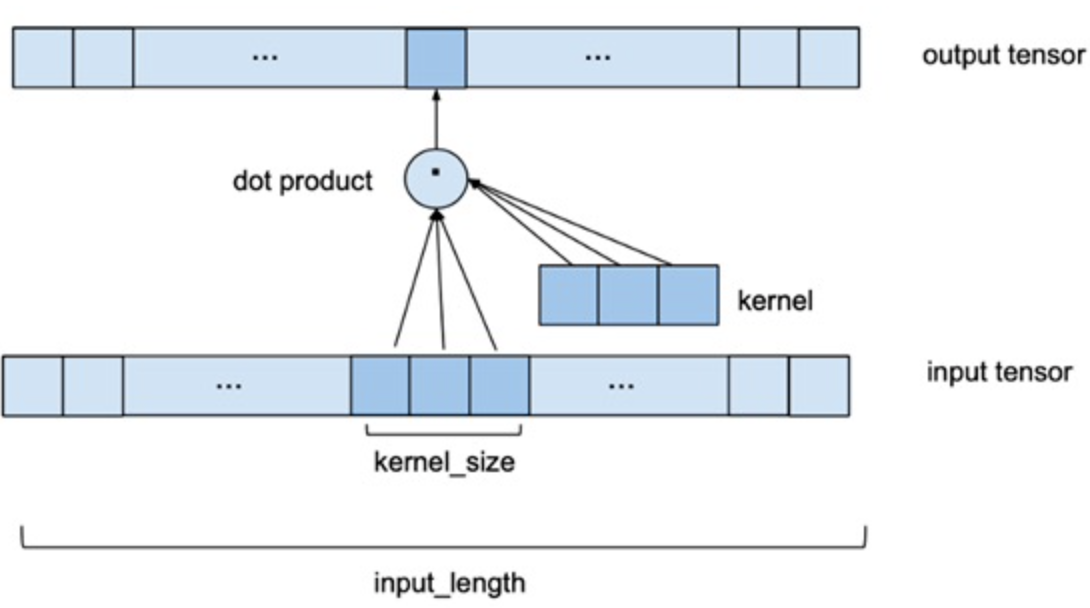
其中两个关键的参数是:
Input_length: 用几个以前的数据作为输入,来预测下一时刻。(在后文称为Window_size)Kernel_size: 卷积核大小。
事实上也可以用二维的卷积和来建模,比如输入可以是多只股票,用二维卷积核对多只股票同时建模预测,或者将一只股票的多个特征同时建模预测,本文仅探究用股票的收盘价来预测未来的股票收盘价格,没有利用股票数据的其他技术指标。
二、模型搭建
基于Pytorch深度学习框架,搭建的CNN网络如下所示:
kernel_size=2 #一维卷积核大小 class CNNmodel(nn.Module): def __init__(self): super(CNNmodel, self).__init__() self.conv1 = nn.Conv1d(1, 64, kernel_size=kernel_size) #1xkersize的卷积核 #self.conv2 = nn.Conv1d(64,128,1) self.relu = nn.ReLU(inplace=True) self.Linear1 = nn.Linear(64*(window_size-kernel_size+1), 10) self.Linear2 = nn.Linear(10, 1) def forward(self, x): x = self.conv1(x) x = self.relu(x) x = x.view(-1) x = self.Linear1(x) x = self.relu(x) x = self.Linear2(x) return x model = CNNmodel() print(model)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
选用relu函数作为激励函数,因为股票都是正数,而relu函数的性质,可以很好的避免模型输出值为负值。
三、模型参数的选择
(1)探究window_size的影响
调节CNN模型中window_size参数,并比较不同window_size下训练集与测试集的相对误差率,结果如下表所示:
| window_size | 训练集相对误差率 | 测试集相对误差率 |
|---|---|---|
| 5 | 2.22% | 2.18% |
| 6 | 1.69% | 1.48% |
| 7 | 2.30% | 2.27% |
| 8 | 2.36% | 2.12% |
| 15 | 1.65% | 1.58% |
| 20 | 2.01% | 2.03% |
| 50 | 2.37% | 2.55% |
| 150 (kernel_size=40) | 3.21% | 2.72% |
分析上表知:
- 不同
window_size对结果有一定影响 window_size比较大时,误差很大- 在10左右,效果比较好,最终我们选择
window_size=6
(2)探究kernel_size的影响
调节CNN模型中kernel_size参数,并比较不同kernel_size下训练集与测试集的相对误差率,结果如下表所示(window_size=6):
| Kernel_size | 训练集相对误差率 | 测试集相对误差率 |
|---|---|---|
| 2 | 1.69% | 1.48% |
| 3 | 1.76% | 1.58% |
| 4 | 1.82% | 1.94% |
| 5 | 1.90% | 1.73% |
分析上表数据知较小的kernel_size能使相对误差率更小,最终我们选择kernel_size=2。
(3)探究探究模型结构的影响
调节CNN模型中模型结构,并比较不同模型结构下的平均误差和平均相对误差率,结果如下表所示:
| 模型结构 | 平均误差 | 平均相对误差率 |
|---|---|---|
| 两个卷积层 | 0.52 | 2.46% |
| 1个卷积层,线性层100 | 0.46 | 2.29% |
| 1个卷积层,线性层10 | 0.28 | 1.38% |
由上表知,模型对学习率十分敏感;模型结构过于复杂,不容易学习,且容易过拟合。
(4) 模型拟合效果
通过以上探究得到的模型结构以及参数,以AAPL股票为例,采用原始数据进行训练,其预测结果如下图所示:
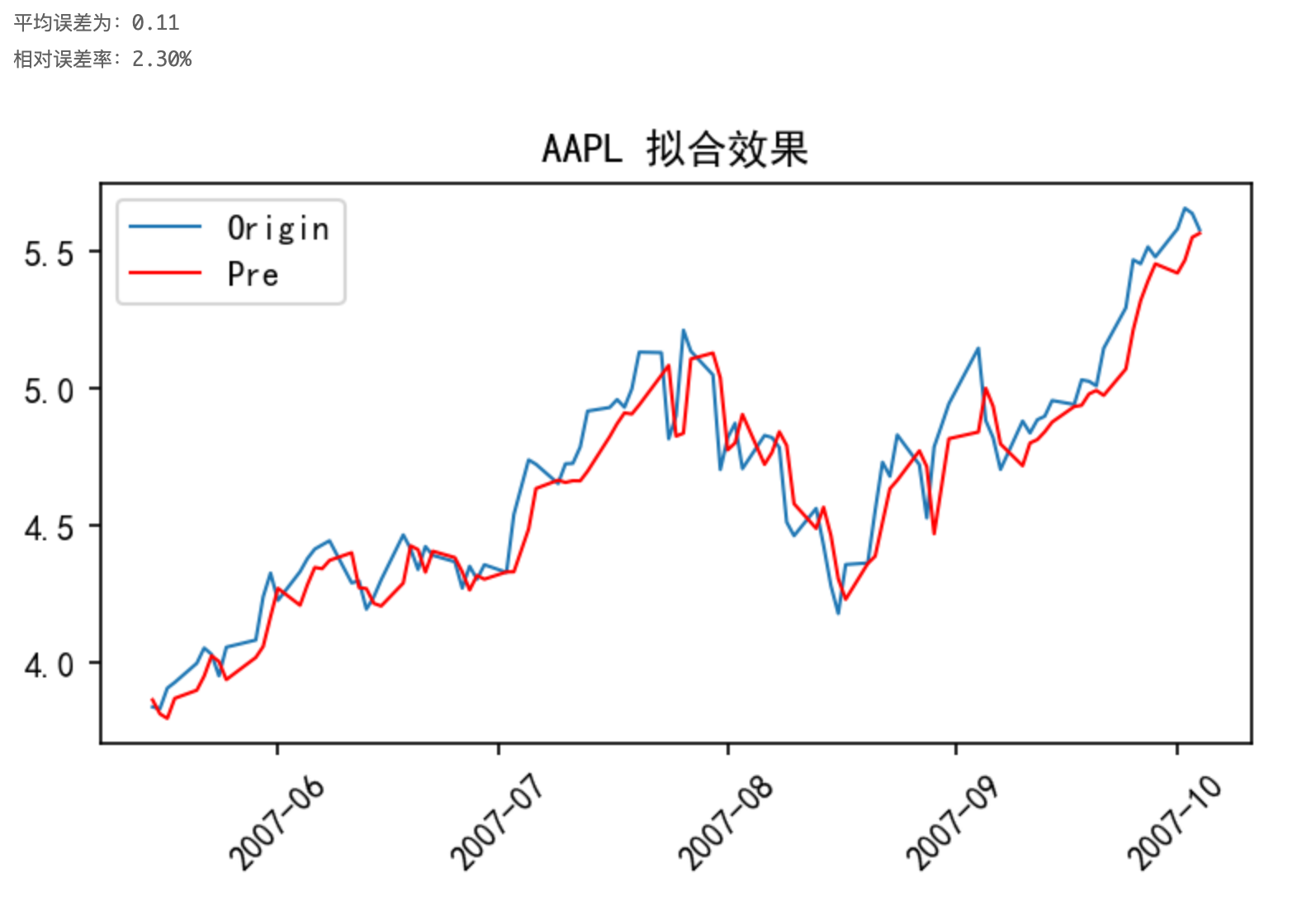
由上图知,以原始数据进行训练有不错的拟合效果,但滞后比较明显,神经网络会“偷懒”,这是因为数据序列中产生了变化趋势,而基于滑动时间窗口策略的对发生变化趋势的数据感知是滞后的。
对测试集进行预测:
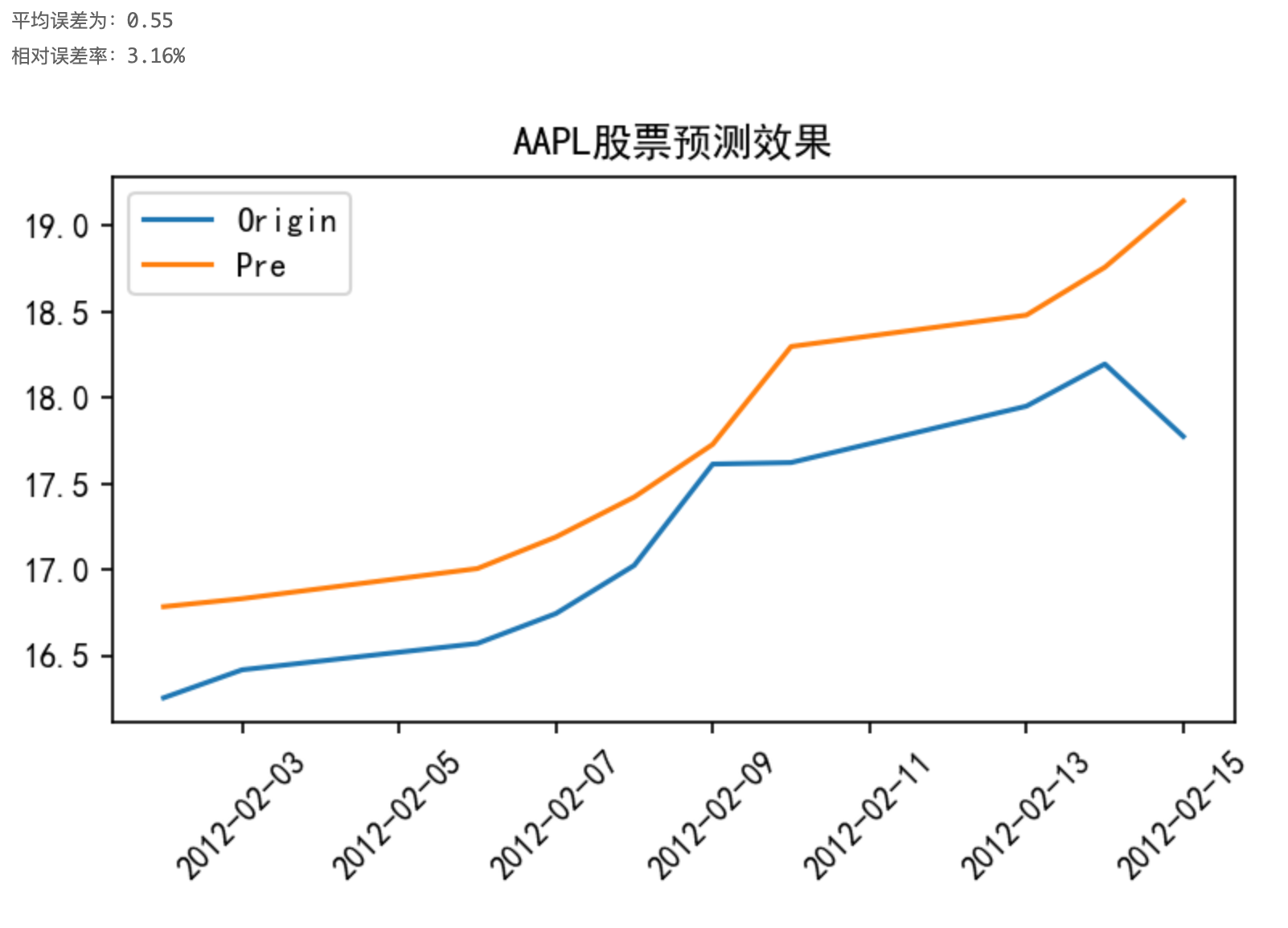
四、数据处理
(1)数据变换
为了解决预测过程中出现的“滞后”问题,常常对原始数据进行一定的处理。常见的数据处理方法有:
- 数据归一化
- 不直接给出希望模型预测的未经处理的真实值,对输入样本进行非线性化的处理如,如:平方、开根号、ln等
- 差分,预测时间t和t-1处值的差异,而不是直接预测t时刻的值
如以AAPL股票数据为例,对其收盘价取其平方的对数进行训练,最终的预测效果如下图所示:
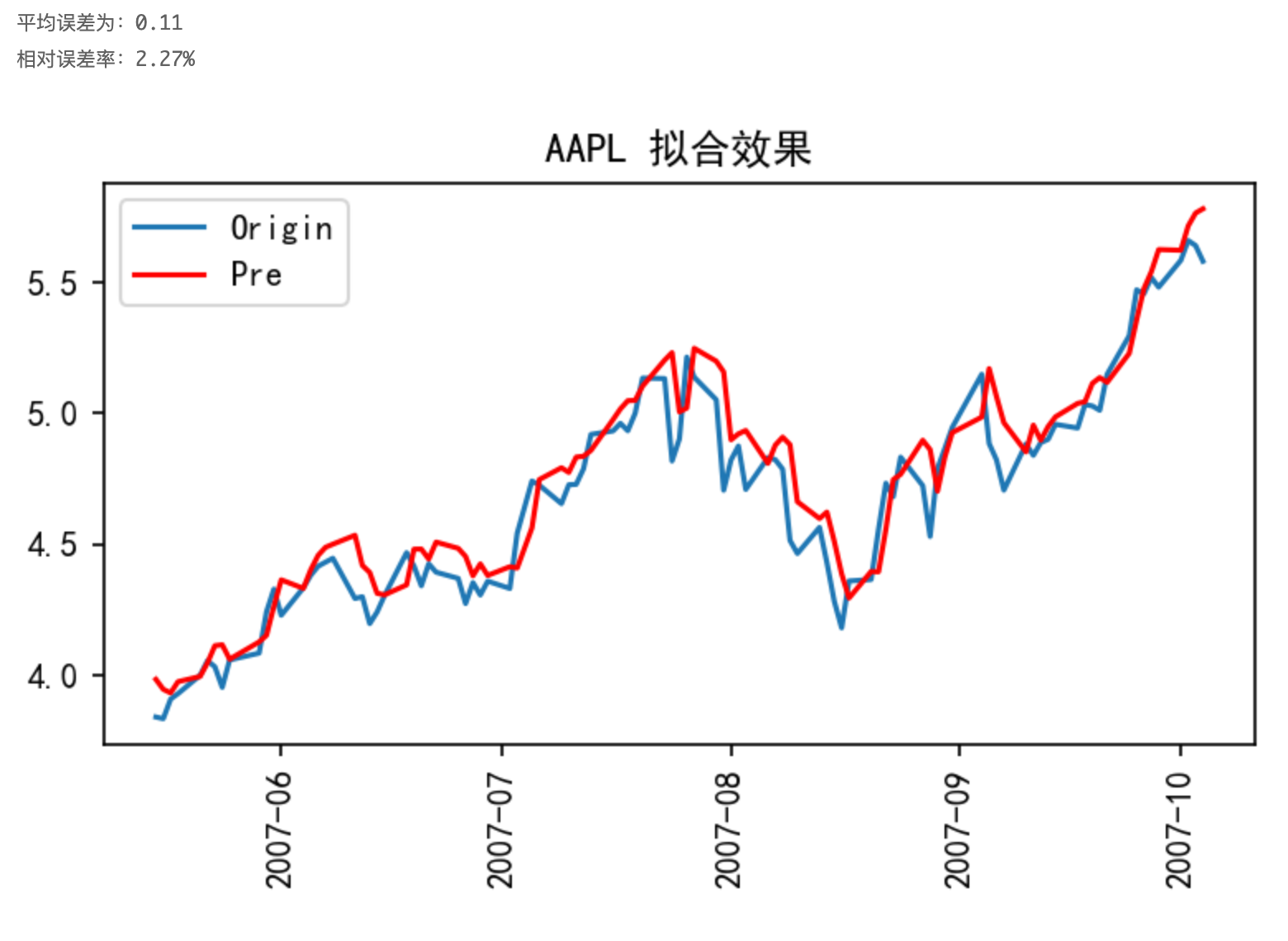
与上一小节的图对比知,“滞后”现象得到显著的减弱,模型的可信度更好。
(2)Kalman滤波
卡尔曼滤波(Kalman filtering)是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。
Kalman滤波原理及数理处理过程如下:
- 给定初始估计值、系统输入、初始协方差矩阵和误差的方差 Q Q Q, 首先要计算预测值、预测值和真实值之间误差协方差矩阵:
X
^
k
′
=
A
X
^
k
−
1
+
B
u
k
−
1
P
k
′
=
A
P
k
−
1
A
T
+
Q
- 然后根据 P k ′ P_{k}^{\prime} Pk′ 计算卡尔曼增益 K k K_{k} Kk :
K k = P k ′ H T ( H P k ′ H T + R ) − 1 K_{k}=P_{k}^{\prime} H^{T}\left(H P_{k}^{\prime} H^{T}+R\right)^{-1} Kk=Pk′HT(HPk′HT+R)−1
- 然后根据卡尔曼增益 K k K_{k} Kk 和 X ^ k ′ \hat{X}_{k}{ }^{\prime} X^k′ 以及测量值 Z k Z_{k} Zk, 调和平均得到估计值:
X ^ k = X ^ k ′ + K k ( Z k − H X ^ k ′ ) \hat{X}_{k}=\hat{X}_{k}^{\prime}+K_{k}\left(Z_{k}-H \hat{X}_{k}^{\prime}\right) X^k=X^k′+Kk(Zk−HX^k′)
- 最后还要计算估计值和真实值之间的误差协方差矩阵, 为下次递推做准备:
P k = ( I − K k H ) P k ′ P_{k}=\left(I-K_{k} H\right) P_{k}^{\prime} Pk=(I−KkH)Pk′
以AAPL股票数据为例,对其收盘价进行kalman滤波后,以CNN模型进行训练,结果如下图所示:
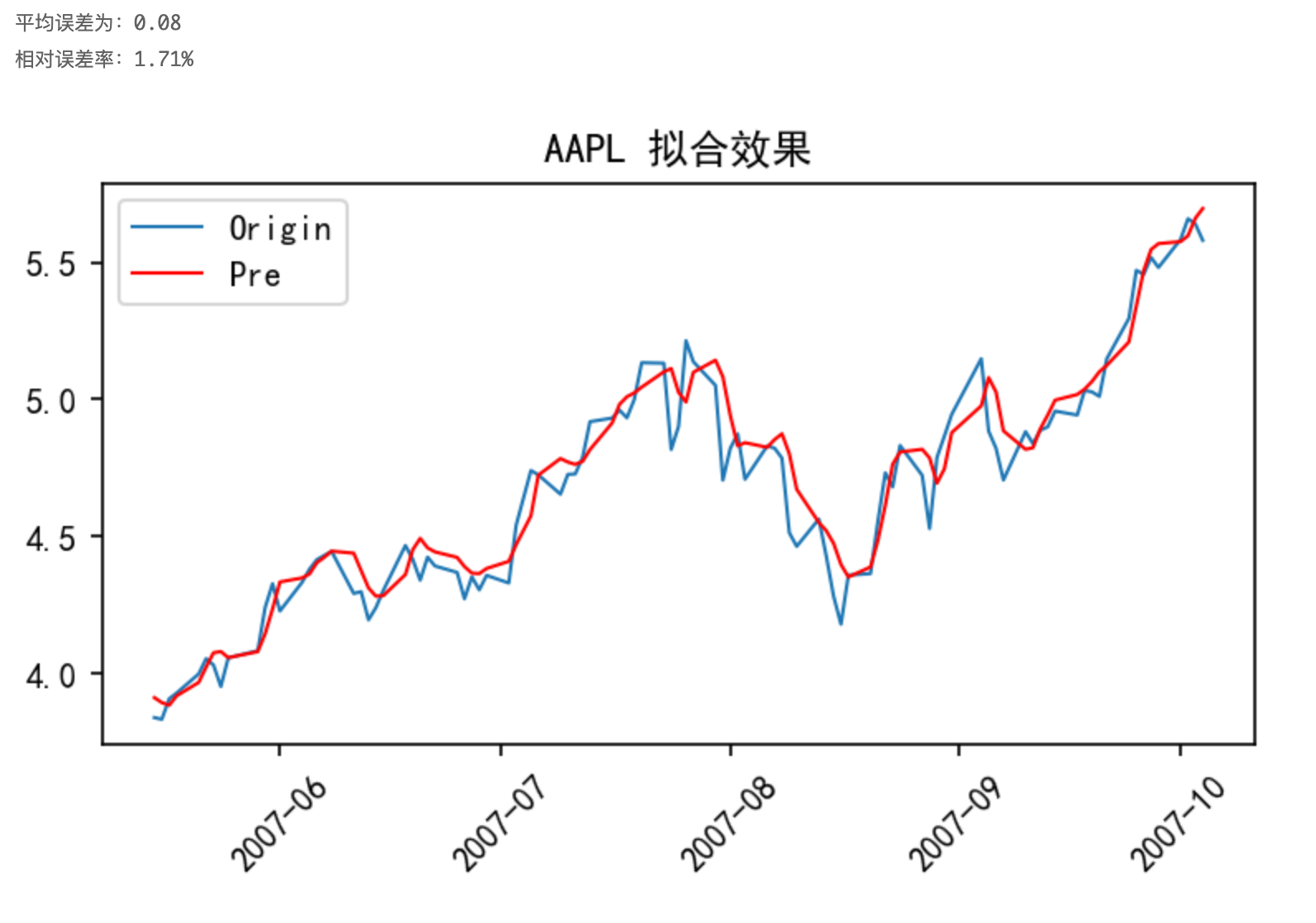
与图3对比可知,图3中平均误差为0.11,相对误差率为2.30%,采用kalman滤波后,平均误差为0.08,相对误差率为1.71%,效果变好。
通过前面2种不同数据处理方法对不同模型效果的影响,我们可以看到,不同数据处理方法对不同模型的影响不一样,但总的来说对数据进行相应的处理后,能够提升模型的性能。而通过实验我们发现Kalman滤波进行数据处理后,模型效果有显著的提升。
五、参考资料
- 王宇轩.基于卷积神经网络的股票预测[D].天津工业大学,2019.

