
- 1python爬取网页内容大作业,python爬取网页内容代码_python网络爬虫大作业
- 2利用awstats分析apache日志
- 3github 续传和加速_ghproxy
- 4Flink,spark对比
- 5鸿蒙Harmony--文本组件Text属性详解
- 6Mysql使用 SHOW TABLE STATUS命令显示表的相关信息_show table status 写到表里
- 708 - 程序的输入和输出_程序的输出
- 8OpenCv之简单的人脸识别项目(动态处理页面)_opencv人脸识别项目
- 9渗透测试工具库总结(全网最全)_mip22 is a advanced phishing tool
- 10Xilinx FPGA Multiboot-使用ICAPE2原语_icape2原语使用
Dropout理解_dropout的值是丢弃率还是保留率
赞
踩
本文转自http://geek.csdn.net/news/detail/161276
4. Dropout
4.1 Dropout简介
dropout是一种防止模型过拟合的技术,这项技术也很简单,但是很实用。它的基本思想是在训练的时候随机的dropout(丢弃)一些神经元的激活,这样可以让模型更鲁棒,因为它不会太依赖某些局部的特征(因为局部特征有可能被丢弃)。
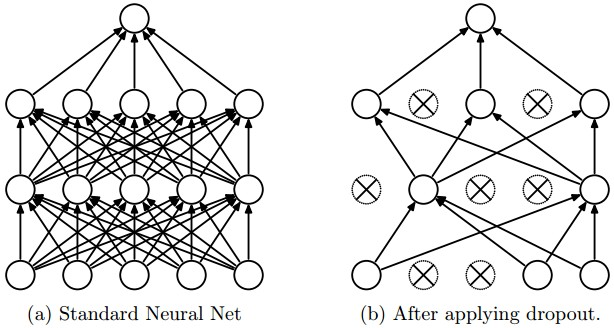
上图a是标准的一个全连接的神经网络,b是对a应用了dropout的结果,它会以一定的概率(dropout probability)随机的丢弃掉一些神经元。
4.2 Dropout的实现
实现Dropout最直观的思路就是按照dropout的定义来计算,比如上面的3层(2个隐藏层)的全连接网络,我们可以这样实现:
- """ 最原始的dropout实现,不推荐使用 """
-
- p = 0.5 # 保留一个神经元的概率,这个值越大,丢弃的概率就越小。
-
- def train_step(X):
-
- H1 = np.maximum(0, np.dot(W1, X) + b1)
- U1 = np.random.rand(*H1.shape) < p # first dropout mask
- H1 *= U1 # drop!
- H2 = np.maximum(0, np.dot(W2, H1) + b2)
- U2 = np.random.rand(*H2.shape) < p # second dropout mask
- H2 *= U2 # drop!
- out = np.dot(W3, H2) + b3
-
- # 反向梯度计算,代码从略
-
- def predict(X):
- H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations
- H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations
- out = np.dot(W3, H2) + b3
 '运行
'运行我们看函数 train_step,正常计算第一层的激活H1之后,我们随机的生成dropout mask数组U1。它生成一个0-1之间均匀分布的随机数组,然后把小于p的变成1,大于p的变成0。极端的情况,p = 0,则所有数都不小于p,因此U1全是0;p=1,所有数都小于1,因此U1全是1。因此越大,U1中1越多,也就keep的越多,反之则dropout的越多。
然后我们用U1乘以H1,这样U1中等于0的神经元的激活就是0,其余的仍然是H1。
第二层也是一样的道理。
predict函数我们需要注意一下。因为我们训练的时候会随机的丢弃一些神经元,但是预测的时候就没办法随机丢弃了【我个人觉得也不是不能丢弃,但是这会带来结果会不稳定的问题,也就是给定一个测试数据,有时候输出a有时候输出b,结果不稳定,这是实际系统不能接受的,用户可能认为你的模型有”bug“】。那么一种”补偿“的方案就是每个神经元的输出都乘以一个p,这样在”总体上“使得测试数据和训练数据是大致一样的。比如一个神经元的输出是x,那么在训练的时候它有p的概率keep,(1-0)的概率丢弃,那么它输出的期望是p x+(1-p) 0=px。因此测试的时候把这个神经元乘以p可以得到同样的期望。
但是这样测试的时候就需要多一次乘法,我们对于训练的实时性要求没有测试那么高。所以更为常见的做法是如下面的代码:
- p = 0.5 # 保留一个神经元的概率,这个值越大,丢弃的概率就越小。
-
- def train_step(X):
- H1 = np.maximum(0, np.dot(W1, X) + b1)
- U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask. Notice /p!
- H1 *= U1 # drop!
- H2 = np.maximum(0, np.dot(W2, H1) + b2)
- U2 = (np.random.rand(*H2.shape) < p) / p # second dropout mask. Notice /p!
- H2 *= U2 # drop!
- out = np.dot(W3, H2) + b3
-
- def predict(X):
- # ensembled forward pass
- H1 = np.maximum(0, np.dot(W1, X) + b1) # no scaling necessary
- H2 = np.maximum(0, np.dot(W2, H1) + b2)
- out = np.dot(W3, H2) + b3
上面的代码在训练的时候给U1的每个元素除以p,相当于给H1放大1/p倍,那么预测的时候,那么后面层的参数学到的就相当于没有dropout的情况,因此预测的时候就不需要再乘以p了。比如第1层的输出是100个神经元,假设每一个神经元的输出都是0.5。如果没有dropout,这100个神经元都会连接到第二层的第一个神经元,假设第二层的第一个神经元的参数都是1,那么它的累加和是50。如果使用了0.5的概率保留,则第二层第一个神经元的累加和变成了25。但是上面的算法,我们对每个神经元的输出都先除以0.5。也就是第一层每个输出都是1,一个100个输入给第二层的第一个神经元,然后又以0.5的概率丢弃,那么最终累加的结果还是50。这样就”相当于“补偿”了第二层的“损失”。
4.3 实现
我们打开作业2的Dropout.ipynb。
4.3.1 cell1-2
和之前的一样的代码
4.3.2 cell3
打开layers.py,把dropout_forward里缺失的代码实现如下:
- if mode == 'train':
- ###########################################################################
- # TODO: Implement the training phase forward pass for inverted dropout. #
- # Store the dropout mask in the mask variable. #
- ###########################################################################
- [N,D] = x.shape
- mask = (np.random.rand(N,D) < (1-p))/(1-p)
- out = x * mask
- ###########################################################################
- # END OF YOUR CODE #
- ###########################################################################
- elif mode == 'test':
- ###########################################################################
- # TODO: Implement the test phase forward pass for inverted dropout. #
- ###########################################################################
- out = x
- ###########################################################################
- # END OF YOUR CODE #
- ###########################################################################
代码非常简单,不过注意的是这里的p是丢弃的概率,所以保留的概率是(1-p)。
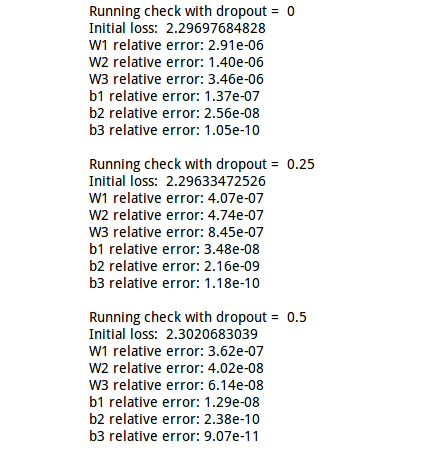
运行这个cell的结果如下图:

注意使用不同的dropout的结果是差不多的,因为我们实现的方法是“补偿”,如果您使用第一种实现,那么均值应该随着p而变化
4.3.3 cell4
接下来是实现dropout_backward,这也非常简单,只有一行代码:
if mode == ‘train’:
- ###########################################################################
- # TODO: Implement the training phase backward pass for inverted dropout. #
- ###########################################################################
- dx = mask * dout
- ###########################################################################
- # END OF YOUR CODE #
- ###########################################################################
然后我们运行cell4进行gradient check

4.3.4 cell5
然后我们需要修改fc_net.py来增加dropout的支持,具体来说,如果dropout参数不是空,那么每一个relu的输出都需要增加一个dropout。
4.3.4.1 loss函数
init里代码已经处理好了,不需要任何修改,我们只需要修改loss的forward和backward部分。
首先是loss函数的forward部分:
- dropout_cache = {}
- for i in range(1, self.num_layers):
- keyW = 'W' + str(i)
- keyb = 'b' + str(i)
-
- if not self.use_batchnorm:
- current_input, affine_relu_cache[i] = affine_relu_forward(current_input, self.params[keyW], self.params[keyb])
-
- else:
- key_gamma = 'gamma' + str(i)
- key_beta = 'beta' + str(i)
- current_input, affine_bn_relu_cache[i] = affine_bn_relu_forward(current_input, self.params[keyW],
- self.params[keyb],
- self.params[key_gamma], self.params[key_beta],
- self.bn_params[i - 1])
-
- if self.use_dropout:
- current_input, dropout_cache[i] = dropout_forward(current_input,self.dropout_param)
和之前的代码比其实就增加了两行,如果self.use_dropout。
当然还要记得在外面定义dropout_cache这个dict
然后是backward部分:
- for i in range(self.num_layers - 1, 0, -1):
- if self.use_dropout:
- affine_dx = dropout_backward(affine_dx, dropout_cache[i])
-
- if not self.use_batchnorm:
- affine_dx, affine_dw, affine_db = affine_relu_backward(affine_dx, affine_relu_cache[i])
-
- else:
- affine_dx, affine_dw, affine_db, dgamma, dbeta = affine_bn_relu_backward(affine_dx, affine_bn_relu_cache[i])
- grads['beta' + str(i)] = dbeta
- grads['gamma' + str(i)] = dgamma
在for循环的最上面增加 if self.use_dropout这两行。
注意顺序,我们是把dropout放到激活函数之后,因此反向求梯度是要最先计算affine_dx
完成代码后我们执行这个cell坚持梯度是否正确计算:
4.3.5 cell6-7
As an experiment, we will train a pair of two-layer networks on 500 training examples: one will use no dropout, and one will use a dropout probability of 0.75. We will then visualize the training and validation accuracies of the two networks over time.
接下来我们做一个实验,我们会用500个数据训练一对2层的网络:其中一个使用dropout(0.75的丢弃概率),一个不用。
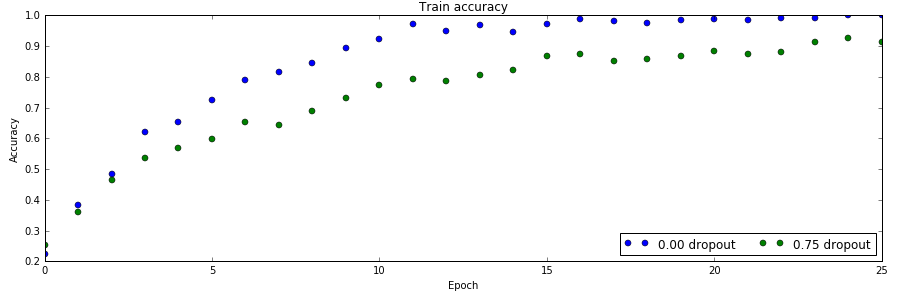
训练数据上的准确率
验证数据上的准确率
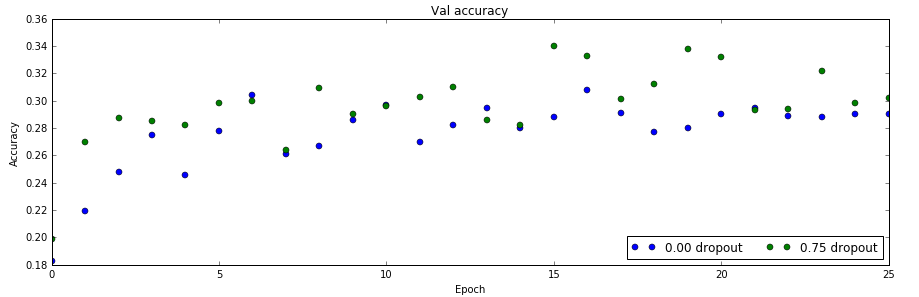
从上面两个图可以看出:不使用dropout,训练数据很少时会过拟合,在训练数据上准确率100%,但是验证数据上只有28%。而使用了dropout之后,训练数据90%,但是验证数据上能提高到30%以上。
这说明dropout确实能缓解过拟合的问题。
本篇文章介绍了Dropout技术,在下一篇文章中,我们将深入讲解一个CNN网络的具体实现。

