
- 1JavaWeb花店商城管理系统(客户端+后台端)+论文报告_花店管理系统
- 2字节的这份《算法中文刷题手册》火了,完整版562页_算法中文手册
- 3群晖NAS公网访问(IP+DNSPOD+桥接+端口转发+DDNS+WebDAV)_群晖公网ip ddns+端口转发
- 42023_JESD204B接口与协议
- 5vivado中的FPGA时钟管理单元PLL学习记录_vivado pll
- 6YOLOv8独家改进:KAN系列 | 「一夜干掉MLP」的KAN ,全新神经网络架构一夜爆火_convkan
- 7Linux - Shell 以及 权限问题
- 8SO解密过程_so文件解密
- 9Git安装教程(图文安装)_gitbash安装
- 10C++笔试强训5_c++ 选择题
全面解析自然语言处理(NLP):基础、挑战及应用前景_nlp自然语言处理
赞
踩
自然语言处理 (NLP) 简介与应用前景

自然语言处理(NLP)是人工智能和计算语言学的一个分支,致力于使计算机能够理解、解释和生成人类语言。这篇博文将深入探讨自然语言处理的基础知识、挑战、典型任务及其广泛的应用前景。
一、自然语言处理的基本概念
1. 自然语言与编程语言
自然语言是人与人之间用以交流信息、思想和知识的工具,而编程语言则是人类与计算机之间的交流工具。自然语言具有以下特点:
- 动态性和多样性:自然语言随着时间的推移不断演变,产生新词汇和新用法。新词汇的出现和现有词汇的变异为NLP系统提出了巨大的挑战。举例来说,随着网络文化的发展,新的网络用语层出不穷,这些新词往往带有强烈的时代特征和社会背景,如何及时准确地理解这些新词的含义是自然语言处理的一大难题。
- 歧义性:自然语言中常常存在多义词,需要上下文来进行消歧。一个典型的例子是“bank”这个词,在不同的上下文中可能表示“银行”或者“河岸”。在自然语言处理中,如何通过上下文准确判断词义,是提高系统理解能力的关键。
- 递归性:自然语言使用递归结构来表达复杂的信息。例如,嵌套的从句和复杂的句法结构在日常语言中非常普遍,这种递归结构增加了自然语言处理的复杂性,需要更加精细的算法来处理和理解。
2. 自然语言处理的定义
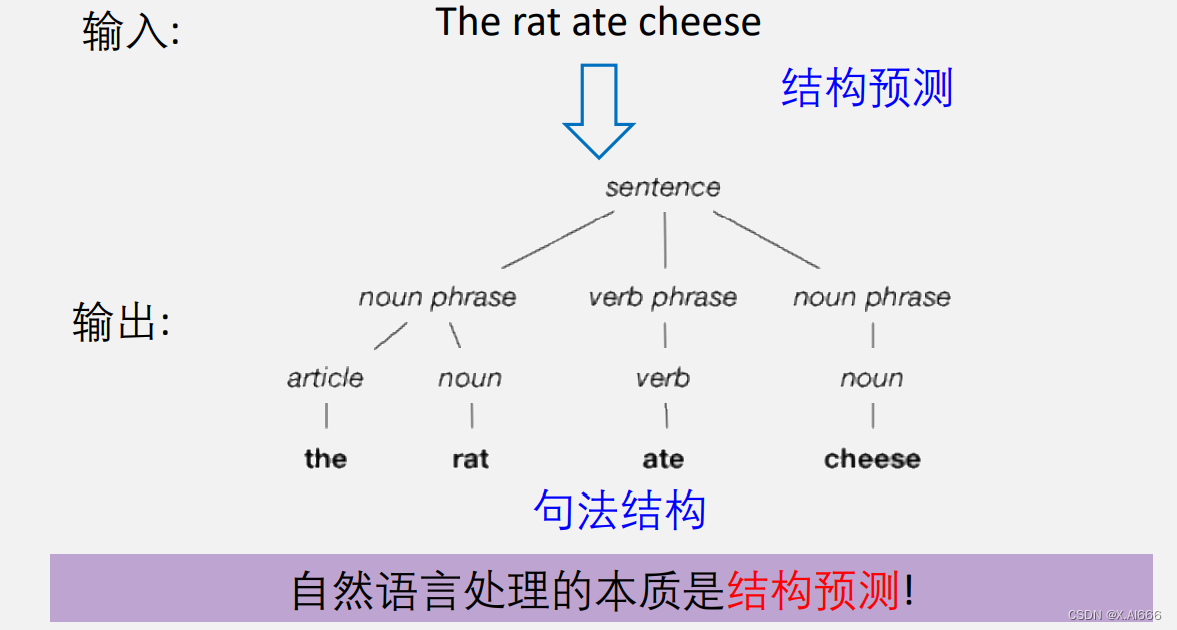
自然语言处理致力于使计算机理解和生成自然语言。其本质在于结构预测,即从输入的自然语言中提取出有用的结构化信息。例如,从句子“The rat ate cheese”中提取出其句法结构。结构预测的过程涉及到多个层次的语言分析,包括词法分析、句法分析和语义分析等。
自然语言处理的最终目标是实现人与机器之间的自然语言交流,使计算机能够像人类一样理解和使用语言。为此,需要构建复杂的模型和算法,模拟人类的语言处理过程。这包括语音识别、文本生成、机器翻译等多个方面的技术。
二、自然语言处理的挑战
1. 搜索空间的指数增长

随着句子长度的增加,句法分析的搜索空间成指数增长。例如,当句子长度为20时,搜索空间大小为1,767,263,190,这给计算带来了巨大的挑战。搜索空间的增长意味着计算量的急剧增加,传统的穷举搜索方法在面对长句时变得不可行。
为了应对这一挑战,研究人员提出了各种优化算法和启发式方法,例如基于统计的句法分析和基于深度学习的句法解析。这些方法利用大规模语料库中的统计信息或者通过训练神经网络模型来预测句法结构,有效地减少了搜索空间,提高了句法分析的效率和准确性。
2. 词汇和语义的多样性
自然语言中不断出现的新词汇和现有词语的新含义,使得动态词嵌入成为一种必要的技术。动态词嵌入能够跟踪词语意义的演变,提升语义理解的准确性。传统的词嵌入方法如Word2Vec和GloVe,虽然在固定语料库上表现良好,但在面对不断变化的语言环境时显得力不从心。
为了适应语言的动态变化,研究人员提出了基于上下文的动态词嵌入方法,如ELMo和BERT。这些方法不仅考虑了词语的静态向量表示,还利用上下文信息动态调整词语的嵌入向量,使得同一个词在不同上下文中的表示能够反映其实际含义。这种动态词嵌入方法极大地提升了自然语言处理系统的语义理解能力。
3. 递归和歧义
递归结构在自然语言中无处不在,这要求NLP系统能够处理复杂的递归信息。此外,歧义现象在单词、句子和篇章中普遍存在,人们通常根据上下文或已有知识进行消歧。这些都对NLP系统提出了很高的要求。递归结构的处理需要系统具备较强的层级关系理解能力,而歧义现象的消解则需要系统能够综合利用上下文信息和外部知识。
近年来,深度学习在自然语言处理中的应用取得了显著进展,特别是在处理递归结构和消解歧义方面。基于递归神经网络(RNN)和长短期记忆网络(LSTM)的模型能够有效处理序列数据,捕捉句子中的递归结构。同时,注意力机制(Attention Mechanism)和变换模型(Transformer)则在处理长距离依赖和多义词消解方面展现出强大的能力。这些技术的结合,使得NLP系统在处理复杂的语言结构和消解歧义方面取得了显著的进步。
三、自然语言处理的典型任务
1. 机器翻译
机器翻译是NLP的一个重要应用领域,从最早的基于规则的方法发展到现在的基于神经网络的方法,机器翻译的准确性和流畅性得到了显著提升。基于规则的机器翻译方法依赖于预定义的语法规则和词典,对于特定领域的翻译效果较好,但在处理语言的多样性和复杂性方面表现不佳。
统计机器翻译方法(SMT)通过从大规模双语语料库中学习翻译规则,显著提高了翻译的灵活性和准确性。然而,SMT方法仍然存在一些局限性,如词语翻译的独立性假设和长句处理的困难。
近年来,神经机器翻译(NMT)方法凭借其强大的建模能力和端到端训练的优势,迅速成为机器翻译的主流技术。NMT方法通过神经网络模型直接学习从源语言到目标语言的映射关系,能够更好地捕捉上下文信息和长距离依赖。特别是基于Transformer架构的NMT模型,如Google的BERT和OpenAI的GPT系列,在多个机器翻译基准测试中取得了领先的性能,显著提升了机器翻译的质量和用户体验。
2. 情感分析和意图识别
情感分析和意图识别通过文本或语音来获取用户的内在情感或意图,广泛应用于社交媒体监控、客户服务和市场分析等领域。情感分析的任务是判断一段文本或语音中所表达的情感是积极的、消极的还是中性的,而意图识别则是理解用户的具体意图,如购买意图、查询意图等。
情感分析和意图识别的方法主要分为基于词典的方法和基于机器学习的方法。基于词典的方法依赖于预定义的情感词典和规则,通过匹配文本中的情感词来判断情感倾向。这种方法简单直观,但在处理复杂情感表达和多义词时表现不佳。
基于机器学习的方法通过训练分类器来识别情感和意图,具有更高的灵活性和准确性。特别是基于深度学习的方法,如卷积神经网络(CNN)和循环神经网络(RNN),能够自动学习文本的情感特征和意图模式,显著提升了情感分析和意图识别的性能。此外,多模态情感分析方法结合了文本、语音和视觉等多种信息来源,进一步提高了情感识别的准确性和鲁棒性。
3. 知识图谱
知识图谱通过结构化的方式展示实体及其关系,广泛应用于搜索引擎、问答系统和推荐系统中。知识图谱的构建过程包括知识抽取、知识表示和知识推理等多个步骤。
知识抽取是从海量文本数据中自动抽取实体及其关系的过程。传统的知识抽取方法主要依赖于规则和模板,具有较高的准确性,但在处理大规模数据时效率较低。近年来,基于深度学习的知识抽取方法得到了广泛关注,这些方法通过训练神经网络模型来自动学习抽取规则,显著提升了知识抽取的效率和准确性。
知识表示是将抽取的知识以图的形式进行表示,其中节点表示实体,边表示实体之间的关系。知识图谱的表示方式多种多样,包括基于图数据库的表示、基于向量的表示和基于张量的表示等。不同的表示方式具有不同的优缺点,需要根据具体应用场景进行选择。
知识推理是利用已有的知识进行推理和推断的过程。知识推理的方法主要包括基于规则的推理和基于机器学习的推理。基于规则的推理方法依赖于预定义的逻辑规则,通过逻辑推理来得出结论。这种方法具有较高的解释性,但在处理复杂知识时效率较低。基于机器学习的推理方法通过训练模型来自动学习推理规则,具有更高的灵活性和扩展性,能够处理大规模复杂知识图谱。
四、自然语言处理的应用前景
1. 科学影响力
自然语言处理在科学研究中具有重要影响。例如,图灵测试通过自然语言来测试机器是否具有与人类相近的智能行为。图灵测试的核心是通过自然语言交流,使测试者无法分辨出被测试的是人还是机器。这一测试方法不仅检验了机器的语言理解和生成能力,还考察了其应对复杂对话场景的能力。
此外,NLP技术在生物医学、社会科学和人文学科等领域也有广泛应用。例如,在生物医学领域,NLP技术可以用于处理和分析大量的医学文献,辅助药物研发和疾病诊断。在社会科学和人文学科领域,NLP技术可以用于分析历史文献、社交媒体数据和新闻报道,揭示社会舆情和文化变迁的趋势。
2. 应用影响力
自然语言处理在商业应用中具有广泛的前景。各大IT巨头如苹果、谷歌等均发布了自然语言处理相关的应用,如Siri、Google Knowledge Graph等。下一代搜索引擎将会是自然语言问答系统,能够更好地理解用户的自然语言查询并给出精确的答案。
商业领域的应用主要包括智能客服、语音助手、文本分析和推荐系统等。智能客服系统利用NLP技术能够自动回答客户的常见问题,提升客服效率并减少人工成本。语音助手如Siri和Alexa,通过语音识别和自然语言理解技术,为用户提供便捷的语音交互体验。文本分析技术则用于处理和分析大规模文本数据,提取有价值的信息,辅助商业决策。推荐系统通过分析用户的行为和偏好,提供个性化的商品或内容推荐,提升用户满意度和转化率。
3. 计算社会学
通过对语言使用的研究,可以揭示人类的心理状态和文化变革。例如,哈佛大学的研究者使用谷歌图书中的关键词来研究人类文化的变革,揭示了文化组学(Culturomics)这一新的研究领域。
计算社会学结合NLP技术,通过分析社交媒体、新闻报道、文学作品等大量语言数据,研究社会行为和文化现象。例如,研究人员可以通过分析社交媒体上的语言使用模式,揭示社会热点事件和公众情绪的变化。通过分析新闻报道中的关键词,研究政治、经济和文化的变迁趋势。通过分析文学作品中的语言风格,研究不同时期的文学创作特点和文化背景。
五、总结
自然语言处理作为人工智能的一个重要分支,正在快速发展并渗透到各个领域。尽管面临着搜索空间指数增长、词汇和语义多样性、递归和歧义等诸多挑战,NLP技术在机器翻译、情感分析、知识图谱等领域取得了显著进展,并展现出了广阔的应用前景。未来,随着技术的不断进步,自然语言处理将进一步推动人工智能的发展,为人类生活和科学研究带来更多的便利和创新。
自然语言处理不仅是一门技术,更是一种工具,它正在改变我们的生活方式和工作方式。通过深入理解和应用自然语言处理技术,我们可以更好地应对信息时代的挑战,创造更加智能和便捷的未来。如果您有任何问题或需要进一步探讨,欢迎在评论区留言。

