
- 1Android 平台编解码——软解、硬解对比_android硬件编解码
- 2【计算机网络】5G网络切片技术 - - 网络切片的多资源分配【含论文解读】_网络切片毕业设计论文
- 3【Turtle库知识 】01--Python下的turtle绘图库详解_turtle画图
- 4如何使用T5进行关键词提取?_t5提取新闻标题
- 5信号处理之快速傅里叶变换(FFT)-通俗易懂
- 6表达式计算_符号运算 给定一个表达式,求其分数计算结果 算法
- 7【智能制造-18】多机器人的干涉区任务规划和防碰撞策略
- 820个值得做的AI变现案例分享,副业搞钱“支棱”起来_人工智能小项目
- 9pyqt事件循环_pyqt qeventloop_pyqt qeventloop()
- 10adb 连接 显示 List of devices attached_list of devices attached eior9tlnhqtgpzyx device 1
什么是大型语言模型 (LLM)
赞
踩
本章探讨下,人工智能如何彻底改变我们理解和与语言互动的方式
大型语言模型 (LLM) 代表了人工智能的突破,它采用具有广泛参数的神经网络技术进行高级语言处理。
本文探讨了 LLM 的演变、架构、应用和挑战,重点关注其在自然语言处理 (NLP) 领域的影响。

什么是大型语言模型(LLM)?
大型语言模型是一种人工智能算法,它应用具有大量参数的神经网络技术,使用自监督学习技术来处理和理解人类语言或文本。文本生成、机器翻译、摘要写作、文本图像生成、机器编码、聊天机器人或对话式人工智能等任务都是大型语言模型的应用。此类 LLM 模型的示例包括 Open AI 的 Chat GPT、Google 的 BERT(来自 Transformers 的双向编码器表示)等。
有许多技术尝试执行与自然语言相关的任务,但 LLM 纯粹基于深度学习方法。LLM(大型语言模型)模型能够高效地捕捉手头文本中的复杂实体关系,并且可以使用我们希望使用的特定语言的语义和句法来生成文本。
LLM 模型
如果我们只谈论 GPT (生成式预训练 Transformer) 模型的进步规模,那么:
·2018 年发布的 GPT-1 包含 1.17 亿个参数,有 9.85 亿个单词。
·2019年发布的GPT-2包含15亿个参数。
·2020 年发布的 GPT-3 包含 1750 亿个参数。Chat GPT 也是基于这个模型。
·GPT-4模型预计将于2023年发布,可能包含数万亿个参数。
大型语言模型如何工作?
大型语言模型 (LLM) 依据深度学习原理运行,利用神经网络架构来处理和理解人类语言。
这些模型使用自监督学习技术在大量数据集上进行训练。其功能的核心在于它们在训练过程中从各种语言数据中学习到的复杂模式和关系。LLM 由多个层组成,包括前馈层、嵌入层和注意层。它们采用注意机制(如自注意力)来衡量序列中不同标记的重要性,从而使模型能够捕获依赖关系和关系。
(LLM) 的架构
大型语言模型 (LLM) 的架构由许多因素决定,例如特定模型设计的目标、可用的计算资源以及 LLM 要执行的语言处理任务类型。LLM 的一般架构由许多层组成,例如前馈层、嵌入层、注意层。嵌入其中的文本相互协作以生成预测。
影响大型语言模型架构的重要组件——
·模型大小和参数数量
·输入表示
·自注意力机制
·培训目标
·计算效率
·解码和输出生成
基于 Transformer 的 LLM 模型架构
基于 Transformer 的模型彻底改变了自然语言处理任务,它通常遵循包含以下组件的通用架构:
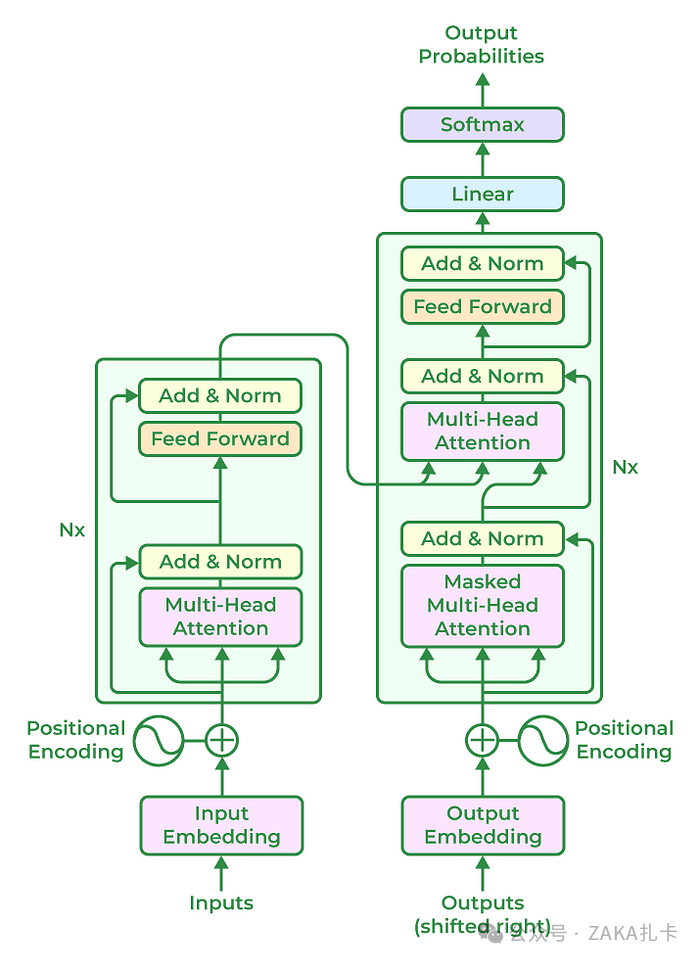
1.**输入嵌入:**将输入文本标记为较小的单元,例如单词或子单词,并将每个标记嵌入到连续向量表示中。此嵌入步骤捕获输入的语义和句法信息。
2.**位置编码:**位置编码被添加到输入嵌入中,以提供有关标记位置的信息,因为转换器不会自然地对标记的顺序进行编码。这使模型能够在考虑标记的顺序的同时处理标记。
3.**编码器:**编码器基于神经网络技术,分析输入文本并创建多个隐藏状态,以保护文本数据的上下文和含义。多个编码器层构成了 Transformer 架构的核心。自注意力机制和前馈神经网络是每个编码器层的两个基本子组件。
4.**自注意力机制:**自注意力机制使得模型能够通过计算注意力分数来衡量输入序列中不同 token 的重要性。它允许模型以上下文感知的方式考虑不同 token 之间的依赖关系和关系。
5.**前馈神经网络:**在自注意力步骤之后,前馈神经网络将独立应用于每个 token。该网络包括具有非线性激活函数的全连接层,允许模型捕获 token 之间的复杂交互。
6.**解码器层:**在一些基于 Transformer 的模型中,除了编码器外,还包含解码器组件。解码器层支持自回归生成,其中模型可以通过关注先前生成的标记来生成顺序输出。
7.多头注意力: Transformer 通常采用多头注意力,其中自注意力与不同的学习注意力权重同时执行。这使模型能够捕捉不同类型的关系并同时关注输入序列的各个部分。
8.层规范化: Transformer 架构中每个子组件或层之后都应用层规范化。它有助于稳定学习过程,并提高模型在不同输入之间进行泛化的能力。
9.输出层: Transformer 模型的输出层可能因具体任务而异。例如,在语言建模中,通常使用线性投影后跟 SoftMax 激活来生成下一个 token 的概率分布。
需要记住的是,基于 Transformer 的模型的实际架构可以根据特定研究和模型创建进行更改和增强。为了完成不同的任务和目标,GPT、BERT 和 T5 等多个模型可能会集成更多组件或修改。
大型语言模型示例
·GPT-3:GPT 的全称是生成式预训练 Transformer,这是该模型的第三个版本,因此编号为 3。这是由 Open AI 开发的,你一定听说过由 Open AI 推出的 Chat GPT,它就是 GPT-3 模型。
·**BERT——**全称是 Transformers 的双向编码器表示。这种大型语言模型由 Google 开发,通常用于与自然语言相关的各种任务。此外,它还可用于为特定文本生成嵌入,或用于训练其他模型。
·**RoBERTa——**其全称是鲁棒优化 BERT 预训练方法。在一系列提高 Transformer 架构性能的尝试中,RoBERTa 是 Facebook AI Research 开发的 BERT 模型的增强版本。
·**BLOOM——**这是第一个由不同组织和研究人员联合产生的多语言法学硕士,他们结合自己的专业知识开发出类似于 GPT-3 架构的模型。
要进一步探索这些模型,您可以单击特定模型以了解如何使用开源平台(如 Open AI 的 Hugging Face)来使用它们。这些文章介绍了 Python 中每个模型的实现部分。
LLM 如此受欢迎的主要原因是它们能够高效地完成各种任务。从以上关于 LLM 的介绍和技术信息中,您一定已经了解到 Chat GPT 也是 LLM,因此,让我们用它来描述大型语言模型的用例。
·代码生成——这项服务最疯狂的用例之一是,它可以为用户向模型描述的特定任务生成相当准确的代码。
·代码调试和文档编制— 如果您在调试某段代码时遇到困难,那么 ChatGPT 就是您的救星,因为它可以告诉您哪一行代码产生了问题以及纠正这些问题的办法。此外,现在您不必花费数小时编写项目文档,您可以让 ChatGPT 为您完成这项工作。
·问答——您一定已经看到,当人工智能个人助理发布时,人们常常向他们提出一些疯狂的问题,那么您也可以在这里这样做,以及提出真正的问题。
·语言转换——它可以将一段文本从一种语言转换为另一种语言,因为它支持 50 多种母语。它还可以帮助您纠正内容中的语法错误。
LLM 的使用案例不仅限于上述内容,只要有足够的创造力来编写更好的提示,您就可以让这些模型执行各种任务,因为它们经过训练可以执行一次性学习和零次学习方法的任务。正因为如此,对于那些期待广泛使用 ChatGPT 类型模型的人来说,只有 Prompt Engineering 才是学术界的一个全新热门话题。
大型语言模型应用
GPT-3 等 LLM 在各个领域都有广泛的应用。其中包括:
自然语言理解 (NLU)
1.大型语言模型为能够进行自然对话的高级聊天机器人提供动力。
2.它们可用于创建智能虚拟助手,执行调度、提醒和信息检索等任务。
内容生成
1.创建类似人类的文本以用于各种目的,包括内容创作、创意写作和讲故事。
2.根据自然语言描述或命令编写代码片段。
语言翻译
大型语言模型可以帮助提高不同语言之间的文本翻译的准确性和流畅度。
文本摘要
生成较长的文本或文章的简洁摘要。
情绪分析
分析和理解社交媒体帖子、评论和评价中表达的情感。
NLP和LLM之间的区别
NLP 是自然语言处理,是人工智能 (AI) 的一个领域。它包括算法的开发。NLP 是一个比 LLM 更广泛的领域,后者包括算法和技术。NLP 规则两种方法,即机器学习和分析语言数据。NLP 的应用包括:
·汽车常规任务
·改进搜索
·搜索引擎优化
·分析和组织大型文档
·社交媒体分析。
另一方面,LLM 是一种大型语言模型,更针对类似人类的文本,提供内容生成和个性化推荐。
大型语言模型有哪些优势?
大型语言模型 (LLM) 具有多种优势,有助于其在各种应用中得到广泛采用和成功:
·LLM 可以执行零样本学习,这意味着它们可以推广到未经明确训练的任务。此功能允许在无需额外训练的情况下适应新的应用程序和场景。
·LLM能够高效处理大量数据,适合执行需要深入理解大量文本语料库的任务,例如语言翻译和文档摘要。
·LLM 可以在特定数据集或领域进行微调,从而实现持续学习并适应特定用例或行业。
·LLM可以实现各种与语言相关的任务的自动化,从代码生成到内容创建,从而释放人力资源以用于项目中更具战略性和更复杂的方面。
大型语言模型训练的挑战
人们对法学硕士未来的能力毫不怀疑,这项技术是大多数人工智能应用程序的一部分,每天都会被多个用户使用。但法学硕士也有一些缺点。
·为了成功训练大型语言模型,需要投入数百万美元来建立能够利用并行性能训练模型的强大计算能力。
·它需要数月的训练,然后由人类参与对模型进行微调,以实现更好的性能。
·获取大量文本语料库可能是一项艰巨的任务,因为 ChatGPT 被指控仅使用非法抓取的数据进行训练,并为商业目的构建应用程序。
·在全球变暖和气候变化的时代,我们不能忘记法学硕士的碳足迹,据说从头开始训练一个人工智能模型的碳足迹相当于五辆汽车在其整个生命周期内的碳足迹,这是一个真正严重的问题。
结论
由于在训练中面临的挑战,LLM 迁移学习被大力推广,以摆脱上述所有挑战。LLM 有能力为人工智能应用带来革命,但该领域的进步似乎有点困难,因为仅仅增加模型的大小可能会提高其性能,但在特定时间之后,性能就会达到饱和,处理这些模型的挑战将大于通过进一步增加模型大小所实现的性能提升。

