
- 1跨境电子商务支付与结算_跨境电商结算模块
- 2WatchAD内网安全态势感知系统搭建_watchad2.0
- 3【CSDN个人博客简介_倪良】_csdn个人简介
- 4RocketMQ 的消费者类型详解与最佳实践_rocketmq 消费者
- 5模拟退火算法介绍及matlab实现_matlab模拟退火算法
- 6python 视频特效库_moviepy: MoviePy 是一个用于视频编辑的Python库:剪切,连接,标题插入,视频合成(也称为非线性编辑),视频处理和创建自定义效果...
- 7【ESP32接入国产大模型之星火】_spark 4.0 ultra评测
- 8Java进阶部分的总结,你们都学会了吗?
- 9java段注释_Java的注释
- 10cc2540 连接时操作的函数_cc2540连接函数
PyTorch实战:BI-LSTM模型的情感分析详解_pytorch bi-lstm
赞
踩
总述
本文的目标是针对一个句子,给出其情感二分类,正向/负向。
代码存放地址:
https://github.com/stay-leave/BI-LSTM-sentiment-classify
输入数据集格式:
标签为1代表正向,0代表负向。
txt版本(即训练集、测试集不在一个文件内),这里我用的是百度千言数据集:

xls版本(即训练集、测试集在一个文件内):

输出数据示例:
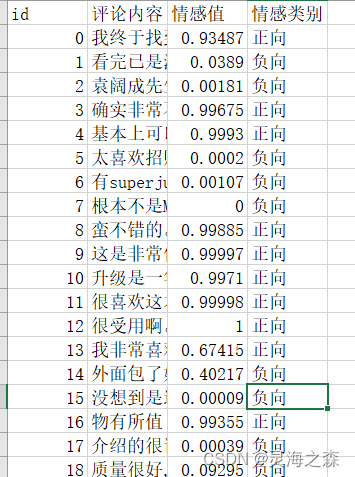
接下来对整个流程作梳理。
数据处理
目标:将原始数据转为tensor并加载到dataloader,以供后续使用。
思路是将文本从txt或xls中提取出来,进行分词,划分句子长度,将句子进行编码,最后将其加载到pytorch的dataloader类。
1.提取文件
txt文件的提取:
def txt_file(self,inpath):
#输入TXT,返回列表
data = []
fp = open(self.inpath,'r',encoding='utf-8')
for line in fp:
line=line.strip('\n')
line=line.split('\t')
data.append(line)
data=data[1:]#去掉表头
return data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
xls文件的提取:
def xls_file(self,inpath):
"""提取一个文件为一个列表"""
data = xlrd.open_workbook(self.inpath, encoding_override='utf-8')
table = data.sheets()[0]#选定表
nrows = table.nrows#获取行号
ncols = table.ncols#获取列号
numbers=[]
for i in range(1, nrows):#第0行为表头
alldata = table.row_values(i)#循环输出excel表中每一行,即所有数据
numbers.append(alldata)
return numbers
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
结果如下:

2.对句子进行分词
上面的数据中同时包含句子和标签,因此需要将其分开进行处理。
这是txt文件的代码,若使用xls文件,需要注释掉splitt函数的label那一行,取消下一行的注释。
def tokenlize(self,sentence): #分词,只要/保留 中文/其他字符,单句 #sentence = re.sub('[^\u4e00-\u9fa5]+','',sentence) URL_REGEX = re.compile(r'(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,<>?«»“”‘’]))',re.IGNORECASE) sentence= re.sub(URL_REGEX,'', sentence)# 去除网址 sentence =jieba.cut(sentence.strip(),cut_all=False,use_paddle=10)#默认精确模式 out=[] for word in sentence: out.append(word) return out def splitt(self,data): #句子和标签的提取 sentence=[] label=[] for i in data: sentence.append(self.tokenlize(i[1])) label.append(int(i[0]))#使用txt #label.append(int(i[2]))#使用xls sentence=tuple(sentence) label=tuple(label) return sentence,label

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
结果如下:

3.建立字典,对句子进行编码
思路是统计词频,将句子转换为数字序列,同时根据自己设置的句子长度对句子进行截取和补全。
这里使用PAD:0作为补全和未登录词的表示。
首先是建立字典,(词:词频):
txt与xls的转换同上
def count_s(self): #统计词频,排序,建立词典(词和序号对) sentence,label=self.splitt(self.txt_file(self.inpath))#提取数据,分词,使用txt读取 #sentence,label=self.splitt(self.xls_file(self.inpath))#提取数据,分词,使用xls读取 count_dict = dict()#普通词典,词:词频 sentences=[]#合并列表 for i in sentence: sentences += i for item in sentences: if item in count_dict: count_dict[item] += 1 else: count_dict[item] = 1 #print(count_dict) #count_dict_s = sorted(count_dict.items(),key=lambda x: x[1], reverse=True)#以值来排序 count_dict_s = collections.OrderedDict(sorted(count_dict.items(),key=lambda t:t[1], reverse=True))#降序 #print('排序字典:') #print(count_dict_s) vocab=list(count_dict_s.keys())#转换成列表 vocab_index=[i for i in range(1,len(vocab)+1)]#索引值 vocab_to_index = dict(zip(vocab, vocab_index))#词汇索引 vocab_to_index["PAD"] = 0#补全 #vocab_to_index["UNK"] = 0#补零 return vocab_to_index,sentence,label,sentences
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
结果如下:

有了字典就可以对一个句子进行编码,即转换为数字序列。
同样的,也可以将一个数字序列转换为句子。
def seq_to_array(self,seq,vocab_to_index): #单个句子转换为数字序列,顺序输出标签,需要先将句子分词 #inputs = [] #for i in seq:#取单个句子 seq_index=[]#单个句子的数字序列 for word in seq:#取句子的词 if word in vocab_to_index:#句子的字在字典中 seq_index.append(vocab_to_index[word]) else: seq_index.append(0)#未登录词的处理,为pad # 保持句子长度一致 if len(seq_index) < self.seq_length:#若句子的数字序列短,补全为0 seq_index = [0] * (self.seq_length-len(seq_index)) + seq_index elif len(seq_index) > self.seq_length:#若句子的数字序列长,截断 seq_index = seq_index[:self.seq_length] else: seq_index=seq_index #inputs.append(seq_index)#所有句子的数字序列 #targets = [i for i in label]#对应标签 return seq_index
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
对于句子
‘你好!我是初学者!’
转换如下:

def array_to_seq(self,indices):
#数字序列转换为句子,一批
vocab_to_index,sentence,label,sentences=self.count_s()
seqs=[]#全部
for i in indices:
seq=[]#单句
for j in i:
for key, value in vocab_to_index.items():
if value==j:
seq.append(key)
seqs.append(seq)
return seqs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
对于上面的数字序列
[[0, 0, 0, 0, 6322, 0, 4, 3, 724, 0]]
转换为句子如下:

对句子的编码完毕,接下来就可以加载到tensor了。
4.将数据加载到dataloader类
以训练集txt文件的加载为例,先是投入句子的编码列表,再转为数组,然后加载到dataloader中。
def data_for_train_txt(self,sentence,vocab_to_index,label): #加载训练集 features=[self.seq_to_array(seq,vocab_to_index) for seq in sentence]#将所有分词好的句子转换为数字序列 # 随机打乱索引 random_order = list(range(len(features))) np.random.seed(2) # 固定种子 np.random.shuffle(random_order)#洗牌 #训练集to数组 features_train = np.array([features[i] for i in random_order]) label_train = np.array([label[i] for i in random_order])[:, np.newaxis] #print(features_train.shape,label_train.shape)#打印形状 #加载到tensor train_data = TensorDataset(torch.LongTensor(features_train), torch.LongTensor(label_train)) train_sampler = RandomSampler(train_data) train_loader = DataLoader(train_data, sampler=train_sampler, batch_size=self.batch_size, drop_last=True) return train_loader
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
数据处理完成!接下来进行模型构建。
BI-LSTM模型构建
关于该模型的原理这篇大神的博客讲得非常好
https://blog.csdn.net/weixin_42118657/article/details/120022112
实现代码如下,基本每一步都有注释:
class BI_lstm(nn.Module): def __init__(self, vocab_size,vocab_to_index,n_layers,hidden_dim,embed,output_size,dropout): super(BI_lstm, self).__init__() self.n_layers = n_layers # LSTM的层数 self.hidden_dim = hidden_dim# 隐状态的维度,即LSTM输出的隐状态的维度 self.embedding_dim = embed # 将单词编码成多少维的向量 self.dropout=dropout # dropout self.output_size=output_size # 定义embedding,随机将数字编码成向量。还没学会怎么使用预训练词向量 self.embedding = nn.Embedding(vocab_size, self.embedding_dim,padding_idx=vocab_to_index['PAD']) self.lstm = nn.LSTM(self.embedding_dim, # 输入的维度 hidden_dim, # LSTM输出的hidden_state的维度 n_layers, # LSTM的层数 dropout=self.dropout, batch_first=True, # 第一个维度是否是batch_size bidirectional = True#双向 ) # LSTM结束后的全连接线性层 self.fc = nn.Linear(self.hidden_dim*2, self.output_size ) # 由于情感分析只需要输出0或1,所以输出的维度是1# 将LSTM的输出作为线性层的输入 self.sigmoid = nn.Sigmoid() # 线性层输出后,还需要过一下sigmoid self.tanh = torch.nn.Tanh()#激活函数 #self.softmax=nn.Softmax() # 给最后的全连接层加一个Dropout self.dropout = nn.Dropout(self.dropout) def forward(self, x, hidden): """ x: 本次的输入,其size为(batch_size, 200),200为句子长度 hidden: 上一时刻的Hidden State和Cell State。类型为tuple: (h, c), 其中h和c的size都为(n_layers, batch_size, hidden_dim) """ # 因为一次输入一组数据,所以第一个维度是batch的大小 batch_size = x.size(0) # 由于embedding只接受LongTensor类型,所以将x转换为LongTensor类型 x = x.long() # 对x进行编码,这里会将x的size由(batch_size, 200)转化为(batch_size, 200, embedding_dim) embeds = self.embedding(x) #embeds=self.relu(embeds) # 将编码后的向量和上一时刻的hidden_state传给LSTM,并获取本次的输出和隐状态(hidden_state, cell_state) # lstm_out的size为 (batch_size, 200, 128),200是单词的数量,由于是一个单词一个单词送给LSTM的,所以会产生与单词数量相同的输出 # hidden为tuple(hidden_state, cell_state),它们俩的size都为(2, batch_size, 512), 2是由于lstm有两层。由于是所有单词都是共享隐状态的,所以并不会出现上面的那个200 lstm_out, hidden = self.lstm(embeds, hidden) # 接下来要过全连接层,所以size变为(batch_size * 200, hidden_dim), # 之所以是batch_size * 200=40000,是因为每个单词的输出都要经过全连接层。 # 换句话说,全连接层的batch_size为40000 lstm_out = lstm_out.contiguous().view(-1, self.hidden_dim) # 给全连接层加个Dropout out = self.dropout(lstm_out) # 将dropout后的数据送给全连接层 # 全连接层输出的size为(40000, 1) out=torch.reshape(out,(-1,256))#改变形状 out=self.tanh(out)#隐藏层激活函数 out = self.fc(out) # 过一下sigmoid out = self.sigmoid(out) # 将最终的输出数据维度变为 (batch_size, 200),即每个单词都对应一个输出 out = out.view(batch_size, -1) # 只取最后一个单词的输出 # 所以out的size会变为(200, 1) out = out[:,-1] # 将输出和本次的(h, c)返回 return out,hidden def init_hidden(self, batch_size): """ 初始化隐状态:第一次送给LSTM时,没有隐状态,所以要初始化一个 这里的初始化策略是全部赋0。 这里之所以是tuple,是因为LSTM需要接受两个隐状态hidden state和cell state """ hidden = (torch.zeros(self.n_layers*2, batch_size, self.hidden_dim).to(device), torch.zeros(self.n_layers*2, batch_size, self.hidden_dim).to(device) ) return hidden
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
结果如下:

模型的训练和评估
将数据投喂给模型,进行训练。
def train(config,model,train_loader): #模型训练 model.train() optimizer = torch.optim.Adam(model.parameters(), lr=config.lr)# criterion = nn.BCELoss()# 分类问题 y_loss=[]#训练过程的所有loss for e in range(config.epochs): # initialize hidden state,初始化隐层状态 h = model.init_hidden(config.batch_size) counter = 0 train_losses=[] # 分批 for inputs, labels in train_loader: counter += 1 inputs, labels = inputs.cuda(), labels.cuda()# GPU h = tuple([each.data for each in h]) #model.zero_grad()#梯度清零 output,h= model(inputs, h) output=output[:, np.newaxis]#加上新的维度 #print(inputs) #print(output) #print(labels.float()) train_loss = criterion(output, labels.float()) train_losses.append(train_loss.item()) optimizer.zero_grad() train_loss.backward()#反向传播 optimizer.step()#更新权重 # loss 训练集信息 if counter % config.print_every == 0:#打印间隔 print("Epoch: {}/{}, ".format(e+1, config.epochs), "Step: {}, ".format(counter), "Loss: {:.6f}, ".format(train_loss.item()), "Val Loss: {:.6f}".format(np.mean(train_losses))) y_loss.append(train_loss.item())#写入 # 训练完画图 x = [i for i in range(len(y_loss))] fig = plt.figure() plt.plot(x, y_loss) plt.show() #保存完整的预训练模型 torch.save(model,config.save_model_path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
训练完对其进行测试评估,使用准确率:
def test(config, model, test_loader): #模型验证,计算损失和准确率 criterion = nn.BCELoss()# 分类问题 h = model.init_hidden(config.batch_size) with torch.no_grad():#不计算梯度,不进行反向传播,节省资源 count = 0 # 预测的和实际的label相同的样本个数 total = 0 # 累计validation样本个数 loss=0#损失 l=0#损失的计数 for input_test, target_test in test_loader: h = tuple([each.data for each in h]) input_test = input_test.type(torch.LongTensor)#long target_test = target_test.type(torch.LongTensor) target_test = target_test.squeeze(1) input_test = input_test.cuda()#GPU target_test = target_test.cuda() output_test,h = model(input_test,h)#output_test为输出结果,(0,1) pred=output_test.cpu().numpy().tolist()#输出值列表 target=target_test.cpu().numpy().tolist()#目标值列表 for i,j in zip(pred,target): if round(i)==j: count=count+1#正确个数 total += target_test.size(0)#测试样本总数 #损失计算 loss = criterion(output_test, target_test.float()) loss+=loss#自增 l=l+1#计数 acc=100 * count/ total#测试集准确率 test_loss=loss/l#测试集平均损失 print("test mean loss: {:.3f}".format(test_loss)) print("test accuracy : {:.3f}".format(acc))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
模型的使用
训练好的模型就可以直接用来对句子进行预测了。
预测代码:
def predict(config, model, pred_loader): #调用训练好的模型对新句子进行预测,以分好词,编码的形式(调用dataset #model.eval() pred_all=[]#所有结果 with torch.no_grad(): #模型初始化赋值 h = model.init_hidden(config.batch_size_pred)#根据待预测的句子数确定 for dat,id in pred_loader: h = tuple([each.data for each in h]) #dat=torch.Tensor(dat)#列表转张量 dat=dat.cuda()#GPU #print('dat的数据:') #print(dat) output,h= model(dat, h)#输出 #print('output的数据:') #print(output) #pred=output.detach().numpy()#转换数据时不需要保留梯度信息 pred=output.cpu().numpy().tolist()#输出列表[0.521,0.465,...] pred_all=pred_all+pred #最后匹配的时候需要与输入的TXT文件列表做同时循环 return pred_all
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
保存预测结果:
def save_file(config, alls): """保存结果到excel """ f = openpyxl.Workbook() sheet1 = f.create_sheet('sheet1') sheet1['A1'] = 'id' sheet1['B1'] = '评论内容' sheet1['C1'] = '情感值' sheet1['D1'] = '情感类别'# [0,0.5]负向,(0.5,1]正向 i = 2 # openpyxl最小值是1,写入的是xlsx for all in alls: # 遍历每一页 # for data in all:#遍历每一行 for j in range(1, len(all) + 1): # 取每一单元格 # sheet1.write(i,j,all[j])#写入单元格 sheet1.cell(row=i, column=j, value=all[j - 1]) i = i + 1 # 往下一行 f.save(config.save_pred_path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
总结
此次是基于pytorch框架简单地实现了bi-lstm模型进行文本分类,采用sigmoid函数的输出作为情感值是很不合理的,应该叫倾向值,或者不看该数据也是可以的,只关心正负向就行。
后续将继续学习使用预训练词向量进行训练。
自己也是个小白,还得继续学习。
参考博客:
https://blog.csdn.net/qq_52785473/article/details/122800625
https://blog.csdn.net/qq_40276310/article/details/109248949
https://blog.csdn.net/qq_40276310/article/details/109248949
http://t.csdn.cn/qjkST
https://blog.51cto.com/u_11466419/5184189

