
- 1docker上部署mysql
- 2电话机器人、电销、外呼系统与回拨系统:销售业绩飙升的秘诀!_电销系统人工电销
- 3以简单的例子从头开始建spring boot web多模块项目(五)-thymeleaf引擎
- 4如何利用AI智能图片去水印,其实很简单_ai去水印
- 5微信小程序发布新版本后使用时自动提示用户更新或自动更新的方法_微信小程序如何主动提示更新
- 6论文解读 | ACL2024:MARVEL:通过视觉模块插件解锁密集检索的多模态能力
- 7Windows 安装Kafka_kafka-data-viewer怎么使用
- 8Java项目硅谷课堂学习笔记-P7点播模块管理-后台-管理员端_硅谷甄选后台
- 9编辑一段用python编程的收发串口的函数
- 10LLM 大模型学习:LLM训练以及Transformer_llm与transformer
深度学习,NLP和表征(译:小巫)(1)
赞
踩
这似乎并不太令人惊讶。毕竟,性别代词意味着转换一个单词会使句子在语法上不正确。你写道,“she is the aunt”,但“he is the uncle。”类似地,“he is the King”,但“she is the Queen”。如果有人看到“she is the uncle”,最有可能的解释是语法错误。如果有一半的时间是随机转换的话,很有可能发生在这里。
“当然!” 事后我们说:“嵌入这个词将学会以一致的方式编码性别。事实上,可能有一个性别层面。单数和复数也是一样的。很容易找到这些琐碎的关系!”
然而,事实证明,更复杂的关系也是用这种方式编码的。简直是奇迹!
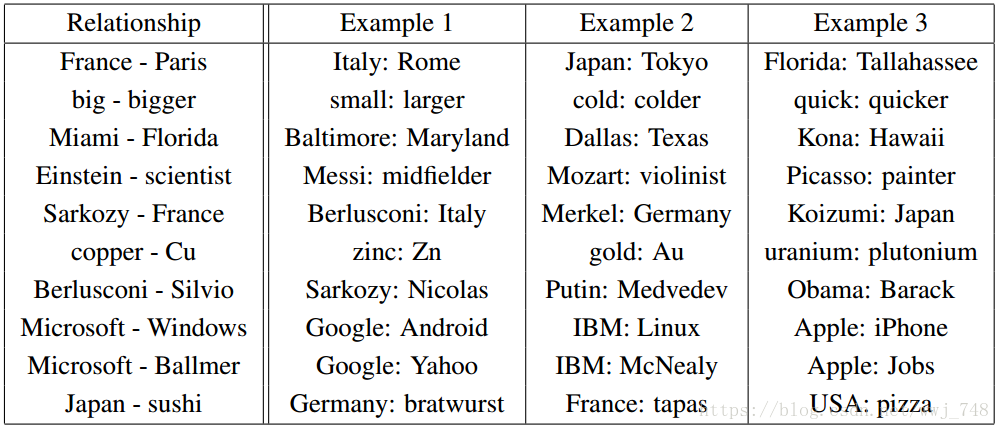
Relationship pairs in a word embedding. From Mikolov et al. (2013b).
认识到 W W W的所有这些性质都是副作用是很重要的。我们并没有试图把相似的词放在一起。我们没有尝试不同的向量进行编码。我们所要做的只是执行一个简单的任务,比如预测一个句子是否有效。这些属性或多或少地出现在优化过程中。
这似乎是神经网络的一大优势:它们学会了更好的自动表示数据的方法。反过来,很好地表示数据似乎是许多机器学习问题成功的关键。词嵌入只是学习表示法的一个特别引人注目的例子。
共享表示
单词嵌入的属性当然是有趣的,但是我们能用它们做一些有用的事情吗?除了预测一些愚蠢的事情,比如5-gram是否“有效”?
我们学习单词嵌入是为了更好地完成一个简单的任务,但是根据我们在单词嵌入中观察到的良好特性,您可能会怀疑它们在NLP任务中通常是有用的。事实上,像这样的单词表示是非常重要的:
近年来,在许多NLP系统的成功中,使用word表示已经成为一种关键的“秘制”,包括命名实体识别、词性标记、解析和语义角色标记。(Luong et al. (2013))
这种通用策略——学习任务A的良好表现,然后将其用于任务B——是深度学习工具箱中的主要技巧之一。根据细节的不同,它有不同的名称:预训练、迁移学习和多任务学习。这种方法最大的优点之一是它允许从多种数据中学习表示。
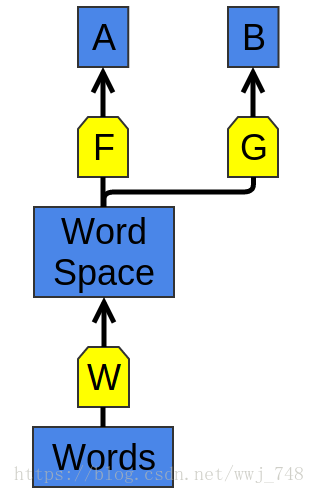
WWW and F F F learn to perform task A. Later, GGG can learn to perform B B B based on WWW.
有一个对应的技巧。我们不需要学习一种方法来表示一种数据并使用它来执行多种任务,我们可以学习一种方法,将多种数据映射到一个单一的表示中!
其中一个很好的例子是在Socher等人(2013a)中制作的双语单词嵌入。我们可以学习在一个单独的共享空间中嵌入两个不同语言的单词。在这种情况下,我们学习在相同的空间中嵌入英语和普通话单词。
我们训练两个单词的嵌入, Wen W e n W_{en} 和 Wzh W z h W_{zh} 的方式类似于我们上面所做的。然而,我们知道某些英语单词和汉语单词有着相似的意思。因此,我们优化了一个附加属性:我们知道的接近翻译的单词应该在一起。

当然,我们注意到我们所知道的词有着相似的意思,最后会紧密结合在一起。因为我们对它进行了优化,所以这并不奇怪。更有趣的是,我们并不知道的单词是最后的翻译。
鉴于我们以前使用词嵌入的经验,这可能并不令人感到意外。单词嵌入将相似的单词拉到一起,所以如果我们知道一个英文和中文单词意味着相似的东西彼此接近,那么它们的同义词也将彼此靠近。我们也知道,像性别差异这样的事物往往最终会以恒定的差异向量来表示。似乎强迫这些不同的向量在英文和中文的嵌入中都是相同的。这样做的结果是,如果我们知道两个男性版本的词语相互转化,我们也应该让女性的词汇相互转化。
直觉上,感觉有点像两种语言有一个相似的“形状”,通过强迫它们在不同的点排列,它们重叠,而其他的点被拉到正确的位置。

t-SNE visualization of the bilingual word embedding. Green is Chinese, Yellow is English. (Socher et al. (2013a))
在双语词语嵌入中,我们学习了两种非常相似类型数据的共享表示。
但是我们也可以学习在相同的空间中嵌入非常不同类型的数据。
最近,深度学习开始探索将图像和单词嵌入到单一表示中的模型。

它的基本思想是,通过在一个单词嵌入中输出一个向量来对图像进行分类。
它的基本思想是,通过在一个单词嵌入输出一个向量来对图像进行分类。狗的图像被绘制在“狗”字向量附近。马的图像被映射到“马”向量附近。汽车的图像在“汽车”向量附近。等等。
有趣的部分是当你在新的图像类别上测试模型时会发生什么。例如,如果模型没有经过训练来分类猫—也就是说,将它们映射到“猫”向量附近—当我们尝试对猫的图像进行分类时会发生什么?

事实证明,网络能够合理处理这些新类别的图像。猫的图像没有被映射到单词嵌入空间中的随机点。相反,它们倾向于映射到“狗”向量的一般附近,并且实际上,接近“猫”向量。类似地,卡车图像与“卡车”向量的距离相对较近,这与“汽车”向量相近。

这是由斯坦福小组的成员完成的,他们只有8个已知类别(和2个未知类别)。结果已经相当令人印象深刻。但是由于已知的类别很少,因此插入图像和语义空间之间的关系的点很少。
谷歌小组做了一个更大的版本—而不是8个类别,他们在同一时间使用1,000个(Frome et al. (2013)),并采用了一个新的变体(Norouzi et al.(2014))。两者均基于非常强大的图像分类模型(from Krizehvsky et al. (2012)),但以不同的方式将图像嵌入词嵌入空间。
结果令人印象深刻。虽然它们可能无法将未知类别的图像转换为表示该类的精确向量,但它们能够到达正确的领域。因此,如果您要求它对未知类别的图像进行分类,并且这些类别是相当不同的,那么它可以区分不同的类别。
尽管我以前从未见过医术的蛇或者犰狳,如果你给我看一张照片和另一张照片,我可以告诉你这是什么,因为我对每种动物的每一个词都有一个大致的概念。这些网络可以完成同样的事情。
(这些结果都利用了一种“这些词是相似的”推理。但基于单词之间的关系,似乎应该有更强的结果。在我们的词嵌入空间中,男性和女性版本的词语之间存在一致的差异向量。同样,在图像空间中,男性和女性之间也有一致的区别特征。胡须,小胡子,和秃头都是男性强烈,高度可见的指标。乳房和不那么可靠的长发、化妆品和珠宝都是女性的明显标志。即使你以前从未见过国王,如果皇后下定决心要成为国王,突然有了胡子,那就很有理由给出男性的版本。)
共享嵌入是一个非常令人兴奋的研究领域,并且强调为什么深度学习的代表性聚焦视角如此引人注目。
递归神经网络
我们从以下网络开始讨论词嵌入的:

Modular Network that learns word embeddings (From Bottou (2011))
上面的图表示一个模块化的网络, R(W(w1), W(w2), W(w3), W(w4), W(w5)) R ( W ( w 1 ) , W ( w 2 ) , W ( w 3 ) , W ( w 4 ) , W ( w 5 ) ) R(W(w_1),~ W(w_2),~ W(w_3),~ W(w_4),~ W(w_5))。它由两个模块组成, W W W和RRR,这种方法,从较小的神经网络“模块”构建神经网络,可以组合在一起,并不是很广泛的传播。然而,它在NLP中非常成功。
像上述这样的模型时强大的,但它们有一个不幸的局限性:它们只能有固定数量的输入。
我们可以通过添加一个关联模块 A A A来克服这个问题,它将使用两个词或短语表示并合并它们。

(From Bottou (2011))
通过合并单词的顺序,AAA把我们从代表单词到表示短语,甚至代表整个句子!因为我们可以合并不同的数量的单词,我们不需要有固定数量的输入。
把一个句子里的单词线性合并并一定有意义。如果有人认为“the cat sat on the mat”,它可以自然会被分成几个部分:“((the cat) (sat(on(the mat))))”。我们可以根据这个括号来应用 A A A:

(From Bottou (2011))
这些模型通常被称为“递归神经网络”,因为人们经常会将模块的输出转换为相同类型的模块。它们有时被称为“树状结构的神经网络”。
递归神经网络在许多NLP任务中都取得了显著的成功。例如,Socher et al. (2013c) 使用递归神经网络来预测句子情感:

(From Socher et al. (2013c))
如果我们能够完成这样的事情,那将是一个非常强大的工具。例如,我们可以尝试制作双语句子表示并将其用于翻译。
不幸的是,这是非常困难的。非常非常困难。考虑到巨大的希望,有很多人在为它工作。
最近,Cho et al. (2014) 在表示短语方面取得了一些进展,有了一种能够对英语短语进行编码并用法语对其进行解码的模型。看看它学习的短语表达!

Small section of the t-SNE of the phrase representation
(From Cho et al. (2014))
批评
–
我已经听过其他领域的研究人员,特别是NLP和语言学领域的研究人员对上述一些结果的批评。关注的不是结果本身,而是从结果中得出的结论,以及它们与其他技术的比较。
我觉得没有资格说出这些问题。我鼓励有这种感觉的人在评论中描述他们所关心的问题。我觉得没有资格说出这些问题。我鼓励有这种感觉的人在评论中描述他们所关心的问题。
结论
–
深度学习的表征视角是一种强有力的观点,似乎可以解释为什么深层神经网络如此有效。除此之外,我认为还有一件非常美妙的事情:为什么神经网络是有效的?因为表示数据的更好方法可以从优化的分层模型中跳出来。
深度学习是一个非常年轻的领域,在这个领域理论还没有得到很好的确立,观点也在迅速变化。话虽如此,但我的印象是,目前神经网络中以表现为中心的观点很受欢迎。
这篇文章回顾了我发现的许多令人兴奋的研究成果,但我的主要动机是为将来的一篇文章创造条件,探索深度学习、类型理论和函数式编程之间的联系。如果您感兴趣,您可以订阅我的RSS提要,以便您在发布时看到它。
(我很高兴听到你的评论和想法:你可以在内联或在结尾发表评论。对于输入错误、技术错误或您希望看到的澄清,我们鼓励您对github发起pull request。)
致谢
–
我感谢Eliana Lorch、Yoshua Bengio、Michael Nielsen、Laura Ball、RobGilson和Jacob Steinhardt的评论和支持。
- 当你有nnn个输入神经元时,为每一个可能的输入构造一个案例需要 2n 2 n 2^n个隐藏的神经元。实际上,情况通常没有那么糟糕。您可以有包含多个输入的情况。您可以将重叠的情况加在一起,以在它们的交集上实现正确的输入。
* (感知器网络不仅具有通用性。sigmoid神经元网络(和其他激活函数)也是通用的:给足够的隐藏神经元,它们可以很好地逼近任意连续函数。看到这一点要困难得多,因为您不能仅仅隔离输入)
- 1
最后
**要想成为高级安卓工程师,必须掌握许多基础的知识。**在工作中,这些原理可以极大的帮助我们理解技术,在面试中,更是可以帮助我们应对大厂面试官的刁难。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-uuQhrtRZ-1714664284885)]
[外链图片转存中…(img-L9PBro10-1714664284885)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


