
- 1JNI中的log日志_jnilog1699437787981.txta
- 2人工智能和机器学习相关的比较活跃的论坛网址列表_人工智能论坛网站
- 3sklearn包中K近邻分类器 KNeighborsClassifier的使用_from sklearn.neighbors import kneighborsclassifier
- 4【demo】用opencv+qt识别人脸与眼睛_qt opencv获取瞳孔
- 5局域网安全17 dot1x
- 6androidStudio配置安装git以及下载项目_android studio从git上下载项目
- 7【Kafka】Kafka的重复消费和消息丢失问题_kafka重复消费
- 8使用STM32芯片ID作为MAC地址_0x1fff7a10
- 9韩国Meetup | Trias,区块链公链底层的一条“高速公路”
- 10如何在自定义数据集上训练YOLOv8的各个模型_yolov8训练示例
基于的Transformer文本情感分析(Keras版)_transformer 情感分析
赞
踩
一、前言
从2017年起,RNN系列网络逐渐被一个叫Transformer的网络替代,发展到现在Transformer已经成为自然语言处理中主流的模型了,而且由Transformer引来了一股大语言模型热潮。从Bert到GPT3,再到如今的ChatGPT。Transformer实现了人类难以想象的功能,而且仍在不停发展。
本文将基于Transformer的Encoder部分,实现文本情感分析任务。
二、数据处理
数据处理可以参考上一篇基于LSTM的文本情感分析(Keras版)的代码,本文使用另一种简单的方法实现。
2.1 数据预览
首先需要下载对应的数据:ai.stanford.edu/~amaas/data…。点击下图位置:

数据解压后得到下面的目录结构:
数据解压后得到下面的目录结构:
- aclImdb
- test
- neg
- pos
- labeledBow.feat
- urls_neg.txt
- urls_pos.txt
- train
- neg
- pos
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这是一个电影影评数据集,neg中包含的评论是评分较低的评论,而pos中包含的是评分较高的评论。我们需要的数据分别是test里面的neg和pos,以及train里面的neg和pos(neg表示negative,pos表示positive)。下面我们开始处理。
2.2 导入模块
在开始写代码之前需要先导入相关模块:
import os
import keras
import tensorflow as tf
from keras import layers
- 1
- 2
- 3
- 4
我的环境是tensorflow2.7,部分版本的tensorflow导入方式不同,可以根据自己环境自行替换。
2.3 读取数据
这里定义一个函数读取评论文件:
def load_data(data_dir=r'/home/zack/Files/datasets/aclImdb/train'): """ data_dir:train的目录或test的目录 输出: X:评论的字符串列表 y:标签列表(0,1) """ classes = ['pos', 'neg'] X, y = [], [] for idx, cls in enumerate(classes): # 拼接某个类别的目录 cls_path = os.path.join(data_dir, cls) for file in os.listdir(cls_path): # 拼接单个文件的目录 file_path = os.path.join(cls_path, file) with open(file_path, encoding='utf-8') as f: X.append(f.read().strip()) y.append(idx) return X, np.array(y)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
上述函数会得到两个列表,便于我们后面处理。
2.4 构建词表及tokenize
前面部分的处理和之前的文章一样,而构建词表和tokenize的操作则用keras的api来实现。代码如下:
X, y = load_data()
vectorization = TextVectorization(max_tokens=vocab_size, output_sequence_length=seq_len)
# 构建词表
vectorization.adapt(X)
# tokenize
X = vectorization(X)
- 1
- 2
- 3
- 4
- 5
- 6
其中adapt方法接收的是句子列表,调用adapt方法后keras会帮我们构建词表,而后用vectorization(X)可以讲句子列表转换成词id列表。
三、构建模型
这里使用Transformer的Encoder部分作为我们网络主干。我们需要实现两个部分,分别是PositionalEmbedding、TransformerEncoder,并将两个部分组成情感分类模型。
3.1 TransformerEncoder
来简单介绍一下Transformer,这里粗略看一下Transformer的各个部件。Transformer结构如下图:
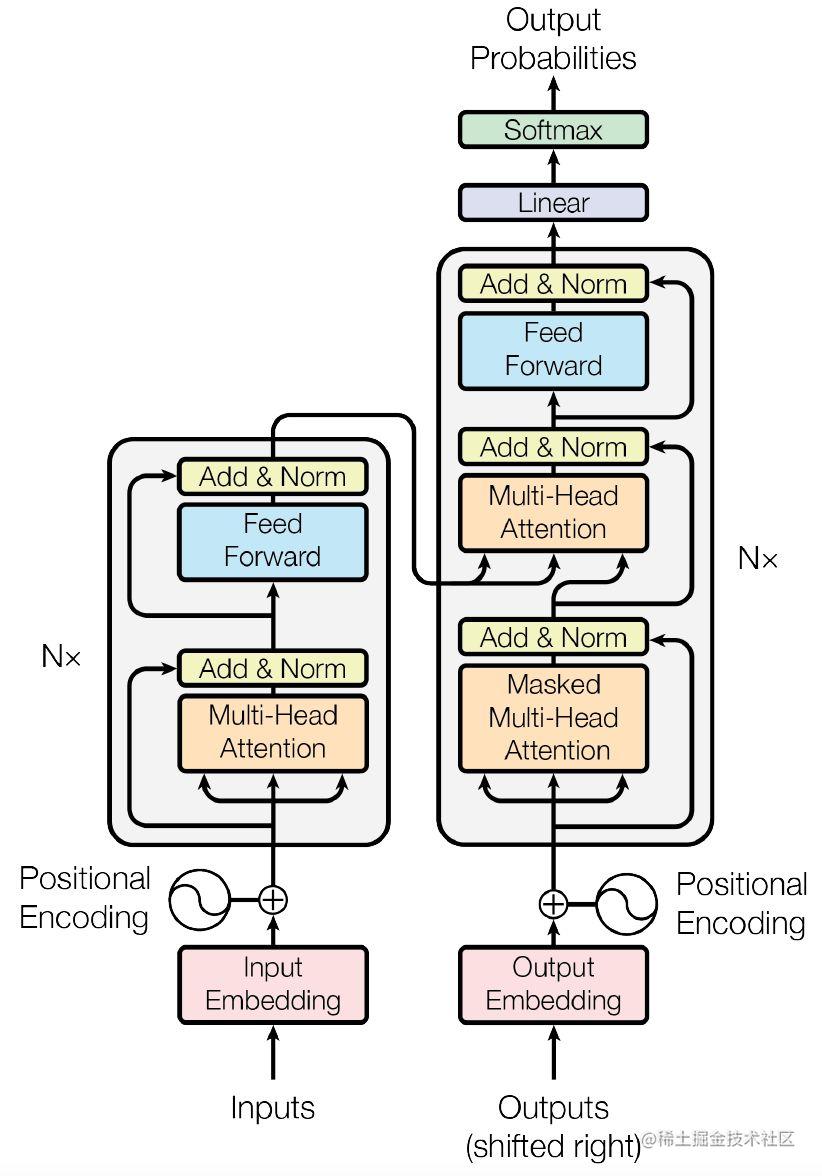
其中左半部分是Encoder,右半部分是Decoder,我们要实现的就是Encoder部分。我们从低向上来看一看Decoder部分。
(1)Input Embedding和Positional Encoding
Transformer的输入是一个id列表,形状为batch_size × sequence_len,输入首先会经过一个简单的Embedding层(Input Embedding)得到一个形状为batch_size × sequence_len × embed_dim,我们称为te。te里面包含了sequence_len个词的嵌入,其中te的第一个嵌入会与向量pe[0]相加,te的第二个嵌入会与向量t[1]相加,依次类推。
因此pe的形状应该为sequence_len × embed_dim,pe里面就包含了位置信息。在原始论文中pe有固定公式获得,位置信息固定后pe就固定了,而本文在实现时用一个叫Positional Embedding方式替代它,实现代码如下:
class PositionalEmbedding(layers.Layer):
def __init__(self, input_size, seq_len, embed_dim):
super(PositionalEmbedding, self).__init__()
self.seq_len = seq_len
# 词嵌入
self.tokens_embedding = layers.Embedding(input_size, embed_dim)
# 位置嵌入
self.positions_embedding = layers.Embedding(seq_len, embed_dim)
def call(self, inputs, *args, **kwargs):
# 生成位置id
positions = tf.range(0, self.seq_len, dtype='int32')
te = self.tokens_embedding(inputs)
pe = self.positions_embedding(positions)
return te + pe
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这里使用了和词嵌入类似的思想,让网络自己学习位置信息。
(2)Multi-Head Attention
Multi-Head Attention可以认为是对一个序列做了多次Self-Attention,然后把每次Self-Attention的结构拼接起来。在Keras和Pytorch中都有对应的实现,这里我们看看应该如何使用。
在创建MultiHeadAttention层时,需要指定头的数量以及key的维数,在正向传播时,如果传入两个相同的序列那么就是在做Self-Attention,代码如下:
from keras import layers
import tensorflow as tf
# 形状为batch_size × sequence_len × embed_dim
X = tf.random.uniform((3, 10, 5))
mta = layers.MultiHeadAttention(4, 10)
out = mta(X, X)
# 输出:(3, 10, 5)
print(out.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
从代码可以看出MultiHeadAttention的输入与输出形状一致。
(3)Add & Norm
在经过Attention后,我们把Attention的输入和Attention的输出都放入了一个叫Add & Norm的模块中。这里其实就是把两者相加,而后经过LayerNormalization,其结构如下图:
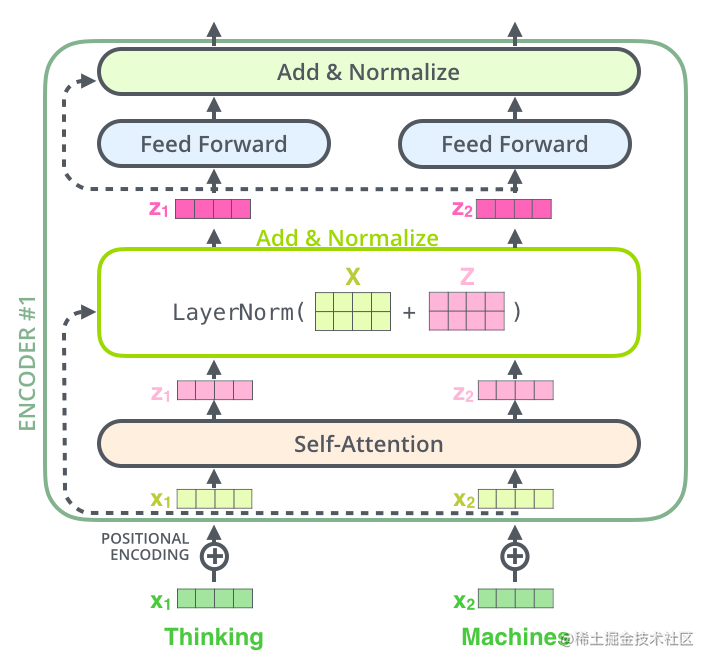
把词嵌入x1、x2输入Attention得到z1、z2,然后把x1、x2组成矩阵X,z1、z2组成矩阵Z,计算LayerNorm(X+Z),输入下一层,代码实现如下:
# 定义层
mta = layers.MultiHeadAttention(4, 10)
ln = layers.LayerNormalization()
# 正向传播
X = tf.random.uniform((3, 10, 5))
Z = mta(X, X)
out = ln(X+Z)
# 输出 (3, 10, 5)
print(out.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(4)Feed Forward
Feed Forward就是简单的全连接层,不过这里是对单个向量进行全连接,即z1-zn每个向量都单独经过Linear层。另外Feed Forward层有两层全连接,先放大再缩小,代码如下:
import keras from keras import layers import tensorflow as tf mta = layers.MultiHeadAttention(4, 10) ln = layers.LayerNormalization() # Feed Forward层 ff = keras.Sequential([ layers.Dense(10, activation='relu'), layers.Dense(5) ]) X = tf.random.uniform((3, 10, 5)) Z = mta(X, X) Z = ln(X+Z) out = ff(Z) # 输出 (3, 10, 5) print(out.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
到此我们就把Encoder的各个部件说明了。下面来实现TransformerEncoder层。
3.2 Encoder的实现
现在我们把上面各个部分写成一个TransformerEncoder类,这里不包含PositionalEmbedding,代码如下:
class TransformerEncoder(layers.Layer): def __init__(self, embed_dim, hidden_dim, num_heads, **kwargs): super(TransformerEncoder, self).__init__(**kwargs) # Multi-Head Attention层 self.attention = layers.MultiHeadAttention( num_heads=num_heads, key_dim=embed_dim ) # Feed Forward层 self.feed_forward = keras.Sequential([ layers.Dense(hidden_dim, activation='relu'), layers.Dense(embed_dim) ]) # layernorm层 self.layernorm1 = layers.LayerNormalization() self.layernorm2 = layers.LayerNormalization() def call(self, inputs, *args, **kwargs): # 计算Self-Attention attention_output = self.attention(inputs, inputs) # 进行第一个Layer & Norm ff_input = self.layernorm1(inputs + attention_output) # Feed Forward ff_output = self.feed_forward(ff_input) # 进行第二个Layer & Norm outputs = self.layernorm2(ff_input + ff_output) return outputs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
现在我们实现的这个TransformerEncoder它接收一个batch_size × sequence_len × embed_dim的张量,输出一个形状一样的张量。如果要用于情感分析,我们可以在输出后面拼接全局平均池化和全连接层。
3.3 分类模型
下面我们使用前面的PositionalEmbedding和TransformerEncoder实现我们的文本分类网络,代码如下:
# 超参数 vocab_size = 20000 seq_len = 180 batch_size = 64 hidden_size = 1024 embed_dim = 256 num_heads = 8 # 加载数据 X_train, y_train = load_data() X_test, y_test = load_data(r'/home/zack/Files/datasets/aclImdb/test') vectorization = layers.TextVectorization( max_tokens=vocab_size, output_sequence_length=seq_len, pad_to_max_tokens=True ) vectorization.adapt(X_train) X_train = vectorization(X_train) X_test = vectorization(X_test) # 构建模型 inputs = layers.Input(shape=(seq_len,)) x = PositionalEmbedding(vocab_size, seq_len, embed_dim)(inputs) x = TransformerEncoder(embed_dim, hidden_size, num_heads)(x) x = layers.GlobalAveragePooling1D()(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(1, activation='sigmoid')(x) model = keras.Model(inputs, outputs) # 训练 model.compile(loss='binary_crossentropy', metrics=['accuracy']) model.fit( X_train, y_train, epochs=20, batch_size=batch_size, validation_data=[X_test, y_test] )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
最终训练后在测试集上准确率在85%左右。

