
- 11.用户画像:方法论与工程化解决方案 --- 用户画像基础_用户画像 方法论与工程化解决方案
- 2华为2288H V5服务器RAID配置_avago megaraid配置raid
- 3基于门控的循环神经网络:LSTM_门控 lstm
- 4使用Ollama+OpenWebUI本地部署阿里通义千问Qwen2 AI大模型
- 5TCP协议详解及实战解析【精心整理收藏】_网络协议分析与运维实战
- 6数据结构:二叉树(带图详解)_二叉树的深度和高度图解
- 7Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS_sparkml 推荐
- 8一站式体验重磅智能化场景与产品,英特尔GTC科技体验中心开幕
- 9linux 内核优化_tcp acked lost segment
- 10vscode 拉取代码失败_vscode无法拉取最新git分支代码
深入理解AI芯片的核心技术
赞
踩
Nvidia的AI芯片路线图分析与解读
在2023年10月的投资者会议上,Nvidia展示了其全新的GPU发展蓝图 [1]。与以往两年一次的更新节奏不同,这次的路线图将演进周期缩短至一年。预计在2024年,Nvidia将推出H200和B100 GPU;到2025年,X100 GPU也将面世。其AI芯片规划的战略核心是“One Architecture”统一架构,支持在任何地方进行模型训练和部署,无论是数据中心还是边缘设备,无论是x86架构还是Arm架构。其解决方案适用于超大规模数据中心的训练任务,也可以满足企业级用户的边缘计算需求。AI芯片从两年一次的更新周期转变为一年一次的更新周期,反映了其产品开发速度的加快和对市场变化的快速响应。其AI芯片布局涵盖了训练和推理两个人工智能关键应用,训练推理融合,并侧重推理。同时支持x86和Arm两种不同硬件生态。在市场定位方面,同时面向超大规模云计算和企业级用户,以满足不同需求。Nvidia旨在通过统一的架构、广泛的硬件支持、快速的产品更新周期以及面向不同市场提供全面的差异化的AI解决方案,从而在人工智能领域保持技术和市场的领先地位。Nvidia是一个同时拥有 GPU、CPU和DPU的计算芯片和系统公司。Nvidia通过NVLink、NVSwitch和NVLink C2C技术将CPU、GPU进行灵活连接组合形成统一的硬件架构,并于CUDA一起形成完整的软硬件生态。
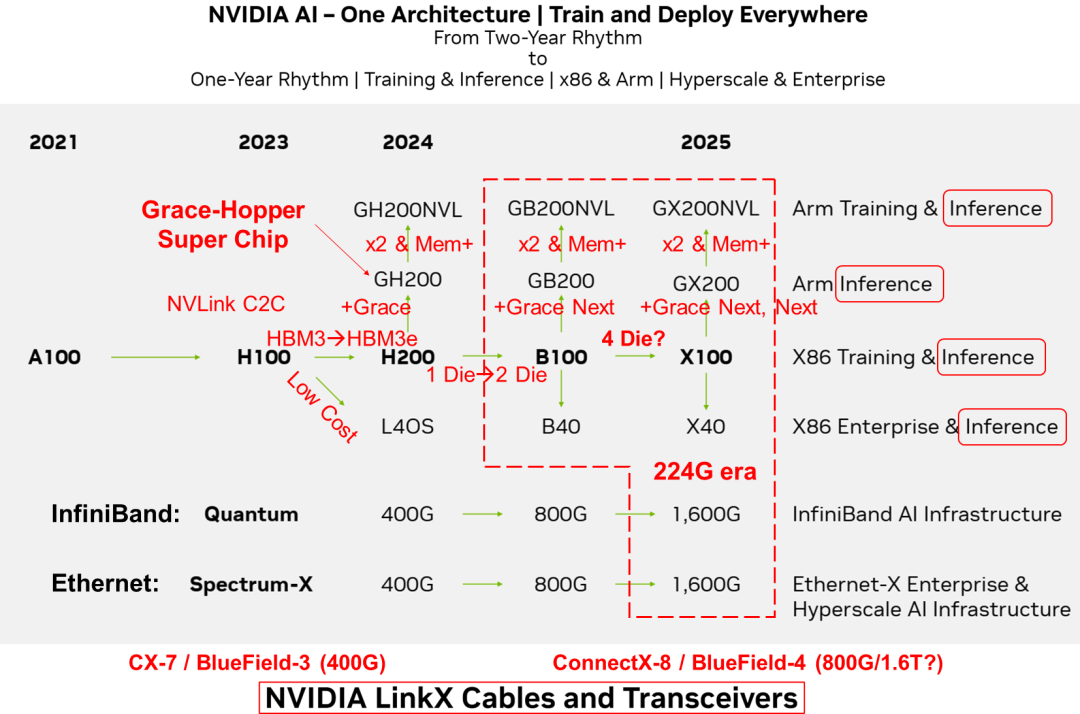
在AI计算芯片架构方面,注重训练和推理功能的整合,侧重推理。围绕GPU打造ARM和X86两条技术路线。在Nvidia的AI路线图中,并没有显示提及Grace CPU的技术路线,而是将其纳入Grace+GPU的SuperChip超级芯片路标中。
Nvidia Grace CPU会跟随GPU的演进节奏并与其组合成新一代超级芯片;而其自身也可能根据市场竞争的需求组合成CPU超级芯片,实现“二打一”的差异化竞争力。从需求角度来看,CPU的技术演进速度并不像GPU那样紧迫,并且CPU对于成本更加敏感。CPU只需按照“摩尔”或“系统摩尔”,以每两年性能翻倍的速度进行演进即可。而GPU算力需要不到一年就要实现性能翻倍,保持每年大约2.5倍的速率增长。这种差异催生了超级芯片和超节点的出现。
Nvidia将延用SuperChip超级芯片架构,NVLink-C2C和NVLink互联技术在Nvidia未来的AI芯片架构中将持续发挥关键作用。其利用NVLink-C2C互联技术构建GH200、GB200和GX200超级芯片。更进一步,通过NVLink互联技术,两颗GH200、GB200和GX200可以背靠背连接,形成GH200NVL、GB200NVL和GX200NVL模组。Nvidia可以通过NVLink网络组成超节点,通过InfiniBand或Ethernet网络组成更大规模的AI集群。
在交换芯片方面,仍然坚持InfiniBand和Ethernet两条开放路线,瞄准不同市场,前者瞄准AI Factory,后者瞄准AIGC Cloud。但其并未给出NVLink和NVSwitch自有生态的明确计划。224G代际的速度提升,可能率先NVLink和NVSwitch上落地。以InfiniBand为基础的Quantum系列和以Ethernet基础的Spectrum-X系列持续升级。预计到2024年,将商用基于100G SerDes的800G接口的交换芯片;而到2025年,将迎来基于200G SerDes的1.6T接口的交换芯片。其中800G对应51.2T交换容量的Spectrum-4芯片,而1.6T则对应下一代Spectrum-5,其交换容量可能高达102.4T。从演进速度上看,224G代际略有提速,但从长时间周期上看,其仍然遵循着SerDes速率大约3到4年翻倍、交换芯片容量大约2年翻倍的规律。虽然有提到2024年Quantum将会升级到800G,但目前我们只能看到2021年发布的基于7nm工艺,400G接口的25.6T Quantum-2交换芯片。路线图中并未包含NVSwitch 4.0和NVLink 5.0的相关计划。有预测指出Nvidia可能会首先在NVSwitch和NVLink中应用224G SerDes技术。NVLink和NVSwitch作为Nvidia自有生态,不会受到标准生态的掣肘,在推出时间和技术路线选择上更灵活,从而实现差异化竞争力。
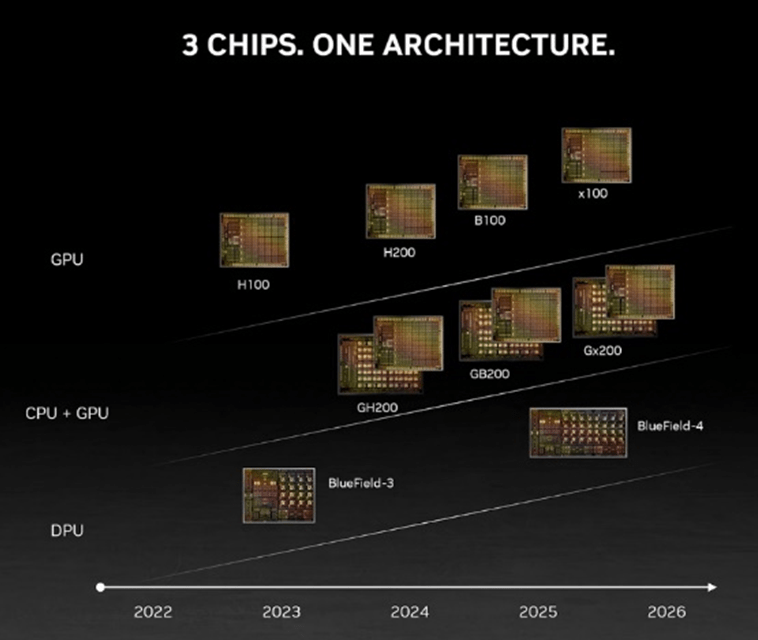
SmartNIC智能网卡/DPU数据处理引擎的下一跳ConnectX-8/BlueField-4目标速率为 800G,与1.6T Quantum和Spectrum-X配套的SmartNIC和DPU的路标仍不明晰,NVLink5.0和NVSwitch4.0可能提前发力。Nvidia ConnectX系列SmartNIC智能网卡与InfiniBand技术相结合,可以在基于NVLink网络的超节点基础上构建更大规模的AI集群。而BlueField DPU则主要面向云数据中心场景,与Ethernet技术结合,提供更强大的网络基础设施能力。相较于NVLink总线域网络,InfiniBand和Ethernet属于传统网络技术,两种网络带宽比例大约为1比9。例如,H00 GPU用于连接SmartNIC和DPU的PCIE带宽为128GB/s,考虑到PCIE到Ethernet的转换,其最大可以支持400G InfiniBand或者Ethernet接口,而NVLink双向带宽为900GB/s或者3.6Tbps,因此传统网络和总线域网络的带宽比为1比9。虽然SmartNIC和DPU的速率增长需求没有总线域网络的增速快,但它们与大容量交换芯片需要保持同步的演进速度。它们也受到由IBTA (InfiniBand) 和IEEE802.3 (Ethernet) 定义互通标准的产业生态成熟度的制约。
互联技术在未来的计算系统的扩展中起到至关重要的作用。Nvidia同步布局的还有LinkX系列光电互联技术。包括传统带oDSP引擎的可插拔光互联 (Pluggable Optics),线性直驱光互联LPO (Linear Pluggable Optics),传统DAC电缆、重驱动电缆 (Redrived Active Copper Cable)、芯片出光 (Co-Packaged Optics) 等一系列光电互联技术。随着超节点和集群网络的规模不断扩大,互联技术将在未来的AI计算系统中发挥至关重要的作用,需要解决带宽、时延、功耗、可靠性、成本等一系列难题。
对Nvidia而言,来自Google、Meta、AMD、Microsoft和Amazon等公司的竞争压力正在加大。这些公司在软件和硬件方面都在积极发展,试图挑战Nvidia在该领域的主导地位,这或许是Nvidia提出相对激进技术路线图的原因。Nvidia为了保持其市场地位和利润率,采取了一种大胆且风险重重的多管齐下的策略。他们的目标是超越传统的竞争对手如Intel和AMD,成为科技巨头,与Google、Microsoft、Amazon、Meta和Apple等公司并驾齐驱。Nvidia的计划包括推出H200、B100和“X100”GPU,以及进行每年度更新的AI GPU。此外,他们还计划推出HBM3E高速存储器、PCIE 6.0和PCIE 7.0、以及NVLink、224G SerDes、1.6T接口等先进技术,如果计划成功,Nvidia将超越所有潜在的竞争对手 [2]。
尽管硬件和芯片领域的创新不断突破,但其发展仍然受到第一性原理的限制,存在天然物理边界的约束。通过深入了解工艺制程、先进封装、内存和互联等多个技术路线,可以推断出未来Nvidia可能采用的技术路径。尽管基于第一性原理的推演成功率高,但仍需考虑非技术因素的影响。例如,通过供应链控制,在一定时间内垄断核心部件或技术的产能,如HBM、TSMC CoWoS先进封装工艺等,可以影响技术演进的节奏。根据Nvidia 2023年Q4财报,该公司季度收入达到76.4亿美元,同比增长53%,创下历史新高。全年收入更是增长61%,达到269.1亿美元的纪录。数据中心业务在第四季度贡献了32.6亿美元的收入,同比增长71%,环比增长11%。财年全年数据中心收入增长58%,达到创纪录的106.1亿美元 [3]。因此Nvidia拥有足够大的现金流可以在短时间内对供应链,甚至产业链施加影响。另外,也存在一些黑天鹅事件也可能产生影响,比如以色列和哈马斯的战争就导致了Nvidia取消了原定于10月15日和16日举行的AI SUMMIT [4]。业界原本预期,Nvidia将于峰会中展示下一代B100 GPU芯片 [5]。值得注意的是,Nvidia的网络部门前身Mellanox正位于以色列。
为了避免陷入不可知论,本文的分析主要基于物理规律的第一性原理,而不考虑经济手段(例如控制供应链)和其他可能出现的黑天鹅事件(例如战争)等不确定性因素。当然,这些因素有可能在技术链条的某个环节产生重大影响,导致技术或者产品演进节奏的放缓,或者导致整个技术体系进行一定的微调,但不会对整个技术演进趋势产生颠覆式的影响。考虑到这些潜在的变化,本文的分析将尽量采取一种客观且全面的方式来评估这些可能的技术路径。我们将以“如果 A 那么 X;如果 B 那么 Y;…”的形式进行思考和分析,旨在涵盖所有可能影响技术发展的因素,以便提供更准确、更全面的分析结果。此外,本文分析是基于两到三年各个关键技术的路标假设,即2025年之前。当相应的前提条件变化,相应的结论也应该作适当的调整,但是整体的分析思路是普适的。
Nvidia的AI布局
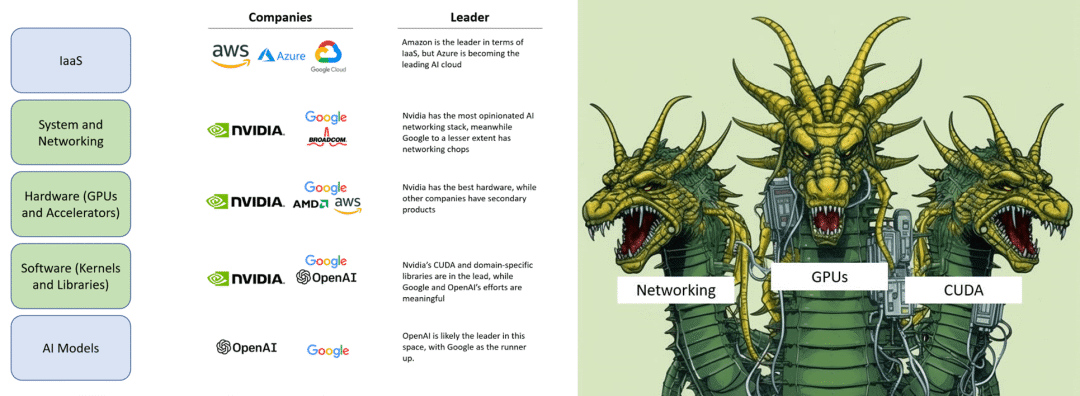
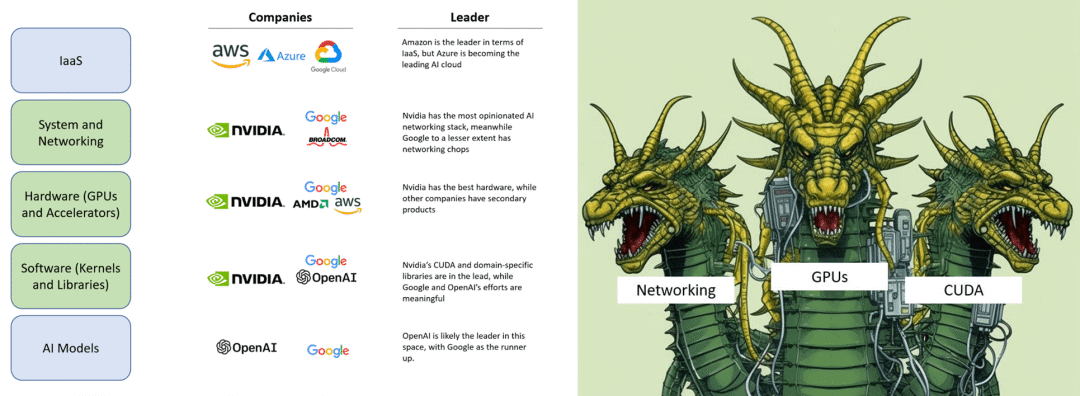
Nvidia在人工智能领域的布局堪称全面,其以系统和网络、硬件和软件为三大支柱,构建起了深厚的技术护城河 [6]。有分析称Nvidia的H100显卡有高达90%的毛利率。Nvidia通过扶持像Coreweave这样的GPU云服务商,利用供货合同让他们从银行获取资金,然后购买更多的H100显卡,锁定未来的显卡需求量。这种模式已经超出传统硬件公司的商业模式,套用马克思在资本论中所述“金银天然不是货币,货币天然是金银。”,有人提出了“货币天然不是H100,但H100天然是货币”的说法 [7]。这一切的背后在于对于对未来奇点临近的预期 [8],在于旺盛的需求,同时更在于其深厚的技术护城河。
Nvidia 2019年3月发起对Mellanox的收购 [9],并且于2020年4月完成收购 [10],经过这次收购Nvidia获取了InfiniBand、Ethernet、SmartNIC、DPU及LinkX互联的能力。面向GPU互联,自研NVLink互联和NVLink网络来实现GPU算力Scale Up扩展,相比于基于InfiniBand网络和基于Ethernet的RoCE网络形成差异化竞争力。NVLink自2014年推出以来,已经历了四个代际的演进,从最初的2014年20G NVLink 1.0,2018年25G NVLink2.0,2020年50G NVLink 3.0 到2022年的100G NVLink 4.0,预计到2024年,NVLink将进一步发展至200G NVLink 5.0。在应用场景上,NVLink 1.0至3.0主要针对PCIE板内和机框内互联的需求,通过SerDes提速在与PCIE互联的竞争中获取显著的带宽优势。值得注意的是,除了NVLink1.0采用了20G特殊速率点以外,NVLink2.0~4.0皆采用了与Ethernet相同或者相近的频点,这样做的好处是可以复用成熟的Ethernet互联生态,也为未来实现连接盒子或机框组成超节点埋下伏笔。NVSwitch 1.0、2.0、3.0分别与NVLink2.0、3.0、4.0配合,形成了NVLink总线域网络的基础。NVLink4.0配合NVSwitch3.0组成了超节点网络的基础,这一变化的外部特征是NVSwitch脱离计算单板而单独成为网络设备,而NVLink则从板级互联技术升级成为设备间互联技术。
在计算芯片领域,Nvidia于2020年9月发起ARM收购,期望构建人工智能时代顶级的计算公司 [11],这一收购提案因为面临重大监管挑战阻碍了交易的进行,于2022年2月终止 [12]。但是,在同年3月其发布了基于ARM的Grace CPU Superchip超级芯片 [13]。成为同时拥有CPU、GPU和DPU的计算芯片和系统公司。
从业务视角看,Nvidia在系统和网络、硬件、软件三个方面占据了主导地位 [6]。系统和网络、硬件、软件这三个方面是人工智能价值链中许多大型参与者无法有效或快速复制的重要部分,这意味着Nvidia在整个生态系统中占据着主导地位。要击败Nvidia就像攻击一个多头蛇怪。必须同时切断所有三个头才有可能有机会,因为它的每个“头”都已经是各自领域的领导者,并且Nvidia正在努力改进和扩大其护城河。在一批人工智能硬件挑战者的失败中,可以看到,他们都提供了一种与Nvidia GPU相当或略好的硬件,但未能提供支持该硬件的软件生态和解决可扩展问题的方案。而Nvidia成功地做到了这一切,并成功抵挡住了一次冲击。这就是为什么Nvidia的战略像是一个三头水蛇怪,后来者必须同时击败他们在系统和网络、硬件以及软件方面的技术和生态护城河。目前,进入Nvidia平台似乎能够占据先机。OpenAI、微软和Nvidia显然处于领先地位。尽管Google和Amazon也在努力建立自己的生态系统,但Nvidia提供了更完整的硬件、软件和系统解决方案,使其成为最具吸引力的选择。要赢得先机,就必须进入其硬件、软件和系统级业务生态。然而,这也意味着进一步被锁定,未来更难撼动其地位。从Google和Amazon等公司的角度来看,如果不选择接入Nvidia的生态系统,可能会失去先机;而如果选择接入,则可能意味着失去未来。
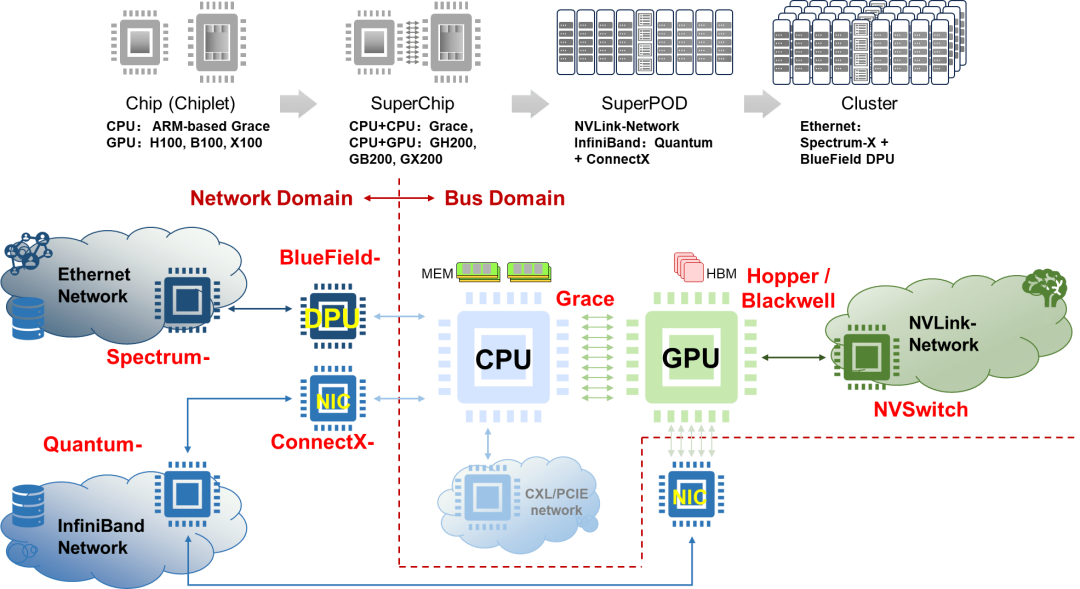
Nvidia布局了两种类型网络,一种是传统InfiniBand和Ethernet网络,另一种是NVLink总线域网络。在传统网络中,Ethernet面向AIGC Cloud多AI训练和推理等云服务,而InfiniBand面向AI Factory,满足大模型训练和推理的应用需求。在交换芯片布局方面,有基于开放Ethernet增强的Spectrum-X交换芯片和基于InfiniBand的封闭高性能的Quantum交换芯片。当前Ultra Ethernet Consortium (UEC) 正在尝试定义基于Ethernet的开放、互操作、高性能的全栈架构,以满足不断增长的AI和HPC网络需求 [14],旨在与Nvidia的网络技术相抗衡。UEC的目标是构建一个类似于InfiniBand的开放协议生态,从技术层面可以理解为将Ethernet进行增强以达到InfiniBand网络的性能,或者说是实现一种InfiniBand化的Ethernet。从某种意义上说UEC在重走InfiniBand道路。总线域网络NVLink的主要特征是要在超节点范围内实现内存语义级通信和总线域网络内部的内存共享,它本质上是一个Load-Store网络,是传统总线网络规模扩大以后的自然演进。从NVLink接口的演进历程可以看出,其1.0~3.0版本明显是对标PCIE的,而4.0版本实际上对标InfiniBand和Ethernet的应用场景,但其主要目标还是实现GPU的Scale Up扩展。
从原始需求的角度来看,NVLink网络在演进过程中需要引入传统网络的一些基本能力,例如编址寻址、路由、均衡、调度、拥塞控制、管理控制和测量等。同时,NVLink还需要保留总线网络基本特征,如低时延、高可靠性、内存统一编址共享以及内存语义通信。这些特征是当前InfiniBand或Ethernet网络所不具备的或者说欠缺的。与InfiniBand和Ethernet传统网络相比,NVLink总线域网络的功能定位和设计理念存在着本质上的区别。我们很难说NVLink网络和传统InfiniBand网络或者增强Ethernet网络最终会殊途同归。
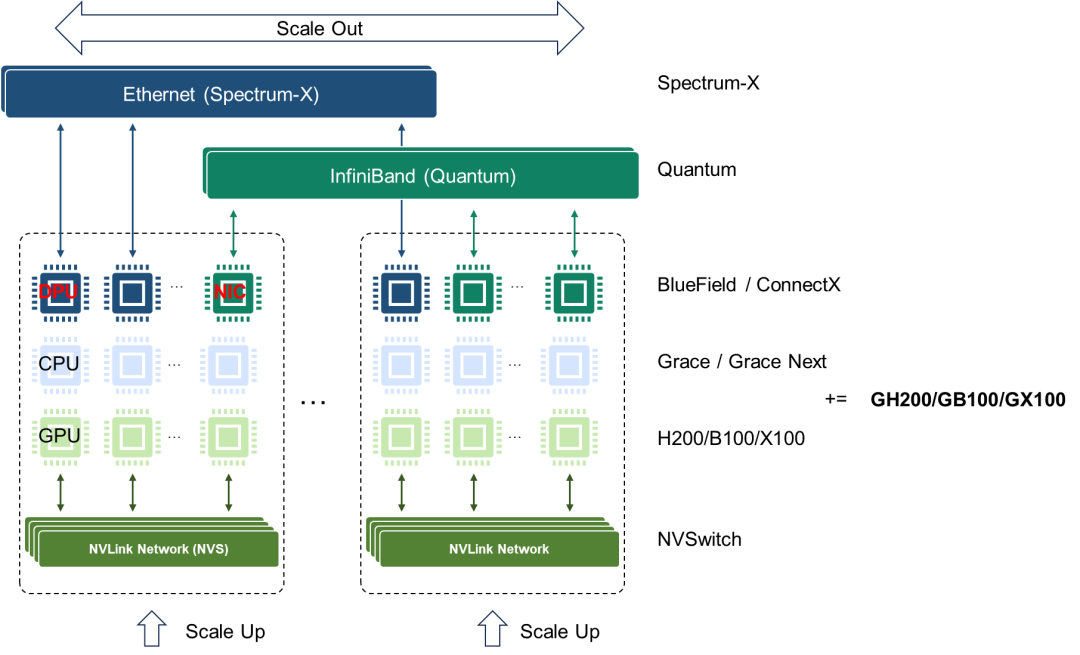
Nvidia在AI集群竞争态势中展现出了全面布局,涵盖了计算(芯片、超级芯片)和网络(超节点、集群)领域。在计算芯片方面,Nvidia拥有CPU、GPU、CPU-CPU/CPU-GPU SuperChip等全面的布局;在超节点网络层面,Nvidia提供了NVLink和InfiniBand两种定制化网络选项;在集群网络方面,Nvidia有基于Ethernet的交换芯片和DPU芯片布局。AMD紧随其后,更专注于CPU和GPU计算芯片,并采用基于先进封装的Chiplet芯粒技术。与Nvidia不同的是,AMD当前没有超级芯片的概念,而是采用了先进封装将CPU和GPU Die合封在一起。AMD使用私有的Infinity Fabric Link内存一致接口进行GPU、CPU、GPU和CPU间的互联,而GPU和CPU之间的互联仍然保留传统的PCIE连接方式。此外,AMD计划推出XSwitch交换芯片,下一代MI450加速器将利用新的互连结构,其目的显然是与Nvidia的NVSwitch竞争 [15]。BRCM则专注于网络领域,在超节点网络有对标InfiniBand的Jericho3-AI+Ramon的DDC方案;在集群网络领域有基于Ethernet的Tomahawk系列和Trident系列交换芯片。近期BRCM推出其新的软件可编程交换Trident 5-X12集成了NetGNT神经网络引擎实时识别网络流量信息,并调用拥塞控制技术来避免网络性能下降,提高网络效率和性能 [16]。Cerebras/Telsa Dojo则“剑走偏锋”,走依赖“晶圆级先进封装”的深度定制硬件路线。
工程工艺洞察和推演假设
半导体工艺演进洞察
根据IRDS的乐观预测,未来5年,逻辑器件的制造工艺仍将快速演进,2025年会初步实现Logic器件的3D集成。TSMC和Samsung将在2025年左右开始量产基于GAA (MBCFET)的2nm和3nm制程的产品 [17]。
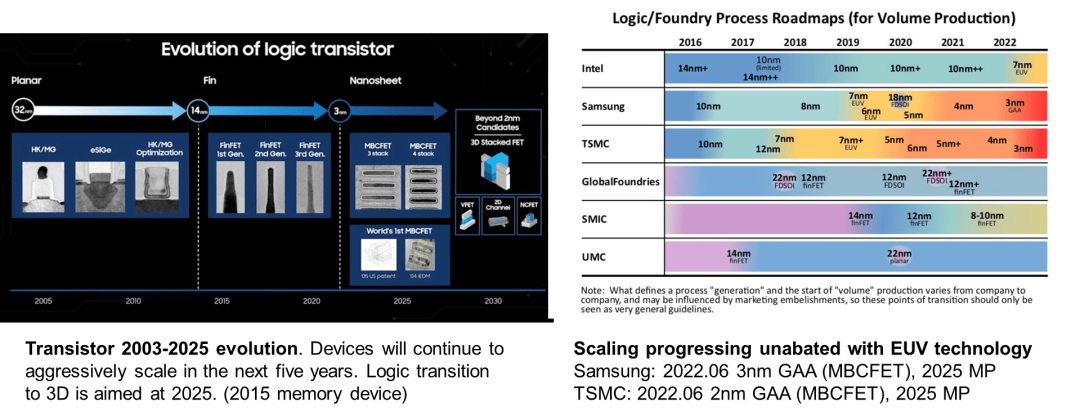
按照TSMC给出的工艺演进路标,2023~2025年基本以3nm工艺为主,2nm工艺在2025年以后才会发布。3nm技术已经进入量产阶段,N3工艺和N3E版本已经于2023年推出。2024年下半年开始生产N3P版本,该版本将提供比N3E更高的速度、更低的功耗和更高的芯片密度。此外,N3X版本将专注于高性能计算应用,提供更高的时钟频率和性能,预计将于2025年开始量产 [18]。工艺演进的收益对于逻辑器件的收益小于50%,因此,未来单芯片算力提升将更依赖于先进封装技术。
先进封装演进洞察
TSMC的CoWoS先进封装工艺封装基板的尺寸在2023年为4倍Reticle面积,2025年将达到6倍Reticle面积 [19]。当前Nvidia H100 GPU的封装基板尺寸小于2倍Reticle面积,AMD的MI300系列GPU的封装基板尺寸大约为3.5倍Reticle面积,逼近当前TSMC CoWoS-L工艺的极限。
HBM内存演进洞察
HBM内存的容量预计将在2024年达到24GB,并在2025年进一步增长至36GB [20]。HBM4预计将带来两个重要的变化:首先,HBM接口位宽将从1024扩展到2048;其次,业界正在尝试将HBM内存Die直接堆叠在逻辑Die的上方 [21][22]。这两个变化意味着HBM内存的带宽和单个封装内能容纳的容量都将持续增长。
据报道,SK海力士已经开始招聘CPU和GPU等逻辑半导体的设计人员。该公司显然正在考虑将HBM4直接堆叠在处理器上,这不仅会改变逻辑和存储器设备的传统互连方式,还会改变它们的制造方式。事实上,如果SK海力士成功实现这一目标,这可能会彻底改变芯片代工行业 [21][22]。
推演假设
本文基于两个前提假设来推演Nvidia未来AI芯片的架构演进。首先,每一代AI芯片的存储、计算和互联比例保持大致一致,且比上一代提升1.5到2倍以上;其次,工程工艺演进是渐进且可预测的,不存在跳变,至少在2025年之前不会发生跳变。到2025年,工艺将保持在3nm水平,但工艺演进给逻辑器件带来的收益预计不会超过50%。同时,先进封装技术预计将在2025年达到6倍 Reticle面积的水平。此外,HBM内存容量也将继续增长,预计在2024年将达到24GB,而在2025年将达到36GB。
Nvidia AI芯片架构解读
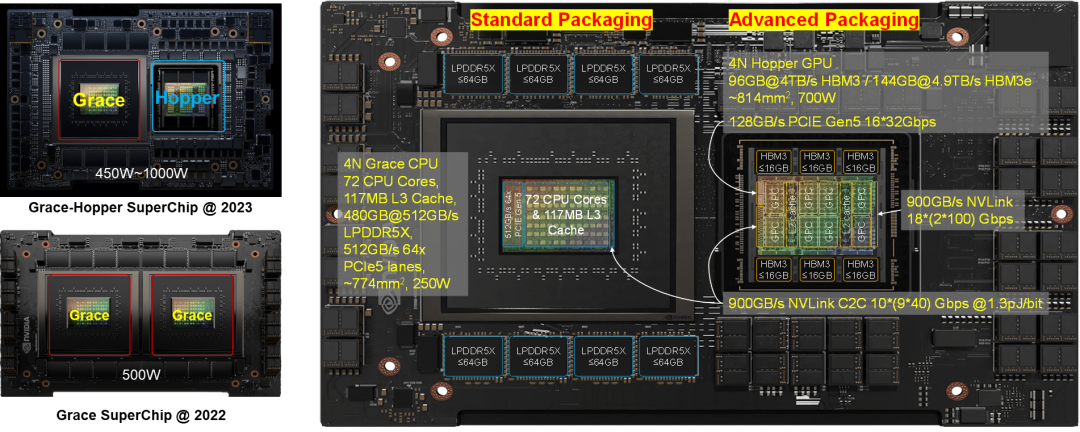
互联技术在很大程度上决定了芯片和系统的物理架构。Nvidia利用NVLink-C2C这种低时延、高密度、低成本的互联技术来构建SuperChip超级芯片,旨在兼顾性能和成本打造差异化竞争力。与传统的SerDes互联相比,NVLink C2C采用了高密度单端架构和NRZ调制,使其在实现相同互联带宽时能够在时延、功耗、面积等方面达到最佳平衡点;而与Chiplet Die-to-Die互联相比,NVLink C2C具备更强的驱动能力,并支持独立封装芯片间的互联,因此可以使用标准封装,满足某些芯片的低成本需求。
为了确保CPU和GPU之间的内存一致性操作 (Cache-Coherency),对于NVLink C2C接口有极低时延的要求。H100 GPU的左侧需要同时支持NVLink C2C和PCIE接口,前者H100 GPU的左侧需要同时支持NVLink C2C和PCIE接口,前者用于实现与Nvidia自研Grace CPU组成Grace-Hopper SuperChip,后者用于实现与PCIE交换芯片、第三方CPU、DPU、SmartNIC对接。NVLink C2C的互联带宽为900GB/s,PCIE互联带宽为128GB/s。而当Hopper GPU与Grace CPU组成SuperChip时,需要支持封装级的互联。值得注意的是,Grace CPU之间也可以通过NVLink C2C互联组成Grace CPU SuperChip。考虑到成本因素,Nvidia没有选择采用双Die合封的方式组成Grace CPU,而是通过封装间的C2C互联组成SuperChip超级芯片。
从时延角度来看,NVLink C2C采用40Gbps NRZ调制,可以实现无误码运行 (BER<1e-12),免除FEC,接口时延可以做到小于5ns。相比之下,112G DSP架构的SerDes本身时延可以高达20ns,因为采用了PAM4调制,因此还需要引入FEC,这会额外增加百纳秒量级的时延。此外,NVLink C2C采用了独立的时钟线来传递时钟信号,因此数据线上的信号不需要维持通信信号直流均衡的编码或扰码,可以进一步将时延降低到极致。因此,引入NVLink C2C的主要动机是满足芯片间低时延互联需求。
从互联密度来看,当前112G SerDes的边密度可以达到12.8Tbps每边长,远远大于当前H100的(900+128)GB/s * 8/2 = 4.112Tbps的边密度需求。NVLink C2C的面密度是SerDes的3到4倍,(169Gbps/mm2 vs. 552Gbps/mm2)。而当前NVLink C2C的边密度还略低于SerDes (281Gbps/mm vs. 304Gbps/mm)。更高的边密度显然不是NVLink C2C需要解决的主要矛盾。
从驱动能力来看,112G SerDes的驱动能力远大于NVLink C2C。这在一定程度上会制约NVLink C2C的应用范围,未来类似于NVLink C2C的单端传输线技术有可能进一步演进,拓展传输距离,尤其是在224G 及以上SerDes时代,芯片间互联更加依赖于电缆解决方案,这对与计算系统是不友好的,会带来诸如芯片布局、散热困难等一系列工程挑战,同时也需要解决电缆方案成本过高的问题。
从功耗来看,112G SerDes的功耗效率为5.5pJ/bit,而NVLink C2C的功耗效率为1.3pJ/bit。在3.6Tbps互联带宽下,SerDes和NVLink C2C的功耗分别为19.8W和4.68W。虽然单独考虑芯片间互联时,功耗降低很多,但是H100 GPU芯片整体功耗大约为700W,因此互联功耗在整个芯片功耗中所占比例较小。
从成本角度来看,NVLink C2C的面积和功耗优于SerDes互联。因此,在提供相同互联带宽的情况下,它可以节省更多的芯片面积用于计算和缓存。然而,考虑到计算芯片并不是IO密集型芯片,因此这种成本节约的比例并不显著。但是,如果将双Chiplet芯粒拼装成更大规模的芯片时,NVLink C2C可以在某些场景下可以避免先进封装的使用,这对降低芯片成本有明显的帮助,例如Grace CPU SuperChip超级芯片选择标准封装加上NVLink C2C互联的方式进行扩展可以降低成本。在当前工艺水平下,先进封装的成本远高于逻辑Die本身。
C2C互联技术的另一个潜在的应用场景是大容量交换芯片,当其容量突破200T时,传统架构的SerDes面积和功耗占比过高,给芯片的设计和制造带来困难。在这种情况下,可以利用出封装的C2C互联技术来实现IO的扇出,同时尽量避免使用先进的封装技术,以降低成本。然而,目前的NVLink C2C技术并不适合这一应用场景,因为它无法与标准SerDes实现比特透明的转换。因此,需要引入背靠背的协议转换,这会增加时延和面积功耗。
Grace CPU 具有上下翻转对称性,因此单个芯片设计可以支持同构 Die 组成 SuperChip 超级芯片。Hopper GPU 不具备上下和左右翻转对称性,未来双 Die B100 GPU 芯片可能由两颗异构 Die 组成。
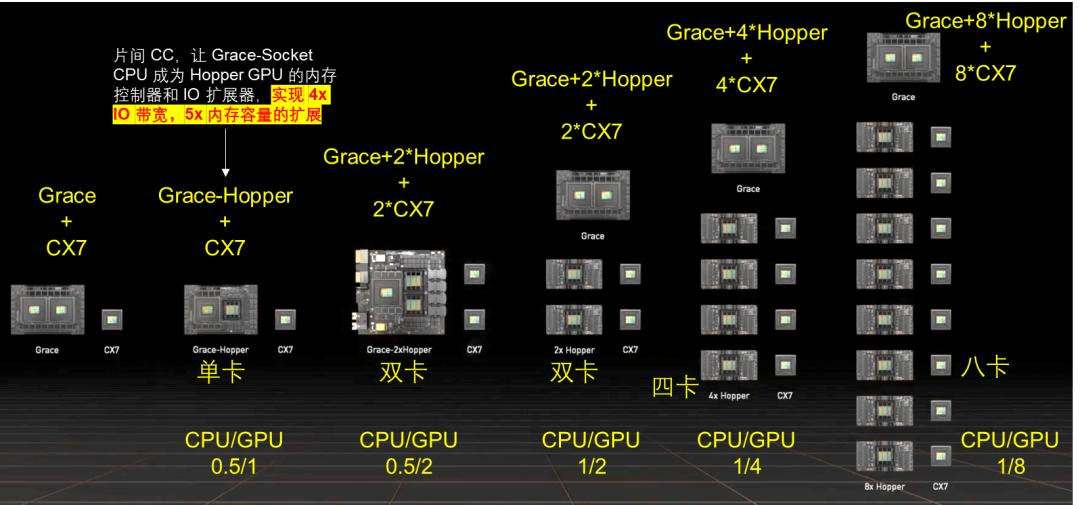 NVLink 和 NVLink C2C 技术提供了更灵活设计,实现了 CPU 和 GPU 灵活配置,可以构建满足不同应用需求的系统架构。NVLink C2C 可以提供灵活的CPU、GPU算力配比,可组成 1/0,0.5/1,0.5/2,1/4,1/8 等多种组合的硬件系统。NVLink C2C支持Grace CPU和Hopper GPU芯片间内存一致性操作 (Cache-Coherency),让 Grace CPU 成为 Hopper GPU 的内存控制器和 IO 扩展器,实现了 4倍 IO 带宽和5倍内存容量的扩展。这种架构打破了HBM的瓶颈,实现了内存超发。对训练影响是可以缓存更大模型,利用ZeRO等技术外存缓存模型,带宽提升能减少Fetch Weight的IO开销。对推理影响是可以缓存更大模型,按需加载模型切片推理,有可能在单CPU-GPU超级芯片内完成大模型推理 [23]。
NVLink 和 NVLink C2C 技术提供了更灵活设计,实现了 CPU 和 GPU 灵活配置,可以构建满足不同应用需求的系统架构。NVLink C2C 可以提供灵活的CPU、GPU算力配比,可组成 1/0,0.5/1,0.5/2,1/4,1/8 等多种组合的硬件系统。NVLink C2C支持Grace CPU和Hopper GPU芯片间内存一致性操作 (Cache-Coherency),让 Grace CPU 成为 Hopper GPU 的内存控制器和 IO 扩展器,实现了 4倍 IO 带宽和5倍内存容量的扩展。这种架构打破了HBM的瓶颈,实现了内存超发。对训练影响是可以缓存更大模型,利用ZeRO等技术外存缓存模型,带宽提升能减少Fetch Weight的IO开销。对推理影响是可以缓存更大模型,按需加载模型切片推理,有可能在单CPU-GPU超级芯片内完成大模型推理 [23]。
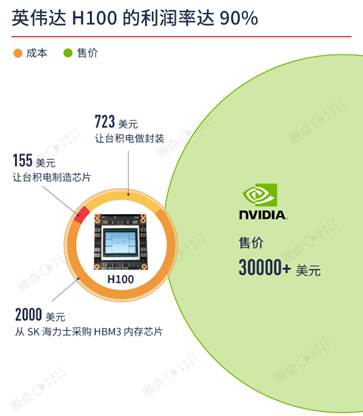
有媒体测算Nvidia的H100利润率达到90%。同时也给出了估算的H100的成本构成,Nvidia向台积电下订单,用 N4工艺制造 GPU 芯片,平均每颗成本 155 美元。Nvidia从 SK 海力士(未来可能有三星、美光)采购六颗 HBM3芯片,成本大概 2000 美元。台积电生产出来的 GPU 和Nvidia采购的 HBM3 芯片,一起送到台积电 CoWoS 封装产线,以性能折损最小的方式加工成 H100,成本大约 723 美元 [24]。
先进封装成本高,是逻辑芯片裸Die成本的3 到4倍以上, GPU内存的成本占比超过 60%。按照DDR: 5美金/GB,HBM: 15美金/GB以及参考文献 [25][26] 中给出的GPU计算Die和先进封装的成本测算,H100 GPU HBM成本占比为62.5%;GH200中HBM和LPDDR的成本占比为78.2%。
 虽然不同来源的信息对各个部件的绝对成本估算略有不同,但可以得出明确的结论:内存在AI计算系统中的成本占比可高达60%到70%以上;先进封装的成本是计算Die成本的3到4倍以上。在接近Reticle面积极限的大芯片良率达到80%的情况下,先进封装无法有效地降低成本。因此,应该遵循非必要不使用的原则。
虽然不同来源的信息对各个部件的绝对成本估算略有不同,但可以得出明确的结论:内存在AI计算系统中的成本占比可高达60%到70%以上;先进封装的成本是计算Die成本的3到4倍以上。在接近Reticle面积极限的大芯片良率达到80%的情况下,先进封装无法有效地降低成本。因此,应该遵循非必要不使用的原则。
与AMD和Intel GPU 架构对比
AMD的GPU相对于Nvidia更加依赖先进封装技术。MI250系列GPU采用了基于EFB硅桥的晶圆级封装技术,而MI300系列GPU则应用了AID晶圆级有源封装基板技术。相比之下,Nvidia并没有用尽先进封装的能力,一方面在当前代际的GPU中保持了相对较低的成本,另一方面也为下一代GPU保留了一部分工程工艺的价值发挥空间。
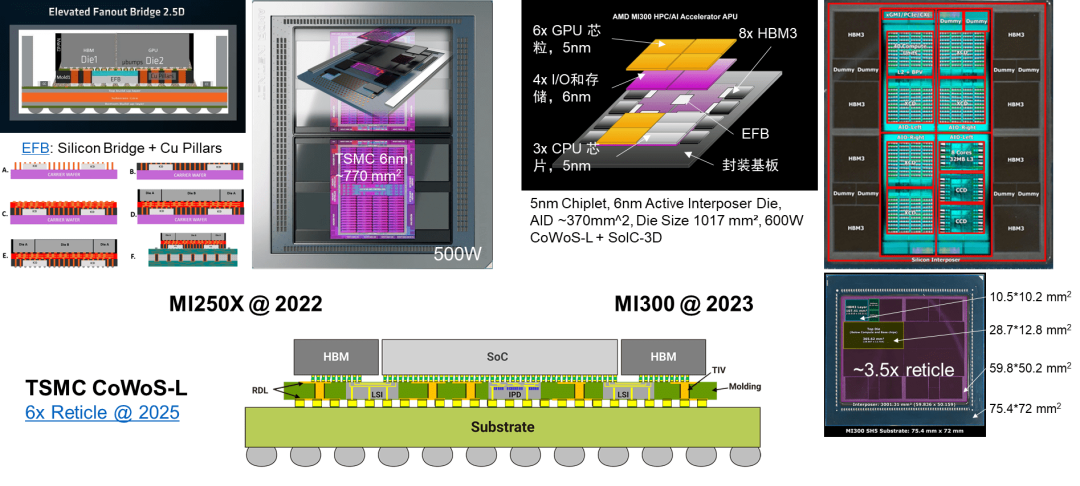
Intel Ponte Vecchio GPU将Chiplet和先进封装技术推向了极致,它涉及5个工艺节点(包括TSMC和Intel两家厂商的不同工艺),47个有源的Tile,并同时采用了EMIB 2.5D和Foveros 3D封装技术。可以说,它更像是一个先进封装技术的试验场。Intel 的主力AI芯片是Gaudi系列AI加速芯片 [27][28][29]。值得注意的是Gaudi系列AI芯片是由TSMC代工的Gaudi 2采用的是TSMC 7nm工艺,Gaudi 3采用的是TSMC 5nm工艺。
Nvidia未来AI芯片架构推演
NVLink和NVLink C2C演进推演
互联技术在很大程度上塑造了芯片和系统的物理架构。从互联技术的发展历程出发,以芯片布局为线索,并考虑工程工艺的物理限制,可以对Nvidia未来AI芯片架构进行预测。这种推演也有助于发掘对互联技术的新需求。
互联技术的演进是一个渐进的过程,其基本技术要素如带宽、调制和编码等都遵循着其内在的发展规律。这些物理规律相对稳定,通过将这些技术进行组合并结合当前工程工艺的发展趋势以及需求,就可以大致描绘和预测出互联技术的发展方向。在这里不深入探讨晦涩难懂的互联技术本身的发展,而是从宏观技术逻辑和外在可观察的指标两个角度出发,探讨NVLink和NVLink C2C的历史演进,并对其未来发展进行预测。
从NVLink的演进看,当前其演进了四个代际,NVLink C2C当前只有一个代际,通过与当下不同协议的速率演进对比及NVLink宣传材料,可以清晰的看到每个代际的NVLink技术的竞争对手和其要解决的痛点问题。当前接口有两大开放的互联生态,PCIE互联生态和Ethernet互联生态,CXL协议依托于PCIE互联生态,而InfiniBand则依托与Ethernet互联生态。NVLink的主要目标是解决GPU之间的互联问题,而早期的GPU一定需要保留与CPU互联的PCIE接口,用于GPU互联是也天然的继承了这一技术,因此NVLink早期的竞争对手是PCIE。从PCIE、Ethernet和NVLink的发展轨迹来看,NVLink的SerDes速率介于同时期PCIE和Ethernet SerDes速率之间。这意味着NVLink利用了Ethernet生态成熟的互联技术来对抗PCIE,实现接口速率超越PCIE。通过复用Ethernet生态的成熟互联技术,NVLink在成本方面也具有优势。
值得注意的是,NVLink并未完全遵循Ethernet的互联技术规范。例如,在50G NVLink3.0采用了NRZ调制,而不是Ethernet所采用的PAM4调制 [30]。这意味着NVLink3.0利用了100Gbps PAM4 SerDes代际的技术,并通过采用更低阶NRZ调制来实现链路的无误码运行,免去FEC实现低时延。同样以低时延著称的InfiniBand在50G这一代际则完全遵从了Ethernet的PAM4调制,这在一定程度上使其在50G这一代际丧失了低时延的技术优势,市场不得不选择长期停留在25G代际的InfiniBand网络上。当然,InfiniBand网络也有其无奈之处,因为它需要复用Ethernet光模块互联生态,所以它必须完全遵循Ethernet的互联电气规范,而与之对应的NVLink3.0则只需要解决盒子内或机框内互联即可。同样的事情也会在100G代际的NVLink4.0上发生,NVLink4.0完全摆脱了盒子和框子的限制,实现了跨盒子、跨框的互联,此时为了复用Ethernet的光模块互联生态,NVLink4.0的频点和调制格式也需要遵从Ethernet互联的电气规范。以前InfiniBand遇到的问题,NVLink也同样需要面对。在100G时代,可以观察到Ethernet、InfiniBand和NVLink的SerDes速率在时间节奏上齐步走的情况。实际上,这三种互联接口都采用了完全相同的SerDes互联技术。同样的情况在200G这一代际也会发生。与InfiniBand和Ethernet不同的是,NVLink是一个完全私有的互联生态,不存在跨速率代际兼容、同代际支持多种速率的接口和多厂商互通的问题。因此,在技术选择上,NVLink可以完全按照具体应用场景下的需求来选择设计甜点,在推出节奏上可以根据竞争情况自由把控,也更容易实现差异化竞争力和高品牌溢价。
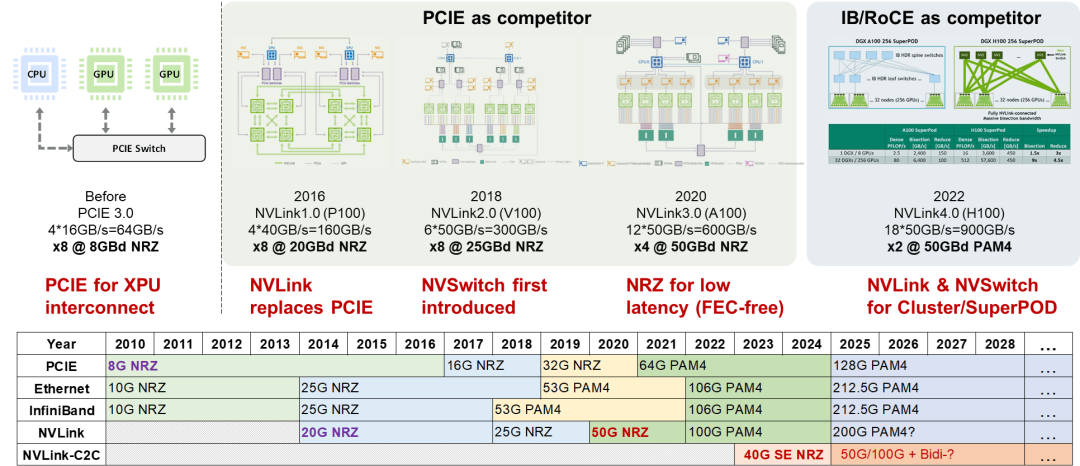 NVLink的发展可以分为两个阶段。NVLink1.0~3.0主要在盒子内、机框内实现GPU高速互联,对标PCIE。它利用了Ethernet SerDes演进更快的优势,采用了更高速的SerDes,同时在NVLink2.0时代开始引入NVSwitch技术,在盒子内、机框内组成总线域网络,在带宽指标上对PCIE形成了碾压式的竞争优势。NVLink4.0以后NVLink走出盒子和机框,NVSwitch走出计算盒子和机框,独立成为网络设备,此时对标的是InfiniBand和Ethernet网络。
NVLink的发展可以分为两个阶段。NVLink1.0~3.0主要在盒子内、机框内实现GPU高速互联,对标PCIE。它利用了Ethernet SerDes演进更快的优势,采用了更高速的SerDes,同时在NVLink2.0时代开始引入NVSwitch技术,在盒子内、机框内组成总线域网络,在带宽指标上对PCIE形成了碾压式的竞争优势。NVLink4.0以后NVLink走出盒子和机框,NVSwitch走出计算盒子和机框,独立成为网络设备,此时对标的是InfiniBand和Ethernet网络。
虽然NVLink4.0没有公开的技术细节,但是从NVLink网络的Load-Store网络定位和满足超节点内部内存共享的需求上看,一个合理的推测是,NVLink4.0很可能采用了轻量FEC加链路级重传的技术支持低时延和高可靠互联。在时延和可靠性竞争力指标上对InfiniBand和Ethernet形成碾压式的竞争力,这更有利于实现内存语义网络,支持超节点内内存共享。提供传统网络所不能提供的关键特性,才是NVLink作为总线域网络独立存在的理由。
基于NVLink C2C的产品目前只有GH200这一代,但是从Nvidia在该领域公开发表的论文中可以大致看出其技术发展的脉络。从技术演进上看,它是封装内Die间互联的在均衡上的增强。从Nvidia SuperChip超级芯片路标来看,它将在未来的AI芯片中继续发挥重要作用。对于这类接口,仍需保持连接两个独立封装芯片的能力和极低的时延和功耗。当前的NVLink C2C采用9*40Gbps NRZ调制方式。未来NVLink-C2C可能会向更高速率和双向传输技术方向演进。而50G NRZ是C2C互联场景下在功耗和时延方面的设计甜点。继续维持NRZ调制,选择合适工作频率,走向双向传输将是实现速率翻倍的重要技术手段。虽然NVLink C2C针对芯片间互联做了优化设计,但由于它与标准SerDes之间不存在速率对应关系,无法实现与标准SerDes之间比特透明的信号转换,因此其应用场景受限。在与标准SerDes对接时需要多引入一层协议转化会增加时延、面积和功耗开销。未来可能存在一种可能性,即采用类似NVLink C2C这种高密单端传输技术,同时与标准SerDes实现多对一的速率匹配,这种技术一旦实现将极大地扩展C2C高密单端互联技术的应用空间,也有可能开启SerDes面向更高速率演进的新赛道。
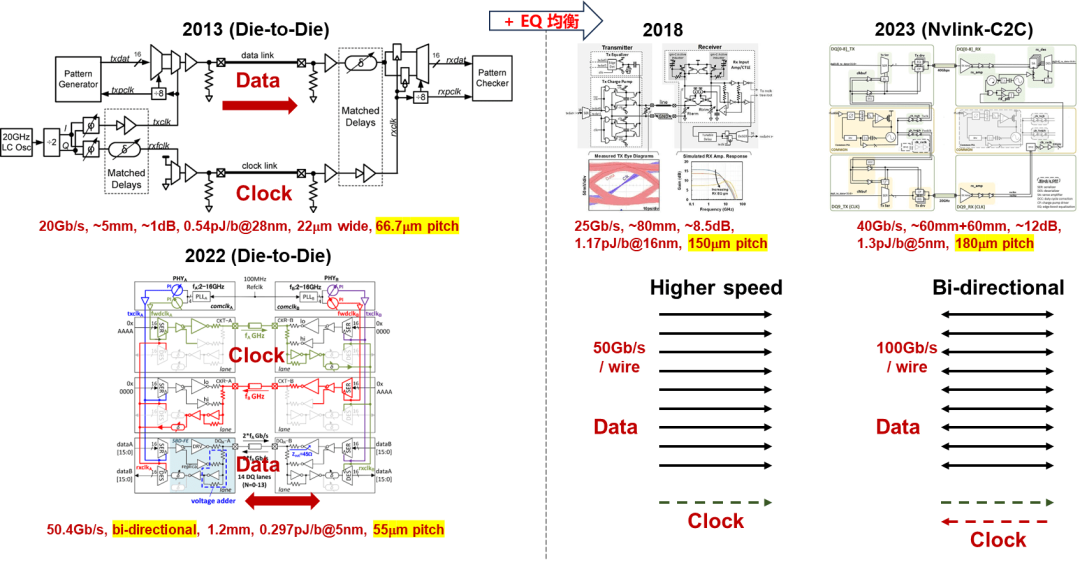
从NVLink和NVSwitch的演进来看,每一代速率会是上一代的1.5到2倍。下一代NVLink5.0大概率会采用200G每通道,每个GPU能够出的NVLink接口数量从18个增加到32个,甚至更高。而NVSwitch4.0在端口速率达到200G以外,交换芯片的端口数量可能在NVSwitch3.0交换芯片64端口的基础上翻2倍甚至4倍,总交换容量从12.8T到25.6T甚至51.2T [30]。
B100 GPU架构推演
以H100 GPU芯片布局为基础,通过先进的封装技术将两颗类似H100大小的裸Die进行合封,可以推演B100 GPU架构。B100 GPU有两种“双Die”推演架构:IO边缝合和HBM边缝合[31][32]。“HBM边缝合”利用H100的HBM边进行双Die连接,这种方案的优点在于,它可以使得IO可用边长翻倍,从而有利于扩展IO带宽。然而,它的缺点在于HBM可用边长并没有改变,因此无法进一步扩展HBM容量。“IO边缝合”利用H100的IO边进行双Die连接,这种方案的优势在于HBM可用边长能够翻倍,从而有利于扩展内存。然而,它的缺点在于IO可用边长并未改变,因此需要进一步提升IO密度。考虑到每代芯片与上一代相比,在内存、算力、互联三个层面需要实现两倍以上的性能提升,采用“IO 边缝合”方案的可能性更大。采用“IO 边缝合”的方案需要提升 IO 的边密度。

H100不具备旋转对对称性,而双Die的B100仍需支持 GH200 SuperChip 超级芯片,因此B100可能由两颗异构 Die组成。按照不同的长宽比采用“IO边缝合的方式”B100 的面积达到3.3到3.9倍的Reticle面积,小于当前TSMC CoWoS先进封装能够提供的4倍Reticle面积的能力极限。计算 Die 之间互联可以复用 NVLink C2C 互联技术,既利用 NVLink C2C出封装的连接能力覆盖Die间互联的场景。
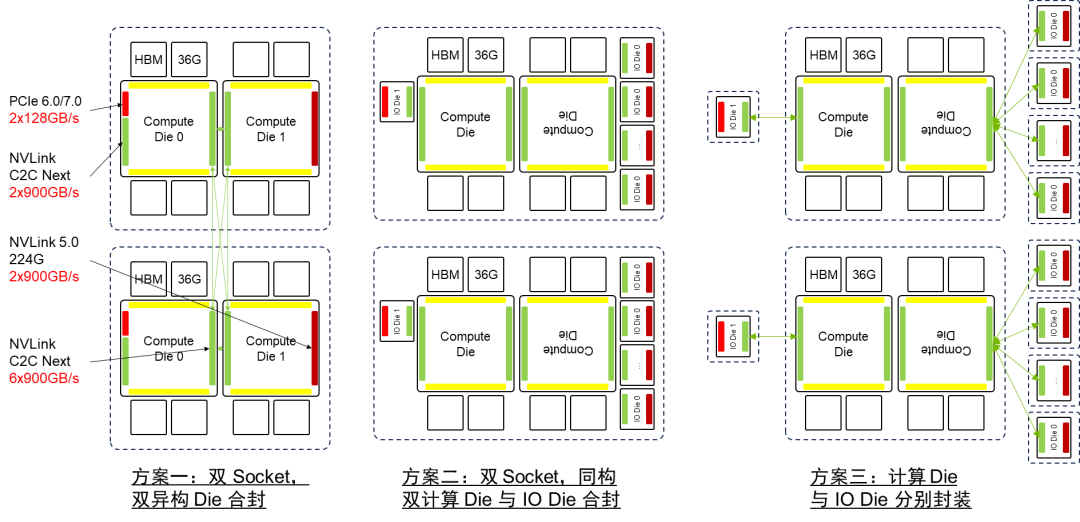
为了实现计算Die的归一化,可以将IO从计算Die中分离出来,形成独立的IO Die。这样,计算Die的互联接口就实现了归一化,使计算Die具备了旋转对称性。在这种情况下,仍然存在两种架构:一种是同构计算Die与IO Die合封,另一种是计算Die与IO Die分别封装并用C2C互联将二者连接。计算Die的同构最大的优势在于可以实现芯片的系列化。通过灵活组合计算Die和IO Die,可以实现不同规格的芯片以适应不同的应用场景的需求。
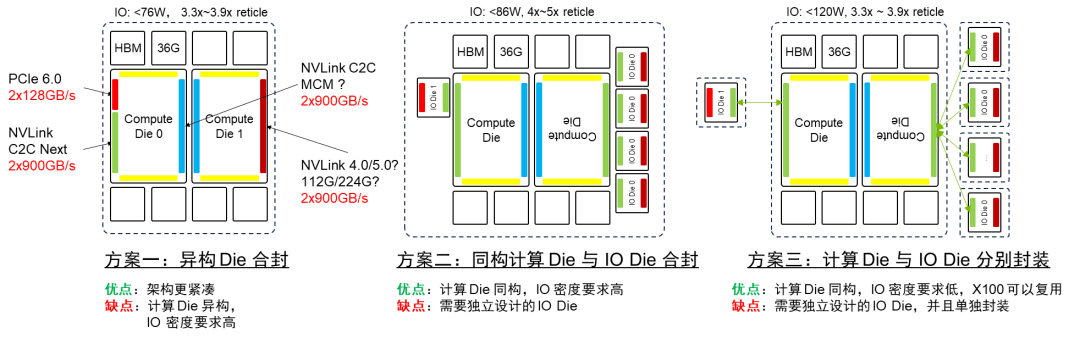 Nvidia B100 有“异构 Die 合封”,“计算Die与IO Die分离,同构计算 Die 与 IO Die 合封”,“计算 Die 与 IO Die 分离并分别封装,并用C2C互联将二者连接”三种架构选项。Nvidia B100 如果采用单封装双 Die 架构,封装基板面积达到 3.3~3.9倍 Reticle面积,功耗可能超过 1kW。计算 Die 之间互联可以复用 NVLink C2C 互联技术。将计算 Die 和 IO Die 分离可以实现计算 Die 的同构化,降低成本。利用 NVLink C2C 出封装互联的能力,可以将 IO 扇出,降低 IO 边密度压力。需要注意的是,当前 NVLink C2C 速率与 PCIE & NVLink 的 SerDes 无法匹配,因此需要 IO Die 上作协议转换,无法做到协议无关。如果 C2C 互联和 SerDes 速率能够进行多对一的匹配实现比特透明的 CDR,这样可以消除协议转换的开销。考虑到B100 2024年推出的节奏,方案一、三匹配当前先进封装能力,但方案三需要引入额外的协议转换;方案二超出当前先进封装能力。
Nvidia B100 有“异构 Die 合封”,“计算Die与IO Die分离,同构计算 Die 与 IO Die 合封”,“计算 Die 与 IO Die 分离并分别封装,并用C2C互联将二者连接”三种架构选项。Nvidia B100 如果采用单封装双 Die 架构,封装基板面积达到 3.3~3.9倍 Reticle面积,功耗可能超过 1kW。计算 Die 之间互联可以复用 NVLink C2C 互联技术。将计算 Die 和 IO Die 分离可以实现计算 Die 的同构化,降低成本。利用 NVLink C2C 出封装互联的能力,可以将 IO 扇出,降低 IO 边密度压力。需要注意的是,当前 NVLink C2C 速率与 PCIE & NVLink 的 SerDes 无法匹配,因此需要 IO Die 上作协议转换,无法做到协议无关。如果 C2C 互联和 SerDes 速率能够进行多对一的匹配实现比特透明的 CDR,这样可以消除协议转换的开销。考虑到B100 2024年推出的节奏,方案一、三匹配当前先进封装能力,但方案三需要引入额外的协议转换;方案二超出当前先进封装能力。
X100 GPU架构推演
Nvidia X100如果采用单Socket封装四Die架构,封装基板面积将超过6倍Reticle面积,这将超出2025年的先进封装路标的目标。而如果采用双Socket封装架构,则需要使用10~15cm的C2C互联技术来实现跨封装的计算 Die间的互联,这可能需要对当前NVLink C2C的驱动能力进一步增强。
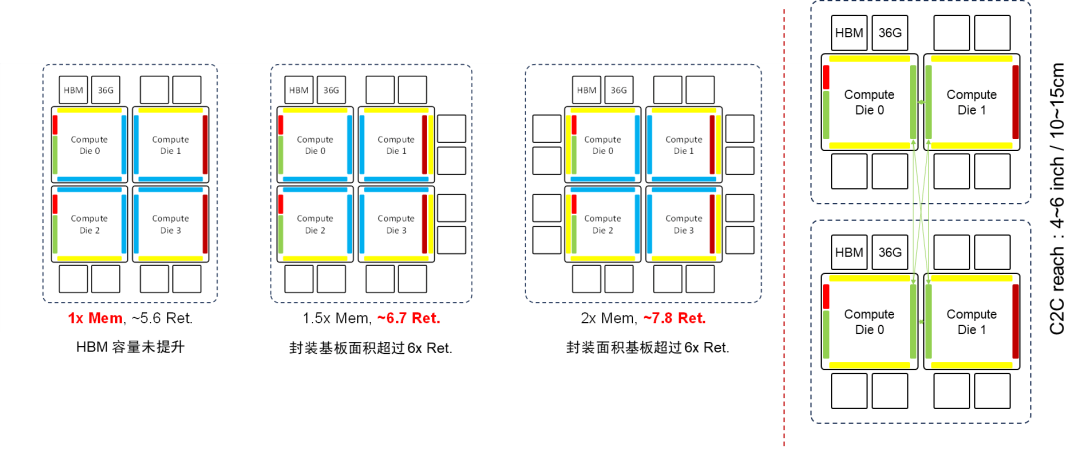 Nvidia X100 GPU如果采用四Die架构,如果要控制封装基板面积在6倍Reticle面积以下,匹配2025年先进封装路标,则需要在计算Die上通过3D堆叠的方式集成HBM [21][22]。因此X100如果不采用SuperChip超级芯片的架构而是延续单封装架构,要想在2025年推出,技术挑战非常大。一方面需要先进封装基板达到6倍Reticle面积,另一方面需要实现在计算Die上堆叠HBM,同时要解决HBM和计算Die堆叠带来的芯片散热问题。
Nvidia X100 GPU如果采用四Die架构,如果要控制封装基板面积在6倍Reticle面积以下,匹配2025年先进封装路标,则需要在计算Die上通过3D堆叠的方式集成HBM [21][22]。因此X100如果不采用SuperChip超级芯片的架构而是延续单封装架构,要想在2025年推出,技术挑战非常大。一方面需要先进封装基板达到6倍Reticle面积,另一方面需要实现在计算Die上堆叠HBM,同时要解决HBM和计算Die堆叠带来的芯片散热问题。
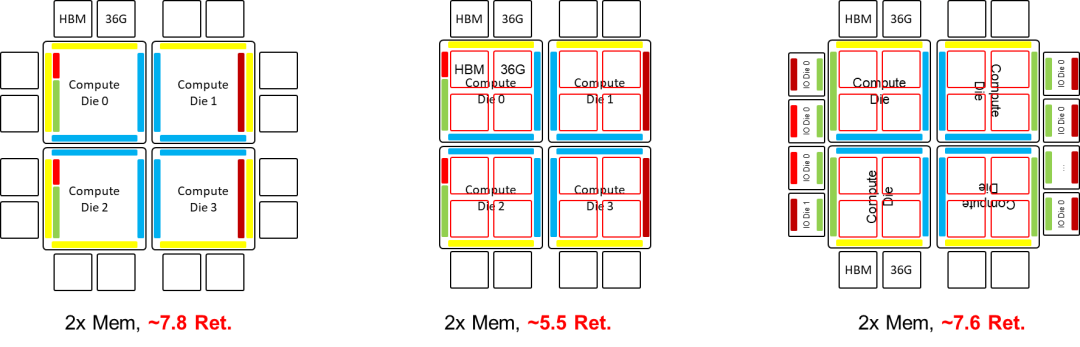 在满足2025年的工程约束的前提下,X100也可以采用SuperChip超级芯片架构在B100双Die架构的基础上进行平面扩展。在这种情况下,Nvidia X100 也有“异构 Die 合封”,“同构计算 Die 与 IO Die 合封”,“计算 Die 与 IO Die 分别封装”三种架构选项。如果采用封装间互联的超级芯片的扩展方式,先进封装的基板面积约束将不再会是瓶颈,此时只需要增强NVLink C2C的驱动能力。
在满足2025年的工程约束的前提下,X100也可以采用SuperChip超级芯片架构在B100双Die架构的基础上进行平面扩展。在这种情况下,Nvidia X100 也有“异构 Die 合封”,“同构计算 Die 与 IO Die 合封”,“计算 Die 与 IO Die 分别封装”三种架构选项。如果采用封装间互联的超级芯片的扩展方式,先进封装的基板面积约束将不再会是瓶颈,此时只需要增强NVLink C2C的驱动能力。
H100/H200, B100, X100 GPU架构演进总结
基于以下两个前提:每一代AI芯片的存储、计算和互联比例保持大致一致,且比上一代提升1.5到2倍以上;工程工艺演进是渐进且可预测的,不存在跳变,至少在2025年之前不会发生跳变。因此,可以对2023年的H100、2024年的B100和2025年的X100的架构进行推演总结。
对于工程工艺的基本假设如下:到2025年,工艺将保持在3nm水平,但工艺演进给逻辑器件带来的收益预计不会超过50%。同时,先进封装技术预计将在2025年达到6倍 Reticle面积的水平。此外,HBM内存容量也将继续增长,预计在2024年将达到24GB,而在2025年将达到36GB。
在上述前提假设条件下,针对H100/H200, B100, X100 GPU可以得到如下推演结论:
1. H200是基于H100的基础上从HBM3升级到HBM3e,提升了内存的容量和带宽。
2. B100将采用双Die架构。如果采用异构Die合封方式,封装基板面积将小于当前先进封装4倍Reticle面积的约束。而如果采用计算Die和IO Die分离,同构计算Die和IO Die合封的方式,封装基板面积将超出当前先进封装4倍Reticle面积的约束。如果采用计算Die和IO Die分离,同构计算Die和IO Die分开封装的方式,则可以满足当前的工程工艺约束。考虑到B100 2024年推出的节奏,以及计算Die在整个GPU芯片中的成本占比并不高,因此用异构Die合封方式的可能性较大。
3. 如果X100采用单Socket封装,四个异构Die合封装的方式,需要在计算Die上堆叠HBM,同时需要先进封装的基板达到6倍Reticle面积。但是,如果采用SuperChip超级芯片的方式组成双Socket封装模组,可以避免计算Die上堆叠HBM,并放松对先进封装基板面积的要求,此时需要对NVLink C2C的驱动能力做增强。
基于B100双Die架构,采用双Socket板级3D扩展可以实现与X100同等的算力。类似的方法也可以应用到X100中进一步扩展算力。板级扩展可以降低对工程工艺的要求,以较低的成本实现算力扩展。虽然基于人们对于先进封装的Chiplet芯粒架构充满了期待,但是其演进速度显然无法满足AI计算系统“三年三个数量级”的增长需求 [33]。在AI计算领域基于先进封装Die间互联Chiplet芯粒架构,很可能因为无法满足AI计算领域快速增长的需求而面临“二世而亡”的窘境,业界需要重新寻找旨在提升AI算力的新技术路径,比如SuperChip超级芯片和SuperPOD超节点。因此,类似于NVLink C2C的低时延、高可靠、高密度的芯片间互联技术在未来AI计算芯片的Scale Up算力扩展中将起到至关重要的作用;面向AI集群Scale Out算力扩展的互联技术也同等重要。这两中互联技术,前者是AI计算芯片算力扩展的基础,而后者是AI计算集群算力扩展的基础。
总结与思考
本文尝试从第一性原理出发,对Nvidia的AI芯片发展路线进行了深入分析和解读,并对未来的B100和X100芯片架构进行了推演预测。并且,希望通过这种推演提取出未来AI计算系统对互联技术的新需求。
本文以互联技术为主线展开推演分析,同时考虑了芯片代际演进的性能提升需求和工程工艺约束。最终得出的结论是:在AI计算领域,基于先进封装Die间互联的Chiplet芯粒架构无法满足AI计算领域快速增长的需求,可能面临“二世而亡”的窘境。低时延、高可靠、高密度的芯片间互联技术在未来AI计算芯片的Scale Up算力扩展中将起到至关重要的作用;虽然未展开讨论,同样的结论也适用于面向AI集群Scale Out算力扩展的互联技术。224G及以上代际中,面向计算集群的互联技术也存在非常大的挑战。需要明确指出的是,互联技术并不是简单地将芯片、盒子、机框连接起来的问题,它并不是一根连线而已,它需要在需求、技术、产业生态等各个方面进行综合考虑,需要极具系统性的创新以及长时间的、坚持不懈的投入和努力。
除了互联技术以外,通过对Nvidia相关技术布局的分析也引发了如下思考:
1. 真正的差异化竞争力源于系统性地、全面地掌握整个价值链中主导无法快速复制的关键环节。Nvidia在系统和网络、硬件、软件这三个方面占据了主导地位,而这三个方面恰恰是人工智能价值链中许多大型参与者无法有效或快速复制的重要部分。然而,要在这三个方面中的任何一方面建立领导地位都离不开长时间坚持不懈的投入和努力带来的技术沉淀和积累。指望在一个技术单点形成突破,期望形成技术壁垒或者技术护城河的可能性为零。“重要且无法快速复制”是核心特征,其中“重要”更容易被理解,而“无法快速复制”则意味着“长时间坚持不懈的投入和努力”带来的沉淀和积累,这是人们往往忽视的因素。
2. 开放的产业生态并不等同于技术先进性和竞争力。只有深入洞察特定领域的需求,进行技术深耕,做出差异化竞争力,才能给客户带来高价值,给自身带来高利润。Nvidia基于NVLink C2C的SuperChip超级芯片以及基于NVLink网络的SuperPOD超节点就是很好的例子。真正构筑核心竞争力的技术是不会开放的,至少在有高溢价的早期不会开放,比如Nvidia的NVLink和NVLink C2C技术,比如Intel的QPI和UPI。开放生态只是后来者用来追赶强者的借口(比如UEC),同时也是强者用来巩固自己地位的工具(比如PCIE)。然而,真正的强者并不会仅仅满足于开放生态所带来的优势,而是会通过细分领域和构筑特定领域的封闭生态,实现差异化竞争力来保持领先地位。
3. 构筑特定领域的差异化竞争力与复用开放的产业生态并不矛盾。其关键在于要在开放的产业生态中找到真正的结合点,并能够果断地做出取舍,勇敢地抛弃不必要的负担,只选择开放产业生态中的精华部分,构建全新的技术体系。为了构筑特定领域的差异化竞争力,更应该积极拥抱开放的产业生态,主动引导其发展以实现这种差异化。比如,InfiniBand与Ethernet在低时延方面的差异化并不是天生的,而是人为构造出来的。两者在基础技术上是相同的。InfiniBand在25G NRZ代际以前抓住了低时延这一核心特征,摒弃跨速率代际兼容的需求,卸掉了技术包袱,并且在HPC领域找到了合适的战场,因此在低时延指标上一直碾压Ethernet,成功实现了高品牌溢价。而InfiniBand在56G PAM4这一代际承袭了Ethernet的互联规范,因此这种低时延上的竞争力就逐渐丧失了。人为制造差异化竞争力的典型例子还有:同时兼容支持InfiniBand和Ethernet的CX系列网卡和BlueField系列DPU;内置在NVSwitch和InfiniBand交换机中的SHARP在网计算协议和技术;Nvidia基于NVLink C2C构筑SuperChip超级芯片以及基于NVLink网络构筑SuperPOD超节点。
4. “天下没有免费的午餐”,这是恒古不变的真理和底层的商业逻辑。商业模式中的“羊毛出在狗身上,由猪买单”其实就是变相的转移支付,羊毛终将是出在羊身上,只是更加隐蔽罢了。这一规律同样适用于对复杂系统中的技术价值的判断上。自媒体分析H100的BOM物料成本除以售价得到90%的毛利率是片面的,因为高价值部分是H100背后的系统竞争力,而不仅仅是那颗眼镜片大小的硅片。这里包含了H100背后的海量的研发投入和技术积累。而隐藏在这背后的实际上是人才。如何对中长期赛道上耕耘的人提供既紧张又轻松的研究环境,使研究人员能安心与具有长期深远影响的技术研究,是研究团队面临的挑战和需要长期思考的课题。从公开发表的D2D和C2C相关文献中可以看到,Nvidia在这一领域的研究投入超过十年,针对C2C互联这一场景的研究工作也超过五年。在五到十年的维度上长期进行迭代研究,需要相当强的战略定力,同时也需要非常宽松的研究环境和持续的研究投入。
5. 在人工智能时代,通过信息不对称来获取差异化竞争力或获得收益的可能性越来越低。这是因为制造信息不对称的难度和代价不断飙升,而其所带来的收益却逐渐减少。在不久的未来,制造信息不对称的代价将会远远超过收益。妄图通过垄断信息而达到差异化的竞争力,浪费的是时间,而失去的是机会。随着大模型的进一步演进发展,普通人可以通过人工智能技术轻松地获取并加工海量的信息且不会被淹没。未来的核心竞争力是如何驾驭包括人工智能在内的工具,对未来技术走向给出正确的判断。
6. Nvidia并非不可战胜,在激进的技术路标背后也隐藏着巨大的风险。如何向资本证明其在AI计算领域的能够长期维持统治地位,保持长期的盈利能力,以维持其高股价、实现持续高速增长,极具挑战性。一旦2025年发布的X100及其配套关键技术不及预期,这将直接影响投资者的信心。这是Nvidia必须面临的资本世界的考验,在这一点上它并没有制度优势。在一些基础技术层面,业界面临的挑战是一样的。以互联技术为例,用于AI计算芯片Scale Up算力扩展的C2C互联技术,以及面向AI集群Scale Out算力扩展的光电互联技术都存在非常大的挑战。谁能在未来互联技术演进的探索中,快速试错,最快地找到最佳路径,少犯错误,谁就抓住了先机。在未来的竞争中有可能实现超越。
参考文献
[1].https://investor.Nvidia.com/events-and-presentations/presentations/presentation-details/2023/Nvidia-Investor-Presentation-October-2023/default.aspx
[2].https://www.semianalysis.com/p/Nvidias-plans-to-crush-competition
[3].https://blogs.nvidia.cn/2022/02/17/nvidia-announces-financial-results-for-fourth-quarter-and-fiscal-2022/
[4]. https://www.nvidia.com/en-il/ai-summit-israel/
[5].https://mp.weixin.qq.com/s/6R-X8QQwwFsl_xzCSmEzGg?poc_token=HEkTXmWjgMNxXePnVbTjRZosjthKKjTSkDPJSign
[6]. https://www.fabricatedknowledge.com/p/the-coming-wave-of-ai-and-how-nvidia
[7]. https://mp.weixin.qq.com/s/S06Rp9KuYzyKlsMXSiSxVg
[8]. https://www.chaspark.com/#/hotspots/920830576377847808
[9]. https://nvidianews.nvidia.com/news/nvidia-to-acquire-mellanox-for-6-9-billion
[10]. https://nvidianews.nvidia.com/news/nvidia-completes-acquisition-of-mellanox-creating-major-force-driving-next-gen-data-centers
[11]. https://nvidianews.nvidia.com/news/nvidia-to-acquire-arm-for-40-billion-creating-worlds-premier-computing-company-for-the-age-of-ai
[12]. https://nvidianews.nvidia.com/news/nvidia-and-softbank-group-announce-termination-of-nvidias-acquisition-of-arm-limited
[13]. https://www.techpowerup.com/293173/nvidia-unveils-grace-cpu-superchip-with-144-cores-and-1-tb-s-bandwidth
[14]. https://ultraethernet.org/
[15]. https://wccftech.com/amd-instinct-mi450-accelerators-allegedly-feature-brand-new-xswitch-interconnect/
[16]. https://finance.yahoo.com/news/broadcom-introduces-industry-first-switch-140000547.html
[17]. https://irds.ieee.org/images/files/pdf/2022/2022IRDS_ES.pdf
[18]. https://wccftech.com/tsmc-roadmap-details-3nm-2nm-process-technologies-n3e-n3p-n3x-n2p-n2x/
[19]. https://www.anandtech.com/show/18876/tsmc-preps-sixreticlesize-super-carrier-interposer-for-extreme-sips
[20]. https://www.anandtech.com/show/18982/micron-publishes-updated-dram-roadmap-32-gb-ddr5-drams-gddr7-hbmnext
[21]. https://irds.ieee.org/images/files/pdf/2023/2023IRDS_Perspectives.pdf
[22]. https://www.tomshardware.com/news/sk-hynix-plans-to-stack-hbm4-directly-on-logic-processors
[23]. https://mp.weixin.qq.com/s/iTJ3b5KWbZXOVnAoOgz5og
[24]. https://mp.weixin.qq.com/s/KRgfCGCd1i8CL32EqEHP7A
[25]. https://www.extremetech.com/computing/report-nvidia-is-raking-in-1000-profit-on-every-h100-ai-accelerator
[26]. https://weibo.com/1663373597/Ngb3X2Vbn
[27]. https://www.sohu.com/a/699298572_120688473
[28]. https://wccftech.com/intel-unveil-ai-supercomputer-5th-gen-xeon-gaudi-2-chips-next-gen-gaudi-3-falcon-shores/
[29]. https://www.smbom.com/news/12608
[30]. https://hc34.hotchips.org/assets/program/conference/day2/Network%20and%20Switches/NVSwitch%20HotChips%202022%20r5.pdf
[31]. https://wccftech.com/nvidia-blackwell-b100-gpus-sk-hynix-hbm3e-memory-launches-q2-2024-rise-in-ai/
[32]. https://wccftech.com/nvidia-next-gen-blackwell-gpus-utilize-chiplet-design-feature-significant-changes/
[33]. https://www.chaspark.com/#/hotspots/927347788806991872
作者:陆玉春
来源:https://www.chaspark.com/#/hotspots/950120945305616384
PS:欢迎校招和社招同学加入极客星球2.0(升级版),一起快速进步,升职/跳槽涨薪:
极客星球核心宗旨是帮助你快速修炼基本功,基本功是职场起飞的基础,尤其是当下比较卷的职场,但大部分人都在卷应用,这些长期来看不可持续,不能真正的成长,所以需要大家修炼好基本功,基本功的重要性不言而喻(再谈大厂招聘),在各个大厂校招和社招最看重的东西,这里有资料,路线,校招,社招,职场,信息差,技术视野,学习问题答疑,专属星球群答疑。
极客星球希望成为最有价值的技术成长社区,尽最大努力帮助大家尽快打通任督二脉(打好基本功,练好软硬基础),然后去大厂镀金,进理想公司,高薪跳槽,去外企养老,以后做开源独立开发者,都是可以自己选择的,我把我所学的知识和多年职场实战经验分享给大家,希望可以帮你解惑成长中困惑和迷茫,助你快速成长,掌握一技之长。
星球另外一个学习目标就是:三年工资翻倍,我们要证明技术必须有回报(当前大模型风口月薪15W+),踏踏实实提高自己,不要总想一步登天,一步一步积累,认真学习,我相信三年薪资是可以翻倍的,正常路线应该是:10W->20W->50W->100W->200W,一般打工100w~200w 就到瓶颈了,再往上可能就看自己天赋了。
选择圈子很重要,一个好的圈子,能提高你能力的下限,极客星球是修炼基本功,结识人脉(群里也有在大厂的同学),扩展技术视野, 获取最新技术信息,提升职场认知,提高技术深度的地方,如果想提升自己,想加强自己基本功(尤其在校和刚毕业几年学生,修炼基本功尤为重要),就不要在观望了,这个是真正修炼基本功的地方,对应社招来说,不管想不想跳槽,我们需要拥有跳槽能力,不要让以后职业生涯太被动(在一个公司很难待一辈子)。
修炼基本功(职业发展基础):分享多年基础技术深度理解,基础概念深度解析,经典书籍推荐和读书分享(一起带领大家精读几本好书,解决书中疑问,读一本相当别人读十本),经典源码阅读分享等,不定期直播分享和答疑解惑;
扩展技术和商业视野(认知和视野):分享热门技术发展,国内外大厂技术内幕,业界解决方案;
校招/社招免费就业指导(找到好工作):模拟面试,简历修改,面试题分析,学习路线就业指导,面试高薪工作指导等;
职场普升/技术专家(职场发展):分享各种不同公司宝贵的职场普升经验,技术方向选择, 大厂普升经验,技术专家成长经验,让你少走几年的弯路;
专属高质量VIP交流群(人脉圈子):技术趋势,技术热点,分享学习心得,技术学习讨论,技术难题分享,群里有已经在各个大厂的同学和前辈,找到志同道合朋友,相互请教和学习;
硬核深入理解系列:
深入理解计算机系统
深入理解操作系统(调度,内存,网络,IO)
深入理解并发技术全景指南
深入理解编程语言
深入理解算法与数据结构
深入理解网络协议
深入理解网络编程
深入理解性能优化 (进大厂,升级高级工程师的核心能力)
深入理解分布式技术(互联网大厂必备核心技能)
分享AI技术原理和出路(加更:下期分享主题)
深入理解数据库
深入理解代码设计
深入理解架构设计
详细了解:极客星球 ,现在加入超级优惠,早点加入一起学习成长,早点突破成长瓶颈,专属的VIP群,任何技术难题都在讨论,每天都在进步,记得加我微信:fr35331508, 拉你进极客星球的群:

坚持干货内容,欢迎大家关注极客重生
感谢大家在看,转发,点赞
推荐阅读;


