
- 1从零开始—仿牛客网讨论社区项目(一)_牛客网项目源码 global.css
- 2JS逆向加密——补浏览器环境方式_唐志远逆向
- 3这些年,我身边的那些人和事
- 4同一台电脑上部署两个解压版的MySQL数据库_一台电脑上怎么部署不同版本mysql_安装两个mysql
- 5Flask模板引擎——Jinja2
- 6伪分布安装Hadoop2.8.0+Hbase1.3.1+Hive1.2.1+Kylin2.0_搭建hadoop、hbase的伪分布
- 7LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战_dashscope中的llm的api
- 8re.compile编译正则表达式_使用compile编译正则表达式;
- 96个利用国内AI大模型赚钱的创新项目_如何通过ai大模型挣钱
- 10转载英语单词_application interface develop
【python】8 API | AI | ML | DL 基本概念_神经网络api什么意思
赞
踩
1 API
在机器、深度学习中,建模、评估都不难,都是套路。
机器学习最关键的是特征工程,怎么才能得到更有价值的输入。
(就比如我一直在考虑权重、特征的问题)
深度学习解决了很多人工的问题,显得更智能。通过网络自动学习特征。
API(Application Programming Interface)应用程序编程借口,即预先定义的函数,提供应用程序,无需访问源码,访问一组例程。如keras就是python编写的高级神经网络API,Tensorflow作为后端运行,支持快速实验,最小时延将想法转为成果。
其实学习机器学习、深度学习就是学会各个模型所应用的场景,适用的范围。
2 AI ML DL
AI 人工智能(计算机视觉、自然语言处理、数据挖掘)
ML 机器学习
DL 深度学习
NN 神经网络 Neural Networks
RNN卷积(计算机视觉)
CNN循环、递归(自然语言处理)
数据获取
特征提取(适合问题,适合模型)(数据层面)(最关键)
建立模型
评估应用
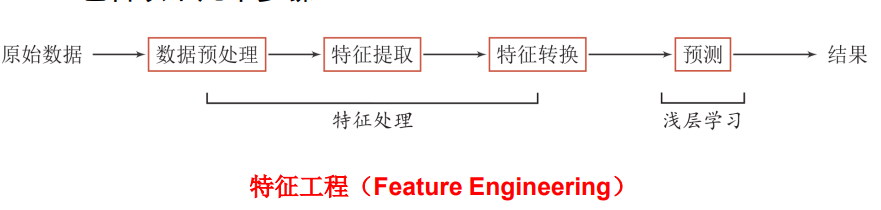
2.1 特征工程
1.数据特征决定模型上限
2.预处理和特征提取是最核心的
3.算法、参数选取只是决定如何逼近上限
3 机器学习概念
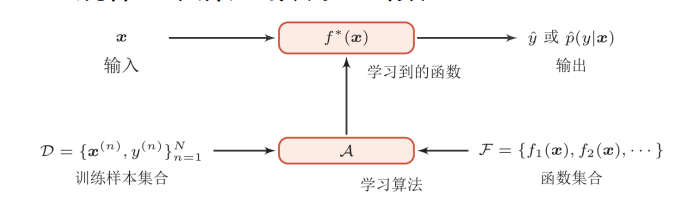
机器学习:构建映射函数,通过算法使机器能从大量数据中学习规律,从而对新的样品进行决策。
特征提取:基于任务或先验去除无用特征。
4 深度学习概念
深度学习:构建深度模型,自动学习好的特征表示。
表示学习:通过深度模型来学习高层语义特征。

5 一些常用专业词汇
5.1 过拟合
过拟合:在训练集表现好,在测试集表现差,即泛化能力差。优化过度,经验风险最小化原则容易导致模型在训练集上错误率很低,但是在测试集上错误率很高。往往是由于训练数据少、以及噪声等原因造成。
解决方法:正则化,所有损害优化的方法都是正则化,要增加优化约束,干扰优化过程,使用验证集来测试超参数,如果错误率在验证集上不再下降,便提前停止。
5.2 超参数
人为设定的参数
机器学习问题可以转化为最优化问题,如梯度下降法,搜索步长α也叫作学习率learning rate(重要的超参数)

6 人工神经网络 ANN artificial
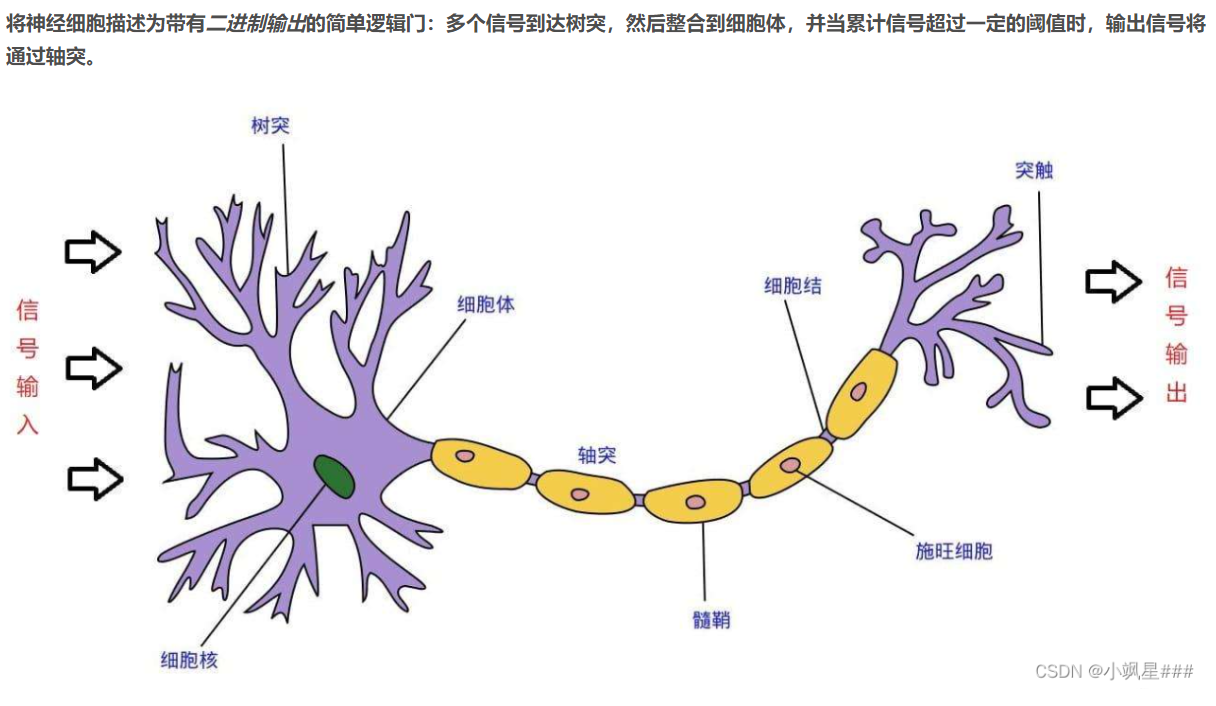

输入值:x(向量)
输入值的权重:w(向量)
净输入函数: z=w1x1+w2x2+…+wm*xm
偏置:(机器学习中把负的阈值或者权重w0=-θ),在直角坐标系中可以理解为直线的截距,目的是对神经元激活状态的控制。
变换函数、作用函数、激活函数f(x):有四种形式:阈值型、S型、伪线性型、概率型

7 感知器
感知器适用于简单模式分类,用于两类模式分类时,相当于用一个超平面(直线)将两类样本分开。感知器是研究其他网络的基础,易理解。简单单节点感知器具有分类原理,将分类知识存储于权向量,由权向量决定判决界面(直线、平面、超平面)以实验分类。
用途:感知器只能解决线性可分问题,输出只能是0和1

7.1 自适应线性单元 adaline
概念:感知器是用于离散时间型的神经网络,而自适应线性单元以连续线性模拟量为输出,结构与感知器网络相似。将期望输出与实际输出的误差作为调整信号,不断在线调整权向量,保证期望与实际输出相等。
用途:线性逼近一个函数式进行联想,用于信号滤波、预测、模型识别、控制。
优点:输出可以是任意值,采用W-H学习规则(最小均方差 LMS)进行训练,收敛速度更快,精度更高。
W-H学习规则:不需求导,简单,快。 (自相关矩阵相关概念)

