
(4-5)文本分类与情感分析算法:循环神经网络(RNN)_rnn文本情感分类
赞
踩
4.5 循环神经网络(RNN)
循环神经网络(Recurrent Neural Network,RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(Recursive Neural Network)。
4.5.1 循环神经网络介绍
RNN是两种神经网络模型的缩写,一种是递归神经网络(Recursive Neural Network),一种是循环神经网络(Recurrent Neural Network)。虽然这两种神经网络有着千丝万缕的联系,但是本书讲解的是第二种神经网络模型:循环神经网络(Recurrent Neural Network)。在现实应用中,经常用循环神经网络解决文本分类问题。
循环神经网络(Recurrent Neural Network, RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。循环神经网络是一个随着时间的推移而重复发生的结构,在自然语言处理(NLP)和语音图像等多个领域均有非常广泛的应用。RNN网络和其他网络最大的不同就在于RNN能够实现某种“记忆功能”,是进行时间序列分析时最好的选择。如同人类能够凭借自己过往的记忆更好地认识这个世界一样。RNN也实现了类似于人脑的这一机制,对所处理过的信息留存有一定的记忆,而不像其他类型的神经网络并不能对处理过的信息留存记忆。一个典型的RNN神经网络如图4-1所示。
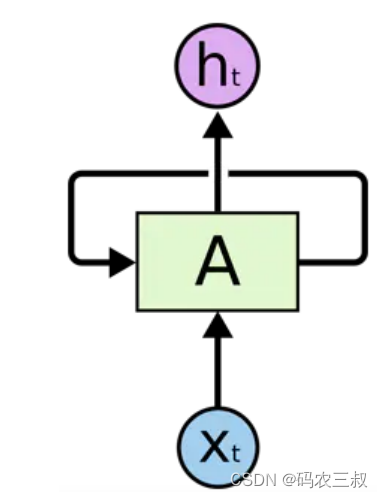
图4-1 一个典型的RNN神经网络
由上图可以看出:一个典型的RNN网络包含一个输入x,一个输出h和一个神经网络单元A。和普通的神经网络不同的是,RNN网络的神经网络单元A不仅仅与输入和输出存在联系,其与自身也存在一个回路。这种网络结构就揭示了RNN的实质:上一个时刻的网络状态信息将会作用于下一个时刻的网络状态。如果上图的网络结构仍不够清晰,RNN网络还能够以时间序列展开成如下图4-2所示的形式。
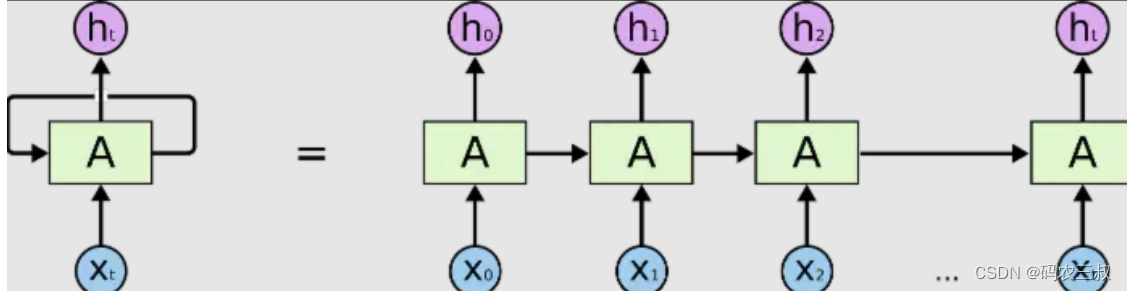
图4-2 以时间序列展开
等号右边是RNN的展开形式。由于RNN一般用来处理序列信息,因此下文说明时都以时间序列来举例,解释。等号右边的等价RNN网络中最初始的输入是x0,输出是h0,这代表着0时刻RNN网络的输入为x0,输出为h0,网络神经元在0时刻的状态保存在A中。当下一个时刻1到来时,此时网络神经元的状态不仅仅由1时刻的输入x1决定,也由0时刻的神经元状态决定。以后的情况都以此类推,直到时间序列的末尾t时刻。
上面的过程可以用一个简单的例子来论证:假设现在有一句话“I want to play basketball”,由于自然语言本身就是一个时间序列,较早的语言会与较后的语言存在某种联系,例如刚才的句子中“play”这个动词意味着后面一定会有一个名词,而这个名词具体是什么可能需要更遥远的语境来决定,因此一句话也可以作为RNN的输入。回到刚才的那句话,这句话中的5个单词是以时序出现的,我们现在将这五个单词编码后依次输入到RNN中。首先是单词“I”,它作为时序上第一个出现的单词被用作x0输入,拥有一个h0输出,并且改变了初始神经元A的状态。单词“want”作为时序上第二个出现的单词作为x1输入,这时RNN的输出和神经元状态将不仅仅由x1决定,也将由上一时刻的神经元状态或者说上一时刻的输入x0决定。之后的情况以此类推,直到上述句子输入到最后一个单词“basketball”。
卷积网络的输入只有输入数据X,而循环神经网络除了输入数据X之外,每一步的输出会作为下一步的输入,如此循环,并且每一次采用相同的激活函数和参数。在每次循环中,x0乘以系数U得到s0,再经过系数W输入到下一次,以此循环构成循环神经网络的正向传播。
循环神经网络与卷积神经网络作比较,卷积神经网络是一个输出经过网络产生一个输出。而循环神经网络可以实现一个输入多个输出(生成图片描述)、多个输入一个输出(文本分类)、多输入多输出(机器翻译、视频解说)。
RNN使用的是tan激活函数,输出在-1到1之间,容易梯度消失。距离输出较远的步骤对于梯度贡献很小。将底层的输出作为高层的输入就构成了多层的RNN网络,而且高层之间也可以进行传递,并且可以采用残差连接防止过拟合。
注意:
RNN的每次传播之间只有一个参数W,用这一个参数很难描述大量的、复杂的信息需求,为了解决这个问题引入了长短期记忆网络(Long Short Term Memory,LSTM)。这个网络可以进行选择性机制,选择性的输入、输出需要使用的信息以及选择性地遗忘不需要的信息。选择性机制的实现是通过Sigmoid门实现的,sigmoid函数的输出介于0到1之间,0代表遗忘,1代表记忆,0.5代表记忆50%。
4.5.2 文本分类
文本分类问题就是对输入的文本字符串进行分析判断,之后再输出结果。字符串无法直接输入到RNN网络,因此在输入之前需要先对文本拆分成单个词组,将词组进行embedding编码成一个向量,每轮输入一个词组,当最后一个词组输入完毕时得到输出结果也是一个向量。embedding将一个词对应为一个向量,向量的每一个维度对应一个浮点值,动态调整这些浮点值使得embedding编码和词的意思相关。这样网络的输入输出都是向量,再最后进行全连接操作对应到不同的分类即可。
RNN网络会不可避免地带来一个问题:最后的输出结果受最近的输入较大,而之前较远的输入可能无法影响结果,这就是信息瓶颈问题,为了解决这个问题引入了双向LSTM。双向LSTM不仅增加了反向信息传播,而且每一轮的都会有一个输出,将这些输出进行组合之后再传给全连接层。
另一个文本分类模型是HAN(Hierarchy Attention Network),首先将文本分为句子、词语级别,将输入的词语进行编码然后相加得到句子的编码,然后再将句子编码相加得到最后的文本编码。而attention是指在每一个级别的编码进行累加前,加入一个加权值,根据不同的权值对编码进行累加。
由于输入的文本长度不统一,所以无法直接使用神经网络进行学习,为了解决这个问题,可以将输入文本的长度统一为一个最大值,勉强采用卷积神经网络进行学习,即TextCNN。文本卷积网络的卷积过程采用的是多通道一维卷积,与二维卷积相比一维卷积就是卷积核只在一个方向上移动。
在现实应用中,虽然CNN网络不能完美处理输入长短不一的序列式问题,但是它可以并行处理多个词组,效率更高,而RNN可以更好地处理序列式的输入,将两者的优势结合起来就构成了R-CNN模型。首先通过双向RNN网络对输入进行特征提取,再使用CNN进一步提取,之后通过池化层将每一步的特征融合在一起,最后经过全连接层进行分类。
4.5.3 使用PyTorch开发歌词生成器模型
请看下面的实例,功能是使用循环神经网络生成新的歌词。本实例包括数据预处理、模型定义、训练过程和生成新歌词等步骤,帮助理解如何使用循环神经网络处理文本数据。
实例4-5:使用循环神经网络生成新的歌词(源码路径:daima\4\gequ.py)
实例文件gequ.py的具体实现流程如下所示。
(1)导入所需的库
导入PyTorch库和其他所需的库,包括神经网络模块、NumPy库用于数据处理,以及Matplotlib库用于可视化。对应的实现代码如下所示。
- import torch
- import torch.nn as nn
- import numpy as np
- import matplotlib.pyplot as plt
(2)定义歌曲专辑歌词
定义了一段歌曲专辑歌词作为我们的训练数据,对应的实现代码如下所示。
- lyrics = """
- In the jungle, the mighty jungle
- The lion sleeps tonight
- In the jungle, the quiet jungle
- The lion sleeps tonight
- """
(3)创建歌词数据集
编写函数create_dataset(),用于将歌词转换为可以用于训练的数据集。它将歌词切割成输入序列和目标序列,并将字符映射到索引值以便于处理。对应的实现代码如下所示。
- def create_dataset(lyrics, seq_length):
- dataX = []
- dataY = []
- chars = list(set(lyrics))
- char_to_idx = {ch: i for i, ch in enumerate(chars)}
-
- for i in range(0, len(lyrics) - seq_length):
- seq_in = lyrics[i:i+seq_length]
- seq_out = lyrics[i+seq_length]
- dataX.append([char_to_idx[ch] for ch in seq_in])
- dataY.append(char_to_idx[seq_out])
-
- return np.array(dataX), np.array(dataY), char_to_idx
(4)定义循环神经网络模型类RNNModel
类RNNModel定义了循环神经网络模型的结构。它包括一个嵌入层(用于将输入序列转换为向量表示)、一个循环层(在这里使用的是简单的RNN)和一个全连接层(用于生成输出)。对应的实现代码如下所示。
- class RNNModel(nn.Module):
- def __init__(self, input_size, hidden_size, output_size):
- super(RNNModel, self).__init__()
- self.hidden_size = hidden_size
- self.embedding = nn.Embedding(input_size, hidden_size)
- self.rnn = nn.RNN(hidden_size, hidden_size, batch_first=True)
- self.fc = nn.Linear(hidden_size, output_size)
-
- def forward(self, x, hidden):
- embedded = self.embedding(x)
- output, hidden = self.rnn(embedded, hidden)
- output = self.fc(output[:, -1, :]) # 只取最后一个时间步的输出
- return output, hidden
-
- def init_hidden(self, batch_size):
- return torch.zeros(1, batch_size, self.hidden_size)
(5)定义超参数
下面这些是超参数,用于定义训练过程的设置,如序列长度、隐藏层大小、训练轮数、批大小等。对应的实现代码如下所示。
- seq_length = 10
- input_size = len(set(lyrics))
- hidden_size = 128
- output_size = len(set(lyrics))
- num_epochs = 100
(6)创建数据集和数据加载器
使用之前定义的create_dataset函数创建了数据集,并将其转换为PyTorch的Tensor类型。然后,我们使用TensorDataset和DataLoader将数据集封装成可供模型训练使用的数据加载器。对应的实现代码如下所示。
- dataX, dataY, char_to_idx = create_dataset(lyrics, seq_length)
- dataX = torch.from_numpy(dataX)
- dataY = torch.from_numpy(dataY)
- dataset = torch.utils.data.TensorDataset(dataX, dataY)
- data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
(7)实例化模型和定义损失函数与优化器
在这一步中,实例化了之前定义的循环神经网络模型,并定义了交叉熵损失函数和Adam优化器。对应的实现代码如下所示。
- model = RNNModel(input_size, hidden_size, output_size)
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
(8)训练模型
在这一步中,我们使用数据加载器逐批次地将数据输入模型进行训练。在每个训练批次中,我们首先将优化器的梯度缓存清零,然后通过模型进行前向传播并计算损失,之后进行反向传播并更新模型参数。最后,我们打印出每10轮训练的损失值。对应的实现代码如下所示。
- for epoch in range(num_epochs):
- model.train()
- hidden = model.init_hidden(batch_size)
-
- for inputs, targets in data_loader:
- optimizer.zero_grad()
- hidden = hidden.detach()
- outputs, hidden = model(inputs, hidden)
- targets = targets.long()
- loss = criterion(outputs, targets)
- loss.backward()
- optimizer.step()
-
- if (epoch+1) % 10 == 0:
- print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}")
(9)可视化训练损失
在训练完成后,绘制了训练过程中损失的曲线图,以便我们可以更直观地了解模型的训练情况。对应的实现代码如下所示。
- plt.plot(losses)
- plt.xlabel('Epoch')
- plt.ylabel('Loss')
- plt.title('Training Loss')
- plt.show()
(10)生成新歌词
使用训练好的模型生成新的歌词。我们首先设置模型为评估模式,并初始化隐藏状态。然后,我们提供一个初始字符,将其转换为Tensor类型,并循环进行预测,每次预测将输出的字符添加到生成的歌词中。最后,我们将生成的歌词输出到控制台。对应的实现代码如下所示。
- model.eval()
- hidden = model.init_hidden(1)
- start_char = 'I'
- generated_lyrics = [start_char]
-
- with torch.no_grad():
- input_char = torch.tensor([[char_to_idx[start_char]]], dtype=torch.long)
- while len(generated_lyrics) < 100:
- output, hidden = model(input_char, hidden)
- _, predicted = torch.max(output, 1)
- next_char = list(char_to_idx.keys())[list(char_to_idx.values()).index(predicted.item())]
- generated_lyrics.append(next_char)
- input_char = torch.tensor([[predicted.item()]], dtype=torch.long)
-
- generated_lyrics = ''.join(generated_lyrics)
- print("Generated Lyrics:")
- print(generated_lyrics)
执行后会输出训练过程,展示生成的新歌词:
- Epoch 10/100, Loss: 1.1320719818505984
- Epoch 20/100, Loss: 0.7656564090223303
- Epoch 30/100, Loss: 0.4912299852448187
- Epoch 40/100, Loss: 0.5815703137422835
- Epoch 50/100, Loss: 0.5197872494708432
- Epoch 60/100, Loss: 0.6041784392461887
- Epoch 70/100, Loss: 0.5132076922750782
- Epoch 80/100, Loss: 0.841928897174127
- Epoch 90/100, Loss: 0.6915850965689768
- Epoch 100/100, Loss: 0.786836911407844
并绘制出训练过程中损失的曲线图,如图4-3所示。
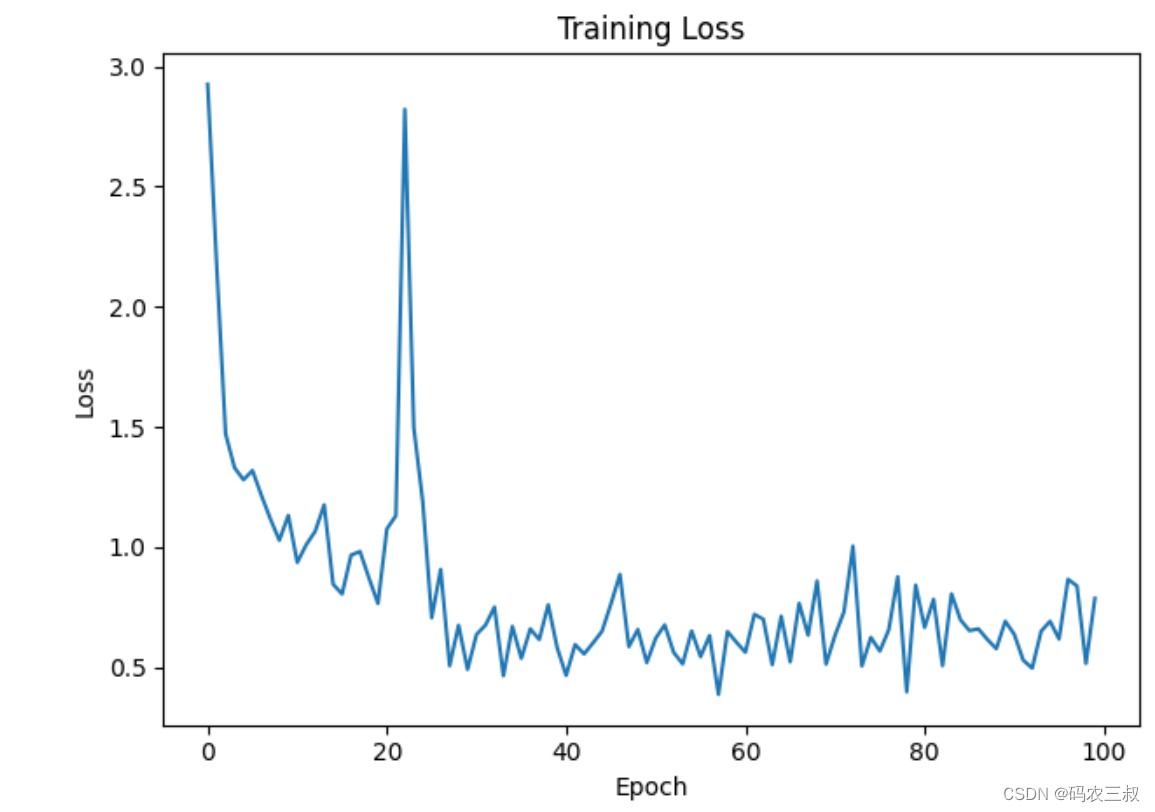
图4-3 训练过程中损失的曲线图
4.5.4 使用TensorFlow制作情感分析模型
请看下面的实例,功能是在IMDB大型电影评论数据集上训练循环神经网络,以进行情感分析。
实例4-6:使用电影评论数据集制作情感分析模型(源码路径:daima\4\xun03.py)
实例文件xun03.py的具体实现流程如下:
(1)导入matplotlib并创建一个辅助函数来绘制计算图,代码如下:
- import matplotlib.pyplot as plt
-
- def plot_graphs(history, metric):
- plt.plot(history.history[metric])
- plt.plot(history.history['val_'+metric], '')
- plt.xlabel("Epochs")
- plt.ylabel(metric)
- plt.legend([metric, 'val_'+metric])
- plt.show()
(2)设置输入流水线,IMDB 大型电影评论数据集是一个二进制分类数据集——所有评论都具有正面或负面情绪。使用 TFDS下载数据集,代码如下:
- dataset, info = tfds.load('imdb_reviews/subwords8k', with_info=True,
- as_supervised=True)
- train_dataset, test_dataset = dataset['train'], dataset['test']
执行后会输出:
- WARNING:absl:TFDS datasets with text encoding are deprecated and will be removed in a future version. Instead, you should use the plain text version and tokenize the text using `tensorflow_text` (See: https://www.tensorflow.org/tutorials/tensorflow_text/intro#tfdata_example)
- Downloading and preparing dataset imdb_reviews/subwords8k/1.0.0 (download: 80.23 MiB, generated: Unknown size, total: 80.23 MiB) to /home/kbuilder/tensorflow_datasets/imdb_reviews/subwords8k/1.0.0...
- Shuffling and writing examples to /home/kbuilder/tensorflow_datasets/imdb_reviews/subwords8k/1.0.0.incomplete7GBYY4/imdb_reviews-train.tfrecord
- Shuffling and writing examples to /home/kbuilder/tensorflow_datasets/imdb_reviews/subwords8k/1.0.0.incomplete7GBYY4/imdb_reviews-test.tfrecord
- Shuffling and writing examples to /home/kbuilder/tensorflow_datasets/imdb_reviews/subwords8k/1.0.0.incomplete7GBYY4/imdb_reviews-unsupervised.tfrecord
- Dataset imdb_reviews downloaded and prepared to /home/kbuilder/tensorflow_datasets/imdb_re
在数据集 info 中包括编码器 (tfds.features.text.SubwordTextEncoder),代码如下:
- encoder = info.features['text'].encoder
- print('Vocabulary size: {}'.format(encoder.vocab_size))
执行后会输出:
Vocabulary size: 8185此文本编码器将以可逆方式对任何字符串进行编码,并在必要时退回到字节编码。代码如下:
- sample_string = 'Hello TensorFlow.'
-
- encoded_string = encoder.encode(sample_string)
- print('Encoded string is {}'.format(encoded_string))
-
- original_string = encoder.decode(encoded_string)
- print('The original string: "{}"'.format(original_string))
执行后会输出:
Vocabulary size: 8185此文本编码器将以可逆方式对任何字符串进行编码,并在必要时退回到字节编码。代码如下:
- sample_string = 'Hello TensorFlow.'
-
- encoded_string = encoder.encode(sample_string)
- print('Encoded string is {}'.format(encoded_string))
-
- original_string = encoder.decode(encoded_string)
- print('The original string: "{}"'.format(original_string))
-
- assert original_string == sample_string
-
- for index in encoded_string:
- print('{} ----> {}'.format(index, encoder.decode([index])))
执行后会输出:
- Encoded string is [4025, 222, 6307, 2327, 4043, 2120, 7975]
- The original string: "Hello TensorFlow."
-
- 4025 ----> Hell
- 222 ----> o
- 6307 ----> Ten
- 2327 ----> sor
- 4043 ----> Fl
- 2120 ----> ow
- 7975 ----> .
(3)开始准备用于训练的数据,创建这些编码字符串的批次。使用 padded_batch 方法将序列零填充至批次中最长字符串的长度,代码如下:
- BUFFER_SIZE = 10000
- BATCH_SIZE = 64
-
- train_dataset = train_dataset.shuffle(BUFFER_SIZE)
- train_dataset = train_dataset.padded_batch(BATCH_SIZE)
-
- test_dataset = test_dataset.padded_batch(BATCH_SIZE)
(4)开始创建模型,构建一个 tf.keras.Sequential 模型并从嵌入向量层开始。嵌入向量层每个单词存储一个向量。调用时,它会将单词索引序列转换为向量序列。这些向量是可训练的。(在足够的数据上)训练后,具有相似含义的单词通常具有相似的向量。与通过 tf.keras.layers.Dense 层传递独热编码向量的等效运算相比,这种索引查找方法要高效得多。
循环神经网络 (RNN) 通过遍历元素来处理序列输入。RNN 将输出从一个时间步骤传递到其输入,然后传递到下一个步骤。tf.keras.layers.Bidirectional 包装器也可以与 RNN 层一起使用,这将通过 RNN 层向前和向后传播输入,然后连接输出,这有助于 RNN 学习长程依赖关系。代码如下:
- model = tf.keras.Sequential([
- tf.keras.layers.Embedding(encoder.vocab_size, 64),
- tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
- tf.keras.layers.Dense(64, activation='relu'),
- tf.keras.layers.Dense(1)
- ])
请注意,在这里选择 使用的是Keras 序贯模型,因为模型中的所有层都只有单个输入并产生单个输出。如果要使用有状态 RNN 层,则可能需要使用 Keras 函数式 API 或模型子类化来构建模型,以便可以检索和重用 RNN 层状态。有关更多详细信息,请参阅 Keras RNN 指南。
(5)编译 Keras 模型以配置训练过程,代码如下:
- model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
- optimizer=tf.keras.optimizers.Adam(1e-4),
- metrics=['accuracy'])
- history = model.fit(train_dataset, epochs=10,
- validation_data=test_dataset,
- validation_steps=30)
执行后会输出:
- Epoch 1/10
- 391/391 [==============================] - 41s 105ms/step - loss: 0.6363 - accuracy: 0.5736 - val_loss: 0.4592 - val_accuracy: 0.8010
- Epoch 2/10
- 391/391 [==============================] - 41s 105ms/step - loss: 0.3426 - accuracy: 0.8556 - val_loss: 0.3710 - val_accuracy: 0.8417
- Epoch 3/10
- 391/391 [==============================] - 42s 107ms/step - loss: 0.2520 - accuracy: 0.9047 - val_loss: 0.3444 - val_accuracy: 0.8719
- Epoch 4/10
- 391/391 [==============================] - 41s 105ms/step - loss: 0.2103 - accuracy: 0.9228 - val_loss: 0.3348 - val_accuracy: 0.8625
- Epoch 5/10
- 391/391 [==============================] - 42s 106ms/step - loss: 0.1803 - accuracy: 0.9360 - val_loss: 0.3591 - val_accuracy: 0.8552
- Epoch 6/10
- 391/391 [==============================] - 42s 106ms/step - loss: 0.1589 - accuracy: 0.9450 - val_loss: 0.4146 - val_accuracy: 0.8635
- Epoch 7/10
- 391/391 [==============================] - 41s 105ms/step - loss: 0.1466 - accuracy: 0.9505 - val_loss: 0.3780 - val_accuracy: 0.8484
- Epoch 8/10
- 391/391 [==============================] - 41s 106ms/step - loss: 0.1463 - accuracy: 0.9485 - val_loss: 0.4074 - val_accuracy: 0.8156
- Epoch 9/10
- 391/391 [==============================] - 41s 106ms/step - loss: 0.1327 - accuracy: 0.9555 - val_loss: 0.4608 - val_accuracy: 0.8589
- Epoch 10/10
- 391/391 [==============================] - 41s 105ms/step - loss: 0.1666 - accuracy: 0.9404 - val_loss: 0.4364 - val_accuracy: 0.8422
(6)查看损失,代码如下:
- test_loss, test_acc = model.evaluate(test_dataset)
-
- print('Test Loss: {}'.format(test_loss))
- print('Test Accuracy: {}'.format(test_acc))
执行后会输出:
- 391/391 [==============================] - 17s 43ms/step - loss: 0.4305 - accuracy: 0.8477
- Test Loss: 0.43051090836524963
- Test Accuracy: 0.8476799726486206
上面的模型没有遮盖应用于序列的填充。如果在填充序列上进行训练并在未填充序列上进行测试,则可能导致倾斜。理想情况下,您可以使用遮盖来避免这种情况,但是正如在下面看到的那样,它只会对输出产生很小的影响。如果预测 >= 0.5,则为正,否则为负。代码如下:
- def pad_to_size(vec, size):
- zeros = [0] * (size - len(vec))
- vec.extend(zeros)
- return vec
-
- def sample_predict(sample_pred_text, pad):
- encoded_sample_pred_text = encoder.encode(sample_pred_text)
-
- if pad:
- encoded_sample_pred_text = pad_to_size(encoded_sample_pred_text, 64)
- encoded_sample_pred_text = tf.cast(encoded_sample_pred_text, tf.float32)
- predictions = model.predict(tf.expand_dims(encoded_sample_pred_text, 0))
-
- return (predictions)
-
- #在没有填充的示例文本上进行预测。
- sample_pred_text = ('The movie was cool. The animation and the graphics '
- 'were out of this world. I would recommend this movie.')
- predictions = sample_predict(sample_pred_text, pad=False)
- print(predictions)
执行后会输出:
[[-0.11829309]](7)使用填充对示例文本进行预测,代码如下:
- sample_pred_text = ('The movie was cool. The animation and the graphics '
- 'were out of this world. I would recommend this movie.')
- predictions = sample_predict(sample_pred_text, pad=True)
- print(predictions)
执行后会输出:
[[-1.162545]](8)编写可视化代码,
- plot_graphs(history, 'accuracy')
- plot_graphs(history, 'loss')
执行后分别绘制accuracy曲线图和loss曲线图,如图4-4所示。
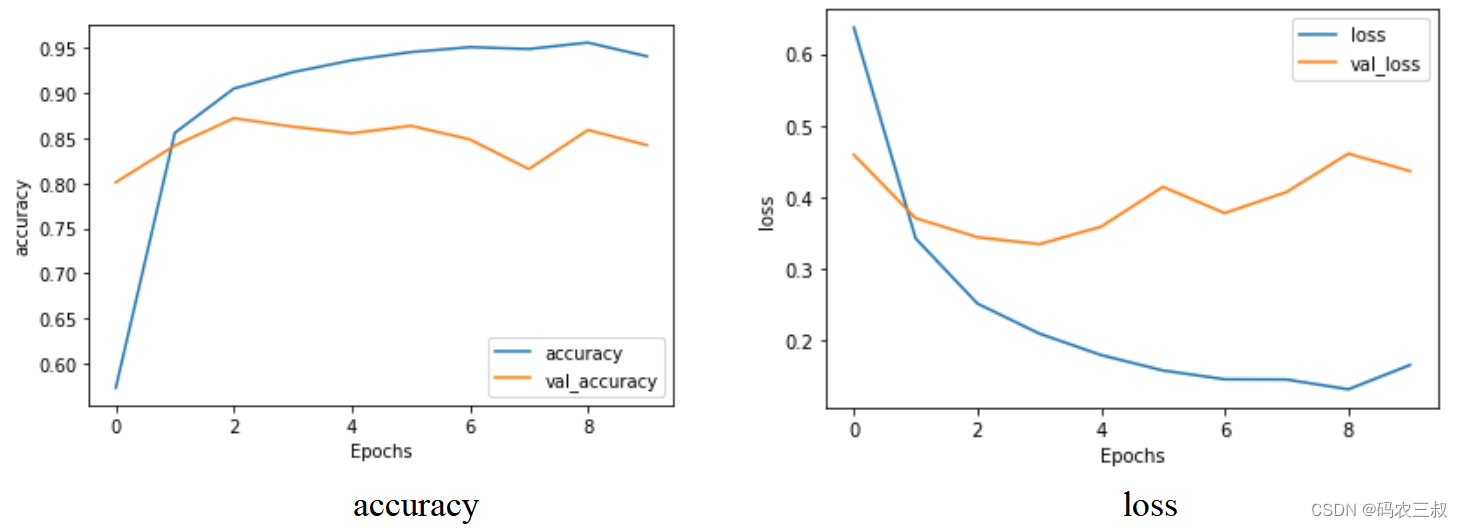
图4-4 可视化效果
(9)开始堆叠两个或更多 LSTM 层,Keras 循环层有两种可用的模式,这些模式由 return_sequences 构造函数参数控制:
- 返回每个时间步骤的连续输出的完整序列(形状为 (batch_size, timesteps, output_features) 的 3D 张量)。
- 仅返回每个输入序列的最后一个输出(形状为 (batch_size, output_features) 的 2D 张量)。
代码如下:
- model = tf.keras.Sequential([
- tf.keras.layers.Embedding(encoder.vocab_size, 64),
- tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True)),
- tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
- tf.keras.layers.Dense(64, activation='relu'),
- tf.keras.layers.Dropout(0.5),
- tf.keras.layers.Dense(1)
- ])
-
- model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
- optimizer=tf.keras.optimizers.Adam(1e-4),
- metrics=['accuracy'])
-
- history = model.fit(train_dataset, epochs=10,
- validation_data=test_dataset,
- validation_steps=30)
执行后会输出:
- Epoch 1/10
- 391/391 [==============================] - 75s 192ms/step - loss: 0.6484 - accuracy: 0.5630 - val_loss: 0.4876 - val_accuracy: 0.7464
- Epoch 2/10
- 391/391 [==============================] - 74s 190ms/step - loss: 0.3603 - accuracy: 0.8528 - val_loss: 0.3533 - val_accuracy: 0.8490
- Epoch 3/10
- 391/391 [==============================] - 75s 191ms/step - loss: 0.2666 - accuracy: 0.9018 - val_loss: 0.3393 - val_accuracy: 0.8703
- Epoch 4/10
- 391/391 [==============================] - 75s 193ms/step - loss: 0.2151 - accuracy: 0.9267 - val_loss: 0.3451 - val_accuracy: 0.8604
- Epoch 5/10
- 391/391 [==============================] - 76s 194ms/step - loss: 0.1806 - accuracy: 0.9422 - val_loss: 0.3687 - val_accuracy: 0.8708
- Epoch 6/10
- 391/391 [==============================] - 75s 193ms/step - loss: 0.1623 - accuracy: 0.9495 - val_loss: 0.3836 - val_accuracy: 0.8594
- Epoch 7/10
- 391/391 [==============================] - 76s 193ms/step - loss: 0.1382 - accuracy: 0.9598 - val_loss: 0.4173 - val_accuracy: 0.8573
- Epoch 8/10
- 391/391 [==============================] - 76s 194ms/step - loss: 0.1227 - accuracy: 0.9664 - val_loss: 0.4586 - val_accuracy: 0.8542
- Epoch 9/10
- 391/391 [==============================] - 76s 194ms/step - loss: 0.0997 - accuracy: 0.9749 - val_loss: 0.4939 - val_accuracy: 0.8547
- Epoch 10/10
- 391/391 [==============================] - 76s 194ms/step - loss: 0.0973 - accuracy: 0.9748 - val_loss: 0.5222 - val_accuracy: 0.8526
(10)开始进行测试,代码如下:
- sample_pred_text = ('The movie was not good. The animation and the graphics '
- 'were terrible. I would not recommend this movie.')
- predictions = sample_predict(sample_pred_text, pad=False)
- print(predictions)
-
-
- sample_pred_text = ('The movie was not good. The animation and the graphics '
- 'were terrible. I would not recommend this movie.')
- predictions = sample_predict(sample_pred_text, pad=True)
- print(predictions)
-
- plot_graphs(history, 'accuracy')
- plot_graphs(history, 'loss')
此时执行后的可视化效果如图4-5所示。
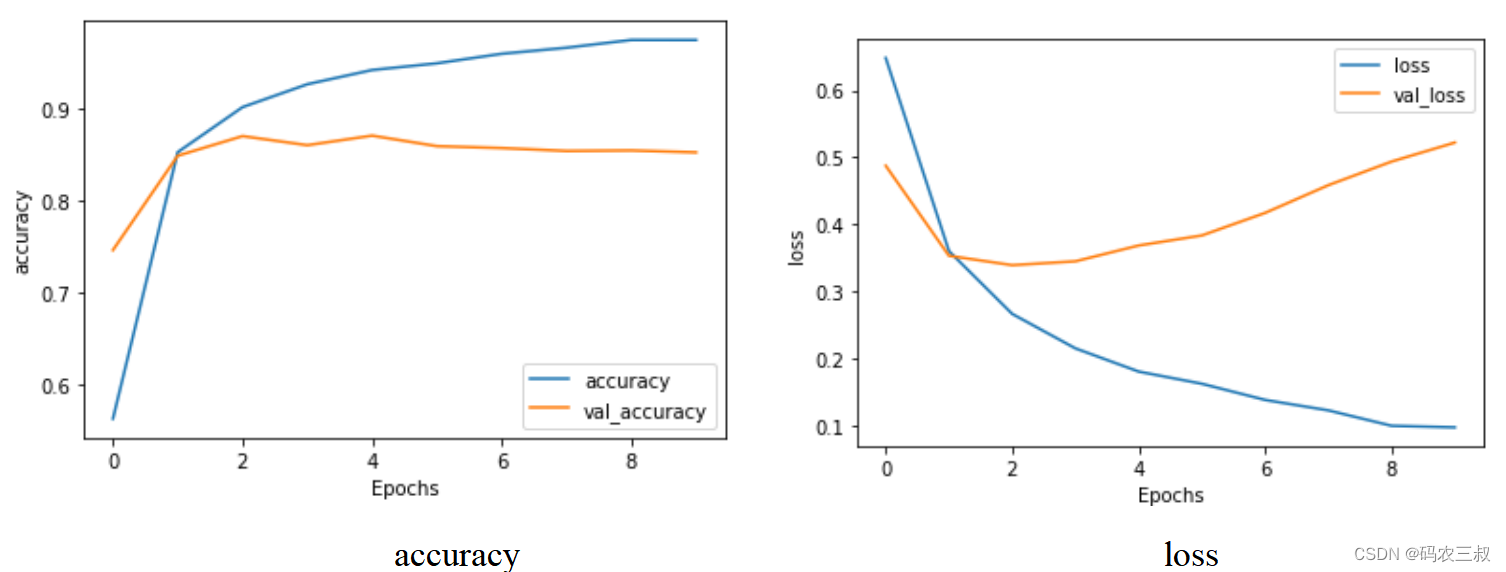
图4-5 可视化效果

