
- 1ShardingSphere 5.0.0 实现按月水平分表_shardingsphere按月分表
- 2【Spark】RDD入门编程实践(完整版)_rddfffffrrrdfffdrdrrrrddrdd4rrrrdrrrrrddrdrdrr4drd
- 3docker安装大数据环境(centos 7)_docker 安装大数据
- 4LeetCode14. 最长公共前缀_leet code 14
- 5Sora背后的技术原理解析(简单易懂版本)_sora技术原理
- 6git撤回已推送远程的提交_git撤回push到远程的
- 7Mac自带apache+php环境配置_mac自带apache开启伪静态
- 8TCP头部详解
- 9中缀表达式转化为后缀表达式 头歌--12关_头歌十二关本关任务:输入一个中缀算术表达式,将其转换为后缀表达式。运算符包括+
- 10JAVA17---安装+配置环境变量 JAVA安装完整教学_java 17安装
AIGC-音频生产十大主流模型技术原理及优缺点_ai音频生成技术
赞
踩
音频生成(Audio Generation)指的是利用机器学习和人工智能技术,从文本、语音或其他源自动生成音频的过程。
音频生成行业是AIGC技术主要渗透的领域之一。AI音频生成行业是指利用人工智能技术和算法来生成音频内容的领域。按照输入数据类型不同可以分为:根据文字信息、音频信息、肌肉震动及视觉内容等数据进行的声音合成;按照场景的不同,可以分为非流式语音生成和流式语音生成。根据应用领域的不同,可以将AI音频生成分为语音合成、音乐生成、语音识别三个领域。具体来说,语音合成技术主要应用于语音助手、语音广告、残障人士辅助工具等;音乐生成技术主要应用于音乐创作、游戏音效、电影配乐等领域;语音识别主要应用于语音搜索、智能客服、语音翻译等领域。其中,语音合成是该行业的主要应用领域,占据了近70%的市场份额。
决定音频生成效果的关键因素是生成速度、分词的准确程度、合成语音的自然度以及语音是否有多样化的韵律和表现力。
1、技术发展的关键阶段
- 早期的音频合成:采用规则式方法,通过预录制的音素片段组合生成语音,这种方法生成的语音生硬、缺乏自然流畅感。
- 参数化音频合成:引入参数化建模方法,使用数学模型描述语音信号,通过调整参数生成语音。这种方法提高了合成语音的自然度,但生成速度较慢。
- 统计音频合成:采用统计学习技术,通过机器学习训练模型自动学习语音规律,实现基于大量语音数据的语音合成,生成的语音更加自然流畅。
- 神经网络音频合成:利用深度神经网络强大的拟合能力,通过端到端的训练实现更高质量的语音合成。常见的网络结构有循环神经网络、变分自编码器、生成对抗网络等。
- 语音合成技术与其他领域融合:语音合成技术与机器翻译、情感计算、虚拟助手等领域技术深度融合,实现语音合成与语音交互、自然语言理解等功能的一体化。
- 多模态音频合成:实现语音与其他模式的结合,如文本、图像、视频等,实现语音与多模态信息的融合,丰富语音交互形式。
- 自适应音频合成:引入自适应机制,使语音合成系统能够根据用户反馈实时调整参数,实现个性化语音合成。
2、主流模型实现原理及优缺点
2.1 Tacotron系列(Google开源)
谷歌开发的Tacotron系列,主要用于文本到语音(TTS)的转换。这些模型基于端到端的序列到序列(Seq2Seq)架构,能够直接从文本中生成自然听起来的语音。Tacotron系列是基于神经网络的自回归语音合成模型,通过编码器-解码器结构,将文本转化为语音波形。Tacotron2引入了WaveNet作为解码器,提高了语音的自然度和质量。
2.1.1 技术原理及架构图
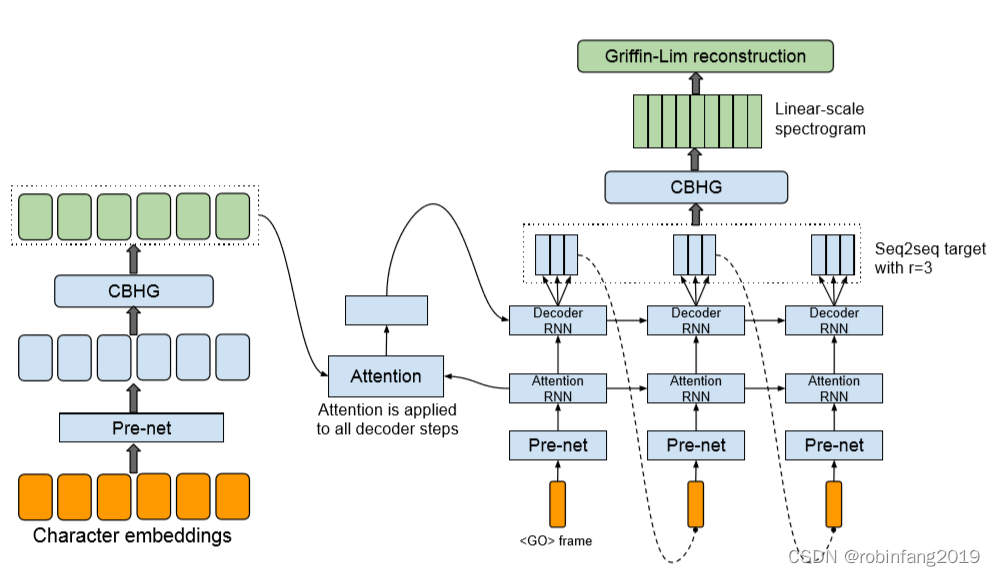
- Tacotron模型的核心是一个带有注意力机制的seq2seq模型。这意味着它可以处理输入的文本序列,并生成对应的语音特征,如声谱图。
- 在Tacotron模型中,首先使用一个编码器(encoder)来理解输入的文本数据,然后通过一个基于注意力的解码器(decoder)来预测或生成语音的声谱图。最后,通过后处理网络(post-processing network)进一步优化生成的声谱图,以便更好地反映实际的语音特征。
- Tacotron2引入了改进的WaveNet作为声码器,用于从预测的声谱图中生成时域波形样本,这使得模型在语音质量上有所提升。
2.1.2 优点及缺点
Tacotron系列模型,包括原始的Tacotron和其改进版本Tacotron2,是基于深度学习的端到端语音合成模型。
Tacotron系列优点:
端到端学习: Tacotron系列模型实现了从文本到语音的直接转换,无需复杂的特征工程,这简化了流程并减少了工程压力。
性能优越: 在frame-level合成语音方面,Tacotron系列模型表现出色,能够处理各种起始点的训练。
自然音质: 经过改良后,Tacotron2的输出非常接近人类的自然语音。
减少误差累积: 相对于传统系统,Tacotron通过避免多模块误差累计,提高了合成质量。
Tacotron系列缺点:
RNN的问题: 原始的Tacotron使用RNN模型,存在短期记忆和梯度消失的问题,这影响了信号合成效果。
端到端不彻底: 尽管Tacotron系列模型在很多方面表现出色,但仍有评论指出其端到端学习并不完全彻底,可能会影响最终的输出质量。
计算资源需求高: 虽然Tacotron可以直接将文本转换为语音波形,但Wavenet作为其组成部分,其训练过程需要大量的计算资源。
2.2 Transformer-TTS(Google开源)
Transformer-TTS利用Transformer的注意力机制,通过编码器-解码器结构实现语音合成。该模型相比Tacotron系列有更高的并行计算能力和更好的长距离依赖建模。
2.2.1 技术原理及架构图
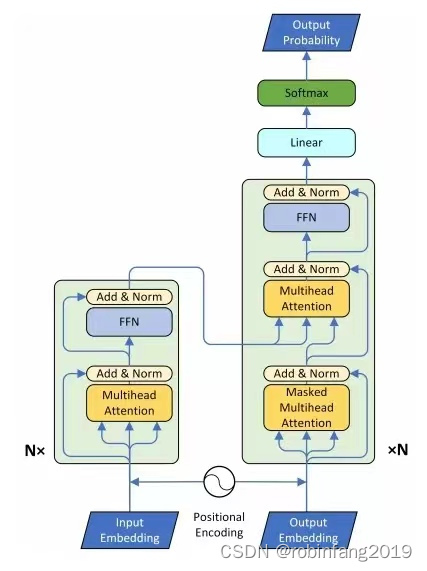
Transformer-TTS主要通过将Transformer模型与Tacotron2系统结合来实现文本到语音的转换。在这种结构中,原始的Transformer模型在输入阶段和输出阶段进行了适当的修改,以更好地处理语音数据。具体来说,Transformer-TTS利用自注意力机制来处理序列数据,这使得模型能够并行处理输入序列,从而提高训练效率。此外,Transformer-TTS还采用了自回归误差方法来优化模型性能。
2.2.2 优点及缺点
优点:
- 训练速度:与基于RNN的模型相比,Transformer-TTS显著提高了训练速度。这是因为Transformer允许并行处理输入序列,而不是依赖于逐步前向传播。
- 性能提升:在多个严格的真人测试中,Transformer-TTS显示出了最先进的性能。
- 并行训练:由于移除了RNN结构,Transformer-TTS可以实现真正的并行训练,这进一步加快了训练过程。
缺点:
- 生成质量问题:尽管Transformer-TTS在训练速度和性能上有所提升,但在某些情况下,其生成的语音质量可能不如其他一些模型。例如,与FastSpeech2相比,Transformer-TTS在生成效果上存在不足。
- 推理阶段的依赖性:虽然Transformer-TTS在训练阶段表现出色,但在推理阶段,它仍然需要依赖于先前生成的mel-spectrogram帧来生成当前时刻的输出,这可能限制了其灵活性和适应性。
2.3 FastSpeech系列(微软&浙大开源)
FastSpeech通过引入速度控制机制,实现快速可控的语音合成,同时保持了较高的语音质量。该模型通过预测语音持续时间,实现了快速的语音合成。
详见另外一篇文章:FastSpeech 2整体结构、模块配置及优化
2.4 Whisper(OpenAI开源)
OpenAI开发并开源的一个自动语音识别系统,主要用于将语音转换为文本。Whisper模型采用了Transformer序列到序列模型,这是一种深度学习技术,特别适合处理序列数据,如语音信号。在这个架构中,输入的音频被分割成30秒的片段,并转换为log-Mel频谱图,然后输入到编码器中。解码器则预测相应的文本标题,并使用特殊的令牌来指导单一模型执行任务。
2.4.1 技术原理及架构
Whisper自动语音识别系统的技术原理主要基于深度学习和神经网络技术。它通过训练大量的音频数据,让模型学习到从音频波形中提取语音特征的能力。具体来说,Whisper采用了编码器-解码器的架构,这是一种端到端的方法,可以直接将语音信号转化为文本。
2.4.2优点及缺点
优点
多语言支持:Whisper支持多种语言,包括但不限于98种语言,这使得它在跨语言交流和多语言应用场景中具有很大的优势。
高准确性:基于深度学习技术,Whisper展现出高准确性的语音识别能力。它已经在真实数据以及其他模型上使用的数据以及弱监督下进行了训练,显示出惊人的准确性。
多任务学习能力:Whisper不仅能执行语音识别,还能进行语音翻译和语言识别等多任务处理,这增加了其应用的灵活性和实用性。
缺点:
资源消耗:大规模的深度学习模型需要大量的计算资源,这可能导致运行成本较高。
对复杂环境的适应性问题:虽然Whisper在多种语言和复杂场景中表现出色,但在极端噪音或非标准发音的情况下,其准确率可能会受到影响。
依赖于大量标注数据:为了达到高准确率,Whisper需要在大规模的多样化音频数据集上进行训练,这意味着需要大量的人工标注工作。
局限于特定领域的应用:虽然Whisper的多语言支持使其在全球范围内有广泛的应用前景,但其性能可能在特定的行业或专业领域(如法律、医学)中需要进一步优化和调整。
2.5 WavLM(微软&Azure开源)
WavLM(WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing)是微软提出的一个大规模自监督预训练模型,主要用于全栈语音处理任务。该模型基于HuBERT框架构建,专注于口语内容建模和说话人身份保护。
2.5.1 技术原理及架构
架构基础:WavLM模型沿用了HuBERT的思想,并采用了Kmeans方法将连续信号转换成离散标签,这些标签作为模型训练的目标16。此外,WavLM遵循了wav2vec 2.0的设定。
预训练任务:在预训练阶段,WavLM同时进行掩码语音预测和去噪处理。这不仅保持了通过掩码语音预测来建模语音内容的能力,还通过语音去噪提高了模型在非ASR(自动语音识别)任务上的潜力。
特征提取与应用:WavLM引入了噪声合成声音,并预测掩码部分的标签。在保持与HuBERT和wav2vec2相当的ASR性能的同时,WavLM能够抽取通用的音频特征,这些特征可以应用于多种任务。
技术创新:WavLM还采用了门控相对位置偏差(gated relative position bias)来优化Transformer模型的性能,这有助于更好地处理序列数据中的位置信息。
数据和性能:WavLM在94,000小时无监督的英文数据上进行训练,并在多个语音相关的数据集上取得了最先进的成绩。该模型已经开源,并被集成到了Hugging Face等平台中。
2.5.2 WavLM优点及缺点
WavLM优点:
高效的自监督预训练:WavLM采用了大规模的自监督预训练方法,能够在没有人工标注的情况下,从大量未标记数据中学习到丰富的语音特征和知识2。
提升多种语音处理任务的性能:研究表明,WavLM在多个代表性的语音处理基准测试中表现出色,显著提高了各种语音处理任务的性能。特别是在低资源小语种的语音识别任务中,WavLM显示出了显著的优势。
适应性强:WavLM不仅适用于传统的语音识别任务,还能通过其框架“Denoising Masked Speech Modeling”扩展到17个不同的语音处理任务,显示出极好的通用性和适应性。
WavLM模型缺点:
依赖大量数据:虽然WavLM能够从大量数据中学习,但这也意味着它需要大量的数据来进行有效的预训练,这可能限制了其在数据稀缺环境中的应用。
局部关联问题:尽管WavLM能够生成包含内容信息和说话者信息的高维SSL特征,但这种方法可能导致模型过度关注局部特征,而忽视了整体语境中的重要信息。
人工标签的稀疏性:由于WavLM是基于自监督学习,其训练过程中依赖于大量未标记的数据。这就要求必须有足够的标记数据来进行微调,以确保模型能够准确地理解和执行具体任务。
2.6 文心ERNIE-SAT (百度部分开源)
百度自研的文心大模型的一个变体,专注于语音和语言的跨模态处理。该模型能够同时处理中文和英文,采用了语音-文本联合训练的方式,在多语言数据集上进行训练,使得合成的声音更加自然。
ERNIE-SAT模型的具体技术架构主要基于多任务学习策略,结合了跨语言和跨说话人的文本到语音转换技术。ERNIE-SAT模型在设计上采用了端到端的语音和文本联合预处理框架,这一框架能够联合学习语音和文本数据,从而提高模型在跨语言语音合成中的性能。
2.7 DeepVoice系列(百度未开源)
百度AI研发的一个高质量语音转文本系统,完全由深度神经网络构建。该系统的主要功能是将文本转换为语音,其技术原理基于深度学习,特别是在处理音素边界定位、字素到音素的转换、音素时长预测、基频预测和音频合成等方面。
2.8 AudioLM(Google未开源)
谷歌的AudioLM采用了语言建模的方法来处理音频数据。这个模型能够根据输入的音频片段或提示,生成与之风格一致的高质量音频内容。
AudioLM的核心技术包括两个主要的分词器:Soundstream和w2v-BERT。Soundstream用于计算声学标记,而w2v-BERT则用于计算语义标记。这种结合使得AudioLM不仅能捕捉到音频的细节,还能理解其背后的语义信息,从而生成连贯且具有长期一致性的音频输出。
2.9 Make-an-audio(浙大、北大及火山语音未开源)
浙江大学、北京大学和火山语音共同开发的一种先进的文本到音频生成系统。该模型能够将自然语言描述转换为音频输出,支持多种输入模态,如文本、音频、图像和视频。
Make-An-Audio模型的技术原理主要基于深度学习和文本到音频的生成技术。该模型通过分析大量的音效数据,学习音效的生成规则和特点,从而能够根据用户输入的简单文字描述自动生成相应的音效。
用户可以通过简单的操作在官方网站上输入文字描述,然后点击“生成”按钮来使用这个模型。模型会自动合成音效,并提供多种风格供选择。此外,该模型还展示了在客观和主观基准评估中的先进性能,特别是在对比语言-音频预训练(CLAP)表示方面表现突出。
2.10 SMART-TTS(科大讯飞 未开源)
科大讯飞研究院提出的一个语音合成框架,其核心原理在于将语音合成的学习过程进行模块化拆解,并通过预训练加强各个模块的学习能力。这种方法与传统的直接从文本到声学特征的学习方式不同,更加注重于模块间的协同和优化。
3、影响模型应用的关键因素
- 语音质量和自然度:高质量的语音是语音合成应用的关键要求,模型需要能够生成自然流畅的语音。
- 生成速度:实时或接近实时的语音合成速度对于交互式应用至关重要。生成速度较快的模型具有更好的交互性。
- 计算资源消耗:模型的计算资源消耗直接影响应用成本。资源消耗较少的模型具有更好的经济性。
- 训练数据需求:高质量语音的生成需要大量标注良好的训练数据。数据获取的难易程度直接影响模型效果。
- 模型大小和复杂度:模型大小和复杂度直接影响应用难度,较小的模型更容易部署到各种设备上。
- 场景适应性:不同的应用场景对语音合成有不同的要求,需要选择合适的模型以适应特定场景。
- 技术支持:模型的技术支持和维护也是应用的关键,直接关系到应用的稳定性和可持续性。
- 知识产权问题:在使用第三方模型时,需要关注潜在的知识产权问题,以避免法律纠纷。

