
- 1Nginx 安装 SSL 配置 HTTPS 超详细完整全过程_nginx 1.26.0 ssl
- 2Windows安装ElasticsSearch详细指南(亲测)_windows elasticsearch jdk
- 3动态代理更改Java方法的返回参数(可用于优化feign调用后R对象的统一处理)
- 4linux防黑工具,CCKiller:Linux轻量级CC攻击防御工具,秒级检查、自动拉黑和释放 (网摘)...
- 5智心顾问:为心智障碍家庭带来温暖与专业支持
- 6SQL如何快速备份/复制一张表(笔记)_sql怎么备份一张表
- 7代码实现springboot创建WebSocket服务端和网页客户端
- 8从头手搓一台ros2复合机器人(带机械臂)_ros机器手
- 9sql函数--08---REGEXP_REPLACE的使用方法_sql语句 regexp
- 10旗晟机器人人员行为监督AI智慧算法
Vivado使用(1)——综合的约束与策略_vivado 综合策略
赞
踩
目录
2.2.8 keep_equivalent_registers
2.2.10 control_set_opt_threshold
2.2.17 max_bram_cascade_height
2.2.18 max_uram_cascade_height
一、概述
综合是将寄存器传输级(RTL)描述的设计转换成门级表示的过程。Xilinx® Vivado® 综合是以时序为驱动的,针对内存使用和性能进行了优化。Vivado 综合支持以下硬件描述语言的可综合子集:
- SystemVerilog:符合 IEEE 标准的 SystemVerilog——统一硬件设计、规范和验证语言(IEEE Std 1800-2012)
- Verilog:符合 IEEE 标准的 Verilog 硬件描述语言(IEEE Std 1364-2005)
- VHDL:符合 IEEE 标准的 VHDL 语言(IEEE Std 1076-2002)
- 混合语言:Vivado 也支持 VHDL、Verilog 和 SystemVerilog 的混合使用
此外,Vivado 工具还支持基于行业标准的 Synopsys Design Constraints (SDC) 的 Xilinx® 设计约束(XDC)。XDC 使设计者能够精确地指定时钟定义、时序约束和其他设计参数,以优化综合结果和满足特定的性能要求。
通过使用 Vivado 综合工具,设计者可以:
- 分析和优化:自动分析 RTL 代码并优化逻辑以提高性能和降低资源使用
- 时序驱动的优化:基于时序约束进行优化,确保设计满足时钟频率和时序要求
- 资源优化:通过智能资源分配和重用减少 FPGA 上所需的逻辑和存储资源
- 支持多语言设计:支持使用多种硬件描述语言进行设计,提供灵活性以利用每种语言的特定优势
- 约束驱动的设计流程:使用 XDC 指定的设计约束来引导综合过程,实现特定的设计目标
Vivado 综合工具的这些特性使其成为针对 Xilinx FPGA 设计和优化的强大工具,帮助设计者实现复杂的数字设计,同时满足严格的性能和资源约束。
二、约束与策略
打开vivado设置中和综合相关的界面,可以看到如下情况:分成3个部分,分别是约束(Constraints)、报告(Report Options)和综合策略选项(Options)。这里我们主要关注约束和综合策略选项这两个部分。
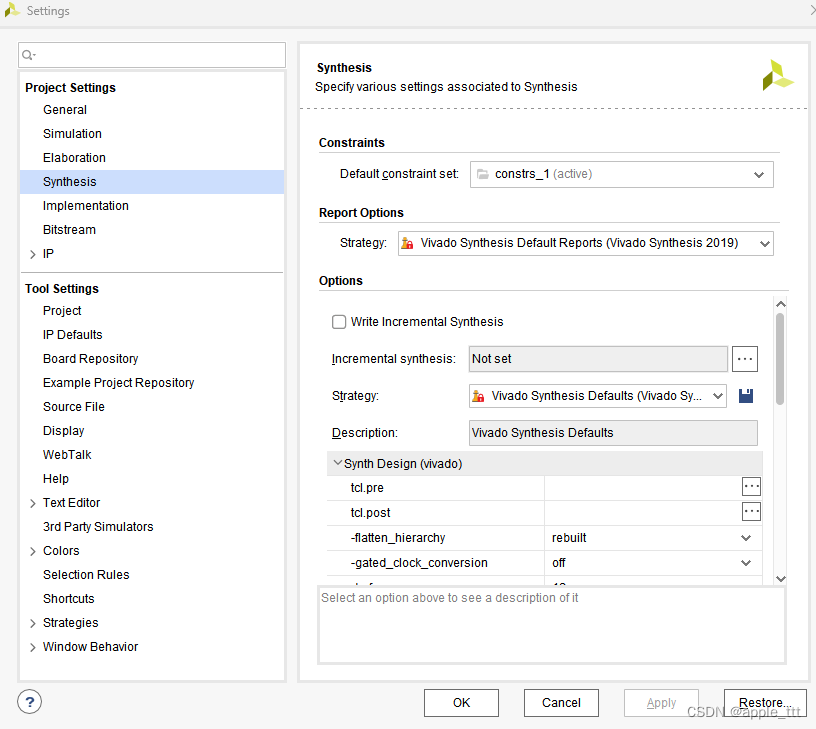
2.1 约束
在 Vivado 设计套件中,约束集是一组包含设计约束的文件,这些约束通过 Xilinx 设计约束(XDC)文件来捕获,并且可以应用到您的设计中。选择默认约束集作为活动约束集意味着这组约束将被用来引导和优化设计的综合和布局布线(Place & Route)过程。设计约束分为两类:
2.1.1 物理约束
物理约束定义了引脚布局以及单元格(如块 RAM、查找表(LUTs)、触发器(Flip-Flops)和设备配置设置)的绝对或相对布局。这类约束对于确保设计满足特定的物理实现要求非常重要,包括但不限于:
- 引脚位置:指定设计中的信号应该映射到 FPGA 芯片上的哪个引脚上。
- 单元布局:控制特定逻辑或存储单元在 FPGA 上的物理位置,可以是相对于其他元件的位置,也可以是绝对位置。
- 设备配置:设定 FPGA 设备的配置参数,如电源设置等。
2.1.2 时序约束
时序约束定义了设计的频率要求。在没有时序约束的情况下,Vivado 设计套件仅根据连线长度和布局拥挤度来优化设计。时序约束对于确保设计能够在目标频率下正常工作至关重要,包括:
- 时钟定义:指定设计中的时钟信号及其频率。
- 时钟域交叉:设置数据从一个时钟域传输到另一个时钟域的约束,以确保数据的稳定性和正确性。
- 输入/输出延迟:定义信号从外部世界进入 FPGA 或从 FPGA 输出到外部世界所允许的时间窗口。
- 假设和例外:指定设计中的某些路径可能不需要遵循普通的时序要求,例如多周期路径或禁止的路径。
通过在 Vivado 中正确设置和应用这些约束,设计者可以确保他们的设计满足既定的性能标准和物理实现要求,从而实现既高效又符合目标规格的 FPGA 设计。
2.2 综合策略
vivado运行设计者对于综合的策略进行部分定制。具体的可定制内容如下:
2.2.1 flatten_hierarchy
–flatten_hierarchy 是 Vivado 合成工具中的一个选项,用于控制设计层次结构的展平。层次结构展平是合成过程中的一个步骤,可以将设计中的模块和子模块展开为一个平面结构,而不是保持它们的原始层次结构。这个选项通常有几种设置,每种设置对合成结果和设计的可管理性有不同的影响:
- none:表示不展开层次结构,综合输出保留设计中的原有层次结构。
- full:表示全部展开层次结构,只留下顶层;
- rebuilt:表示综合工具展开层次结构后进行综合,综合后再按原始RTL重建层次结构。这样既保留了跨界优化的好处,又让最终层次结构与RTL类似,便于分析。
2.2.2 gated_clock_conversion
–gated_clock_conversion 是 Vivado 合成工具中的一个选项,用于控制门控时钟(gated clocks)到时钟使能(clock enable)信号的转换过程。门控时钟通常是通过在时钟路径上使用逻辑门(例如 AND 门或 OR 门)来动态控制时钟信号的传输,以减少功耗或实现特定的时序需求。然而,在 FPGA 设计中,过度使用门控时钟可能会导致时序分析复杂化,增加设计的难度,并可能影响性能。
使用 –gated_clock_conversion 选项,设计者可以指示合成工具将设计中的门控时钟结构转换为使用时钟使能信号的结构。这种转换的主要目的是简化时序分析和提高设计的可靠性,同时仍然实现减少功耗的目标。
2.2.3 bufg
在 Vivado 设计工具中,–bufg 选项实际上用于控制工具在设计中推断(或自动实例化)的全局缓冲器(BUFG)的数量。这个选项在综合过程中特别有用,尤其是当设计的网表中的其他 BUFG 对综合工具不可见时。通过使用这个选项,设计者可以指导综合工具在必要时自动添加 BUFG 实例,以确保全局时钟和关键信号在 FPGA 内部得到适当的分配。
假设 –bufg 选项被设置为 12,而在 RTL 中已经实例化了三个 BUFG,综合工具将推断最多九个额外的 BUFG。这意味着综合工具会根据需要和可用资源,自动在设计中添加最多九个 BUFG 实例,以确保时钟和其他关键信号的有效分配。
使用 –bufg 选项时,设计者需要了解自己设计中的时钟需求和全局信号的分布情况。虽然综合工具能够自动推断 BUFG 的使用,但是合理的设计和约束指定依然是确保设计成功的关键。例如,在 Vivado 的 TCL 脚本或合成命令中指定 –bufg 选项,可以帮助控制全局缓冲资源的使用,但这需要与设计的实际时钟架构和性能要求相匹配。
2.2.4 fanout_limit
设置一个信号的最大驱动负载数量,如果超出了该限制,就会复制一个相同的逻辑来驱动超出的负载。
2.2.5 directive
这个选项替代了之前的 effort_level 选项。通过指定不同的优化级别,它控制 Vivado 合成执行不同的优化策略。
- Default:默认设置,提供平衡的优化策略。
- RuntimeOptimized:执行最短时间的优化选项,会忽略一些RTL优化来减少综合运行时间。
- AreaOptimized_high/medium:执行一些通用的面积优化。
- AlternateRoutability:使用算法提高布线能力,减少MUXF和CARRY的使用。
- AreaMapLargeShiftRegToBRAM:将大型的移位寄存器用块RAM来实现。
- AreaMultThresholdDSP:会更多地使用DSP块资源。
- FewerCarryChains:位宽较大的操作数使用查找表(LUT)实现,而不用进位链。
2.2.6 retiming
重定时(Retiming)是一种强大的逻辑优化技术,它在不改变电路原有功能和延迟的前提下,通过在组合逻辑和查找表(LUT)之间移动寄存器来优化电路的性能。这项技术的主要目的是改善内部时钟的时序路径,从而提高电路的工作频率或减少所需的资源。
重定时通过以下方式改善电路性能:
- 减少关键路径延迟:通过将寄存器从组合逻辑区域的一端移动到另一端,可以减少关键时序路径上的逻辑延迟,从而提高电路的工作频率。
- 寄存器平衡:通过智能地重新分布寄存器,以平衡电路中的寄存器分布,这有助于均匀地分配时延,提高时钟频率和电路的稳定性。
- 提高性能:可以显著提升设计的最大工作频率,使电路能够在更高的时钟速率下稳定工作。
- 节省资源:在某些情况下,通过重定时可以减少总体所需的寄存器数量,从而节省 FPGA 内的资源。
- 无需修改 RTL 源文件:重定时是在综合阶段进行的优化,不需要手动修改 RTL 代码,这使得它成为提高电路性能的一个低成本且高效的方法。
2.2.7 fsm_extraction
这个选项控制合成过程中有限状态机(FSM)的提取和映射方式。可以通过不同的编码策略来优化 FSM 的实现。
Vivado 的 –fsm_extraction 选项通常包括以下几种设置:
- None:不执行 FSM 提取。这意味着设计中的状态机将不会被作为特殊结构识别和优化。
- Auto(默认):合成工具自动识别和提取 FSM,然后根据内部算法优化它们。这个选项旨在平衡性能和资源使用,适用于大多数情况。
- Onehot、Sequential、Gray、Johnson 等:这些值指示合成工具使用特定的状态编码方式。选择合适的编码方式对于减少所需的逻辑资源和优化性能至关重要。
FSM 编码方式如下:
- Onehot:每个状态由一个单独的寄存器位表示,适用于状态转换简单的 FSM,可以减少状态解码逻辑,但可能会增加寄存器使用。
- Sequential(二进制编码):状态以二进制形式编码,这种方式在状态数较多时节省寄存器,但可能需要更复杂的状态转换逻辑。
- Gray:状态以格雷码(Gray code)编码,每次状态转换只改变一个位,有助于减少状态转换时的瞬态错误。
- Johnson:采用约翰逊计数器编码方式,状态转换时位的变化是循环的,适用于特定的应用场景。
2.2.8 keep_equivalent_registers
防止具有相同输入逻辑的寄存器被合并。这对于保持设计中特定的寄存器结构可能很有用,例如,当需要保留特定的时序或功能行为时。
2.2.9 resource_sharing
设置不同信号之间算术运算符的共享策略。
- auto:根据设计的时序自动决定是否进行资源共享。
- on:始终开启资源共享。
- off:始终关闭资源共享。
2.2.10 control_set_opt_threshold
control_set_opt_threshold 用于设置触发优化的控制集数量的阈值。控制集通常指的是共享相同的时钟、复位、使能信号集合的一组寄存器。这个选项影响的是时钟使能优化,特别是在处理寄存器的 D 逻辑时的行为。
control_set_opt_threshold 的主要目的是优化 FPGA 设计中的时钟使能逻辑。在特定阈值以下,合成和实现工具将尝试将控制信号集成到寄存器的 D 逻辑中,以减少所需的控制集数量。这种优化可以减少所需的资源并可能改善时序性能。
2.2.11 no_lc
当选中此选项时,关闭查找表(LUT)组合。这可以防止合成工具在尝试减少 LUT 使用时合并 LUT,可能用于特定的设计约束或优化目的。
2.2.12 no_srlextract
选中该选项时,移位寄存器会用普通的寄存器实现,而不用FPGA内部专用的SRL资源。
2.2.13 sherg_min_size
sherg_min_size选项用于设置在合成过程中考虑进行移位寄存器优化的最小触发器链长度。这个选项允许用户定义一个阈值,只有当触发器链的长度达到或超过这个阈值时,合成工具才会尝试将这些触发器优化为移位寄存器(Shift Register LUT, SRL)。这种优化可以减少资源消耗,并可能提高性能。
2.2.14 max_bram
设置设计中运行使用的最大块RAM数量。通常当设计中有黑盒子或第三方网表时,使用该选项来节省空间。默认值为-1,表示允许使用该FPGA中所有的块RAM。
2.2.15 max_uram
设置设计中运行使用的最大UltraRAM数量(对于UltraScale架构FPGA而言)。-1,表示允许使用该FPGA中所有的UltraRAM。
2.2.16 max_dsp
设置设计中运行使用的最大DSP块数量。通常当设计中有黑盒子或第三方网表时,使用该选项来节省空间。默认值为-1,表示允许使用该FPGA中所有的DSP资源。
2.2.17 max_bram_cascade_height
设置可以将BRAM级联在一起的最大数量。BRAM 级联是指在 FPGA 设计中串联多个 BRAM 单元以形成更大的存储结构的技术。这种串联可以提高存储效率和访问速度,但也可能增加信号传播延迟和资源消耗。
2.2.18 max_uram_cascade_height
设置可以将URAM级联在一起的最大数量。
2.2.19 cascade_dsp
设置在求DSP块输出总数时使用多少个加法器,默认计算时会使用块内部的加法器链。设置为tree会强制将该计算在fabric结构中实现。
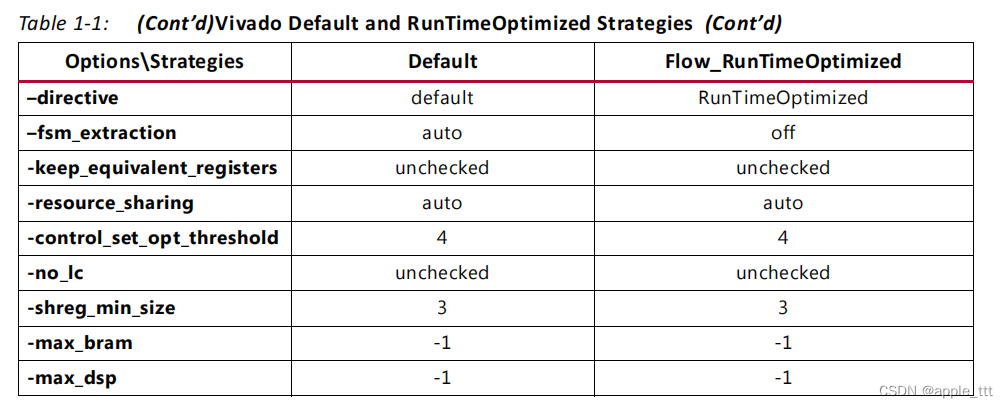
对于综合来说,很多时候设计者不会考虑这么多,因此vivado给出了一些默认的设置:

三、控制文件编译顺序
在 Vivado IDE 中,处理源文件的编译顺序是很重要的,尤其是当一个文件依赖于另一个文件中的声明时。为了确保依赖关系得到正确处理,编译顺序必须精确控制。幸运的是,Vivado 工具能够自动识别最佳的顶层模块候选,并自动管理编译顺序。这意味着顶层文件和所有在活动层次结构下的源文件都会以正确的顺序传递给综合和仿真。
3.1 自动更新与编译顺序
Vivado 的默认设置,“自动更新和编译顺序”(Automatic Update and Compile Order),允许工具自动管理编译顺序,并在“层次结构”(Hierarchy)窗口中显示哪些模块被使用以及它们在层次树中的位置。当你更改源文件时,编译顺序会自动更新。
3.2 如何在综合前修改编译顺序
如果需要在综合前手动指定编译顺序,可以按照以下步骤操作:
- 设置“层次结构更新”(Hierarchy Update)> “自动更新,手动编译顺序”(Automatic Update, Manual Compile Order),这样 Vivado IDE 会自动确定设计的最佳顶层模块,并允许手动指定编译顺序。
- 在“源文件”(Sources)窗口的弹出菜单中,可以通过拖放文件在“编译顺序”(Compile Order)窗口中排列编译顺序,或使用“上移”(Move Up)或“下移”(Move Down)命令调整文件顺序。

