
- 1深入浅出Python日志打印_python 打印日志
- 2永恒之蓝 (EternalBlue) 漏洞利用原理详解_永恒之蓝漏洞
- 3直播系统开发之对接微信支付sdk流程_微信支付sdk干嘛的
- 4【IEEE出版】第六届电子与通信,网络与计算机技术国际学术会议(ECNCT 2024,7月19-21)_2024 ecnct
- 5Seata 中XA,AT模式浅析_xa at
- 6这是一份简单到没朋友的上手图数据库的图文教程_图数据库怎么访问
- 7性能巅峰对决:Rust vs C++ —— 速度、安全与权衡的艺术_rust语言和c++性能
- 8Mybatis 标签大全及标签中各属性详解_写出10个mybatis中mapper配置文件的标签
- 9git远程分支与本地分支合并_git合并本地分支 与远程分支
- 10网络安全工程师入门教程,从零基础入门到精通,看完这一篇就够了~_网络工程师教学csdn
python 操作Excel入门到进阶_python excel文件操作
赞
踩
目录
openpyxl:不需要 打开Excel 进程,仅支持xlsx、xlsm文件进行读、写操作
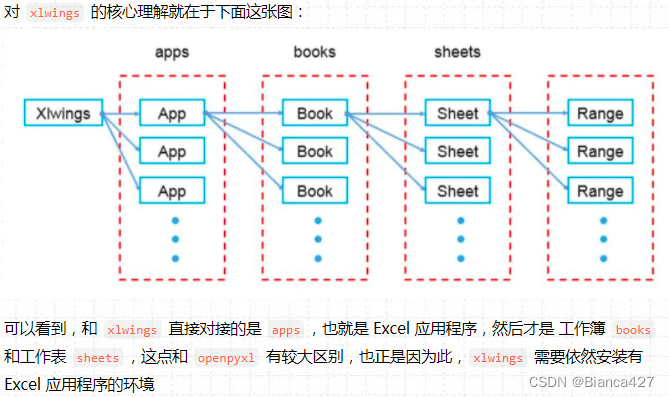
xlwings:需要安装并打开 Excel 进程,支持 xls 和 xlsx 格式;可以调用 Excel 文件中 VBA 写好的程序;和 matplotlib 以及 pandas 的兼容性强
xlrd:可以对xlsx、xls、xlsm文件进行读操作且效率高
xlwt:主要对xls文件进行写操作且效率高,但是不能执行xlsx文件
openpyxl操作Excel
注意:openpyxl索引从1开始
读取工作簿(公式)
- import openpyxl
- # 实例化,此步可忽略
- wb = openpyxl.Workbook()
- # 读取指定文件
- wb = openpyxl.load_workbook('新工作簿.xlsx')
-
- # 读取的是公式(data_only默认为False,可不写):
- wb = openpyxl.load_workbook(filename, data_only=False)
-
- #data_only=True读取的是公式计算值:
- wb = openpyxl.load_workbook(filename, data_only=True)
保存工作簿
wb.save('新工作簿.xlsx')写入内容
- from openpyxl import load_workbook
- wb=load_workbook(r"D:\data\新工作簿.xlsx")
- ws=wb.active
- ws.cell(1,2).value="写入内容"
- wb.save("新工作簿.xlsx")
-
- #ws=wb["表名字"]
表(sheet)
创建表
- # 插入到最后
- ws1 = wb.create_sheet('工作簿1')
- # 插入到最开始的位置 create_sheet(表名,位置)
- ws2 = wb.create_sheet('新工作表',0)
选择表(sheet)
- # 当前活动的工作表
- sh1 = wb.active
- sh2 = wb['新工作表']
- sh3 = wb.get_sheet_by_name("新工作表")
查看表名、工作簿名
- # 显示所有表名
- print(wb.sheetnames)
- # 打印指定表名
- print(wb.sheetnames[0])
- # 遍历所有表
- for sheet in wb:
- print(sheet.title)
-
- # 查看当前工作簿名
- ws.title
查看
删除工作表
- # 方法一
- sh.remove(sheet)
- # 方法二
- del sh['新工作表']
修改表名称(重命名)
sh2.title="new_sheet_name"复制工作表
Workbook.copy_worksheet(表名) 方法:复制整个表作为副本,包含单元格(包括值、样式、超链接和注释)和某些工作表属性(包括尺寸、格式和属性)。不复制所有其他工作簿/工作表属性-例如图像、图表。
- wb = openpyxl.load_workbook("原文件.xlsx")
- ws = wb.active
- target = wb.copy_worksheet(ws) # 复制整个工作簿 + 1(ws)
- wb.save("新文件.xlsx")
单元格(cell)
获取表格尺寸大小
返回excel表格中数据有几行几列
sh.dimensions # 返回A1:G10
单元格访问
- cell = sh["A1"] # 返回<Cell '新工作表'.A1>
-
- # 获取单元格的数据
- sh["A1"].value
- sh.cell(row=1,column=1).value
多单元格访问
- # 指定坐标范围的值
- r1 = sh["A1:C3"]
-
- # 指定列的值
- c1 = sh['B']
- c2 = sh['A:C']
-
- # 指定行的值
- r2 = sh[10]
- r3 = sh[1:10]
-
- # 输出每个单元格的值
- for cell in r1:
- print(cell.value)
-
- # 通过指定范围
- # 方法一:(获取A1:B2的值)
- for row in sh.iter_rows(min_row=1,max_row=2,min_col=1,max_col=2):
- print(row) # 返回 (<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>)
- for cell in row:
- print(cell.value)
- # 方法二:(获取A2:A~的值)
- for row in range(2,sh.max_row+1):
- for col in range(1,2):
- cell = sh.cell(row=row,column=col)
- print(cell.value)
-
- # 简写获取矩阵值
- r = ws["B2:N18"]
- values = [[cell.value for cell in row] for row in r]
-
- # 读取所有的行
- for row in sh.rows:
- print(row) # 返回迭代器
-
- # sh.rows/sh.columns 所有行/列的迭代器,可通过循环获取
- # 读取所有的行的值
- for row in sh.rows:
- print(row) # 返回迭代器
- for cell in row:
- print(cell.value) # 返回单元格的值
- # 读取所有的列的值
- for column in sh.columns:
- for cell in column:
- print(cell.value)

写入单元格
- # 方法一
- sh.cell(row, colum).value = 新的值 # 修改单元格的数据
-
- # 方法二:row 行;column 列 value 值
- sh.cell(row=2,column=3,value=10)
-
- sh['B10'] = '=SUM(B1:B9)' # 将公式写入单元格
根据特定文本查找行列号
- from openpyxl import load_workbook
-
- def find_row_by_char(file_path,sheet_name,char):
- # 加载工作簿和工作表
- workbook = load_workbook(file_path)
- sheet = workbook[sheet_name]
-
- # 遍历工作表中的所有行
- for row in sheet.iter_rows():
- for cell in row:
- if char in cell.value:
- return cell.row # cell.column返回列号
- return None # 如果没有找到字符,返回None
-
- # # 使用示例
- file_path = 'example.xlsx' # Excel文件路径
- sheet_name = 'Sheet1' # 工作表名称
- char_to_find = '撤销原因' # 要查找的字符
- row_number = find_row_by_char(ds_低保,char_to_find)
- if row_number:
- print(f'字符找到在第{row_number}行')
- else:
- print('字符未找到')
append写入一行或多行数据
1、append是按行向Excel中追加数据,从当前行的下一行开始追加,默认从第一行开始
2、append的数据类型必须是list,tuple,dict
sheet.append(列表) :追加写入
- sh = wb['sheet']
- data1 = ['王俊凯',23,'歌手'] # 一行写入
- sh.append(data1)
批量写入需循环
- sh = wb['sheet']
- data1 = [['王俊凯',23,'歌手'],
- ['杨幂',33,'演员'],
- ['杨紫',29,'演员']]
- for i in data1:
- sh.append(i)
指定位置插入:表._current_row=行数
- ws._current_row=20 # 将当前行指定在20行
- ws.append([1,2,3]) # 1,2,3将插入21行的A,B,C列
append的数据类型(list,tuple,dict)
如果数据是dict,那keys所对应的value只能是一个str/number,不能是list/tuple/dict
- x = [1,2,3,4,5]
- y = (6,7,8,9,10)
- z = {'A':11,'B':12,'C':13,'F':"aaa"}
- m = {'A':['a','b','c'],'B':['c','d','e'],'C':['f','g','h']} # 无效操作
- ws.append(x)
- ws.append(y)
- ws.append(z)
- # ws.append(m) # 此处报错

指定行列插入,利用dict(作用不大相当于ws.cell(行,列).value=)
- ws._current_row = 2
- z = {'A':11,'C':12,'E':13,'G':"aaa"}
- ws.append(z)

Python 处理数据(Excel)—— openpyxl 之append - 知乎
写入一列
将列表写入excel第一列
- l = ['张三', '李四', '王五', '赵六']
- for each in l:
- print(l.index(each))
- # 通过row关键字指定行,colunm关键字指定列,均从1开始
- # 列表从0开始,单元格从1开始
- ws.cell(row=l.index(each) + 1, column=1, value=each)
插入一行或多行
在idx行上面插入一行
- sh = wb['sheet']
- sh.insert_rows(idx=2)
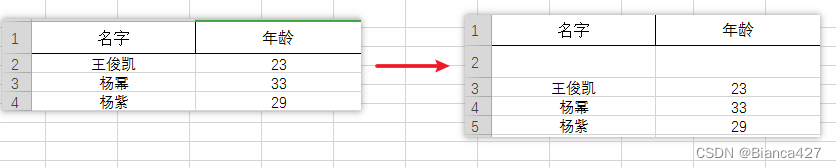
在idx行上面插入多行(amount=4插入4行)
- import openpyxl
- wb = openpyxl.load_workbook(r'E:\测试表.xlsx')
- sh = wb['sheet']
- sh.insert_rows(idx=2,amount=4)
- wb.save(r'E:\测试表.xlsx')
插入一列或多列
在idx列左边插入多列(amount=3插入3列)
- import openpyxl
- wb = openpyxl.load_workbook(r'E:\测试表.xlsx')
- sh = wb['sheet']
- sh.insert_cols(idx=2)
- sh.insert_cols(idx=4,amount=3)
- wb.save(r'E:\测试表.xlsx')
删除多行/列
- sh = wb['sheet']
- sh.delete_rows(idx=2)
- sh.delete_rows(idx=2,amount=2) # 从第二行开始删除两行
- sh.delete_cols(idx=2,amount=3) # 删除三列
移动范围数据
向下移动两行,向左移动两列
- sh = wb['sheet']
- sh.move_range('C1:D1',rows=2,cols=-2)

获取单元格的行数、列数、坐标
- # 获取A1单元格的行、列、坐标
- cell = sh['A1']
- print(cell.row, cell.column, cell.coordinate) #返回 1 1 A1
获取最大行/列号
- max_row = ws.max_row #行数
- max_col = ws.max_column#列数
-
- # 求A列最大行数
- max_row_A = max((a.row for a in day_book['A'] if a.value))
合并和拆分单元格
- sh.merge_cells("A1:C3") #合并一个矩形区域中的单元格
- sheet.merge_cells(start_row=1, start_column=3,
- end_row=2, end_column=4) # 合并c1:d2
-
- sh.unmerge_cells("A1:C3") # 拆分单元格
- sheet.unmerge_cells(start_row=1, start_column=3,
- end_row=2, end_column=4)
指定删除单元格(行/列)
- sh.delete_cols(3,5) # 删除从3~5列的内容
- sh.delete_rows(2,7) # 删除从2~7行的内容
写入图片
- from openpyxl.drawing.image import Image
- # 实例化图片对象 Image(接收图片)
- img = Image('图片1.jpg')
- # 指定单元格添加图片
- sh.add_image(img,"B3")
- wb.save('新工作簿.xlsx')
获取整行数据
values获取该表所有值,通过行索引获取整行
- # 获取所有表
- for sh in wb.sheetnames:
- max_row = wb[sh].max_row # 最大行数
- max_col = wb[sh].max_column # 最大列数
- # 方法一
- values = list(wb[sh].values) # 获取该表所有值
- # 方法二
- # 循环每行
- for i in range(2,max_row+1):
- for j in range(1,max_col+1):
- # 获取单元格的值
- value = wb[sh].cell(i, j).value
- # 符合条件整行添加到新表中
- if value == filename:
- wb1['查找'].append(values[i-1])
单元格写入公式
大部分公式可直接复制
- # 获取B列最大的行号
- max_row_B = max((b.row for b in ws['B'] if b.value))
- # 循环写入公式
- for i in range(3,max_row_B+1):
- # 售
- sum_formula = f"=SUM(J{i}:AN{i})"
- #sum_formula2 = f"=SUM(D{i}:I{i},-AO{i})"
- ws.cell(row=i,column=41,value=sum_formula)
-
- # 公式引用F3:F最大行号
- ws.cell(max_row+1,6).value = f"=SUM(F{3}:F{i})"
openpyxl样式调整
可指定单元格范围设置样式,需循环两次(第一次迭代,第二次单元格)
设置字体样式
Font(name字体名称,size大小,bold粗体,italic斜体,color颜色)
- import openpyxl
- from openpyxl.styles import Font
- wb = openpyxl.load_workbook(r'E:\测试表.xlsx')
- sh = wb['sheet']
- cell = sh['B1']
- font = Font(name='微软雅黑',size=12,bold=True,italic=True,color='FF0000')
- cell.font = font
- wb.save(r'E:\测试表.xlsx')
设置对齐样式
Alignment(horizontal水平对齐,vertical垂直对齐,text_rotation字体倾斜度,wrap_text自动换行)
- import openpyxl
- from openpyxl.styles import Alignment
- wb = openpyxl.load_workbook(r'E:\测试表.xlsx')
- sh = wb['sheet']
- cell = sh['B1']
- alignment = Alignment(horizontal='center',vertical='center',
- text_rotation=45,wrap_text=True) # 倾斜可删text_rotation
- cell.alignment = alignment
- wb.save(r'E:\测试表.xlsx')
-
水平对齐:
distributed, justify, center, left, fill, centerContinuous, right, general -
垂直对齐:
bottom, distributed, justify, center, top
设置边框样式
- import openpyxl
- from openpyxl.styles import Side,Border
- wb = openpyxl.load_workbook(r'E:\测试表.xlsx')
- sh = wb['sheet']
- cell = sh['A1:D4']
- side = Side(style='thin',color='FF000000')
- border = Border(left=side,right=side,top=side,bottom=side)
- for i in cell:
- for j in i:
- j.border = border
- wb.save(r'E:\测试表.xlsx')
-
边线样式:
double, mediumDashDotDot, slantDashDot, dashDotDot, dotted, hair, mediumDashed, dashed, dashDot, thin, mediumDashDot, medium, thick
设置单元格填充样式
- import openpyxl
- from openpyxl.styles import PatternFill,GradientFill
- wb = openpyxl.load_workbook(r'E:\测试表.xlsx')
- sh = wb['sheet']
- cell1 = sh['A1']
- cell2 = sh['B1']
- # 单色填充
- pattern_fill = PatternFill(fill_type='solid',fgColor="99ccff")
- cell1.fill = pattern_fill
- # 渐变填充
- gradient_fill = GradientFill(stop=('FFFFFF',"99ccff","000000"))
- cell2.fill = gradient_fill
- wb.save(r'E:\测试表.xlsx')
设置行高和列宽
- import openpyxl
- # from openpyxl.styles import PatternFill,GradientFill
- wb = openpyxl.load_workbook(r'E:\测试表.xlsx')
- sh = wb['sheet']
- # 可循环
- sh.row_dimensions[1].height = 30
- sh.column_dimensions["C"].width = 20
- wb.save(r'E:\测试表.xlsx')
设置格式(常规,文本,自定义,日期)
- from openpyxl.styles import numbers
-
- # 设置为”常规“格式
- ws.cell(1, 4).number_format = 'General'
- # 设置为“文本”格式
- ws.cell(1, 4).number_format = '@'
- # 设置为“自定义”格式中的“0.00” 比如:100 转换为100.00
- ws.cell(1, 4).number_format = '0.00'
- # 设置为“自定义”格式中的“0”
- ws.cell(1, 4).number_format = '0'
- # 一列设置“日期”格式
- for cell in ws["A"]:
- cell.number_format = 'yyyy-mm-dd'
具体可参考:openpyxl.styles.numbers — openpyxl 3.1.2 documentation
设置日期格式
- from openpyxl.styles import numbers
-
- ws['A1'] = datetime.date(2021, 2, 13)
- ws['A1'].number_format = 'yyyy/m/d'
-
- # 设置一列
- for cell in ws["A"]:
- cell.number_format = numbers.FORMAT_DATE_YYYYMMDD2
-
- # 在B列写入并设置日期格式
- dates = ["2023-11-29","2023-11-30","2023-12-01"]
- for i,date_str in enumerate(dates,start=1):
- ws.cell(row=i,column=2,value=datetime.strptime(date_str,"%Y-%m-%d"))
-
没啥用的方法
根据数据得到字母,根据字母得到数字
- from openpyxl.utils import get_column_letter,column_index_from_string
- # 未知用处
- # 根据列的数字返回字母
- print(get_column_letter(2)) # B
- # 根据字母返回列的数字
- print(column_index_from_string("d")) # 4
openpyxl案例:

评论区自取文件
1、拆分表格
将人员以各部门进行区分(J列)单独提取出来的信息(人员所有信息)插入新的sheet页
- import openpyxl
- wb = openpyxl.load_workbook(r'E:\课件\人员信息表待筛选.xlsx')
- sheetnames = wb.sheetnames # 返回列表
-
- department_list = []
- # 筛选部门
- for sheetname in sheetnames:
- ws = wb[sheetname]
- max_row = ws.max_row # 最大行数
- # range不包含最后一位数
- for row in range(2,max_row+1):
- department = ws.cell(row,10).value
- if "[" in department:
- department = department.replace('[','_')
- if "]" in department:
- department = department.replace(']','')
- if department not in department_list:
- department_list.append(department)
- # 获取标题
- title = list(wb['Sheet1'].values)[0]
-
- # 创建工作簿
- wb2 = openpyxl.load_workbook(r'E:\课件\建表测试.xlsx')
- for table in department_list:
- # 创建工作簿
- wb2.create_sheet(table)
- # 添加标题
- wb2[table].append(title)
-
- # 拆分数据
- for sheetname in sheetnames:
- ws = wb[sheetname]
- max_row = ws.max_row
- values = list(ws.values)
- for row in range(2,max_row+1):
- content = ws.cell(row,10).value
- if "[" in content:
- content = content.replace('[','_')
- if "]" in content:
- content = content.replace(']','')
- wb2[content].append(values[row-1])
- wb2.save(r'E:\课件\建表测试.xlsx')
2、提取信息
将工作证(O列)包含字母的证件号人员信息单独提取插入新的sheet页
- import string
- import openpyxl
- wb = openpyxl.load_workbook(r'D:\星越\办公自动化课件\人员信息表.xlsx')
- # 当前工作簿中创建工作表
- wb_card = wb.create_sheet("工作证")
- # print(wb.sheetnames)
- # 添加标题
- wb_card.append(list(wb['Sheet1'].values)[0])
- # 循环所有表
- for sheetname in wb.sheetnames:
- # 该表所有值
- value = list(wb[sheetname].values)
- # 最大行号
- max_row = wb[sheetname].max_row
- # range不包含max_row得+1
- for row in range(2,max_row+1):
- cell = str(wb[sheetname].cell(row, 15).value)
- # 循环获得每一个字符
- for letter in cell:
- # 得到的字符判断是否包含英文,包含添加并跳出循环
- if letter in string.ascii_lowercase:
- # value为列表,当row为2时,需要取得是value的1,所以需减1
- wb_card.append(value[row-1])
- # 当循环遇到字母就跳出
- break
- wb.save(r'D:\星越\办公自动化课件\人员信息表.xlsx')
3、查找字符串
多层级查找包含杨幂字符串的excel表格返回路径和单元格(openpyxl只支持xlsx,xlsm)
- import glob
- import openpyxl
- path = r"C:\Users\Administrator\Desktop\办公自动化"
- for file in glob.glob(path + "/**",recursive=True):
- suffix = file.split('.')[-1]
- if suffix == 'xlsx' or suffix == 'xlsm':
- wb = openpyxl.load_workbook(file)
- # 获取所有表
- for sh in wb.sheetnames:
- max_row = wb[sh].max_row # 最大行数
- max_col = wb[sh].max_column # 最大列数
- values = list(wb[sh].values) # 获取该表所有值,返回list
- # 方法一
- # if "杨幂" in str(values):
- # print(file)
- # 方法二
- # 循环每行
- for i in range(1,max_row+1):
- for j in range(1,max_col+1):
- # 获取单元格的值
- value = wb[sh].cell(i, j).value
- if "杨幂" in str(value):
- print('{}.cell({},{});路径:{}'.format(sh,i,j,file))
- wb.close() # 必须关闭
4、汇总
汇总表仅有5行标题,多表数据写入汇总表
- import openpyxl
- wb = openpyxl.load_workbook('汇总数据.xlsx')
-
- for sheet in wb:
- sh=wb[sheet.title]
- max_row_B = max((b.row for b in sh['B'] if b.value))
- for i in range(5,max_row_B+1):
- l = [] # 存储行数据
- if sh.cell(i,2).value is None and sh.cell(i,3).value is None:
- continue
- else:
- for j in range(1,23):
- data = sh.cell(i,j).value
- l.append(str(data))
- wb['汇总'].append(l)
-
- wb.save('text.xlsx')
- wb.close()
xlwings操作Excel
pip install xlwings
打开Excel程序
使用app打开Excel进程
- import xlwings as xw
- app = xw.App(visible=True,add_book=False) # 程序可见,只打开不新建工作簿
- app.display_alerts = False # 警告关闭
- app.screen_updating = False # 屏幕更新关闭
保存、退出、关闭
xlwings依赖于(app)Excel进程,结束需要关闭(app)
- import xlwings as xw
- app = xw.App()
- wb = app.books.open(r'E:\测试表.xlsx')
- wb.save(r'E:\测试表.xlsx') # 保存文件
- wb.close() # 关闭文件
- app.quit() # 关闭程序
新建Excel文件
- wb = app.books.add()
- wb.save((r'E:\新建工作簿.xlsx')
- wb.close()
- app.quit()
获取表
- for s in wb.sheets:
- print(wb.sheets[s])
读取内容
方法一
- # 获取单个单元格的值
- A1 = sh.range("A1").value
- print(A1)
- # 获取横向或纵向多个单元格的值,返回列表
- A1_A3 = sh.range("A1:A3").value
- print(A1_A3)
- # 获取指定范围的值,返回嵌套列表,按行为列表
- A1_B3 = sh.range("A1:B3").value
- print(A1_B3)
方法二
- # 获取单个单元格的值
- A1 = sh["A1"].value
- print(A1)
- # 获取横向或纵向多个单元格的值,返回列表
- A1_A3 = sh["A1:A3"].value
- print(A1_A3)
- # 获取指定范围的值,返回嵌套列表,按行为列表
- A1_B3 = sh["A1:B3"].value
- print(A1_B3)
方法三:
- A1_B2 = sh[:2,:2].value
- print(A1_B2)
写入数据
- # 写入1个单元格
- sh.range("A5").value = "杨迪"
- # 横向写入A6:B6
- sh.range('A6').value = ['杨洋',32]
- # 纵向写入C2:C5
- sh.range("C2").options(transpose=True).value = ['歌手','演员','演员','搞笑艺人']
- # 写入范围内A7:C8
- sh.range("A7").options(expand="table").value=[[1,2,3],[4,5,6]]
获取数据范围
- shape = sh.used_range.shape
- print(shape)
- # 最大行数列数
- max_row = wb.sheets[s].used_range.last_cell.row
- max_col = wb.sheets[s].used_range.last_cell.column
输出并修改行高列宽
- # 输出
- print(sh.range("A1:A2").row_height)
- print(sh.range("A1:A2").column_width)
- # 修改
- sh.range("A1:A2").row_height = 30
- sh.range('A1:A2').column_width = 50
获取及设置公式
可以调用Excel公式
- # 获取公式
- print(sh.range("B7").formula_array)
- # 写入公式
- sh.range("F2").formula = "=VLOOKUP(E2,A:B,2,0)"
获取、设置及清除颜色格式
- # 获取颜色
- print(sh.range("A1:A7").color)
- # 设置颜色
- sh.range("C:C").color = (255,0,120)
- # 清除颜色
- sh.range("E2:F2").color = None
xlrd读取Excel
注意:xlrd索引从0开始,仅读取,不可写入。
新版本只支持xls文件,版本降级支持(xlsx和xls):pip install xlrd==1.2.0
pip install Xlrd # 安装打开Excel文件
- import xlrd
- file = r"D:\demo\A.xlsx"
- df = xlrd.open_workbook(file)
查看工作簿中所有工作表
df.sheet_names()指定工作表三种方式
- table = df.sheets()[0]
- table = df.sheet_by_index(0)
- table = df.sheet_by_name("工作表1")
获取表格最大行数和列数
- table.nrows
- table.ncols
获取整行或整列的值
- table.row_values(0) # 获取第一行
- table.col_values(0) # 获取第一列
循环读取所有行
- for i in range(table.nrows):
- print(table.row_values(i)) # 返回整行
表操作(待试验)
ds.row_values(0,6,10) #取第一行,第6-9列
ds.col_values(0,0,5) #取第一列,第0-4行
ds.row_slice(2,0,2) #获取单元格值类型和内容,同sheet1.row()
sheet1.row_types(1,0,2) #获取单元格数据类型
table.row_values(0,6获取单元格的值
- print(table.cell_value(3,0)) # 第四行第一列的值
- print(table.row_values(1,0)) # 第二行第一列的值
- # col_values(self,colx,start_rowx,end_rowx)
- print(table.col_values(0,0)) # 第一列的值
xlrd案例
1、同层级文件夹中查找字符串
在单元格中找含有杨幂的字符串
- # 同层级,遍历所有表格内的所有表的所有单元格包含字符串的返回路径和该行单元格值
- import glob
- import xlrd
- path = r"D:\demo\一层级"
- for file in (glob.glob(path+"/*/*"):
- # 获取文件后缀
- file_suffix = file.split(".")[-1]
- # 后缀名为xls
- if file_suffix == "xls" or file_suffix == "xlsx": # xlrd修改版本后可操作xlsx文件
- # 读取Excel文件
- df = xlrd.open_workbook(file)
- # 获取表格内所有表名
- for sheet in df.sheet_names():
- # 表名
- table = df.sheet_by_name(sheet)
- # 最大行列数
- max_row = table.nrows
- max_col = table.ncols
- # xlrd索引从0开始
- for i in range(max_row):
- # 循环某表每行的值
- for h in table.row_values(i):
- # 查找含有杨幂字符串的单元格
- if "杨幂" in str(h):
- print(f"路径:{file},{h}")
1、pip install xlrd==1.2.0 #此版本支持xlsx和xls
2、如果报错:'ElementTree' object has no attribute 'getiterator' ,则需要进行如下更改:
3、先pip show xlrd根据Location找到并进入xlrd文件夹,打开xlsx.py
4、然后查询里面的 getiterator(),把里面两处getiterator替换为iter 即可。
2、多层级文件夹中查找
使用glob的recursive=True实现多层级查找
- import glob
- import xlrd
- path = r"D:\demo\层级"
- for file in glob.glob(path + "/**",recursive=True):
- # 获取文件后缀
- file_suffix = file.split(".")[-1]
- '''
- 同层级相同步骤
- '''
3、匹配数据
类似VLOOKUP,但是查找整个文件夹的文件
- import glob
- import xlrd
- import openpyxl
- # openpyxl 从1开始,xlrd从0开始
- path = r"查找的文件夹路径"
- match_path = r"待匹配的数据表.xlsx"
- data = openpyxl.load_workbook(match_path)
- match_table = data['Sheet1']
- Match_max_row = match_table.max_row #待匹配表的最大行号
- # for m in range(2, Match_max_row + 1) 如果待匹配的表格数量小放在此处
- for file in glob.glob(path+"/*"):
- # 获取文件后缀
- file_suffix = file.split(".")[-1]
- # 后缀名为xls
- if file_suffix == "xls" or file_suffix == "xlsx":
- # 读取Excel文件
- df = xlrd.open_workbook(file)
- # 获取表格内所有表名
- for sheet in df.sheet_names():
- # 表名
- table = df.sheet_by_name(sheet)
- # 最大行列数
- max_row = table.nrows
- max_col = table.ncols
- # xlrd索引从0开始
- for i in range(1,max_row+1):
- try:
- # 循环某表每行的值
- for h in table.row_values(i):
- # 循环待匹配表的每行
- for m in range(2, Match_max_row + 1):
- # for m in range(2, Match_max_row + 1)如果待匹配的表数量大放在此处
- # 判断是否存在
- if str(match_table.cell(m, 7).value) in str(h):
- # 存在写入表名
- match_table.cell(m, 8).value = sheet
- continue
- except:
- continue
- data.save(r'待匹配的数据表(副本).xlsx')
- data.close()
4、汇总多个excel
- import os
- import openpyxl
- import datetime
- import xlrd
- date = datetime.datetime.now().date()
- Year = date.year
- Month = date.month
- # 待汇总的表
- wb = openpyxl.load_workbook(路径)
- ws = wb['汇总']
-
- path = r"C:\Users\HP\Desktop\Text"
- # 多层级搜索
- for file in os.scandir(path):
- # 是文件夹
- if file.is_dir():
- # 读取文件夹
- for f in os.scandir(file.path):
- # 如果文件名包含“ xxx.xlsx”
- if "text.xlsx" in f.name:
- # 打开excel文件(文件路径+文件名)
- sheets = xlrd.open_workbook(file.path + "/" + f.name)
- # sheets.sheet_by_index(0) 根据索引获取表
- # 指定读取excel工作表
- sheet = sheets.sheet_by_name("汇总")
- # 获取最大的行号
- rows = sheet.nrows
- # 获取最大的列号
- cols = sheet.ncols
- # 除去表头,开始汇总的行数
- startrow = 1 # 从第二行开始
- for row in range(startrow,rows):
- l = sheet.row_values(row)
- ws.append(l)
- wb.save(路径)
5、复制工作簿
- import xlrd
- import openpyxl
- wb = xlrd.open_workbook("原表.xlsx")
- ws = wb.sheet_by_name("2024") # 待复制的工作表
- maxrow = ws.nrows
-
- df = openpyxl.load_workbook(r"新表.xlsx")
- ds = df.create_sheet("2024年-copy",0) # 创建表名
- for i in range(0,maxrow):
- ds.append(ws.row_values(i)) # ws.row_values(i)整行 ,整行数据追加到新表
-
- df.save("新表.xlsx")
xls转xlsx
- import win32com.client as win32
-
- fname = r"C:\Users\HP\Desktop\text.xlsx"
- excel = win32.gencache.EnsureDispatch('Excel.Application')
- wb = excel.Workbooks.Open(fname)
-
- ## 转换为xls
- # xls_f = fname.split('.')[0]+"xls"
- # wb.SaveAs(xls_f, FileFormat=56)
-
- wb.SaveAs(fname + "x", FileFormat=51) #FileFormat = 51 is for .xlsx extension
- wb.Close() #FileFormat = 56 is for .xls extension
- excel.Application.Quit()
知识扩展:glog()通配符搜索
持续更新中
部分来源:

