
- 1华为的热机备份和流量限制
- 2前端7大常用布局方式_前端布局
- 3超简单,手把手教你在本地运行Llama 3大模型_ollama run llama3
- 4直播系统源码性能调优方案最全最详细
- 5【项目开发记录】微信小程序_colorui底部导航栏
- 6基于Hadoop2.7.2+ ICTCLAS2015的并行化中文分词
- 7HarmonyOS Next开发学习手册——UI开发 (兼容JS的类Web开发范式)
- 8信创基础软件之信创云介绍_信创软件
- 9英伟达A100、A800、H100、H800、V100以及RTX 4090的详细性能参数对比_a100 a800 h100 h800
- 10基于复旦微的 FMQL45T900 ARM+FPGA+AD全国产化解决方案,兼容XILINX的XC7Z045-2FFG900I (即ZYNQ7045)
人工智能任务3-读懂BERT模型的几个灵魂拷问问题,深度理解 BERT模型架构_掩蔽语言预测模型损失函数
赞
踩
大家好,我是微学AI,今天给大家介绍一下人工智能任务3-读懂BERT模型的几个灵魂拷问问题,深度理解BERT模型架构。BERT是一种基于Transformer模型的预训练语言模型。它由Google在2018年开发,旨在解决自然语言处理领域中的各种任务,如情感分析、问答系统、命名实体识别等。BERT模型在预训练阶段,BERT使用大量的无标记文本数据来训练一个深度的双向Transformer编码器。这个编码器能够同时考虑左侧和右侧的上下文信息,从而更好地理解句子中的单词之间的关系。
BERT模型的预训练过程包括两个任务:掩码语言建模(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。在MLM任务中,BERT随机掩盖输入句子中的某些单词,并通过上下文中的其他单词来预测这些被掩码的单词。在NSP任务中,BERT判断两个句子是否是连续的。预训练完成后,BERT模型可以用于各种具体的下游任务。为了适应特定任务,需要在预训练模型之上进行微调。微调过程涉及到将任务相关的标记和特定的输入添加到预训练模型中,并使用任务相关的数据集来进行有监督训练。
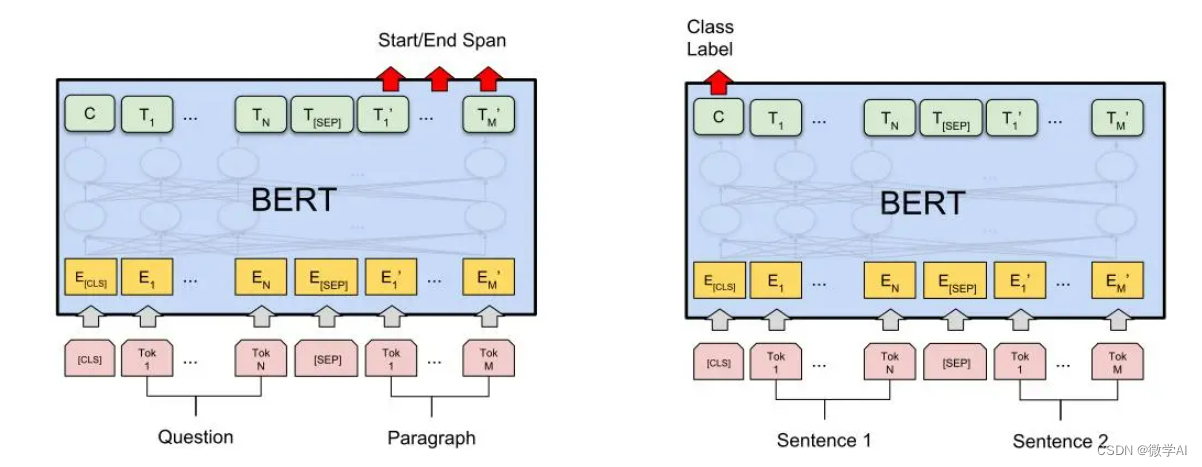
一、 BERT模型训练过程中,词嵌入做了哪些步骤,请具体说明,并举个例子?
BERT模型的训练过程中,词嵌入是第一步,它涉及将输入文本转换为模型可以处理的数值形式。BERT使用的词嵌入过程包括以下几个步骤:
1. Tokenization
将文本分割成更小的单元,通常是单词、子词或者字符。BERT主要使用WordPiece tokenization,这种方法可以有效处理未知词汇,因为它将未知的单词进一步分解为已知的子词。
2. 添加特殊标记
BERT在输入序列的开始处添加了一个特殊的[CLS]标记,用于分类任务。对于句子对任务(如下一句预测),在两个句子之间以及最后会分别添加[SEP]标记来区分它们。
3. 转换为词索引
将每个token转换为词汇表中的索引。BERT有一个固定大小的词汇表,每个token都映射到这个词汇表中的一个唯一索引。
4. 分段嵌入
对于处理两个句子的任务,BERT使用分段嵌入来区分两个句子。这是一个二进制掩码,标识每个token属于输入中的哪个句子。
5. 位置嵌入
由于BERT使用的是Transformer架构,这种架构本身不像循环神经网络那样具有处理序列的能力,所以需要添加位置嵌入来给模型提供token的顺序信息。
6. 嵌入的总和
将Token嵌入、分段嵌入和位置嵌入相加,得到最终的输入嵌入,这个嵌入将被送入模型的后续层中。
例子:
假设我们有一个简单的输入句子:“Hello, BERT loves to read books.” 这个句子将会经历以下转换过程:
1.Tokenization:
- 分割为:[“Hello”, “,”, “BERT”, “loves”, “to”, “read”, “books”, “.”]
2.添加特殊标记:
- 添加 [CLS] 和 [SEP]:[“[CLS]”, “Hello”, “,”, “BERT”, “loves”, “to”, “read”, “books”, “.”, “[SEP]”]
3.转换为词索引:
- 假设每个token在词汇表中的索引如下:[101, 7592, 1012, 14324, 7459, 2000, 3191, 2338, 1012, 102]
4.分段嵌入:
- 假设这是单句输入,分段嵌入将会是:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
5.位置嵌入:
- 对于每个位置有一个对应的位置嵌入,例如:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
6.嵌入的总和:
- 最终的输入嵌入将会是上述三种嵌入的总和。
这个嵌入的结果是BERT模型训练的起始点,模型将基于这些嵌入进一步学习文本的深层语义表示。
二、BERT模型训练过程中计算预测结果、真实标签是长什么样的,是用什么形式的,请举例子?
在BERT模型中,损失函数的计算涉及到两个主要任务:遮蔽语言模型(Masked Language Model, MLM)任务和下一句预测(Next Sentence Prediction, NSP)任务。损失函数通常是针对这两个任务计算出来的交叉熵损失的和。下面我会分别解释这两个任务中预测结果和真实标签的形式,并提供实例来说明。
1. 遮蔽语言模型(MLM)任务
在MLM任务中,BERT会随机地将输入序列中的某些单词(tokens)替换为一个特殊的[MASK]标记,模型的任务是预测这些被遮蔽的单词。预测的结果是一个概率分布,表示模型对于每个可能的词汇表中单词作为遮蔽位置正确单词的置信度。
预测结果: 模型输出的概率分布,为每个可能的单词赋予一个概率值。
真实标签: 被遮蔽单词的实际单词。
例子:
假设原始句子是 “The cat sat on the mat”,BERT可能遮蔽单词"cat",那么输入就变成了 “The [MASK] sat on the mat”。在训练过程中,模型尝试预测这个[MASK]位置的正确单词。
- 真实标签: “cat”
- 预测结果: 一个概率分布,例如 {“cat”: 0.9, “dog”: 0.05, “mat”: 0.03, …}。
损失函数计算的是这个概率分布和一热编码的真实标签之间的交叉熵损失。
2. 下一句预测(NSP)任务
在NSP任务中,模型需要判断第二个句子是否是第一个句子的下一句。在训练时,有一半的几率第二个句子实际上是紧跟在第一个句子后面的下一句,而另一半几率则是从语料库中随机选取的一个句子。
预测结果: 模型输出一个二分类概率分布,表示两个句子是否连贯的概率。
真实标签: 一个简单的二分类标签,0表示两个句子不连贯,1表示连贯。
例子:
假设有两个句子 A 和 B。
- 句子 A: “The cat sat on the mat.”
- 句子 B: “It was very cozy and warm.”
假设句子 B 实际上是句子 A 的下一句。
- 真实标签: 1
- 预测结果: {“不连贯”: 0.2, “连贯”: 0.8}
如果句子 B 不是句子 A 的下一句,那么真实标签将是 0。
对于这两种任务,模型最终的损失是两个任务损失的和,如果模型在预测时更接近于真实的标签,那么产生的损失就会更小。通过梯度下降等优化方法,BERT模型会逐渐调整其参数以最小化这个损失函数,从而提高预测的准确性。
三、BERT模型中的真实标签和词汇表中的one-hot编码有什么关系?
BERT模型中的真实标签和词汇表中的one-hot编码有一些相似之处。在BERT模型中,真实标签是指模型在训练过程中用于计算损失的标签,通常是一个单词或一个词语的索引。而在词汇表中,通常使用one-hot编码来表示每个单词或词语的存在与否。
让我们通过一个简单的中文示例来说明这一点:
假设我们有一个词汇表,其中包含三个单词:“苹果”、“香蕉”和“橙子”。我们可以使用one-hot编码来表示这些单词:
苹果:[1, 0, 0]
香蕉:[0, 1, 0]
橙子:[0, 0, 1]
这种编码方式确保了每个单词都有一个唯一的表示,就像在BERT模型中使用真实标签来表示每个单词的索引一样。这种相似性使得我们可以将词汇表中的one-hot编码与BERT模型中的真实标签联系起来。
四、BERT模型中的真实标签值是什么,怎么计算损失值,又是怎么填充的?
BERT模型中的真实标签值是通过Masked-Language Modeling (MLM)来确定的。在MLM中,我们输入一个句子,并对BERT模型的权重进行优化,以便输出与输入句子相同的句子。在输入句子之前,我们会对其中的一些标记进行掩盖。这意味着我们实际上输入的是一个不完整的句子,并要求BERT模型为我们完成它。损失值是通过比较模型输出的结果与真实标签值之间的差异来计算的。在计算损失值时,我们需要忽略填充区域,以确保只考虑有效标记的损失。接下来,我将为您提供一个示例代码,演示如何使用PyTorch计算BERT模型的损失值并忽略填充区域。
下面是一个实例代码,帮助大家理解:
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
# 初始化BERT模型和tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
# 假设我们有一批输入数据和对应的真实标签
input_text = ["[CLS] The cat sat on the [MASK] . [SEP]", "[CLS] She played [MASK] piano. [SEP]"]
#如果“mat”和“the”分别对应于词汇表中的索引2003和2001
labels = torch.tensor([[ -100, -100, -100, -100, -100, 2003, -100, -100],
[ -100, -100, -100, 2001, -100, -100, -100, -100]])
# 将输入文本转换为模型输入
inputs = tokenizer(input_text, return_tensors='pt', padding=True, truncation=True)
# 获取模型输出
outputs = model(**inputs)
# 假设模型输出的结果为predictions
predictions = outputs.last_hidden_state
# 计算损失值
loss_fn = nn.CrossEntropyLoss(ignore_index=-100) # 忽略填充区域
loss = loss_fn(predictions.view(-1, predictions.shape[-1]), labels.view(-1))
# 打印损失值
print(loss.item())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
在上面的示例代码中,我们使用了PyTorch和Hugging Face的transformers库来加载BERT模型和tokenizer。然后,我们将输入文本转换为模型输入,并获取模型输出。最后,我们使用交叉熵损失函数来计算损失值,并通过设置ignore_index参数来忽略填充区域。这样,我们就可以计算出BERT模型的损失值并忽略填充区域。
五、BERT中为什么输入部分用特殊符进行padding,而标签labs用[-100]进行填充??
输入部分使用特殊符进行padding是为了将不同长度的句子补齐到相同的长度,以便进行批量处理。而对于标签部分,通常会使用特定的占位符(如-100)来表示需要忽略的标签。
填充输入序列可以确保批量中的所有样本具有相同的长度,以便于模型对它们进行并行计算。而填充标签时,我们希望在训练过程中忽略这些padding部分的标签,因为这些标签并没有实际的意义。使用特定的占位符(如-100)可以在损失函数计算时将这些padding部分的标签忽略掉,从而不影响模型的训练。
需要注意的是,具体使用哪个占位符值来表示忽略标签并不是固定的,可以根据具体任务和模型的需求进行调整。在这里使用-100只是一个常见的选择,其他值也可以用于表示忽略标签的占位符。
六、BERT模型输出的维度是什么样的,和词汇表的维度有什么关系?
BERT模型的输出维度与词汇表的大小有关系。具体来说,对于一个BERT模型,在输入文本中包含n个单词时,它的输出维度为(n, h),其中h是模型的隐藏层大小。这个输出可以被看作是一个n个向量组成的矩阵,其中每个向量的长度为h。
在BERT模型中,通常会通过将每个单词的向量与一个词向量表进行点积操作来得到该单词的预测概率分布。这个词向量表的大小与词汇表的大小相同,每个词在词向量表中都有一个对应的向量表示。因此,如果我们假设词汇表的大小为v,那么BERT模型的输出维度可以看作是一个(n, v)的矩阵,其中每个位置上的值代表了模型对该单词在词汇表中的预测概率。
需要注意的是,BERT模型的输出并不是直接对应于词汇表中的one-hot编码。相反,它的输出是由一系列复杂的运算和变换得到的,包括自注意力机制、残差连接、全连接层等等。这些运算和变换的目的是将输入文本序列的信息编码成一个具有丰富语义表达能力的向量表示,从而支持下游任务的处理。

