
热门标签
热门文章
- 1手把手教你FreeRTOS源码详解(三)——队列
- 2基于C语言实现图书馆管理系统毕业设计——关键代码解析_毕设关键代码太多怎么简
- 3Connection reset by 13.229.188.59 port 22 github连接超时
- 4【吊打面试官系列-ZooKeeper面试题】四种类型的数据节点 Znode ?
- 5who calls SurfaceFlinger::composite
- 6【计算机毕设文章】基于微信小程序的点餐小程序
- 7初中化学知识点总结(人教版)
- 82024年软件测试最全分享8款开源的自动化测试框架_开源自动化测试平台,2024软件测试高频精选面试题讲解_软件测试开源项目
- 9AI-CV-ML领域重要的会议及期刊_aaai期刊
- 10SpringBoot异步执行方法,采用CompletableFuture_spring boot completablefuture
当前位置: article > 正文
C语言数据结构——带头双向循环链表的实现_c语言数据结构双链表源码
作者:神奇cpp | 2024-07-15 04:13:47
赞
踩
c语言数据结构双链表源码
文章目录
- 前言
- 双链表的实现
-
- DoubleList.h
- void ListPrint(ListNode* phead)
- ListNode* BuyListNode(LTDataType x)
- void InitList(ListNode** pphead)
- void ListPushBack(ListNode* phead, LTDataType x)
- void ListPopBack(ListNode* phead)
- void ListPushFront(ListNode* phead, LTDataType x)
- void ListPopFront(ListNode* phead)
- ListNode* ListFind(ListNode* phead, LTDataType x)
- void ListInsert(ListNode* pos, LTDataType x)
- void ListErase(ListNode* pos)
- Destroy & Clear
- 结束语
前言
为什么博主只写了双链表的实现,主要是考虑了一下带头双向循环链表的优势远远大于无头单向非循环链表,重点体现在结点的插入与删除这方面上。
另外不知道大家是否了解顺序表,已经它与链表之间的区别呢?
博主在这里先为大家介绍一下它们:
1、顺序表就是在数组的基础上实现增删查改,并且插入时可以动态增长
顺序表的缺陷:
a、可能存在一定的空间浪费(两倍动态增容所致)
b、增容有一些效率损失(realloc可能会拷贝数据)
c、中间或者头部插入删除,时间复杂度为O(N),因为要挪动数据
以上abc的缺点都可以由链表来解决,互补的数据结构
链表的缺陷:
就是顺序表优点的反面
a、不能随机访问
b、由于预加载原因,缓存利用率并不高
双链表的实现
博主先将头文件给大家看看,具体函数的思路与实现会一一介绍,另外头文件上有与之相关的注释给予浏览。
DoubleList.h
#define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> #include <stdlib.h> #include <assert.h> //不是int类型,而是是double、float等其他形式的话,用typedef命名比较方便 //有点#define那味儿,但不等价 typedef int LTDataType; typedef struct ListNode { LTDataType data; struct ListNode* next; struct ListNode* prev; }ListNode; //打印链表 void ListPrint(ListNode* phead); //建立新结点 ListNode* BuyListNode(LTDataType x); //初始化链表 void InitList(ListNode** pphead); //尾插 void ListPushBack(ListNode* phead, LTDataType x); //尾删 void ListPopBack(ListNode* phead); //头插 void ListPushFront(ListNode* phead, LTDataType x); //头删 void ListPopFront(ListNode* phead); //访问数据 ListNode* ListFind(ListNode* phead, LTDataType x); //中间插入(需要利用ListFind函数) void ListInsert(ListNode* pos, LTDataType x); //中间删除(需要利用ListFind函数) void ListErase(ListNode* pos); //销毁数据(不保留头结点) void ListDestroy(ListNode** phead); //清理数据(保留头结点) void ListClear(ListNode* phead);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
void ListPrint(ListNode* phead)
在实现各个函数功能之前,我们需要知道带头双向循环链表的形式到底是什么样的,如下:
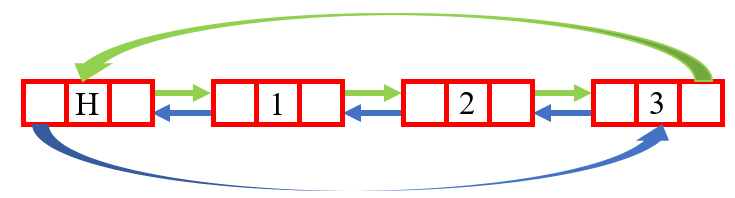
H的意思就是“头”,起到一个哨兵位的效果,里面的数据是随机值,不算做链表的内容,显然仅仅是带头的作用。H的左边是指针prev,右边是next,看英文意思就明白指的是一前一后,从而形成循环,每个结点都保留了前一个结点和后一个结点的地址,方便访问。
但是如果一直循环的话岂不是死循环而无法打印链表了?解决方法也很简单,建立一个新指针cur = phead->next,循环遍历,当cur = phead时停止,如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/827681
推荐阅读

相关标签

