
- 1docker、k8s 面试总结_会docker简历怎么写
- 2【无标题】知识蒸馏_bckd 知识蒸馏
- 3Jenkins - 单机和集群搭建、基于git分支部署spring boot项目(脚本、docker发布)、gitlab钩子部署【图文详解】_jenkins集群部署
- 42024C++信息素养大赛-算法创意实践挑战_复赛真题(广东省)题目+参考答案和详细解析
- 5Mybatis从入门到CRUD到分页到日志到Lombok到动态SQL再到缓存
- 6爱星物联——设备运行情况和故障排查初探
- 7老牛知点所以然-两种安卓两种网络请求框架(ksoap2-android & okhttp)配置https_android ksoap请求过程
- 8[NLP] BERT模型参数量_bert训练词向量的参数
- 9图片怎么放大比例?两个方法轻松放大
- 10头歌:Spark的安装与使用_spark的安装与使用头歌
【知识图谱】基于neo4j构建医疗领域知识图谱_neo4j构建知识图谱的教程
赞
踩
【知识图谱】基于neo4j构建医疗领域知识图谱
- 知识图谱本体建模
- 1.知识图谱实体类型
- 2. 知识图谱实体关系类型
- 3. 知识图谱实体属性类型
- 构建neo4j知识图谱
- 创建并启动医疗领域知识图谱
- 图谱创建python脚本介绍
- 1.Python连接Node4j数据库
- 2.创建图对象
- 3.增加node节点:
- 4.创建实体关系:
- 5.两个节点新加关系:
- 运行创建图谱
- 医疗实体数据导入
- 医疗实体关系数据导入
- 医疗领域知识图谱可视化
前文中我们通过爬虫收集医疗领域结构化数据medical.json,数据中包含实体规模4.4112万,实体关系24万。
medical.json资源链接:https://download.csdn.net/download/chenghao1012/89246979
医疗知识图谱的数据库迁移参考教程:https://editor.csdn.net/md/?articleId=137857310
医疗知识图谱dump文件资源链接: https://download.csdn.net/download/chenghao1012/89217606
探讨知识图谱问题,下载所需资源欢迎联系
微信账号: zskp1012
欢迎关注小红书账号:知识靠谱
知识图谱本体建模
在数据库中构建了三元组并且这些三元组形成了结构化的数据关系,进行知识图谱建模。知识图谱是一种用于表示和组织实体、属性和它们之间关系的图形结构。三元组(Subject, Predicate, Object)是知识图谱中的基本构建块,每个三元组都可以被看作是一个图中的边,连接两个节点(实体)。这些节点和边的组合形成了一个图,其中节点表示实体,边表示实体之间的关系。这种方式可以用于构建一个基本的知识图谱。
具体以下几个方面:
实体(Entities): 你的数据库中的记录是知识图谱中的实体。每个实体对应于一个节点。
属性(Properties): 数据库中的字段可以被视为实体的属性。这些属性可以形成连接实体的边。
关系(Relationships): 三元组中的谓词(Predicate)对应于实体之间的关系。关系连接两个实体。
本体(Ontology): 如果你想要对实体和关系进行更详细的定义和注释,可以考虑使用本体。
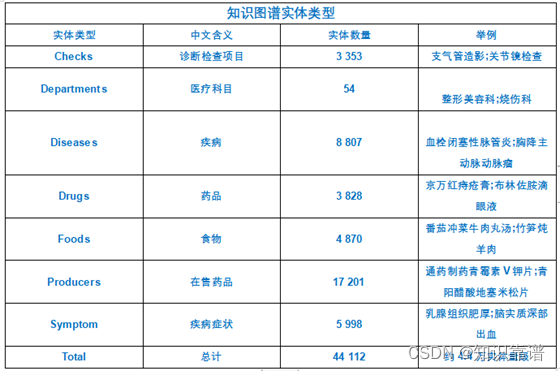
1.知识图谱实体类型
知识图谱实体类型如下图所示:

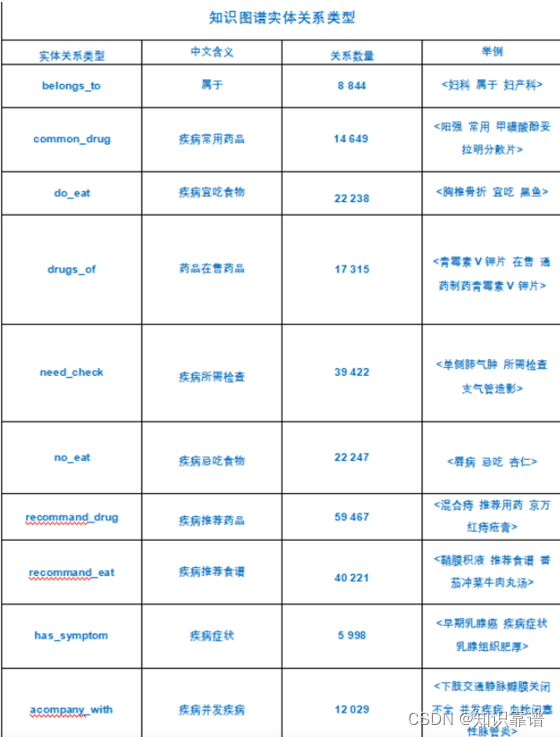
2. 知识图谱实体关系类型
知识图谱实体关系类型,如下图所示:
# 构建节点实体关系,共11类
rels_department = []
rels_noteat = [] # 疾病-忌吃食物关系
rels_doeat = [] # 疾病-宜吃食物关系
rels_recommandeat = [] # 疾病-推荐吃食物关系
rels_commonddrug = [] # 疾病-通用药品关系
rels_recommanddrug = [] # 疾病-热门药品关系
rels_check = [] # 疾病-检查关系
rels_drug_producer = [] # 厂商-药物关系
rels_symptom = [] #疾病症状关系
rels_acompany = [] # 疾病并发关系
rels_category = [] # 疾病与科室之间的关系
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
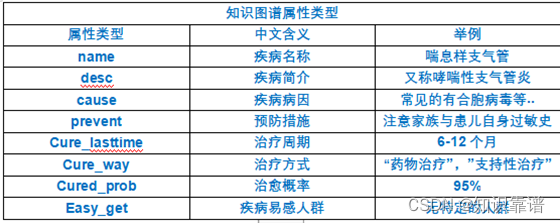
3. 知识图谱实体属性类型
知识图谱实体属性类型,如下图所示:
构建neo4j知识图谱
构建知识图谱首先需要安装neo4j图数据库,相关安装教程如下:
neo4j桌面版安装教程: https://blog.csdn.net/chenghao1012/article/details/136736760
neo4j社区版安装教程:https://blog.csdn.net/chenghao1012/article/details/135931544
创建并启动医疗领域知识图谱
打开已安装好的neo4j,点击Add 添加数据库,填写如下信息后create。
数据库名称:医疗领域知识图谱( 名字都可以随便取)
选择版本4.4.18
密码:12345678

点击start启动数据库

图谱创建python脚本介绍
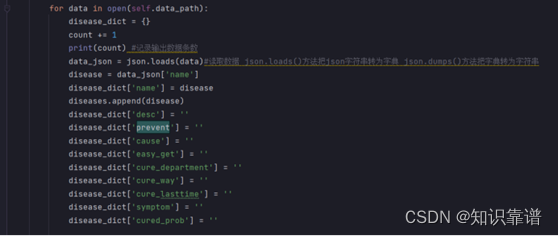
根据字典形式的数据创建结点,以疾病为中心定义关系形成三元组表示的知识,将结点和关系导入neo4j数据库形成知识图谱,通过运行build_medicalgraph.py脚本构建图谱。
该脚本构建了一个MedicalGraph类,定义了Graph类的成员变量g和json数据路径成员变量data_path。
1.Python连接Node4j数据库
from py2neo import Graph
class AnswerSearcher:
def __init__(self):#调用数据库进行查询
# self.g = Graph("bolt://localhost:7687", username="neo4j", password="12345678")#老版本neo4j
self.g = Graph("bolt://localhost:7687", auth=("neo4j", "12345678"))#输入自己修改的用户名,密码
- 1
- 2
- 3
- 4
- 5
- 6
2.创建图对象
#对绝对路径进行拼接 获取json文件路径
self.data_path = os.path.join(cur_dir, 'data/medical.json')
class MedicalGraph:
def __init__(self):
cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])
self.data_path = os.path.join(cur_dir, 'data/medical.json')# 对绝对路径进行拼接 获取json文件路径 这里使用的Jason为部分数据量
# self.g = Graph("http://localhost:7474", username="neo4j", password="12345678")#老版本neo4j
self.g = Graph("bolt://localhost:7687", auth=("neo4j", "12345678"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.增加node节点:
def create_node(self, label, nodes):
count = 0
for node_name in nodes:
node = Node(label, name=node_name)
self.g.create(node)
count += 1
print(count, len(nodes))
return
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.创建实体关系:
def create_graphrels(self):
Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category = self.read_nodes()
self.create_relationship('Disease', 'Food', rels_recommandeat, 'recommand_eat', '推荐食谱')#调用下面的关系边创建函数
self.create_relationship('Disease', 'Food', rels_noteat, 'no_eat', '忌吃')
self.create_relationship('Disease', 'Food', rels_doeat, 'do_eat', '宜吃')
self.create_relationship('Department', 'Department', rels_department, 'belongs_to', '属于')
self.create_relationship('Disease', 'Drug', rels_commonddrug, 'common_drug', '常用药品')
self.create_relationship('Producer', 'Drug', rels_drug_producer, 'drugs_of', '生产药品')
self.create_relationship('Disease', 'Drug', rels_recommanddrug, 'recommand_drug', '好评药品')
self.create_relationship('Disease', 'Check', rels_check, 'need_check', '诊断检查')
self.create_relationship('Disease', 'Symptom', rels_symptom, 'has_symptom', '症状')
self.create_relationship('Disease', 'Disease', rels_acompany, 'acompany_with', '并发症')
self.create_relationship('Disease', 'Department', rels_category, 'belongs_to', '所属科室')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.两个节点新加关系:
from py2neo import Graph, Node, Relationship, NodeMatcher, Subgraph
g = Graph('http://localhost:7687', auth=("neo4j", "123456"))
matcher = NodeMatcher(g)
fugui = matcher.match('Person', name='节点名称1').first()
youqian = matcher.match('Person', name='节点名称2').first()
relation = Relationship(节点名称1, '所要建立的关系', 节点名称2)
g.create(relation)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行创建图谱
运行build_medicalgraph.py脚本构建图谱:
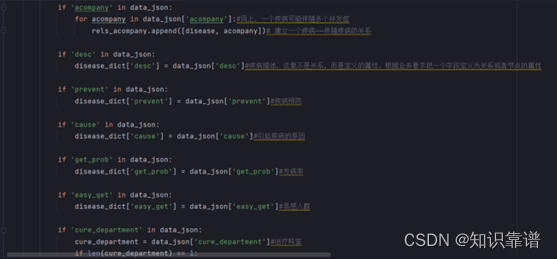
医疗实体数据导入
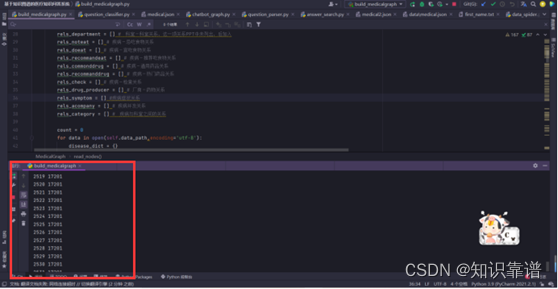
医疗实体关系数据导入
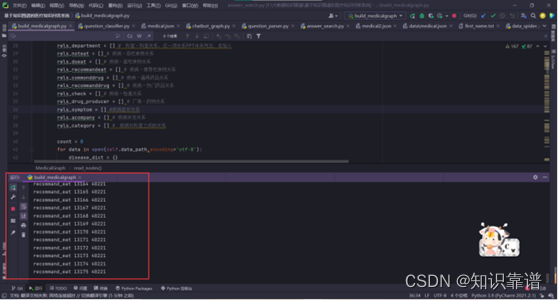
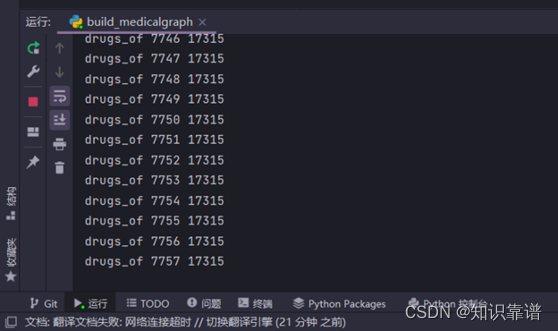
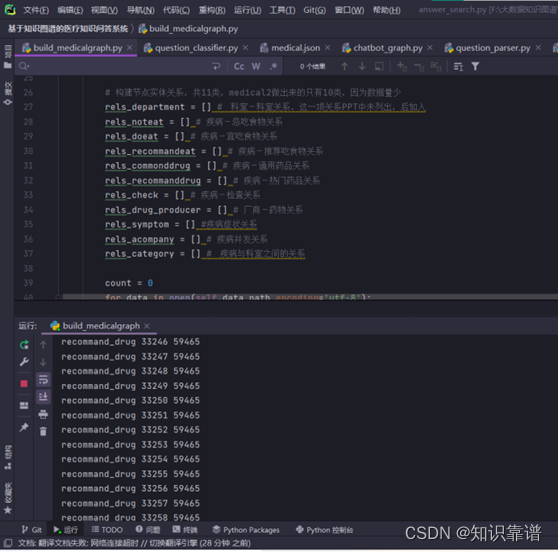
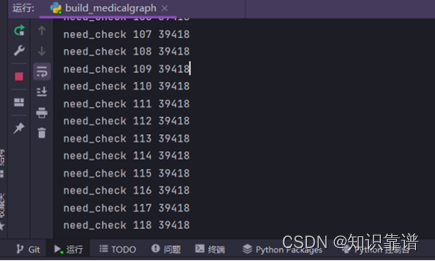
脚本运行完之后查看neo4j数据库中构建的知识图谱。
建立的图谱实体关系和属性类型数量有点多,需要等待一会儿(两三个小时)。耐心等待就可以,因为我们这个爬取的数据量大,知识图谱如果数据量不足,构建的实体关系和属性类型再多再合适也没用,大数据下的知识图谱才有更强的问答能力。
通过数据库迁移可实现快速部署知识图谱,需要创建完的医疗领域知识图谱的数据库迁移dump文件,
数据库迁移参考教程:https://editor.csdn.net/md/?articleId=137857310
医疗知识图谱dump文件资源链接: https://download.csdn.net/download/chenghao1012/89217606
医疗领域知识图谱可视化
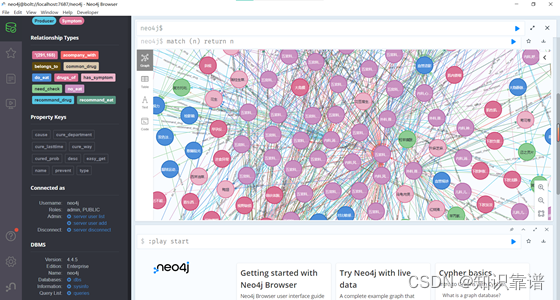
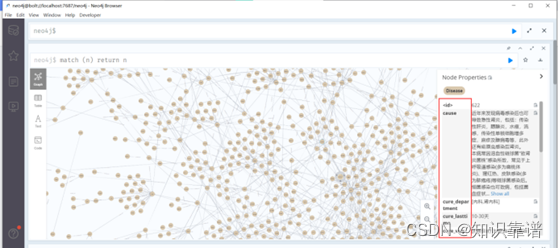
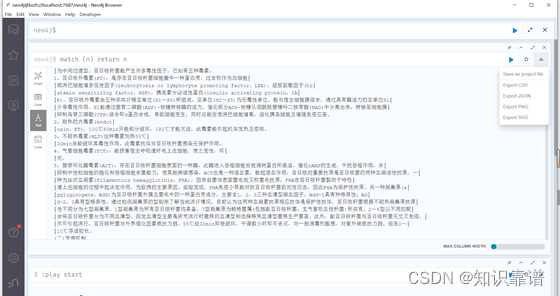
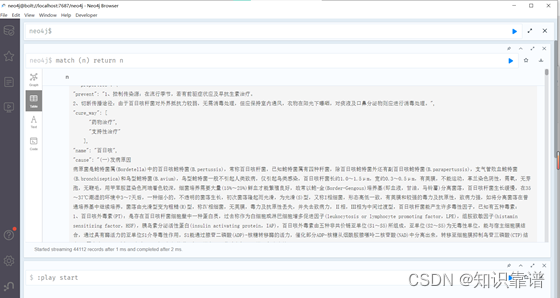
至此医疗领域知识图谱创建完成,水平有限,如有问题欢迎多做交流!!!
探讨知识图谱问题,下载所需资源欢迎联系
微信账号: zskp1012
欢迎关注小红书账号:知识靠谱

