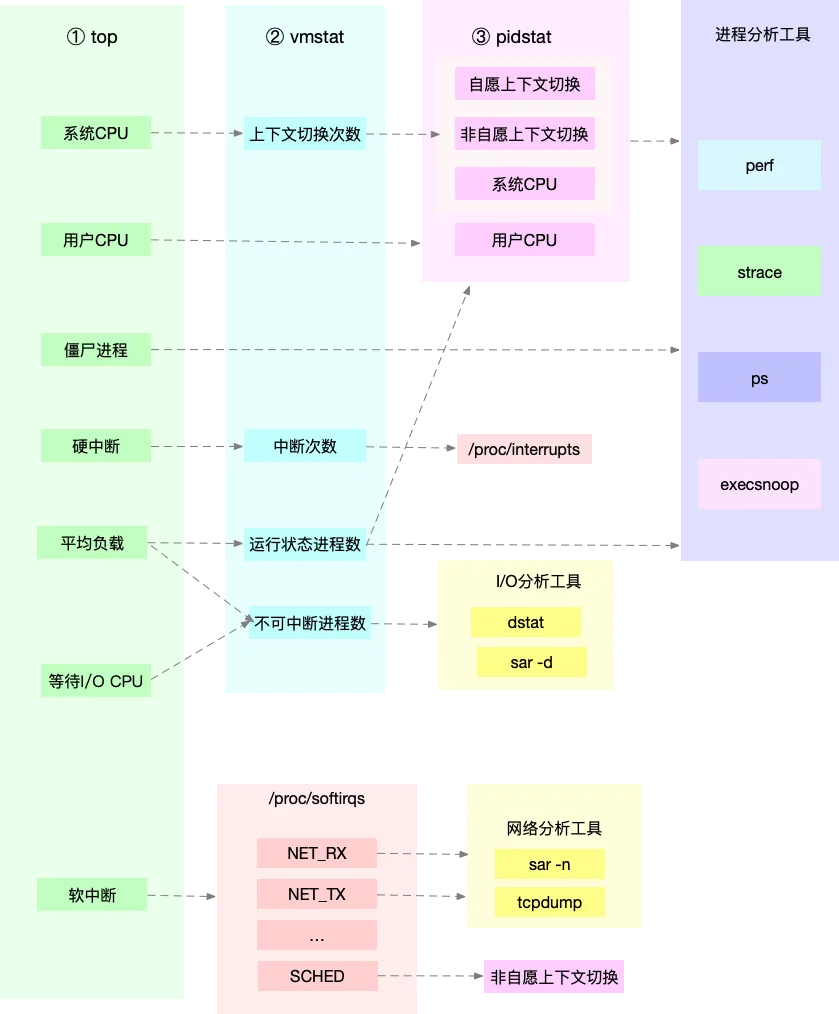
- 1安装ollama并部署大模型并测试_ollama 测试
- 2MATLAB求解微分方程_matlab解微分方程
- 3管理Windows/Mac混合环境的三个选项_域控管理的环境有macos怎么办
- 4【详讲】手把手带你 Typora+PicGoo 配置 gitee 图床_typora+gitee配置picgo图床
- 5算术逻辑单元 —— 串行加法器和并行加法器
- 6java xml transformer_Java xml出现错误 javax.xml.transform.TransformerException: java.lang.NullPointerExc...
- 7python哈希值与地址值_什么时候计算python对象的哈希值,为什么是-1的哈希值是不同的?...
- 8Linux学习系列(二十):在Linux系统中使用Git上传代码到GitHub仓库_linux github
- 9关于warp操作_warp+
- 10头歌MySQL数据库实训答案 有目录_头歌数据库答案mysql
【Linux 性能详解】CPU性能分析工具篇_linux下cpu跑分工具
赞
踩
目录
uptime
uptime 是一个在 Linux 和 Unix 类操作系统中广泛使用的命令行工具,用于提供关于系统运行时间和负载状况的简要信息。执行 uptime 命令时,它会输出一行包含以下几个关键数据的文本:
- 当前时间:
显示当前系统的日期和时间。这可以帮助用户快速了解命令执行的具体时刻。 - 系统运行时间:
表示自系统上次启动以来已运行的总时间。通常以“天+小时:分钟:秒”的格式呈现,如:“1 day, .jpg hours, 34 minutes”。 - 当前登录用户数:
显示当前在系统上处于活动状态(已登录并进行交互或运行进程)的用户数量。这对于评估系统实时使用情况有一定参考价值。 - 平均负载:
提供过去一段时间内系统的平均负载值,通常包括1分钟、5分钟和15分钟的平均负载。这些数值反映了在这三个时间段内,系统处理器(CPU)的繁忙程度。平均负载是系统在特定时间间隔内正在处理或等待处理的任务(进程)的平均数量。理想情况下,这些值应接近系统的处理器核心数(如双核系统期望的平均负载大致在1-2之间),过高可能表明系统资源紧张或存在性能问题。
例如,一个典型的 uptime 命令输出可能如下所示:
![]()
解读上述输出:
- 当前时间为 13:53:41。
- 系统已经运行了 57天。
- 有 2名用户当前在线。
- 过去1分钟、5分钟、15分钟的平均负载分别为 0.09、0.04、0.01。
通过定期检查 uptime 输出,系统管理员和用户可以快速了解系统的总体运行状态、稳定性以及是否存在潜在的资源瓶颈。如果平均负载持续高于系统可处理能力,可能需要进一步调查原因(如是否有资源密集型进程在运行、是否需要增加硬件资源等)。此外,结合其他系统监控工具和命令(如 top、htop、vmstat、iostat 等),可以更深入地分析系统的性能和健康状况。
mpstat
mpstat命令作为Linux系统中用于监控CPU性能的强大工具,具有多种功能特性,以下是一些可能您感兴趣或想要了解的方面:
实时监控
mpstat默认不带任何参数时,会显示系统启动以来CPU的统计信息。若要观察实时变化,可以指定采样间隔和采样次数,如:
mpstat 5 10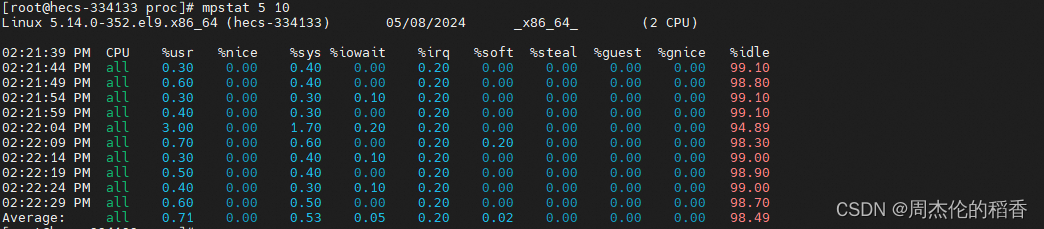
这将每5秒采样一次CPU状态,并连续采样10次。
查看特定CPU核心
使用-P选项指定要监控的CPU编号。例如,查看CPU编号为0的核心状态:
若要同时监控所有CPU核心,使用-P ALL:
mpstat -P ALL
- 显示的统计指标:
mpstat输出包括但不限于以下各项:
%usr: 用户态CPU时间百分比,即执行用户进程所花费的时间。%nice: 低优先级(nice)用户进程所占CPU时间百分比。%sys: 系统态CPU时间百分比,即执行内核进程所花费的时间。%iowait: 等待I/O操作完成时CPU空闲时间百分比。%irq: 处理硬件中断所占CPU时间百分比。%soft: 处理软件中断(包括内核调度等)所占CPU时间百分比。%steal: 在虚拟化环境中,被其他虚拟机“偷走”的CPU时间百分比。%guest: 执行虚拟机所占CPU时间百分比(如果支持)。%idle: CPU空闲时间百分比。- 其他选项:
-u: 显示更为详细的CPU利用率统计,包括平均负载(load average)、进程上下文切换等信息。-A: 显示所有活动和非活动CPU核心的统计信息,这对于识别未完全利用的CPU核心很有帮助。-V: 显示mpstat版本信息。
pidstart
以下是该命令的一些说明:
监控指定进程
使用-p选项后跟进程ID(PID),可以监控特定进程的资源使用情况。例如,监控PID为1234的进程:
pidstat -p 1821
组合多个监控类型
pidstat允许同时指定多个选项来监控不同类型的资源使用。例如,同时查看CPU使用率和内存使用情况:
pidstat -urd 5 10 上述命令每5秒采样一次,连续采样10次,显示指定进程的CPU使用(-u)、内存使用(-r)以及磁盘I/O(-d)情况。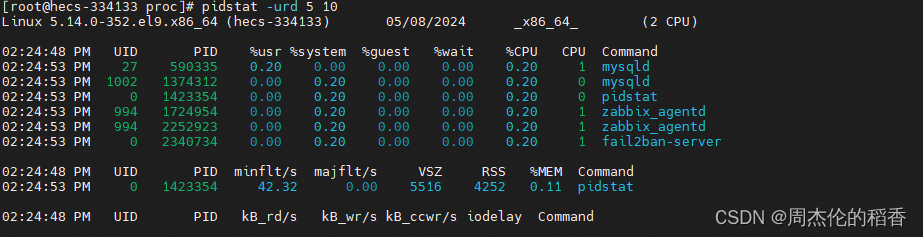
监控线程资源
使用-t选项可以显示线程级别的资源使用情况。这在多线程应用程序中非常有用,可以深入分析线程间的资源分配和消耗:
pidstat -ut 5此命令每5秒显示一次每个线程的CPU使用情况。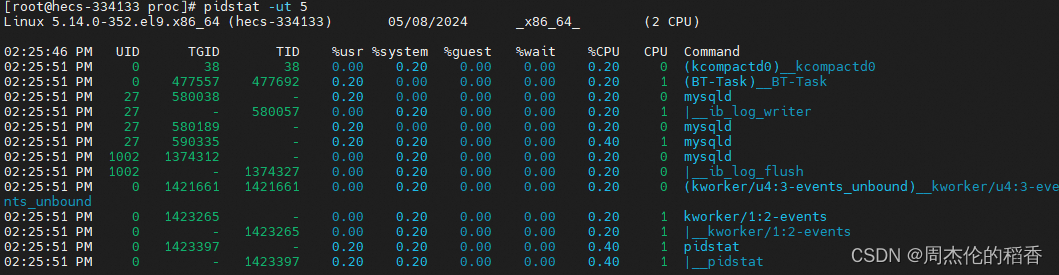
按用户过滤进程
使用-U选项可以指定用户名,仅显示该用户所拥有的进程资源使用情况:
pidstat -U john 5此命令每5秒显示一次用户“john”所拥有的所有进程资源使用情况。
- 统计信息输出:
-h:以人类可读的格式显示数值(如K、M、G等单位)。-V:显示pidstat命令的版本信息。- 高级选项和统计字段:
pidstat提供了更多详细的统计字段和选项,如:
-T:显示进程的线程总数。-L:显示进程的页缓存(page cache)使用情况。-W:显示进程的交换(swapped)内存使用情况。
vmstart
用途
vmstat命令主要用来报告关于系统虚拟内存、进程、CPU活动、磁盘I/O、系统中断等关键系统统计信息。通过这些统计数据,管理员可以快速了解系统的整体性能和健康状况,帮助诊断诸如内存压力、CPU瓶颈、磁盘I/O问题等系统性能问题。
基本用法
vmstat的基本用法如下:
vmstat [options] [interval [count]]
- 选项 (
options):可选,用于指定输出内容的详细程度或指定特定统计项。例如:
-a或--active:显示活跃和非活跃内存信息。-d或--disk:显示磁盘统计信息。-m或--slabs:显示SLAB信息(内核对象缓存)。-s或--stats:仅在开始时打印一次概要统计信息。- 其他选项可能因不同Linux版本而异,可通过
man vmstat获取完整的选项列表。
- 间隔 (
interval):可选,以秒为单位的时间间隔,表示每隔多少时间采集并输出一次系统状态。如果提供了此参数,vmstat将进入循环模式,持续更新输出。- 计数 (
count):可选,指定循环输出的次数。如果不指定或设为0,则会一直循环输出,直到手动停止(通常通过按Ctrl+C中断)。
输出字段
vmstat的输出通常包含多列数据,每列代表不同的统计指标。一些常见的列包括:
- procs:
r:运行队列中的进程数,即正在运行或等待CPU时间片的进程数。如果该值持续较高,可能表明CPU过载。b:阻塞在等待I/O完成的进程数。
- memory:
swpd:虚拟内存中使用的交换空间大小。free:可用物理内存大小。buff:用于文件系统缓存的缓冲区大小。cache:用于文件系统缓存的高速缓存大小。- 在某些系统上,
buff和cache可能合并为一列buf/cach或类似表示。
- swap:
si:从磁盘交换到内存的大小(KB/s)。so:从内存交换到磁盘的大小(KB/s)。高值可能表示内存压力较大。
- io:
bi:块设备接收的块数(块/秒)。bo:块设备发送的块数(块/秒)。这两个值可用于评估磁盘I/O活动。
- system:
in:系统中断次数(每秒)。cs:上下文切换次数(每秒)。高值可能表示进程调度过于频繁。
- cpu:
us:用户态CPU时间占比。sy:内核态CPU时间占比。id:空闲CPU时间占比。wa:等待I/O完成的CPU时间占比。st:被虚拟化系统偷取(如果适用)的CPU时间占比。
使用vmstat时,可以根据需要调整参数来监控特定时间段内的系统行为,或者在排查系统性能问题时持续观察系统状态的变化。结合其他系统监控工具(如top、iostat、free等),可以更全面地分析系统的运行状况。

perf
- 内核 tracepoints 和动态探针:除了硬件事件,
perf还可以利用内核 tracepoints(预定义的内核跟踪点)和动态插入的 kprobes/usdt 探针来捕获特定的软件事件,如系统调用、函数调用、锁争用等。 - 性能数据采集:
perf可以记录采样数据(如 CPU 性能计数器的值)、堆栈跟踪信息,以及基于事件的跟踪数据,并将这些数据保存到文件中以供后续分析。 - 分析与可视化:收集到的性能数据可以使用
perf自带的分析工具或与其他第三方工具(如FlameGraph)结合,生成各种报告和图形化视图(如火焰图),便于直观地识别热点函数、查找性能瓶颈和资源争用情况。
常用子命令与功能:
- perf list:列出当前系统支持的所有性能事件,包括硬件计数器事件、软件事件(tracepoints)、以及由 perf_events 驱动提供的其他事件。这对于选择合适的事件进行性能分析非常有用。
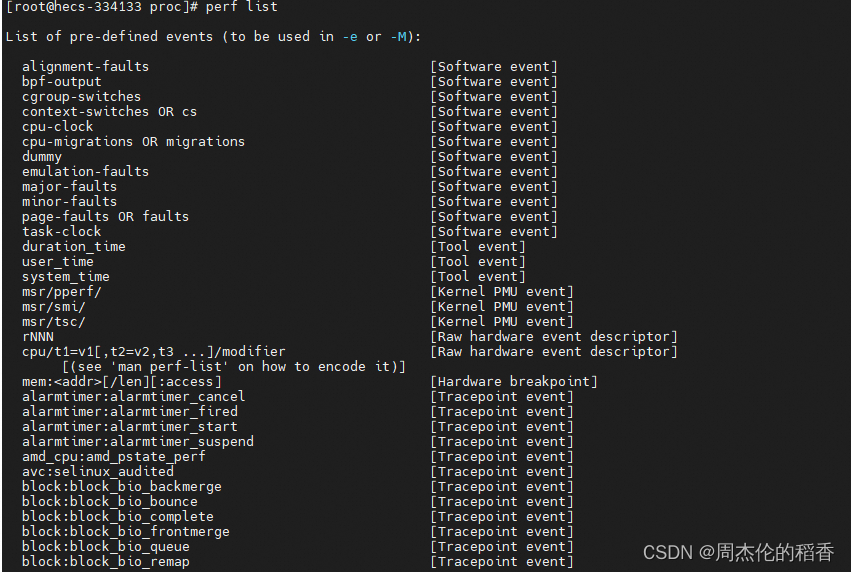
- perf stat:用于快速获取指定命令或进程的整体性能统计数据。它会在命令执行前后采样,并报告诸如 CPU 时间、缓存命中率、指令数、上下文切换等各项指标。
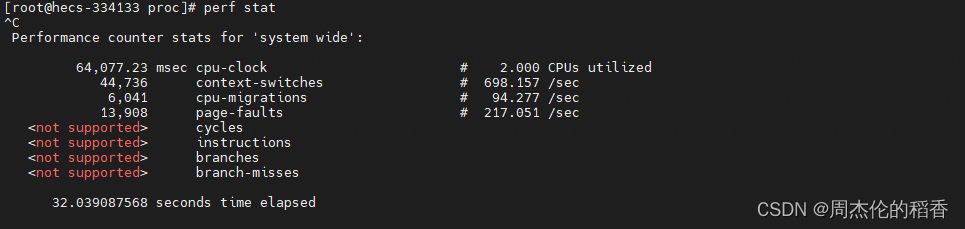
- perf record:记录指定进程在运行期间的性能数据,生成一个
.perf.data文件。此文件可以使用perf report、perf annotate等命令进行详细分析。 - perf report:读取先前使用
perf record生成的数据文件,展示采样数据的分析结果,通常包括按样本数排序的函数列表、调用关系树(caller/callee)、以及每个函数的源码行级别细节。 - perf top:提供类似
top命令的实时视图,显示当前系统或指定进程中占用资源最多的函数(按照 CPU 使用率、指令数等)。这对于实时监控系统或进程的性能热点非常有用。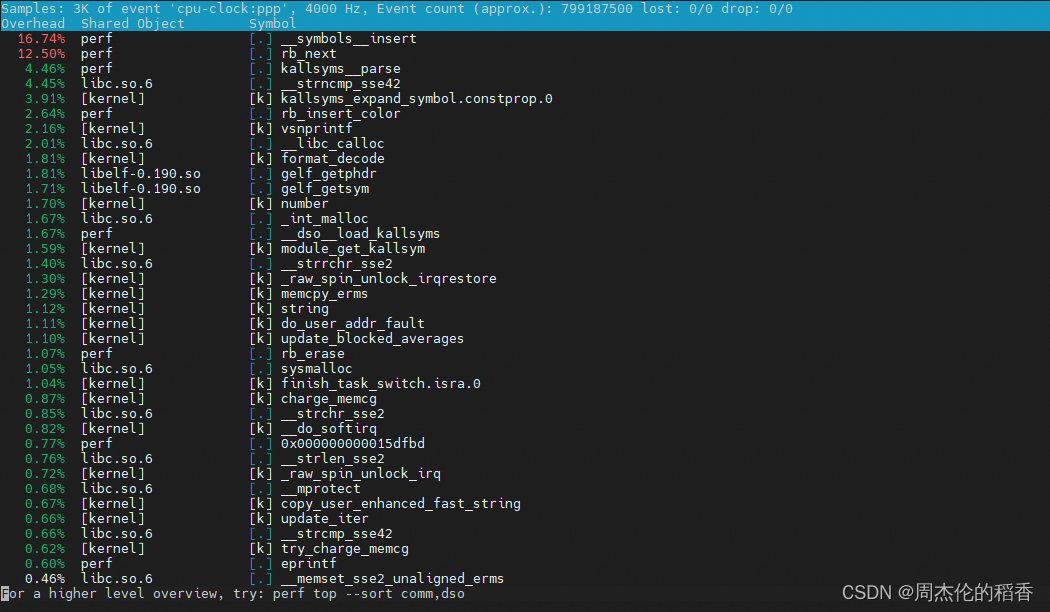
- perf annotate:针对特定函数,展示其源代码并标注每一行代码被采样的次数,有助于识别函数内部的具体热点。
- perf script:处理
perf record收集的事件数据,可以配合-g参数生成适合于 FlameGraph 工具的折叠堆栈格式,用于生成火焰图。
这些只是 perf 命令的一部分功能。实际使用中,根据具体的性能分析需求,可以组合使用不同的子命令和选项。
execsnoop
execsnoop 是一个在 Linux 系统中用于监控进程执行情况的实用工具。它通常被用作一种动态追踪技术,能够实时监测并报告系统上正在运行的所有进程(或特定条件下的进程)所执行的外部命令(即通过 execve() 系统调用启动的新程序)。execsnoop 主要利用 eBPF (Extended Berkeley Packet Filter) 或者早期版本中可能使用的内核跟踪点(tracepoints)来实现这一功能。
以下是 execsnoop 命令的一些关键特性与用途:
- 实时监控:
execsnoop可以实时捕获和显示任何时刻系统上新执行的命令及其相关信息,这对于诊断系统行为、识别异常活动、安全审计、性能分析等场景非常有用。 - 命令行参数捕获:除了记录被执行的命令本身,
execsnoop还可能显示命令执行时携带的参数,这对于理解具体操作的上下文至关重要。 - 过滤与筛选:用户可以指定过滤规则来关注特定类型的进程执行事件,比如仅监控特定用户、特定命令、特定目录下的命令执行,或者基于命令行参数内容进行匹配。
- 性能影响小:由于利用了高效的 eBPF 技术,
execsnoop在提供详细监控能力的同时,对系统性能的影响相对较小,使其适用于生产环境中非侵入式的监控需求。 - 输出格式:
execsnoop的输出通常包括进程 ID(PID)、父进程 ID(PPID)、执行命令的完整路径、命令行参数以及执行时间戳等信息。 - 工具来源:
execsnoop往往是作为 BCC(Berkeley Packet Filter Compiler Collection)工具集的一部分提供的。BCC 是一套用于创建高效内核 tracing 和分析工具的框架,包含了大量基于 eBPF 的实用程序,包括execsnoop。
如果您想在您的 Linux 系统上使用 execsnoop,您需要确保已经安装了 BCC 工具集。在许多现代 Linux 发行版中,可以通过包管理器(如 apt、yum 或 dnf)来安装 BCC。安装后,您就可以在终端中直接运行 execsnoop 命令来开始监控进程执行情况。具体的使用语法和选项可能会因 BCC 版本不同而有所差异,但通常会包括一些基本的过滤选项,允许您根据需要定制监控范围。
dstat
dstat 是一款强大的 Linux 系统监控工具,它设计用于实时展示系统的各项关键性能指标,被誉为“全能型”监控利器。以下是对 dstat 命令的通俗且详细的介绍:
通俗解释
想象你正在经营一家工厂,需要随时掌握生产线上各个环节的工作状态,以便及时调整策略、优化流程,确保整体运营高效顺畅。为此,你可能会在各个关键位置安装各种仪表和传感器,如电流表监测电力消耗,温度计监控设备温度,计数器记录产品产出,等等。这些设备会实时反馈数据,让你一目了然地看到当前生产线的整体运行状况。
在 Linux 系统的世界里,dstat 就扮演了这样一个综合监控仪表板的角色。当运行 dstat 命令时,它会在终端上实时滚动显示一系列系统性能统计数据,这些数据就像是工厂中的各类仪表读数,涵盖了 CPU 使用率、内存使用情况、磁盘 I/O 活动、网络流量等关键性能指标。通过观察 dstat 的输出,系统管理员或开发者可以迅速了解系统的健康状况、资源分配是否合理、是否存在性能瓶颈等问题,就像工厂经理通过监控面板判断生产线是否正常运转一样。
技术层面解释
dstat 的主要特点和优势包括:
- 全面性:它整合了多个传统监控工具的功能,如
vmstat(虚拟内存统计)、iostat(磁盘 I/O 统计)、ifstat(网络接口统计)、netstat(网络连接统计)等,省去了用户需要运行多个命令才能获取完整系统视图的麻烦。 - 灵活性:
dstat允许用户根据需要定制要监控的项目,可以选择显示哪些性能指标,也可以通过参数动态添加或移除监控项。这意味着你可以聚焦于特定的关注点,避免无关信息干扰。 - 实时性:
dstat以秒级乃至更短的时间间隔持续刷新显示数据,确保用户能够及时捕捉到系统状态的变化。这对于快速响应性能波动或故障排查尤其重要。 - 易用性:其简洁的命令行界面使得即使非专业用户也能快速上手。通过简单的命令选项,可以轻松调整输出格式、采样频率、显示列数等。
使用示例
运行最基本的 dstat 命令,会得到一组默认的核心系统统计信息:
dstat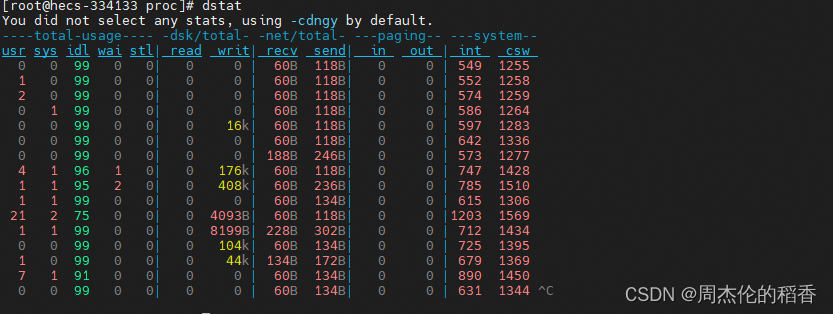
如果你想查看特定的监控项,可以使用参数指定,比如仅关注 CPU 和磁盘 I/O:
dstat -cd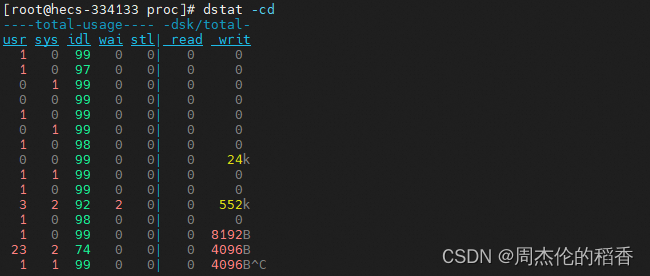
若需以较长时间间隔(如每5秒)监控网络流量和系统负载,可以这样操作:
dstat -tn --interval 5dstat 还支持输出到文件供后续分析,或与其他工具结合使用进行自动化监控。
总之,dstat 是 Linux 系统管理员和开发者手中的得力助手,凭借其全面、灵活、实时的特性,使得对系统性能的监控变得直观、便捷,有助于快速识别和解决问题,优化系统资源利用效率。
总结
有了以上性能工具,在实际遇到问题时我们并不可能全部性能工具跑一遍,这样效率也太低了,所以这里可以先运行常用的工具 top分析系统大概的运行情况然后在具体定位原因。