
热门标签
热门文章
- 1大数据在物联网中的应用_物联网大数据的应用
- 2最详细的Nginx安装【自测可用】_nginx tar.gz安装
- 3Git拉取代码问题_git pull 本地分支必须也是最新的吗
- 4动态规划:分阶段最优化的巧妙技巧_多阶段优化策略
- 5JDK下载安装与配置(详细教程)_jdk下载官网
- 6五大流浏览器内核及其代表
- 7计算机颜色学---CIE 色度图以及饱和度处理_cie色度计算实例
- 8UI设计理念_ui设计理念怎么写
- 9【分享】免费并集多个人工智能于一体的在线使用网站_poe人工智能网站
- 10程序员常用九大算法(二分查找(非递归)、分治、动态规划、KMP、贪心、普里姆、克鲁斯卡尔、迪杰斯特拉、弗洛伊德算法)_程序员常用的十大经典算法
当前位置: article > 正文
Python零基础入门二十之爬虫之抓取有道词典_爬虫获取整个有道词典
作者:神奇cpp | 2024-07-20 06:59:49
赞
踩
爬虫获取整个有道词典
这篇博客在上一篇的基础上,继续深入学习爬虫的技巧。上一篇博客中通过从网页上抓取一张简单的图片简单了解了urllib.request中的模块的用法,今天在学习一个有道词典的例子。
这个例子主要是实现我们在Python中实现有道词典的功能,还是通过抓取有道词典的翻译的核心代码来实现。
首先我们先打开有道词典的网页来踩踩点。
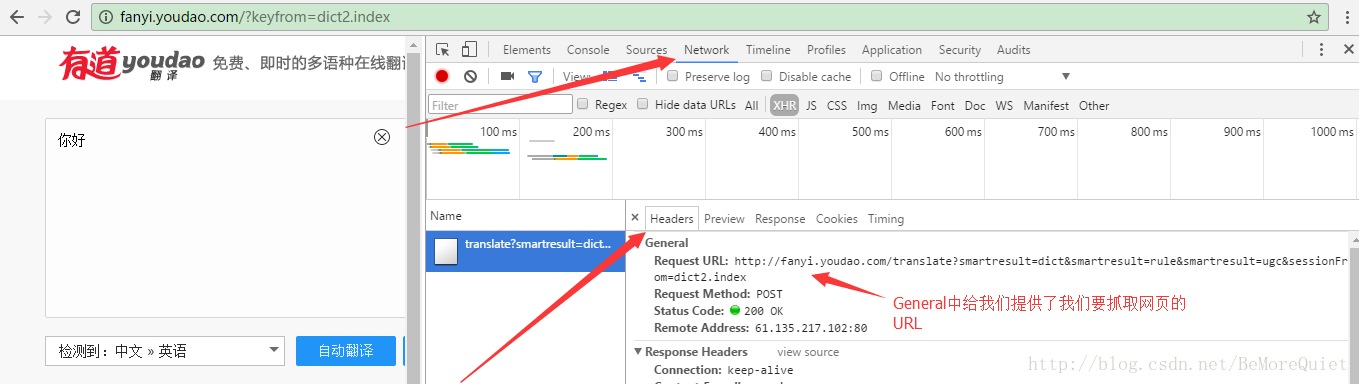
有了url之后还不行,我们这次不是抓取图片,而是要向网页中发送数据,所以要找到网页提交的表单。
继续往下看,便找到了我们的表单数据
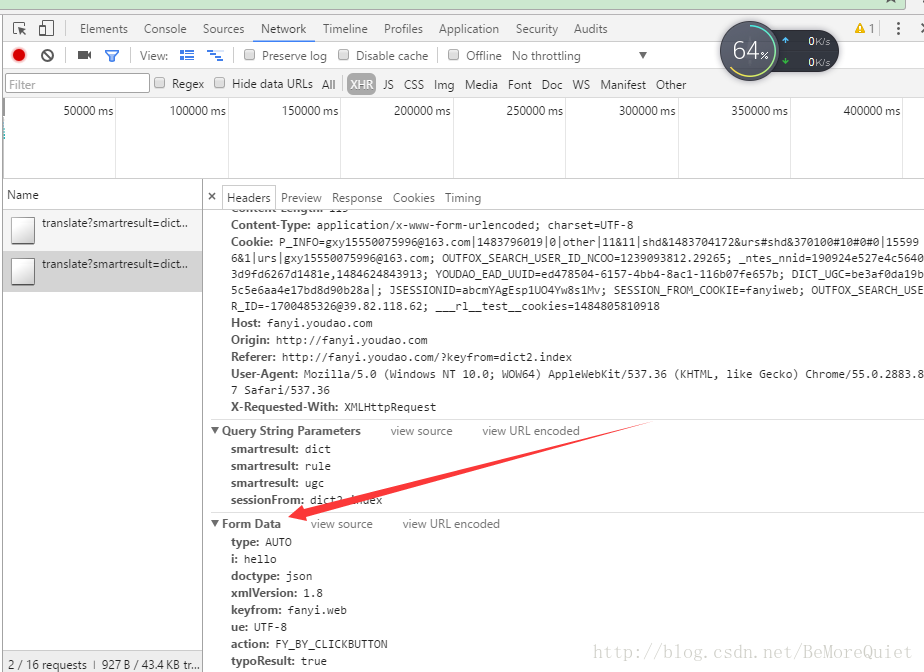
这样之后,我们的踩点工才完成了,下面开始代码的编写。在编写代码之前,我们再说一下urlopen这个函数:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/855664
推荐阅读
相关标签

