
- 1spring boot连接多个数据库_spring boot访问多个数据库用户
- 2前端性能优化--懒加载
- 3聚焦生成式AI,从基石到平台到应用,亚马逊云科技火力全开
- 4链下数据互操作_链下数据和链上数据
- 5Spark大数据技术(Scala)小白教程(一)——大数据技术概述以及环境配置_spark scala教程_spark中scala
- 6SSD7-FFAM | 对嵌入式友好的目标检测网络
- 7Parallels Desktop 19 for mac破解版安装激活使用指南
- 8ubuntu20.04 Auditd使用教程(监控所有用户命令输入记录,包括常用命令、运行脚本、pip安装、apt安装等)(操作监控、输入监控、命令监控、操作日志、命令日志、history命令)失败了_ubuntu auditd
- 9大模型炼丹术:大模型微调总结及实现_微调与调优
- 10Go语言:UUID 的生成与解析_uuid.newv4()
Mamba YOLO | 超越所有YOLO系列模型?
赞
踩
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
论文作者 | Zeyu Wang等
编辑 | 自动驾驶之心
写在前面&笔者的个人理解
在深度学习技术快速进步的推动下,YOLO系列为实时物体探测器树立了新的基准。研究人员在YOLO的基础上不断探索重新参数化、高效层聚合网络和无锚技术的创新应用。为了进一步提高检测性能,引入了基于Transformer的结构,显著扩展了模型的感受野,并实现了显著的性能增益。然而,这种改进是有代价的,因为自注意机制的平方复杂性增加了模型的计算负担。幸运的是,状态空间模型(SSM)作为一种创新技术的出现有效地缓解了平方复杂性带来的问题。鉴于这些进展,我们介绍了一种新的基于SSM的目标检测模型Mamba YOLO。Mamba YOLO不仅优化了SSM基础,而且专门适用于目标检测任务。考虑到SSM在序列建模中的潜在局限性,如感受野不足和图像定位较弱,我们设计了LSBlock和RGBlock。这些模块能够更精确地捕捉局部图像相关性,并显著增强模型的稳健性。在公开的基准数据集COCO和VOC上的大量实验结果表明,Mamba YOLO在性能和竞争力方面都超过了现有的YOLO系列模型,展示了其巨大的潜力和竞争优势。
开源链接:https://github.com/HZAI-ZJNU/Mamba-YOLO
总结来说,本文的主要贡献如下:
我们提出了基于SSM的Mamba YOLO,为YOLO在目标检测中建立了一个新的基线,并为未来基于SSM开发更高效、更有效的检测器奠定了坚实的基础。
我们提出了ODSSBlock,其中LS Block有效地提取输入特征图的局部空间信息,以补偿SSM的局部建模能力。通过重新思考MLP层的设计,我们将门控聚合的思想与具有残差连通性的有效卷积相结合,提出了RG块,有效地捕获了局部依赖性并增强了模型的鲁棒性。
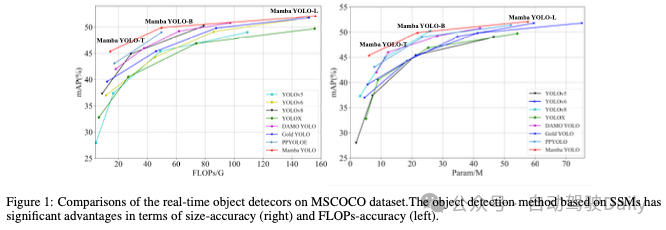
我们设计了一组不同规模的Mamba YOLO(微小/基本/大型)模型,以支持不同规模和规模的任务部署,并在COCO和VOC两个数据集上进行了实验,如图1所示,这表明与现有最先进的方法相比,我们的Mamba YOLO实现了显著的性能改进。
相关工作回顾
Real-time Object Detectors
YOLOv1到YOLOv3是YOLO系列的早起工作,它们的性能改进都与主干网的改进密切相关,使DarkNet得到了广泛的应用。YOLOv4引入了大量残差结构设计提出的CSPDaknet53骨干网,有效降低了计算冗余,实现了高性能的特征表达和高效的训练。YOLOv7提出了E-ELAN结构,以在不破坏原有模型的情况下增强模型能力。Yolov8结合了前几代YOLO的特点,采用了具有更丰富梯度流的C2f结构,重量轻,在考虑准确性的同时适应不同的场景。最近,Gold Yolo引入了一种名为GD(Gather and Distribute)的新机制,该机制通过自注意操作实现,以解决传统特征金字塔网络和Rep PAN的信息融合问题,并成功实现了SOTA。事实上,传统的细胞神经网络由于其局部感受野和层次结构设计,在图像尺度变化剧烈、背景复杂和多视角干扰等挑战方面存在一定的局限性。
End-to-end Object Detectors
DETR首次将Transformer引入到对象检测中,使用了Transformer编码器-解码器架构,该架构绕过了传统的手工组件,如锚生成和非最大值抑制,将检测视为一个简单的集成预测问题。可变形DETR引入了可变形注意力,这是Transformer注意力的一种变体,用于对参考位置周围的稀疏关键点集进行采样,解决了DETR在处理高分辨率特征图方面的局限性。DINO集成了混合查询选择策略、可变形注意力和注入噪声的演示训练,并通过查询优化提高了性能。RT-DETR提出了一种混合编码器来解耦尺度内交互和跨尺度融合,以实现高效的多尺度特征处理。然而,DETR在训练收敛性、计算成本和小目标检测方面存在挑战,YOLO序列在小模型领域仍然是精度和速度平衡的SOTA。
Vision State Space Models
状态空间模型是近年来研究的热点。基于对SSM的研究,Mamba在输入大小上表现出线性复杂性,并解决了Transformer在建模状态空间的长序列上的计算效率问题。在广义视觉主干领域,Vision Mamba提出了一种基于SSM的纯视觉主干模型,标志着Mamba首次被引入视觉领域。VMamba引入了交叉扫描模块,使模型能够对2D图像进行选择性扫描增强视觉处理,并展示了在图像分类任务上的优势。LocalMamba专注于视觉模型的窗口扫描策略,优化视觉信息以捕获局部依赖关系,并引入动态扫描方法来搜索不同层的最佳选择。MambaOut探讨了Mamba架构在视觉任务中的必要性,指出SSM对于图像分类任务不是必要的,但它对于遵循长序列特征的检测和分割任务的价值值得进一步探索。在下游视觉任务中,Mamba 也被广泛应用于医学图像分割和遥感图像分割的研究。受VMamba在视觉任务领域取得的显著成果的启发,本文首次提出了Mamba YOLO,这是一种新的SSM模型,旨在考虑全局感觉场,同时展示其在目标检测任务中的潜力。
方法
准备工作
源于状态空间模型(SSM)的结构化状态空间序列模型S4和Mamba都源于一个连续系统,该系统通过隐式潜在中间状态将单变量序列映射到输出序列中。这种设计不仅桥接了输入和输出之间的关系,而且封装了时间动态。该系统的数学定义如下:


Mamba通过使用固定的离散化规则fA和fB将该连续系统应用于离散时间序列数据,以将参数A和B分别转换为其离散对应物,从而将系统更好地集成到深度学习架构中。用于此目的的常用判断方法是零阶保持(ZOH)。离散版本可以定义如下:
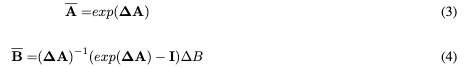
转换后,模型通过线性递归形式进行计算,其定义如下:

整个序列变换也可以用卷积形式表示,其定义如下:

整体结构
Mamba YOLO的体系结构概述如图2所示。我们的目标检测模型分为ODMamba主干部分和颈部部分。ODMamba由简单Stem、下采样block组成。在neck,我们遵循PAN-FPN的设计,使用ODSBlock模块而不是C2f来捕获更梯度丰富的信息流。主干首先通过Stem模块进行下采样,得到分辨率为H/4、W/4的2D特征图。因此,所有模型都由ODSBlock和VisionVue合并模块组成,用于进一步的下采样。在颈部,我们采用了PAFPN的设计,使用ODSSBlock代替C2f,其中Conv全权负责下采样。

Simple Stem:Modern Vision Transformers(ViTs)通常使用分割块作为其初始模块,将图像划分为不重叠的片段。该分割过程是通过核大小为4、步长为4的卷积运算来实现的。然而,最近的研究,如EfficientFormerV2的研究表明,这种方法可能会限制ViT的优化能力,影响整体性能。为了在性能和效率之间取得平衡,我们提出了一种精简的语音层。我们使用两个步长为2、内核大小为3的卷积,而不是使用不重叠的补丁。
Vision Clue Merge:虽然卷积神经网络(CNNs)和视觉Transformer(ViT)结构通常使用卷积进行下采样,但我们发现这种方法会干扰SS2D在不同信息流阶段的选择性操作。为了解决这一问题,VMamba分割2D特征图,并使用1x1卷积来降低维度。我们的研究结果表明,为状态空间模型(SSM)保留更多的视觉线索有利于模型训练。与传统的尺寸减半相比,我们通过以下方式简化了这一过程:1)删除规范;2) 拆分维度图;3) 将多余的特征图附加到通道维度;4) 利用4倍压缩逐点卷积进行下采样。与使用步长为2的3x3卷积不同,我们的方法保留了SS2D从上一层选择的特征图。
ODSS Block
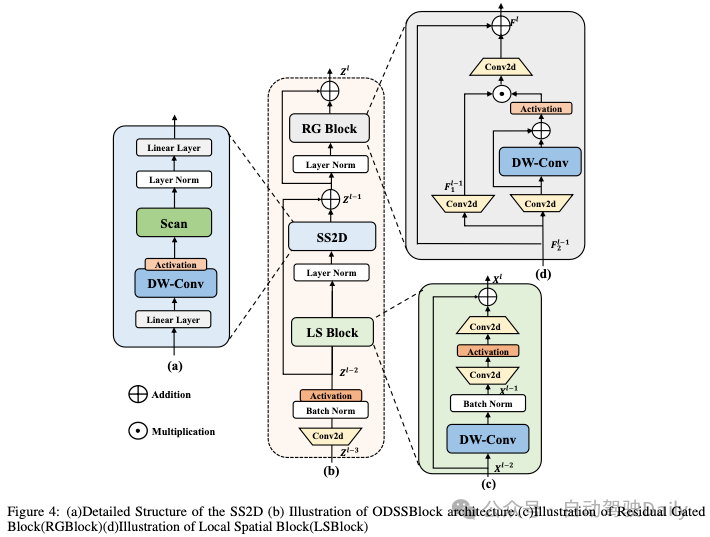
如图4所示,ODSS Block是Mamba YOLO的核心模块,它在输入阶段经过一系列处理,使网络能够学习到更深入、更丰富的特征表示,同时通过批量归一化保持训练推理过程的高效和稳定。

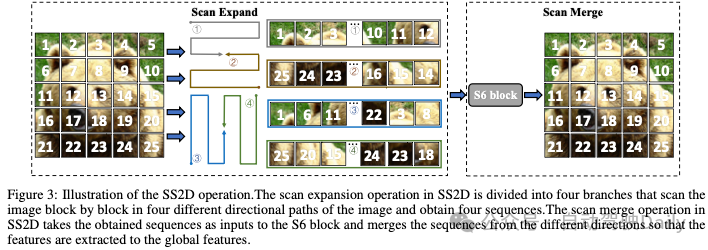
扫描扩展、S6块和扫描合并是SS2D算法的三个主要步骤,其主要流程如图3所示。扫描扩展操作将输入图像扩展为一系列子图像,每个子图像表示特定的方向,并且当从对角视点观察时,扫描扩展操作沿着四个对称方向进行处理,这四个方向分别是自上而下、自下而上、左右和单词从右到左。这样的布局不仅全面覆盖了输入图像的所有区域,而且通过系统的方向变换为后续的特征提取提供了丰富的多维信息库,从而提高了图像特征多维捕捉的效率和全面性。然后,在S6块操作中将这些子图像提交给特征提取,并且最后通过扫描合并操作,将这些子图像合并在一起以形成与输入图像相同大小的输出图像。
LocalSpatial Block
Mamba 体系结构已被证明在捕获远程地面依赖性方面是有效的。然而,在处理涉及复杂尺度变化的任务时,它在提取局部特征方面面临一定的挑战。在图4(c)中,本文提出了LocalSpatial Block来增强对局部特征的捕获。具体而言,对于给定的输入特征,它首先进行深度可分离卷积,该卷积在不混合信道信息的情况下单独地对每个输入信道进行操作。有效提取输入特征图的局部空间信息,同时降低计算成本和参数数量,然后进行批量归一化,在减少过拟合的同时提供一定程度的正则化效果,得到的中间状态定义为:

中间状态通过1×1卷积混合通道信息,并通过激活函数更好地保持信息的分布,使模型能够学习更复杂的特征表示,这些特征表示能够从输入特征图中提取丰富的多尺度上下文信息。在LSBlock中,激活函数使用非线性GELU来改变特征的通道数量,而不改变空间维度,从而增强特征表示。最后,通过残差拼接将原始输入与处理后的特征融合。使模型能够理解和集成图像中不同维度的特征,从而提高对比例变化的鲁棒性。
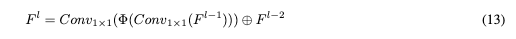
ResGated Block
最初的MLP仍然是最广泛采用的,VMamba架构中的MLP也遵循Transformer设计,对输入序列进行非线性变换,以增强模型的表达能力。最近的研究表明,门控MLP在自然语言处理中表现出强大的性能,我们发现门控机制对视觉具有同样的潜力。在图4(d)中,本文提出ResGated Block的简单设计旨在以低计算成本提高模型的性能,RG Block从输入创建两个分支和,并在每个分支上以1×1卷积的形式实现全连接层。

在的分支上使用深度分离卷积作为位置编码模块,并且在训练过程中通过残差级联更有效地反映梯度,这具有更低的计算成本,并且通过保留和使用图像的空间结构信息来显著提高性能。RG块采用非线性GeLU作为激活函数来控制每个级别的信息流,然后通过元素乘法与的一个分支合并,然后通过1x1卷积与全局特征进行细化以混合信道信息,最后通过残差级联与原始输入与隐藏层中的特征求和。RG Block可以捕获更多的全局特征,同时只带来轻微的计算成本增加,由此产生的输出特征定义为:
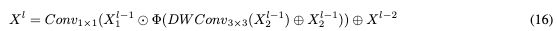
实验结果

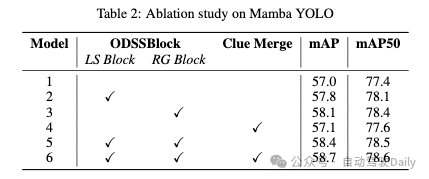
在VOC0712数据集上进行Mamba YOLO以进行消融实验,测试模型为Mamba YOLO-T。我们的结果表2显示,线索合并为状态空间模型(SSM)保留了更多的视觉线索,也为ODSS块结构确实是最优的断言提供了证据。
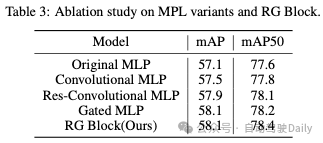
RGBlock通过逐像素获取全局相关性和全局特征来捕获逐像素的局部相关性。关于RG块设计的细节,我们还考虑了多层感知基础之上的三种变体:1)卷积MLP,它将DW-Conv添加到原始MLP;2) Res卷积MLP,其以残差级联方式将DW-Conv添加到原始MLP;3) 门控MLP,一种在门控机制下设计的MLP变体。图5说明了这些变体,表3显示了原始MLP、RG块和VOC0712数据集中每个变体的性能,以验证我们使用测试模型Mamba YOLO-T对MLP分析的有效性。我们观察到,卷积的引入并不能有效提高性能,其中在图5(d)门控MLP的变体中,其输出由两个元素乘法的线性投影组成,其中一个由残差连接的DWConv和门控激活函数组成,这实际上使模型能够通过分层结构函数传播重要特征。该实验表明,在处理复杂图像任务时,引入的卷积性能的提高与门控聚合机制非常相关,前提是它们适用于残差连通性的情况。
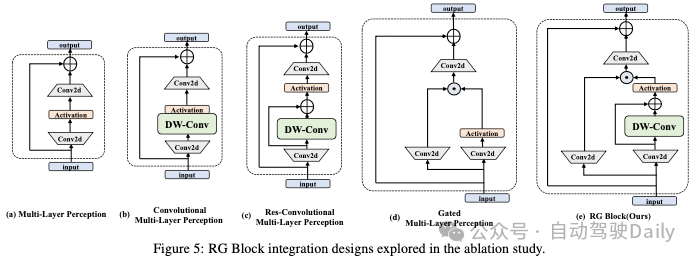
为了评估我们提出的基于ssm的Mamba YOLO架构的优越性和良好的可扩展性,我们将其应用于除目标检测领域外的实例分割任务。我们采用Mamba YOLO-T之上的v8分割头,并在COCOSeg数据集上对其进行训练和测试,通过Bbox AP和Mask AP等指标评估模型性能。Mamba YOLO-T-seg在每种尺寸上都显著优于YOLOv5和YOLOv8的分割模型。RTMDet基于包含深度卷积大内核的基本构建块,在动态标签分配过程中引入软标签来计算匹配成本,并在几个视觉任务中表现出出色的性能,Mamba YOLO-T-seg与Tiny相比,在Mask mAP上仍保持2.3的优势。结果如表4和图8所示。
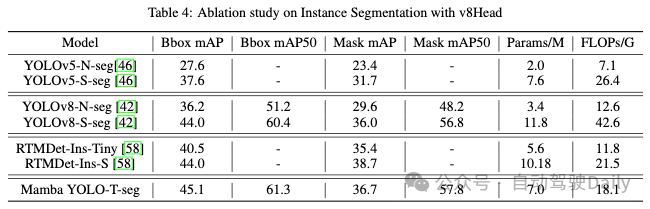

其他可视化:
结论
在本文中,我们重新分析了CNN和Transformer架构在目标检测领域的优缺点,并指出了它们融合的局限性。基于此,我们提出了一种基于状态空间模型架构设计并由YOLO扩展的检测器,我们重新分析了传统MLP的局限性,并提出了RG块,其门控机制和深度卷积残差连通性被设计为使模型能够在分层结构中传播重要特征。此外,为了解决Mamba架构在捕获局部依赖性方面的局限性,LSBlock增强了捕获局部特征的能力,并将它们与原始输入融合,以增强特征的表示,这显著提高了模型的检测能力。我们的目标是建立一个新的YOLO基线,前提是Mamba YOLO具有高度竞争力。我们的工作是对Mamba 架构在实时目标检测任务中的首次探索,我们也希望为该领域的研究人员带来新的想法。
参考
[1] Mamba YOLO: SSMs-Based YOLO For Object Detection
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


