
- 1探索开源新声:深入Fish Speech,革新文本转语音技术的先锋!
- 2消息中间件MQ——RabbitMQ、RocketMQ、Kafka_使用什么mq
- 3手把手教你在linux中部署stable-diffusion-webui
- 4【零基础学flink】flink DataStream API 详解
- 5LaTex使用技巧10:公式中的各种英文字体_latex 英文字体
- 6基于sklearn的七种回归算法预测波士顿房价_波士顿房价预测sklearn
- 7【数据结构笔记备忘】单链表,双向链表,循环单双链表_哪些排序用到单链,双链,循环链
- 8使用Java替换字符串中的占位符${xx}_java根据${}替换
- 9JAVA面试题分享四百三十九:要保证消息不丢失,又不重复,消息队列怎么选型?_面试消息队列保证消息不丢失
- 10探索React Apollo:下一代GraphQL客户端
用 YOLO V4训练自己的数据集_yolov4训练自己的数据集
赞
踩
一.搭建实验环境
1.下载Anoconda管理相关环境,将pytorch环境搭建在Anoconda上,经过多次实验,由于python用的3.6版本,最终较为兼容的版本是torch1.4.0和torchvision0.5.0
2.安装PyCharm,配置好运行环境
3.Pytorch环境中其他库的安装, scipy==1.2.1
numpy==1.17.0
matplotlib==3.1.2
opencv_python==4.1.2.30
torch==1.2.0
torchvision==0.4.0
tqdm==4.60.0
Pillow==8.2.0
h5py==2.10.0
二. 准备数据集
首先,需要准备一个标注好的数据集。这通常包括图像文件和相应的标注文件,标注文件中记录了图像中目标物体的位置(边界框)和类别。
- 图像文件:可以是常见的图像格式,如JPG、PNG等。
- 标注文件:通常采用VOC格式或YOLO格式。对于VOC格式,每个图像对应一个XML文件,其中包含了物体的边界框坐标和类别信息。对于YOLO格式,标注信息通常直接写在文本文件中,每行代表一个物体,包含类别和边界框坐标。
- 训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
- 训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
 编辑
编辑
三. 数据集的处理
在完成数据集的摆放之后,我们需要利用voc_annotation.py获得训练用的2007_train.txt和2007_val.txt。
修改voc_annotation.py里面的参数。第一次训练可以仅修改classes_path,classes_path用于指向检测类别所对应的txt。
训练自己的数据集时,可以自己建立一个cls_classes.txt,里面写自己所需要区分的类别。
model_data/cls_classes.txt文件内容为:
```python
cat
dog
...
```
修改voc_annotation.py中的classes_path,使其对应cls_classes.txt,并运行voc_annotation.py。
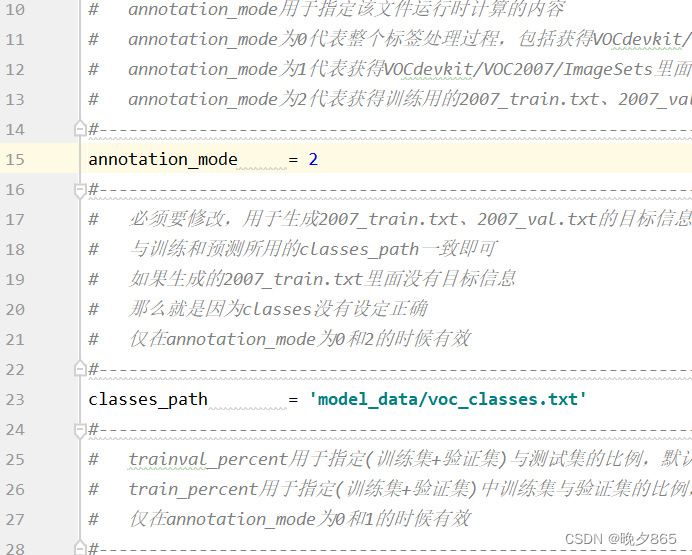
如上图所示,打开voc_annotation.py将annotation_mode设置为2,目的是获得训练用2007_train.txt以及2007_val.txt。此文件中的classes_path需要指向检测类别对应的文件,本实验用的VOC数据集,路径为根目录下model_data中voc_classes.txt文件,如果是训练自己建立的数据集,可以在model_data中建立一个新的txt文件并将classes_path指向其路径即可。
四.开始训练数据集
打开train.py文件,如下图所示:
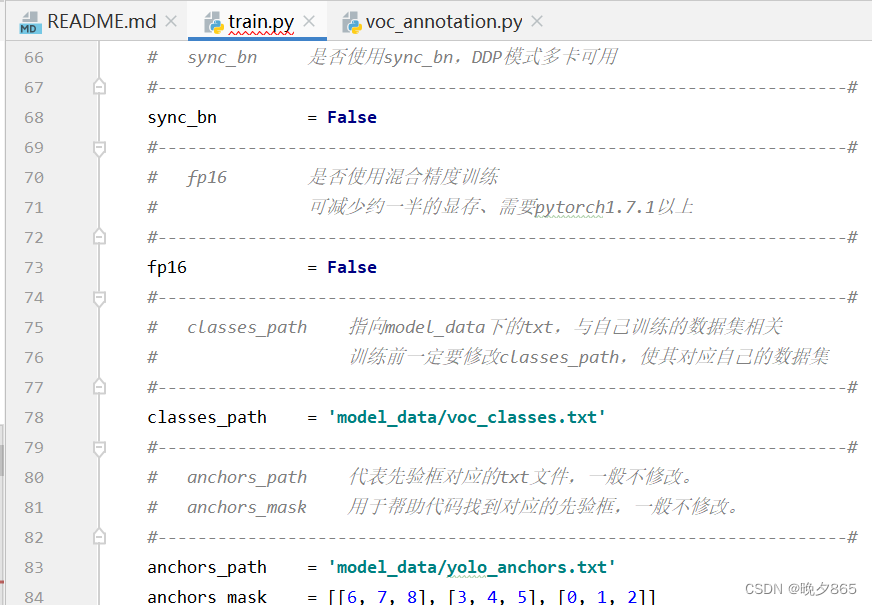
文件中的第78行,classes.path需要对应voc_annotation.py中的classes.path,再将预权重文件放入model_data中,设置好后开始训练。
训练多个Epoch后,权值文件会生成到根目录中的logs里
五.训练结果预测
训练结果预测需要先打开根目录下的yolo.py文件设置相关路径,如图所示

训练结果预测需要用到两个文件,分别是yolo.py和predict.py。在yolo.py里面修改model_path以及classes_path。
model_path指向训练好的权值文件,在logs文件夹里。
classes_path指向检测类别所对应的txt。**
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
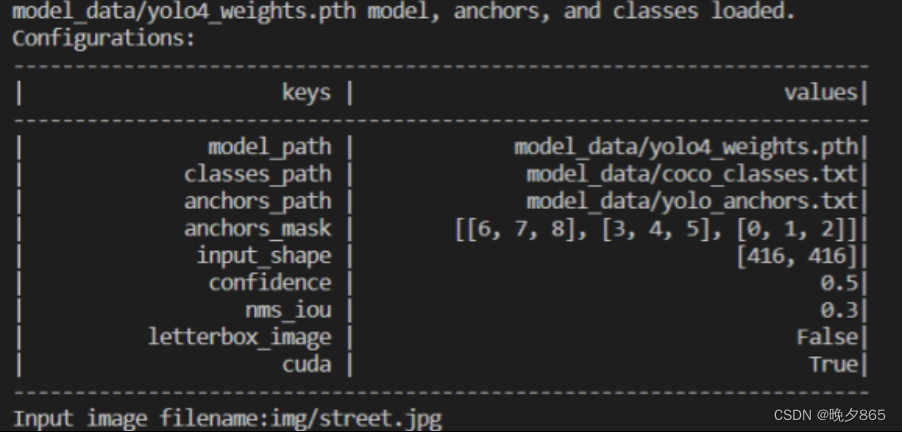
输入图片路径结果如下:
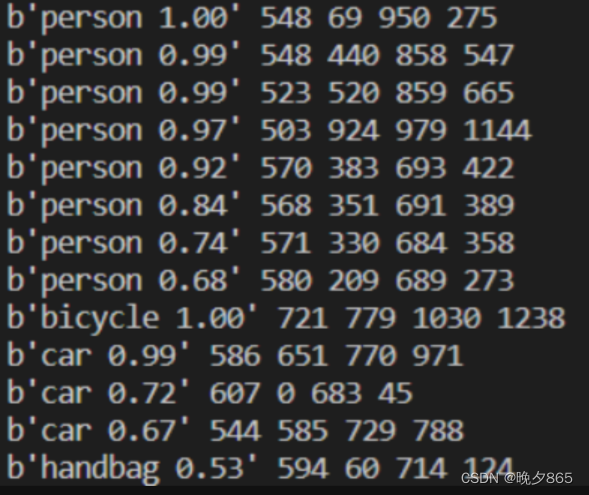
六、实验结果与分析
经过多次尝试和优化,我们成功训练了一个针对自定义数据集的YOLOv4目标检测模型。在测试集上,模型取得了较高的精度和召回率,能够满足实际应用需求。同时,我们也对实验结果进行了详细的分析和讨论,总结了模型性能提升的关键因素和进一步优化的方向。

