基于Opencv的车牌识别系统(毕业设计可用)
赞
踩

系统架构
-
图像采集:首先,通过摄像头等设备捕捉车辆图像。图像质量直接影响后续处理的准确性,因此高质量的图像采集是基础。
-
预处理:对获取的原始图像进行预处理,包括灰度化、降噪、对比度增强和边缘检测等。这些操作旨在提高车牌区域与背景之间的对比度,便于后续的车牌定位。
-
车牌定位:此阶段运用形态学操作、边缘检测(如Canny算法)、模板匹配或基于机器学习的方法(如Haar特征分类器、HOG特征+SVM)来定位图像中的车牌区域。算法需具备一定的鲁棒性,以适应不同光照、角度变化和遮挡情况下的车牌检测。
-
车牌校正与分割:找到车牌区域后,根据车牌的几何特性进行倾斜校正,使车牌图像处于水平状态。随后,通过投影分析、连通域分析等方法分割出单个字符,为字符识别做准备。
-
字符识别:对分割后的字符图像进行特征提取,常用的有基于像素特征、形状特征或深度学习特征的方法。之后,利用分类器(如SVM、KNN)或深度学习模型(如CNN)进行字符识别。近年来,深度学习尤其是卷积神经网络(CNN)在字符识别上的应用显著提高了识别率。
-
结果输出:将识别出的字符序列组合成完整的车牌号,并进行合法性验证(如检查车牌号是否符合当地的车牌号码规则),最终输出识别结果。
技术亮点
- 高精度与实时性:通过优化算法和深度学习模型,系统能在保证识别精度的同时,实现实时处理大量视频流的能力。
- 鲁棒性:针对不同的光照条件、车牌类型、拍摄角度等因素,系统设计有较强的适应性和抗干扰能力。
- 易部署与扩展:基于OpenCV的开源平台,系统易于开发和维护,且可根据需求灵活添加新功能或改进现有算法。
应用场景
- 智能交通系统:自动识别违章车辆,提高交通执法效率。
- 停车场管理:实现快速车辆进出管理,提升用户体验。
- 安防监控:辅助犯罪侦查,增强公共安全。
- 车辆追踪与管理:为企业或政府机构提供车辆追踪与资产管理方案。
总之,基于OpenCV的车牌识别系统通过集成先进的计算机视觉技术和深度学习算法,为现代城市交通管理和车辆智能化提供了强有力的技术支撑,展现了人工智能在实际应用中的巨大潜力。
使用方法:
版本:python3.4.4,opencv3.4和numpy1.14和PIL5
下载源码,并安装python、numpy、opencv的python版、PIL,运行surface.py即可。
算法实现:
算法的设计灵感汲取自网络资源,其核心步骤包括图像边缘检测与车牌色彩分析以实现车牌定位,随后运用字符识别技术辨认车牌号码。具体实施中,predict函数扮演了关键角色,它不仅负责车牌的精确定位,也涵盖了字符识别的逻辑。为了提升代码可读性和理解深度,我已详尽地添加注释,确保每一步操作背后的意图清晰可见。关于字符识别机制,本项目采纳了OpenCV库中的SVM(支持向量机)方法,其代码框架直接引用自OpenCV自带的实例代码,特别是StatModel与SVM类的使用,这为字符分类提供了坚实的理论与实践基础。
值得注意的是,SVM模型的训练数据源自EasyPR项目C++版本的GitHub仓库,受限于训练样本的数量与多样性,实际应用时,尤其是首个汉字识别上,可能会遇到一定的误识率。为便于研究与调整,我已随源代码一同提供了EasyPR训练样本集,位于train/目录下。若欲开展重新训练,只需解压缩该样本至项目根目录,并移除原有的模型文件svm.dat与svmchinese.dat。
此外,有必要指出的是,当前算法代码保持在约500行的精简规模,但其性能表现,特别是车牌定位的准确性,受到输入图像的分辨率、色彩偏差以及拍摄距离的影响较大。测试案例集中于test/目录下尺寸较小的车牌图像,而对于其他尺寸或条件的图片,可能因像素尺寸不匹配而无法有效识别。为此,用户需根据实际情况调整config配置文件中的相关参数以优化识别效果。本项目意在提供一个启发性的起点,展示一种可行的解决方案思路,期待能激发更多创新与改进。
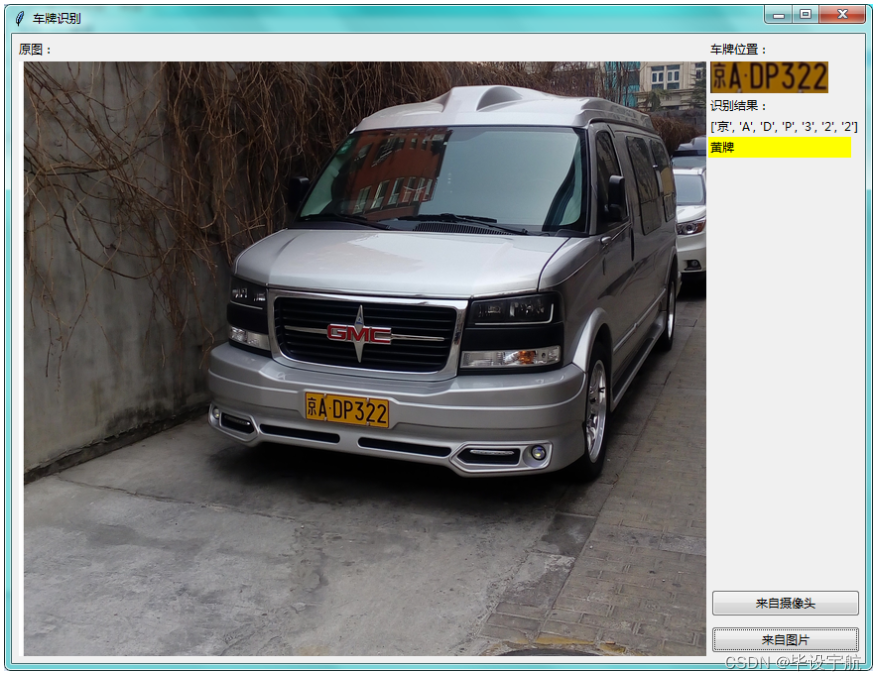
界面实现效果: