
- 1ShardingSphere 5.0.0 实现按月水平分表_shardingsphere按月分表
- 2【Spark】RDD入门编程实践(完整版)_rddfffffrrrdfffdrdrrrrddrdd4rrrrdrrrrrddrdrdrr4drd
- 3docker安装大数据环境(centos 7)_docker 安装大数据
- 4LeetCode14. 最长公共前缀_leet code 14
- 5Sora背后的技术原理解析(简单易懂版本)_sora技术原理
- 6git撤回已推送远程的提交_git撤回push到远程的
- 7Mac自带apache+php环境配置_mac自带apache开启伪静态
- 8TCP头部详解
- 9中缀表达式转化为后缀表达式 头歌--12关_头歌十二关本关任务:输入一个中缀算术表达式,将其转换为后缀表达式。运算符包括+
- 10JAVA17---安装+配置环境变量 JAVA安装完整教学_java 17安装
python代码实现及Logistic回归(逻辑回归)_python实现logistic回归
赞
踩
简介
逻辑回归是机器学习中非常重要的一种统计方法,广泛用于分类问题。尽管名为“回归”,逻辑回归实际上是用来做二分类的工具,例如判断邮件是否为垃圾邮件,或者一个患者是否有某种疾病。逻辑回归的优点在于它的输出可以被解释为概率,这为决策提供了便利,而且它相对简单,易于实现,是初学者入门机器学习的良好起点。
目标
本文将全面解析逻辑回归模型,包括它的结构、学习目标、优化算法,以及如何使用 Python 进行实现。读者将从基本的数学原理了解到如何在实际数据集上应用逻辑回归,最终能够自己动手编写代码,建立并优化逻辑回归模型。文章的结构清晰,旨在帮助刚接触人工智能的大学新生,理解并掌握逻辑回归的核心概念和应用。


一、逻辑回归模型结构
1.1 基本概念
模型定义
逻辑回归(Logistic Regression,简称 LR)是一种广义线性模型(GLM),通常用于分类问题。与传统的线性回归模型(预测连续值输出)不同,逻辑回归预测的是一个概率值,表示为介于 0 和 1 之间的数。这使得它非常适合于二分类问题,比如预测一个电子邮件是不是垃圾邮件。
模型功能
逻辑回归通过输入特征的加权和,使用 sigmoid 函数将任意实数映射到 (0, 1) 区间,输出一个概率值。Sigmoid 函数的 S 形曲线确保了输出值在 0 到 1 之间,这个值表示样本属于正类(通常编码为 1)的概率。

决策边界
逻辑回归模型的决策边界是功能的关键,这是一个用来决定样本分类的边界。在逻辑回归中,这个边界是线性的,意味着它可以用一条直线(或者在多维空间中是一个超平面)来表示。当逻辑回归模型的输出(概率)等于 0.5 时,对应的输入特征组合就位于这条决策边界上。

1.2 数学表达
逻辑回归的数学基础非常重要,理解它有助于深入掌握模型的工作原理。模型本质上是一个概率估计,通过最大似然估计(MLE)来优化参数。公式表达为:
其中 ( p ) 是给定输入特征 ( x ) 下样本属于正类的概率,( w ) 表示模型参数。
逻辑回归的目标是调整 ( w ) 的值,使得模型的预测尽可能接近实际的标签。

二、学习目标和损失函数
2.1 理解分类目标
预测和实际的对比
在使用逻辑回归进行分类时,核心目标是确保模型的预测概率尽可能接近实际的标签。例如,如果一个样本的实际标签是 1(正类),逻辑回归模型预测这个样本属于正类的概率应该接近 1。相反,如果样本的标签是 0(负类),则模型的预测概率应接近 0。这种方式帮助我们评价和优化模型的性能,确保模型能够正确区分不同类别的样本。
2.2 最大似然估计
最大似然估计(MLE)是一种在统计模型中估计参数的方法,它寻找能够使观测到的数据出现概率最大的参数值。在逻辑回归中,MLE尝试找到一组参数,使得给定参数下,观测到的样本标签的概率最大化。这通常通过优化一个称为似然函数的表达式来实现,该函数是对所有数据点的预测概率的乘积。
2.3 交叉熵损失
交叉熵损失函数解释
交叉熵损失函数是评估逻辑回归模型性能的一个关键工具。它衡量的是模型预测的概率分布与实际标签的概率分布之间的差异。公式可以表示为:

其中 ( y ) 是实际标签,( p ) 是预测为正类的概率。这个损失函数的值越小,表示模型的预测结果与实际情况越接近。
损失函数与预测准确度的关系
一般来说,交叉熵损失函数的值越小,模型的分类准确度越高。通过训练过程中损失函数的下降趋势,我们可以观察到模型性能的改善。实际操作中,可以通过绘制训练周期与损失值的图表来直观展示这一过程,帮助理解模型优化的效果。

三、优化算法
3.1 梯度下降法详解
算法原理
梯度下降法是一种用于优化逻辑回归模型参数的流行算法,其核心思想是利用函数的梯度(或斜率)来确定参数更新的方向。梯度指示了函数增长最快的方向,因此在优化过程中,我们沿着梯度的相反方向(下降最快的方向)调整参数,以寻找函数的最小值。
梯度下降可以通过一个简单的比喻来理解:想象你在山上,需要找到下山的最快路径。在任何位置,你都可以查看周围最陡峭的下坡路,然后朝那个方向迈出一步。梯度下降法就是这样在参数空间中寻找损失函数最小值的方法。
算法步骤
梯度下降的每一步都需要计算损失函数关于每个参数的梯度
其中:
- ( θ ) 表示模型参数。
- ( α ) 是学习率,控制步长的大小。

是损失函数 ( J ) 关于参数 (θ) 的梯度
更新的步骤重复进行,直到满足停止条件,例如梯度的大小小于某个阈值,或达到预定的迭代次数。
在实际操作中,选择合适的学习率是非常关键的,因为太小的学习率会导致收敛过慢,而太大的学习率则可能导致跳过最小值点,使得算法无法正确收敛。

四、Python实现逻辑回归
4.1 准备数据
数据集简介
我们将使用乳腺癌分类数据集(Breast Cancer Wisconsin Diagnostic Dataset)进行逻辑回归的实践。这个数据集包含了乳腺癌肿瘤的各种医学特征,每个样本被标记为恶性或良性,非常适合用来练习二分类问题。选择此数据集的原因是因为它的特征明确、数据质量高,且问题设置符合逻辑回归处理的典型场景。
数据预处理
数据预处理是机器学习中至关重要的一步,它直接影响模型的性能。对乳腺癌数据集的预处理包括:
- 特征选择:从多个可用特征中选择最有影响力的特征,以简化模型并减少计算复杂度。
- 数据标准化:对特征进行标准化处理(如 Z-score 标准化),以消除不同量级特征带来的影响,使模型更稳定,训练更快。
4.2 实现细节
核心函数解释
在Python中实现逻辑回归,我们需要定义几个核心函数:
sigmoid:该函数计算sigmoid激活,用于将线性回归输出转换为概率。
- def sigmoid(z):
- return 1 / (1 + np.exp(-z))
- # initialize_with_zeros:初始化模型参数。
- def initialize_with_zeros(dim):
- w = np.zeros((dim, 1))
- b = 0
- return w, b
- # propagate:计算损失函数和梯度,用于后续的梯度下降步骤。
- def propagate(w, b, X, Y):
- m = X.shape[1]
- A = sigmoid(np.dot(w.T, X) + b)
- cost = (-1 / m) * np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A))
- dw = (1 / m) * np.dot(X, (A - Y).T)
- db = (1 / m) * np.sum(A - Y)
- return dw, db, cost
- # 准确率计算
- def accuracy(Y_true, Y_pred):
- return np.mean(Y_true == Y_pred)

完整代码
- import numpy as np
- import pandas as pd
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import confusion_matrix, accuracy_score
-
- # 定义sigmoid函数
- def sigmoid(z):
- return 1 / (1 + np.exp(-z))
-
- # 初始化参数
- def initialize_with_zeros(dim):
- w = np.zeros((dim, 1))
- b = 0
- return w, b
-
- # 前向和后向传播
- def propagate(w, b, X, Y):
- m = X.shape[1]
- A = sigmoid(np.dot(w.T, X) + b)
- cost = (-1 / m) * np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A))
- dw = (1 / m) * np.dot(X, (A - Y).T)
- db = (1 / m) * np.sum(A - Y)
- return dw, db, cost
-
- # 优化函数
- def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost=False):
- costs = []
- for i in range(num_iterations):
- dw, db, cost = propagate(w, b, X, Y)
- w = w - learning_rate * dw
- b = b - learning_rate * db
- if i % 100 == 0:
- costs.append(cost)
- if print_cost:
- print("Cost after iteration %i: %f" % (i, cost))
- return w, b, costs
-
- # 预测函数
- def predict(w, b, X):
- m = X.shape[1]
- Y_prediction = np.zeros((1, m))
- w = w.reshape(X.shape[0], 1)
- A = sigmoid(np.dot(w.T, X) + b)
- for i in range(A.shape[1]):
- Y_prediction[0, i] = 1 if A[0, i] > 0.5 else 0
- return Y_prediction
-
- # 主函数
- def model(X_train, Y_train, X_test, Y_test, num_iterations=2000, learning_rate=0.5, print_cost=False):
- w, b = initialize_with_zeros(X_train.shape[0])
- w, b, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
- Y_prediction_test = predict(w, b, X_test)
- Y_prediction_train = predict(w, b, X_train)
-
-
- # 计算准确率
- train_accuracy = 100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100
- test_accuracy = 100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100
-
- print("train accuracy: {} %".format(train_accuracy))
- print("test accuracy: {} %".format(test_accuracy))
-
- d = {"costs": costs,
- "Y_prediction_test": Y_prediction_test,
- "Y_prediction_train": Y_prediction_train,
- "train_accuracy": train_accuracy,
- "test_accuracy": test_accuracy,
- "w": w,
- "b": b,
- "learning_rate": learning_rate,
- "num_iterations": num_iterations}
- return d

- import numpy as np
- import numpy as np
- from sklearn import datasets
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
-
- # 加载数据
- data = datasets.load_breast_cancer()
- X, y = data.data, data.target
-
- # 分割数据为训练集和测试集
- X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 特征标准化
- scaler = StandardScaler()
- X_train = scaler.fit_transform(X_train)
- X_test = scaler.transform(X_test)
-
- # 将标签数据格式化为正确的形状
- Y_train = Y_train.reshape((Y_train.shape[0], 1)).T
- Y_test = Y_test.reshape((Y_test.shape[0], 1)).T
-
- # 调用模型函数
- results = model(X_train.T, Y_train, X_test.T, Y_test, num_iterations=2000, learning_rate=0.005, print_cost=True)
-
- # 打印准确率
- print("Training accuracy: {:.2f}%".format(results['train_accuracy']))
- print("Test accuracy: {:.2f}%".format(results['test_accuracy']))
这段代码演示了如何加载乳腺癌数据集,对其进行预处理,并用逻辑回归模型进行训练和测试。确保在运行这些代码之前已经定义了 model() 函数及其相关的辅助函数,如 sigmoid()、initialize_with_zeros()、propagate() 和 optimize()。
运行输出
逻辑回归是一项可用于预测二分类结果(binary outcome)的统计技术,广泛应用于金融、医学、犯罪学和其他社会科学中。逻辑回归使用简单且非常有效,你可以在许多机器学习、应用统计的书中的前几章中找到个关于逻辑回归的介绍。逻辑回归在许多统计课程中都会用到。
我们不难找到使用R语言的高质量的逻辑回归实例,如UCLA的教程R Data Analysis Examples: Logit Regression就是一个很好的资源。Python是机器学习领域最流行的语言之一,并且已有许多Python的资源涵盖了支持向量积和文本分类等话题,但少有关于逻辑回归的资料。

示例代码中使用了一些算法包,请确保在运行这些代码前,你的电脑已经安装了如下包:
- numpy: Python的语言扩展,定义了数字的数组和矩阵
- pandas: 直接处理和操作数据的主要package
- statsmodels: 统计和计量经济学的package,包含了用于参数评估和统计测试的实用工具
- pylab: 用于生成统计图
可参考 Windows安装Python机器学习包 或 Ubuntu/CentOS安装Python机器学习包 来搭建所需要的环境。
逻辑回归的实例
在此使用与Logit Regression in R相同的数据集来研究Python中的逻辑回归,目的是要辨别不同的因素对研究生录取的影响。
数据集中的前三列可作为预测变量(predictor variables):
gpagre分数rank表示本科生母校的声望
第四列admit则是二分类目标变量(binary target variable),它表明考生最终是否被录用。
加载数据
使用 pandas.read_csv加载数据,这样我们就有了可用于探索数据的DataFrame。
- import pandas as pd
- import statsmodels.api as sm
- import pylab as pl
- import numpy as np
- # 加载数据
- df = pd.read_csv("http://www.ats.ucla.edu/stat/data/binary.csv")
- # 浏览数据集
- print df.head()
- # admit gre gpa rank
- # 0 0 380 3.61 3
- # 1 1 660 3.67 3
- # 2 1 800 4.00 1
- # 3 1 640 3.19 4
- # 4 0 520 2.93 4
- # 重命名'rank'列,因为dataframe中有个方法名也为'rank'
- df.columns = ["admit", "gre", "gpa", "prestige"]
- print df.columns
- # array([admit, gre, gpa, prestige], dtype=object)
language-python
注意到有一列属性名为rank,但因为rank也是pandas dataframe中一个方法的名字,因此需要将该列重命名为"prestige".
统计摘要(Summary Statistics) 以及 查看数据
现在我们就将需要的数据正确载入到Python中了,现在来看下数据。我们可以使用pandas的函数describe来给出数据的摘要--describe与R语言中的summay类似。这里也有一个用于计算标准差的函数std,但在describe中已包括了计算标准差。
我特别喜欢pandas的pivot_table/crosstab聚合功能。crosstab可方便的实现多维频率表(frequency tables)(有点像R语言中的table)。你可以用它来查看不同数据所占的比例。
- # summarize the data
- print df.describe()
- # admit gre gpa prestige
- # count 400.000000 400.000000 400.000000 400.00000
- # mean 0.317500 587.700000 3.389900 2.48500
- # std 0.466087 115.516536 0.380567 0.94446
- # min 0.000000 220.000000 2.260000 1.00000
- # 25% 0.000000 520.000000 3.130000 2.00000
- # 50% 0.000000 580.000000 3.395000 2.00000
- # 75% 1.000000 660.000000 3.670000 3.00000
- # max 1.000000 800.000000 4.000000 4.00000
- # 查看每一列的标准差
- print df.std()
- # admit 0.466087
- # gre 115.516536
- # gpa 0.380567
- # prestige 0.944460
- # 频率表,表示prestige与admin的值相应的数量关系
- print pd.crosstab(df['admit'], df['prestige'], rownames=['admit'])
- # prestige 1 2 3 4
- # admit
- # 0 28 97 93 55
- # 1 33 54 28 12
- # plot all of the columns
- df.hist()
- pl.show()
language-python
运行代码后,绘制的柱状统计图如下所示:

虚拟变量(dummy variables)
虚拟变量,也叫哑变量,可用来表示分类变量、非数量因素可能产生的影响。在计量经济学模型,需要经常考虑属性因素的影响。例如,职业、文化程度、季节等属性因素往往很难直接度量它们的大小。只能给出它们的“Yes—D=1”或”No—D=0”,或者它们的程度或等级。为了反映属性因素和提高模型的精度,必须将属性因素“量化”。通过构造0-1型的人工变量来量化属性因素。
pandas提供了一系列分类变量的控制。我们可以用get_dummies来将"prestige"一列虚拟化。
get_dummies为每个指定的列创建了新的带二分类预测变量的DataFrame,在本例中,prestige有四个级别:1,2,3以及4(1代表最有声望),prestige作为分类变量更加合适。当调用get_dummies时,会产生四列的dataframe,每一列表示四个级别中的一个。
- # 将prestige设为虚拟变量
- dummy_ranks = pd.get_dummies(df['prestige'], prefix='prestige')
- print dummy_ranks.head()
- # prestige_1 prestige_2 prestige_3 prestige_4
- # 0 0 0 1 0
- # 1 0 0 1 0
- # 2 1 0 0 0
- # 3 0 0 0 1
- # 4 0 0 0 1
- # 为逻辑回归创建所需的data frame
- # 除admit、gre、gpa外,加入了上面常见的虚拟变量(注意,引入的虚拟变量列数应为虚拟变量总列数减1,减去的1列作为基准)
- cols_to_keep = ['admit', 'gre', 'gpa']
- data = df[cols_to_keep].join(dummy_ranks.ix[:, 'prestige_2':])
- print data.head()
- # admit gre gpa prestige_2 prestige_3 prestige_4
- # 0 0 380 3.61 0 1 0
- # 1 1 660 3.67 0 1 0
- # 2 1 800 4.00 0 0 0
- # 3 1 640 3.19 0 0 1
- # 4 0 520 2.93 0 0 1
- # 需要自行添加逻辑回归所需的intercept变量
- data['intercept'] = 1.0
language-python
这样,数据原本的prestige属性就被prestige_x代替了,例如原本的数值为2,则prestige_2为1,prestige_1、prestige_3、prestige_4都为0。
将新的虚拟变量加入到了原始的数据集中后,就不再需要原来的prestige列了。在此要强调一点,生成m个虚拟变量后,只要引入m-1个虚拟变量到数据集中,未引入的一个是作为基准对比的。
最后,还需加上常数intercept,statemodels实现的逻辑回归需要显式指定。
执行逻辑回归
实际上完成逻辑回归是相当简单的,首先指定要预测变量的列,接着指定模型用于做预测的列,剩下的就由算法包去完成了。
本例中要预测的是admin列,使用到gre、gpa和虚拟变量prestige_2、prestige_3、prestige_4。prestige_1作为基准,所以排除掉,以防止多元共线性(multicollinearity)和引入分类变量的所有虚拟变量值所导致的陷阱(dummy variable trap)。
- # 指定作为训练变量的列,不含目标列`admit`
- train_cols = data.columns[1:]
- # Index([gre, gpa, prestige_2, prestige_3, prestige_4], dtype=object)
- logit = sm.Logit(data['admit'], data[train_cols])
- # 拟合模型
- result = logit.fit()
language-python
在这里是使用了statesmodels的Logit函数,更多的模型细节可以查阅statesmodels的文档
使用训练模型预测数据
(本小节是博主补充的)通过上述步骤,我们就得到了训练后的模型。基于这个模型,我们就可以用来预测数据,代码如下:
- # 构建预测集
- # 与训练集相似,一般也是通过 pd.read_csv() 读入
- # 在这边为方便,我们将训练集拷贝一份作为预测集(不包括 admin 列)
- import copy
- combos = copy.deepcopy(data)
- # 数据中的列要跟预测时用到的列一致
- predict_cols = combos.columns[1:]
- # 预测集也要添加intercept变量
- combos['intercept'] = 1.0
- # 进行预测,并将预测评分存入 predict 列中
- combos['predict'] = result.predict(combos[predict_cols])
- # 预测完成后,predict 的值是介于 [0, 1] 间的概率值
- # 我们可以根据需要,提取预测结果
- # 例如,假定 predict > 0.5,则表示会被录取
- # 在这边我们检验一下上述选取结果的精确度
- total = 0
- hit = 0
- for value in combos.values:
- # 预测分数 predict, 是数据中的最后一列
- predict = value[-1]
- # 实际录取结果
- admit = int(value[0])
- # 假定预测概率大于0.5则表示预测被录取
- if predict > 0.5:
- total += 1
- # 表示预测命中
- if admit == 1:
- hit += 1
- # 输出结果
- print 'Total: %d, Hit: %d, Precision: %.2f' % (total, hit, 100.0*hit/total)
- # Total: 49, Hit: 30, Precision: 61.22
language-python
在这里,我是简单的将原始数据再作为待预测的数据进行检验。通过上述步骤得到的是一个概率值,而不是一个直接的二分类结果(被录取/不被录取)。通常,我们可以设定一个阈值,若 predict 大于该阈值,则认为是被录取了,反之,则表示不被录取。
在上面的例子中,假定预测概率大于 0.5 则表示预测被录取,一共预测有 49 个被录取,其中有 30 个预测命中,精确度为 61.22%。
结果解释
statesmodels提供了结果的摘要,如果你使用过R语言,你会发现结果的输出与之相似。
- # 查看数据的要点
- print result.summary()
language-python
- Logit Regression Results
- ==============================================================================
- Dep. Variable: admit No. Observations: 400
- Model: Logit Df Residuals: 394
- Method: MLE Df Model: 5
- Date: Sun, 03 Mar 2013 Pseudo R-squ.: 0.08292
- Time: 12:34:59 Log-Likelihood: -229.26
- converged: True LL-Null: -249.99
- LLR p-value: 7.578e-08
- ==============================================================================
- coef std err z P>|z| [95.0% Conf. Int.]
- ------------------------------------------------------------------------------
- gre 0.0023 0.001 2.070 0.038 0.000 0.004
- gpa 0.8040 0.332 2.423 0.015 0.154 1.454
- prestige_2 -0.6754 0.316 -2.134 0.033 -1.296 -0.055
- prestige_3 -1.3402 0.345 -3.881 0.000 -2.017 -0.663
- prestige_4 -1.5515 0.418 -3.713 0.000 -2.370 -0.733
- intercept -3.9900 1.140 -3.500 0.000 -6.224 -1.756
- ==============================================================================
language-python
你可以看到模型的系数,系数拟合的效果,以及总的拟合质量,以及一些统计度量。[待补充: 模型结果主要参数的含义]
当然你也可以只观察结果的某部分,如置信区间(confidence interval)可以看出模型系数的健壮性。
- # 查看每个系数的置信区间
- print result.conf_int()
- # 0 1
- # gre 0.000120 0.004409
- # gpa 0.153684 1.454391
- # prestige_2 -1.295751 -0.055135
- # prestige_3 -2.016992 -0.663416
- # prestige_4 -2.370399 -0.732529
- # intercept -6.224242 -1.755716
language-python
在这个例子中,我们可以肯定被录取的可能性与应试者毕业学校的声望存在着逆相关的关系。
换句话说,高排名学校(prestige_1==True)的湘鄂生呗录取的概率比低排名学校(prestige_4==True)要高。
相对危险度(odds ratio)
odds ratio: OR值,是相对危险度,又称比值比、优势比。
使用每个变量系数的指数来生成odds ratio,可知变量每单位的增加、减少对录取几率的影响。例如,如果学校的声望为2,则我们可以期待被录取的几率减少大概50%。UCLA上有一个对odds ratio更为深入的解释: 在逻辑回归中如何解释odds ratios?。
- # 输出 odds ratio
- print np.exp(result.params)
- # gre 1.002267
- # gpa 2.234545
- # prestige_2 0.508931
- # prestige_3 0.261792
- # prestige_4 0.211938
- # intercept 0.018500
language-python
我们也可以使用置信区间来计算系数的影响,来更好地估计一个变量影响录取率的不确定性。
- # odds ratios and 95% CI
- params = result.params
- conf = result.conf_int()
- conf['OR'] = params
- conf.columns = ['2.5%', '97.5%', 'OR']
- print np.exp(conf)
- # 2.5% 97.5% OR
- # gre 1.000120 1.004418 1.002267
- # gpa 1.166122 4.281877 2.234545
- # prestige_2 0.273692 0.946358 0.508931
- # prestige_3 0.133055 0.515089 0.261792
- # prestige_4 0.093443 0.480692 0.211938
- # intercept 0.001981 0.172783 0.018500
language-python
更深入的挖掘
为了评估我们分类器的效果,我们将使用每个输入值的逻辑组合(logical combination)来重新创建数据集,如此可以得知在不同的变量下预测录取可能性的增加、减少。首先我们使用名为 cartesian 的辅助函数来生成组合值(来源于: 如何使用numpy构建两个数组的组合)
我们使用 np.linspace 创建 "gre" 和 "gpa" 值的一个范围,即从指定的最大、最小值来创建一个线性间隔的值的范围。在本例子中,取已知的最大、最小值。
- # 根据最大、最小值生成 GRE、GPA 均匀分布的10个值,而不是生成所有可能的值
- gres = np.linspace(data['gre'].min(), data['gre'].max(), 10)
- print gres
- # array([ 220. , 284.44444444, 348.88888889, 413.33333333,
- # 477.77777778, 542.22222222, 606.66666667, 671.11111111,
- # 735.55555556, 800. ])
- gpas = np.linspace(data['gpa'].min(), data['gpa'].max(), 10)
- print gpas
- # array([ 2.26 , 2.45333333, 2.64666667, 2.84 , 3.03333333,
- # 3.22666667, 3.42 , 3.61333333, 3.80666667, 4. ])
- # 枚举所有的可能性
- combos = pd.DataFrame(cartesian([gres, gpas, [1, 2, 3, 4], [1.]]))
- # 重新创建哑变量
- combos.columns = ['gre', 'gpa', 'prestige', 'intercept']
- dummy_ranks = pd.get_dummies(combos['prestige'], prefix='prestige')
- dummy_ranks.columns = ['prestige_1', 'prestige_2', 'prestige_3', 'prestige_4']
- # 只保留用于预测的列
- cols_to_keep = ['gre', 'gpa', 'prestige', 'intercept']
- combos = combos[cols_to_keep].join(dummy_ranks.ix[:, 'prestige_2':])
- # 使用枚举的数据集来做预测
- combos['admit_pred'] = result.predict(combos[train_cols])
- print combos.head()
- # gre gpa prestige intercept prestige_2 prestige_3 prestige_4 admit_pred
- # 0 220 2.260000 1 1 0 0 0 0.157801
- # 1 220 2.260000 2 1 1 0 0 0.087056
- # 2 220 2.260000 3 1 0 1 0 0.046758
- # 3 220 2.260000 4 1 0 0 1 0.038194
- # 4 220 2.453333 1 1 0 0 0 0.179574
language-python
现在我们已生成了预测结果,接着通过画图来呈现结果。我编写了一个名为 isolate_and_plot 的辅助函数,可以比较给定的变量与不同的声望等级、组合的平均可能性。为了分离声望和其他变量,我使用了 pivot_table 来简单地聚合数据。
- def isolate_and_plot(variable):
- # isolate gre and class rank
- grouped = pd.pivot_table(combos, values=['admit_pred'], index=[variable, 'prestige'],
- aggfunc=np.mean)
- # in case you're curious as to what this looks like
- # print grouped.head()
- # admit_pred
- # gre prestige
- # 220.000000 1 0.282462
- # 2 0.169987
- # 3 0.096544
- # 4 0.079859
- # 284.444444 1 0.311718
- # make a plot
- colors = 'rbgyrbgy'
- for col in combos.prestige.unique():
- plt_data = grouped.ix[grouped.index.get_level_values(1)==col]
- pl.plot(plt_data.index.get_level_values(0), plt_data['admit_pred'],
- color=colors[int(col)])
- pl.xlabel(variable)
- pl.ylabel("P(admit=1)")
- pl.legend(['1', '2', '3', '4'], loc='upper left', title='Prestige')
- pl.title("Prob(admit=1) isolating " + variable + " and presitge")
- pl.show()
- isolate_and_plot('gre')
- isolate_and_plot('gpa')
language-python
结果图显示了 gre, gpa 和 prestige 如何影响录取。可以看出,随着 gre 和 gpa 的增加,录取可能性如何逐渐增加,并且,不同的学校声望对录取可能性的增加程度相差很大。
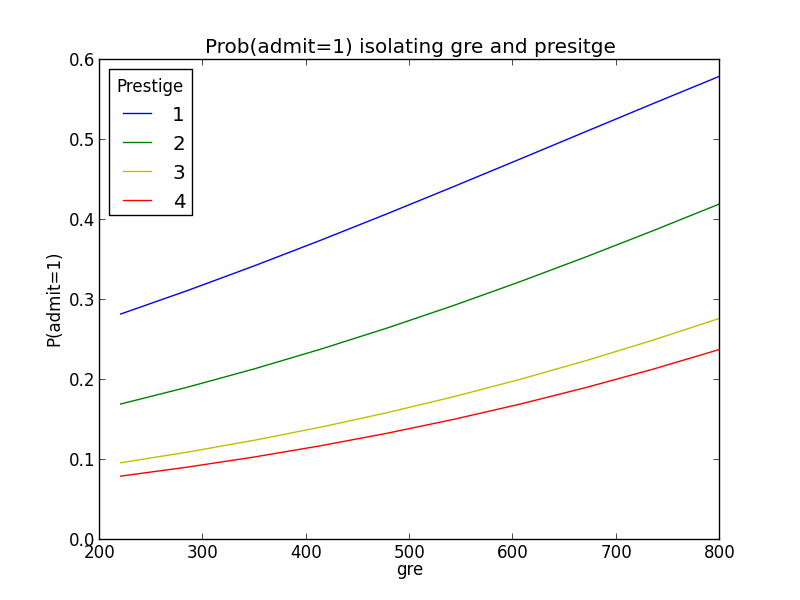

结束语
逻辑回归是用于分类的优秀算法,尽管有一些更加性感的,或是黑盒分类器算法,如SVM和随机森林(RandomForest)在一些情况下性能更好,但深入了解你正在使用的模型是很有价值的。很多时候你可以使用随机森林来筛选模型的特征,并基于筛选出的最佳的特征,使用逻辑回归来重建模型。

