
- 1数据结构——二叉树_采用二叉链表存储结构,visit是对数据元素操作的应用函数。 中序遍历二叉树t的递归
- 22023人工智能大模型产业创新价值研究报告.pdf(附下载链接)
- 3autojs脚本引擎实现的安卓手机发短信源码_autojs多卡手机后台静默发送短信
- 4python生成的html动态页面能添加视频或者图片显示,只给出实现代码
- 5JAVA中链表的实现_hascycle
- 6Kafka生产者源码解析(二)——RecordAccumulator_kafka recordaccumulator
- 7链表的奇偶重排_java 链表的奇偶重排
- 8分布式服务框架Zookeeper解析_zk observer
- 9【Python sklearn】kaggle Titanic生死预测--0.81准确率--python超详细数据分析--附源代码和报告的下载地址_泰坦尼克号生存率预测python
- 10ubuntu设置本机无密码登录_ubuntu免密码登录
大模型入门基础-基本概念介绍
赞
踩
1.背景介绍
1.1 奇点到来:ChatGPT引爆AIGC
2022年末,ChatGPT一经推出即火爆全球,作为一款自然语言处理(Natural Language Processing,NLP)大模型,ChatGPT在意图理解和内容生成上,表现出了令人惊叹的性能。
2023年初,ChatGPT的升级版GPT-4引入了对图片、语音的支持等多模态能力,多项考试分数已经超越了大部分人类。
2024年初,OpenAI发布文生视频大模型Sora,在全球视频大模型领域取得里程碑式进展。
如果说2016年AlphaGo在围棋上战胜人类棋王,是AI在专业领域战胜人类的起点,那么以ChatGPT为代表的大模型的发布,则标志着泛化能力更强,通用任务处理更出色的生成式人工智能(AIGC: Artificial Intelligence Generated Content)的奇点来临。

1.2 全球热潮:全球AI市场预计将于2030年达到1万亿美元

2024 年全球人工智能 50 强
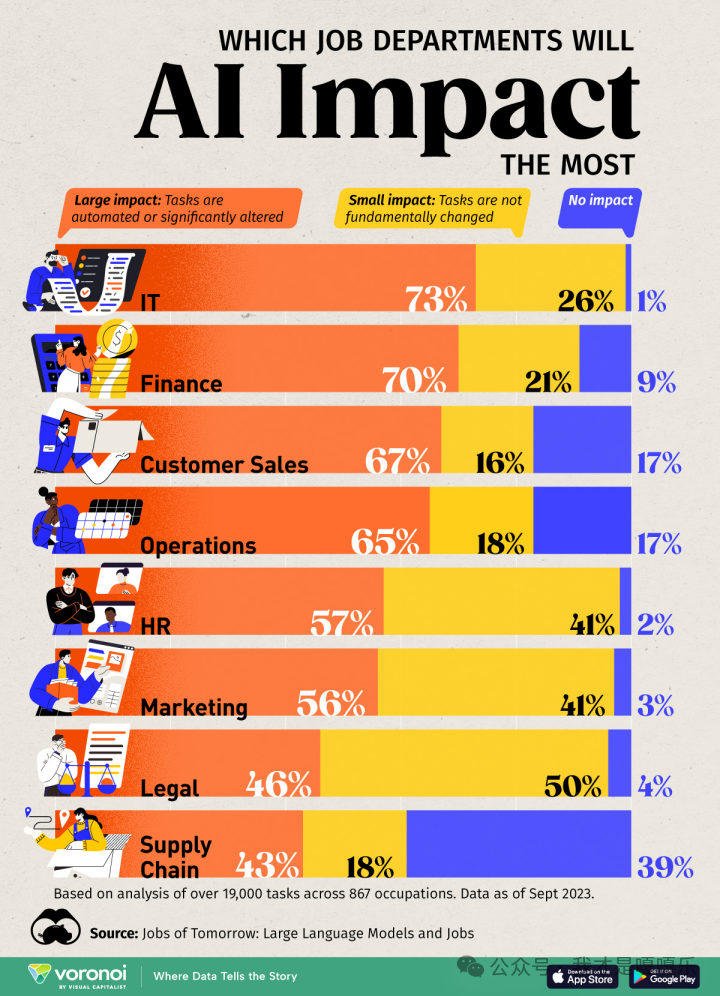
AI对各类工作的影响
1.3 AGI看到希望
1.4 高估的短期与低估的长期
2023年大众对AI的看法 : 这是啥->好像也没那么厉害->和我没太大关系
-
短期:AGI并没有马上催生出大量"明星APP“和“变现机器”。只有ChatGPT,Charactor.ai等少数App实现了用户突破。大量上层应用APP就像韭菜一样:不仅昙花一现,迅速被OpenAI官方所取代,而且还无法做到成本打平。于是,投资人极端谨慎,公众也渐渐对于AI麻木。
-
长期:技术的稳定的、加速度的选代。23年3月预测的众多技术到现在都有了长足进步:视频生成、音频生成、代理Agent、记忆能力、模型小型化…………它们距离商用可能还有各种各样的问题,但捅破这层窗户纸只是时间问题。
人间一日,AI十年,技术加速迭代已是常态,大模型技术浪潮是我们切身经历的这个时代最显著的技术变革,目前还没有看到阻止AGI出现的硬性限制,且我们距离AGI只有几年距离,各位实施线同事要饱含热情投入进来。
1.5 为什么大语言模型开启了迈向通用人工智能之路?
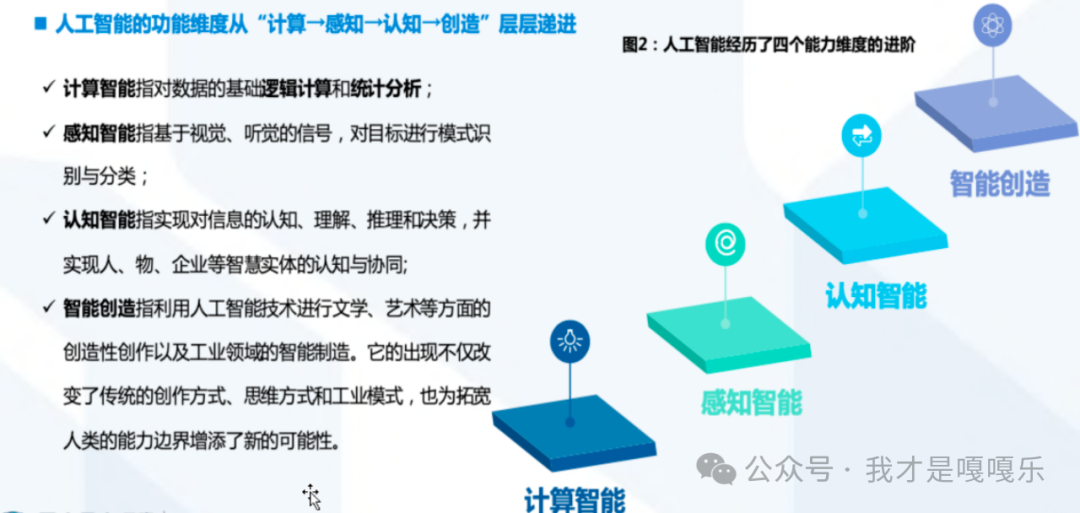
认知智能是智能的终极体现,人机同频的交流是智能被实现的象征,无论一个人工智能算法有多强大的能力。只要它不能普适性地理解人类、不能让人类理解、不能与人类顺畅交流,它终归是无法融入人类和商业社会的(残酷的是,一个真人也是一样)。人工智能的终极评判标准,就是人机同频交流。
在“人机同频交流”的大目标下,自然语言处理这一领域的关键性不言而喻。人类90%的信息获取与交流都依赖于语言,人类所有的逻辑、情感、知识、智慧、甚至社会的构建、文明的传承依赖于对语言的理解和表达。因此,计算机想要具备“看人类所看,想人类所想,与人类同频”的能力,就必须理解人类所使用的自然语言,而自然语言处理(Natural Langurage Process)正是研究如何让计算机认知人类语言、理解人类语言、生成人类语言、甚至依赖这些语言与人进行交流、完成特定语言任务的关键学科。豪不夸张的说,人工智能能否真正“智能”,很大程度上都依赖于自然语言处理领域的发展。也正因如此,ChatGPT在人类语言领域的成功,很大程度上给出了通向通用人工智能的希望。
1.6 只是预测下一个“词”而已?
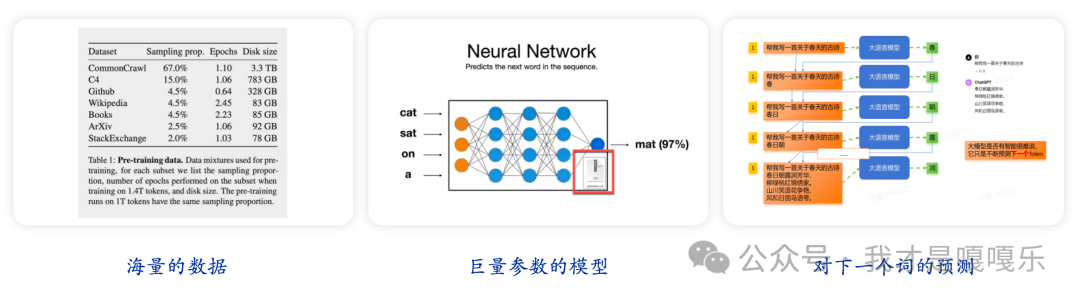
1.7 引爆新一轮技术革命的真实原因:涌现能力
1)大语言模型的训练目标是什么?
通常来说,大语言模型的原始训练目标都是为了生成自然、连贯的文本,这也就是为什么GPT-3模型最早是被用来编写新闻稿件、写小说、编写产品介绍文案、诗歌等;
由于模型本身接受了大量的文本进行预训练,因此根据提示补全和创造文本可以看成是模型的原生技能;
2)引爆新一轮技术革命的真实原因:大语言模型的涌现能力
不过,仅仅能进行文本创造,并不足以让大语言模型掀起新的一轮技术革命。人们真正看好大语言模型技术的根本在于当模型足够大(参数足够大&训练数据足够多)时模型展示出了“涌现能力”;
所谓涌现能力(Emergent Capabilities),指的是模型在没有针对特定任务进行训练的情况下,仍然能够在合理提示下处理这些任务的能力;有时也可以将涌现能力理解为模型潜力;巨大的技术潜力,才是LLM爆火的根本原因;
3)大语言模型的涌现能力具体有哪些?
·对话能力:很难想象的是,对话能力其实也是大语言模型的涌现能力;对于大语言模型(例如Completion模型)来说,本身并未接受对话语料训练,因此对话能力并不属于模型的原生能力;
·翻译能力、摘要提取能力、编程能力、推理能力、语意理解能力等,也都属于大语言模型的涌现能力;
4)大语言模型到底能做什么?
·原生能力范畴一一文本创造:写稿件、邮件、小说、新闻、诗歌…
·涌现能力范畴一一对话、编程、翻译、推理(包括逻辑推理、自然科学类推理、NLP自然语言推理等),以及其他各类NLP任务,如文本分类、情感识别、推荐排序等…
2.重点概念解析

2.1 模型
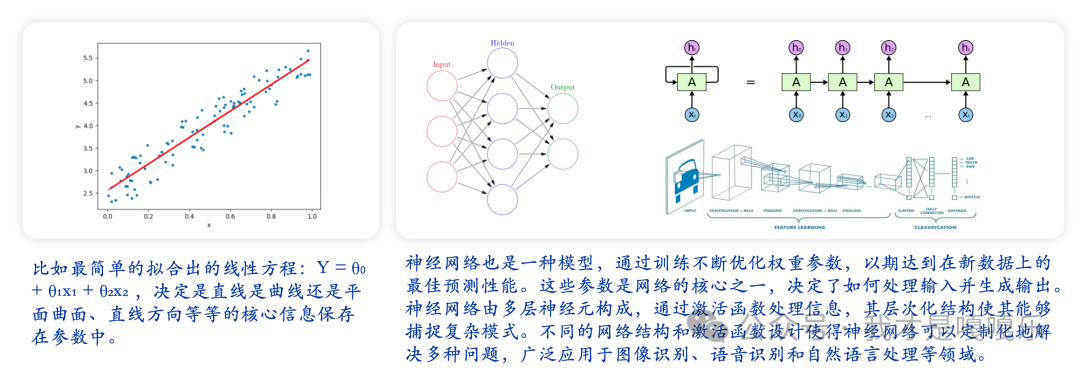
在人工智能(AI)领域,一个“模型”通常是指一个用于对现实世界数据进行理解、预测和解决问题的算法框架,模型可以是一个数学公式,也可以是一个复杂的神经网络。AI模型基于数据学习,其目的是从提供的训练数据中检测出模式和关系,然后在新数据上应用这些学习到的规则来做出决策或推断。AI模型的类型包括决策树、支持向量机、神经网络等,具体取决于所要解决的问题和所使用的技术或方法。
2.2 大语言模型
1)什么是语言模型

语言模型是一种函数,或者是一种用于学习这种函数的算法,它可以捕捉自然语言中单词序列分布的显著统计特征,通常允许人们根据前面的单词对下一个单词做出概率预测。
2)什么是大语言模型?
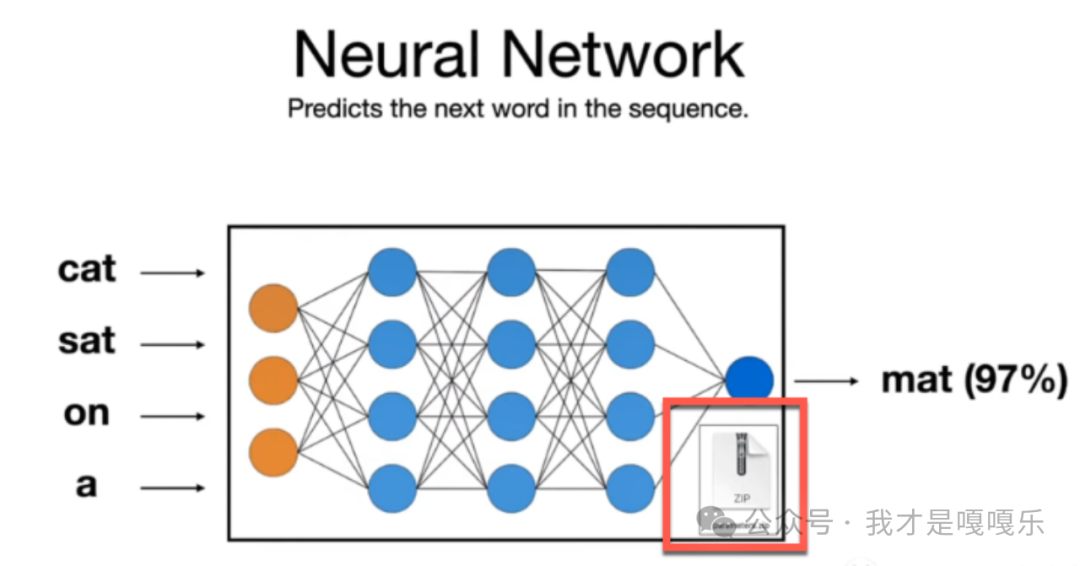
大语言模型(LLM),也是一种神经网络模型,通常是具有大规模参数和计算能力,GPT由128层网络和1750亿参数组成,并使用45TB数据进行训练。
2.3 自然语言处理
大语言模型不是一蹴而就的,是经过了漫长的发展历史,大语言模型是自然语言处理领域的重要成果。自然语言处理是人工智能 (AI)的一个分支,专注于计算机与自然语言之间的交互。
自然语言处理(NLP)的发展历程可分为早期、中期以及现代(后期)三个阶段:
早期(1950s-1980s):早期的NLP主要由基于规则的系统构成。这些系统依据语言学家编写的复杂规则来处理语言。
机器翻译:NLP的早期研究主要关注机器翻译,如1950s的Georgetown-IBM实验,它使用了一组简单的俄语到英语翻译规则。
句法分析:70年代见证了句法分析器的开发,它们依靠编码的语法规则来解析文本。
专家系统:1980年代,出现了基于专家知识的系统,如SHRDLU等,处理特定领域的自然语言理解问题。
中期(1980s-2000s):在这个阶段,与基于规则的系统相比,统计方法开始变得流行。
统计模型:1990年代起,统计模型在NLP中变得主流,尤其是隐马尔可夫模型(HMMs)和概率上下文无关文法(PCFGs)被用于语音识别和句法分析。
数据驱动学习:大规模语料库的建立使得基于数据的机器学习方法发展迅速。
机器翻译的进步:90年代后期,基于数据的机器翻译方法变得势不可挡,尤其是基于短语的统计翻译模型。
现代(2000s-至今):现代NLP几乎完全依赖于机器学习模型,尤其是深度学习方法,它们在性能上取得了质的飞跃。
Word2Vec和深度学习:2010年代初,Word2Vec词嵌入方法的发明以及卷积神经网络(CNNs)和循环神经网络(RNNs)在NLP的应用推动了深度学习的爆发。
注意力机制和Transformer模型:2017年,注意力机制和Transformer模型的出现彻底改变了NLP领域,这导致了BERT、GPT等预训练语言模型的开发。
预训练语言模型:预训练语言模型利用大量未标注文本数据学习语言表示,通过微调可适用于多种NLP任务,显著提升了下游应用的表现。
2.4 什么是token
人类的语言是由文字构成,语言的含义也是由单词构成的,即单词是含义的最小单位。因此,为了让计算机理解自然语言,寻找数字表示的方法是第一步。

2.5 什么是词嵌入(word embedding)
⾃然语⾔是⽤来表达⼈脑思维的复杂系统。在这个系统中,词是意义的基本单元。顾名思义,词向量是⽤于表⽰单词意义的向量,并且还可以被认为是单词的特征向量或表⽰。将单词映射到实向量的技术称为词嵌⼊。

2.6 什么是预训练?
在大型语言模型(LLM)的场景中,预训练是使用大规模文本语料库来学习语法结构、单词上下文和语言模式的一种方法,预训练过程:
1.选择一个大规模的文本数据集:数据集的选择依赖于模型的预训练目标,通常使用网站、书籍或其他文本资源收集的未标记文本数据。
2.定义预训练任务:任务可能包括语言模型预测、掩码语言模型、句子关系预测等。具体的任务取决于预训练模型的设计。
3.训练模型:使用选择的数据集和任务来训练模型,这个过程可能持续数日至数月不等,需要大量计算资源。
4.提取知识:预训练完成后,模型内部的权重编码了对语言的广泛理解,这些知识可以迁移到下游任务中。
2.7 什么是微调?
感性理解:大模型微调指的是“喂”给模型更多信息,对模型的特定功能进行“调教”,即通过输入特定领域的数据集,让其学习这个领域的知识,从而让大模型能够更好的完成特定领域的NLP任务,例如情感分析、命名实体识别、文本分类、对话聊天等;
从模型本身角度而言:微调阶段相当于是进一步进行训练,该过程会修改模型参数,并最终使模型“记住”了这些额外信息;让大模型永久记住信息的唯一方法就是修改参数;
有监督微调:supervised fine-tuning,简称SFT;
数据标注:高质量的有标签数据集在微调过程中必不可少,数据标注工作则是用于创建这些有标签的数据集;伴随着大模型发展,人们也在尝试使用大模型来完成很多数据标注工作;
2.8 什么是提示工程?
在人工智能和自然语言处理领域,特别是在使用大型语言模型(如GPT系列)时,prompt是指输入给模型的文本,用于引导模型生成特定的输出。Prompt可以是一个简单的问题、一段描述或是一段指令,它告诉模型应该做什么以及如何生成所需的输出。也就说,Prompt 是与大模型对话的语言,是大模型应用的核心。


2.9 什么是增强检索(RAG)?
检索增强生成(Retrieval-Augmented Generation,简称RAG)是一种人工智能技术,该技术通过检索信息库中的相关事实,以提高大型语言模型(LLMs)的准确性和可靠性。RAG结构是由Facebook AI于2020年提出的,旨在改善机器理解和生成自然语言的能力。RAG是一种结构或设计方法,结合了信息检索技术和文本生成模型,在 LLM 本就强大的功能基础上,RAG 将其扩展为能访问特定领域或组织的内部知识库,所有这些都无需重新训练模型。这是一种经济高效地改进 LLM 输出的方法。
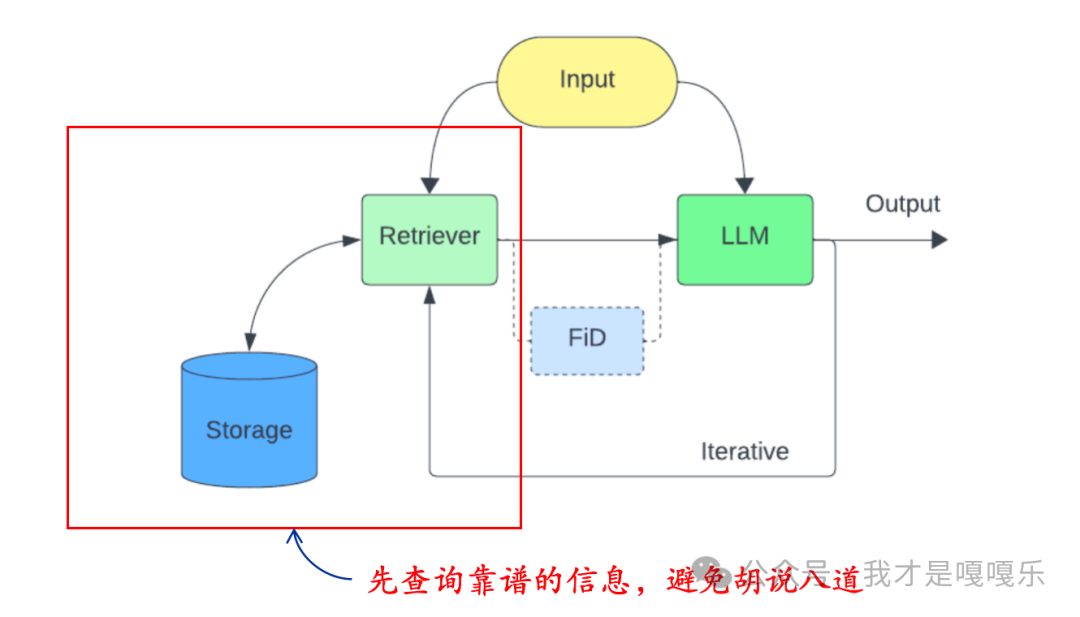
2.10 什么是知识库?
基于RAG(Retrieval-Augmented Generation)的知识库是一种结合了信息检索(Retrieval)和生成模型(Generation)能力的人工智能系统。这种系统旨在通过检索相关信息丰富其回答,同时利用生成模型按照检索到的信息自动生成文本回答或解决方案。

2.11 什么是智能体(Agents)?
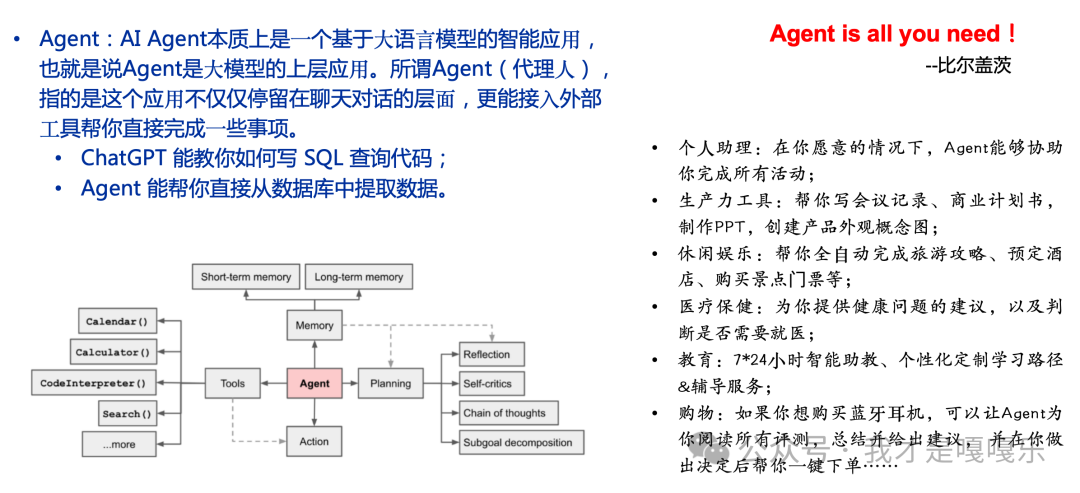
Agent:AI Agent本质上是⼀个基于⼤语⾔模型的智能应⽤,也就是说Agent是⼤模型的上层应⽤。所谓Agent(代理⼈),指的是这个应⽤不仅仅停留在聊天对话的层⾯,更能接⼊外部⼯具帮你直接完成⼀些事项。
ChatGPT 能教你如何写 SQL 查询代码;
Agent 能帮你直接从数据库中提取数据。
2.12 什么是GPTs?
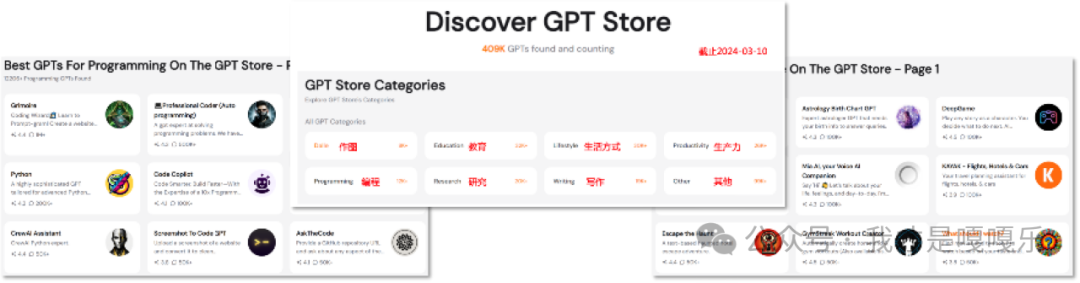
GPTs 是OpenAI 开发的一个工具,无需任何编程知识,通过简单聊天的交互方式就能创建数学、论文、创意设计等不同任务的专属GPT。是一种让使用者将指令、额外知识和任何技能组合搭配起来 AI 助理的工具。从某种程度来说,也是智能体(Agent)的代名词。可以上架至GPT Store。
GPT Store 是由OpenAI推出的一个平台,在这个平台上,开发者和社区可以创建、分享以及发现各种基于GPT的应用。在GPTs商店中提供搜索及分类排行榜,能为制作者提供收益,鼓励用户制作与分享工具。截止到2024-3-10,GPTs的创建数量已经超过400万。
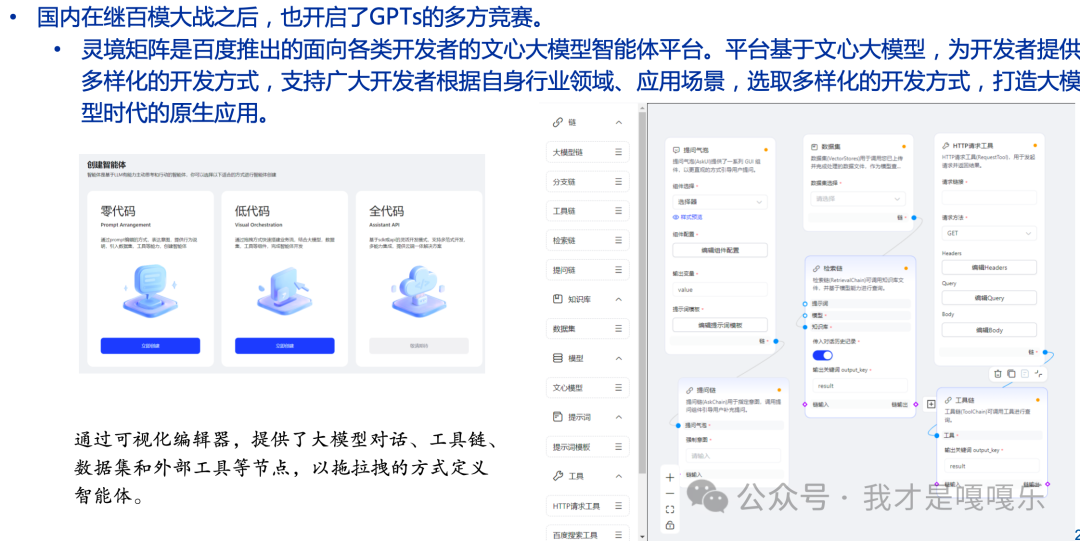
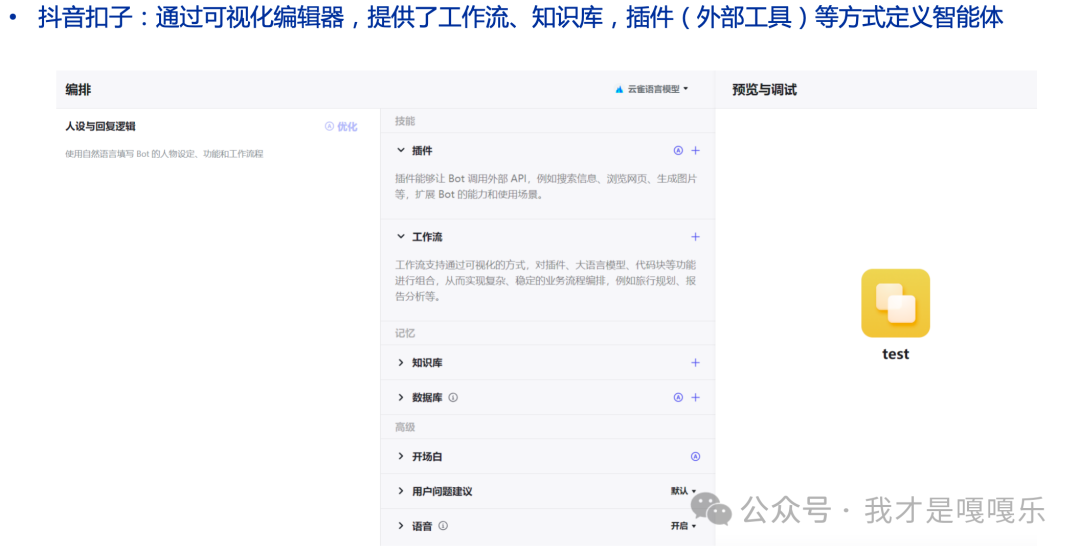
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

