
- 1损失次数模型-泊松分布_已知损失观察值求泊松分布参数
- 2YOLOV5学习笔记(二)——环境安装+运行+训练_yolov5环境安装
- 3关于转置卷积(反卷积)的理解_转置卷积放大倍数
- 4服务器上的安全数据库没有此工作站信任关系的计算机帐户如何解决?_服务器上的安全数据库没有此工作站的账号
- 5【StableDiffusion秋叶包反斜杠问题】Failed to find xxx\sd-webui-aki-v4.8\...\xxx.pth_sd秋叶4.8
- 6SpringBoot集成ElasticSearch,实现模糊查询,批量CRUD,排序,分页,高亮_elasticsearch springboot查询
- 7利用SuperGlue算法实现跨尺度金字塔特征点的高效匹配(含py代码)_superglue特征匹配
- 8c语言输出一个变量 值为字符串,【我有c语言提问1.putchar函数可以向终端输出一个【】.(A)数组(B)实型变量值(C)字符串(D)字符或字符型变量值2.假设有如下定义inta=-2;和输出语句...
- 9微信小程序WeUI Toptips使用和封装改进(可解决navigationStyle值为custom时位置靠上的问题)_微信小程序 weui mp-toptips 宽度为0
- 10探索大模型技术及其前沿应用——TextIn 文档解析技术_大模型是如何检查文本格式错误的
关系抽取简介
赞
踩
每天给你送来NLP技术干货!
来自:NLP就该这么学
作者:LindgeW
基本概念
为了构建知识图谱,从结构化(如表格)、半结构化(如JSON)和非结构化(如纯文本)数据中获取形式为(事物1,关系,事物2)的三元组的过程称为关系抽取(relation extraction)。一般情况下,我们会尽量把关系抽取抽象成若干三元组的抽取,而不会做n元组(n>3)的抽取。在NLP中,实体关系抽取则是致力于从自然语言文本中识别出实体对并判断实体间特定语义关系的任务,输入的是一句文本,输出的是spo三元组(subject-predicate/relation-object)。
例:刘翔,1983年7月13日出生于上海,中国男子田径队110米栏运行员。可以抽取出的实体关系三元组有:(刘翔-出生地-上海)、(刘翔-职业-田径运动员)。
关系类型
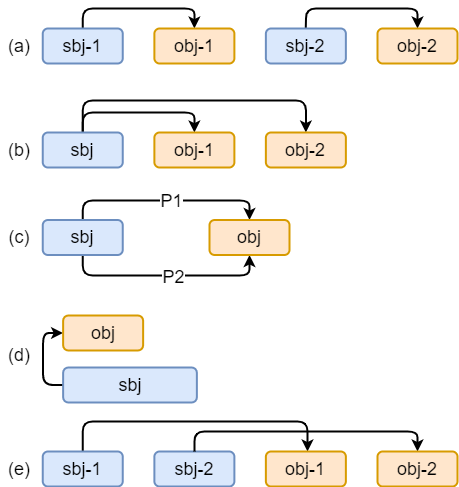
a:正常关系
b:关系重叠:一对多
“张学友演唱过《吻别》《在你身边》”中存在2种关系:(张学友-歌手-吻别)、(张学友-歌手-在你身边)
c:关系重叠:一对实体间存在多种关系
“周杰伦作曲并演唱《七里香》”中存在2种关系:(周杰伦-歌手-七里香)、(周杰伦-作曲-七里香)
d:由实体重叠导致的复杂关系
“《叶圣陶散文选集》”中存在关系:(叶圣陶-作品-叶圣陶散文选集)
e:由关系交叉导致的复杂关系
“张学友、周杰伦分别演唱过《吻别》《七里香》”中存在关系:(张学友-歌手-吻别)、(周杰伦-歌手-七里香)
实体关系抽取
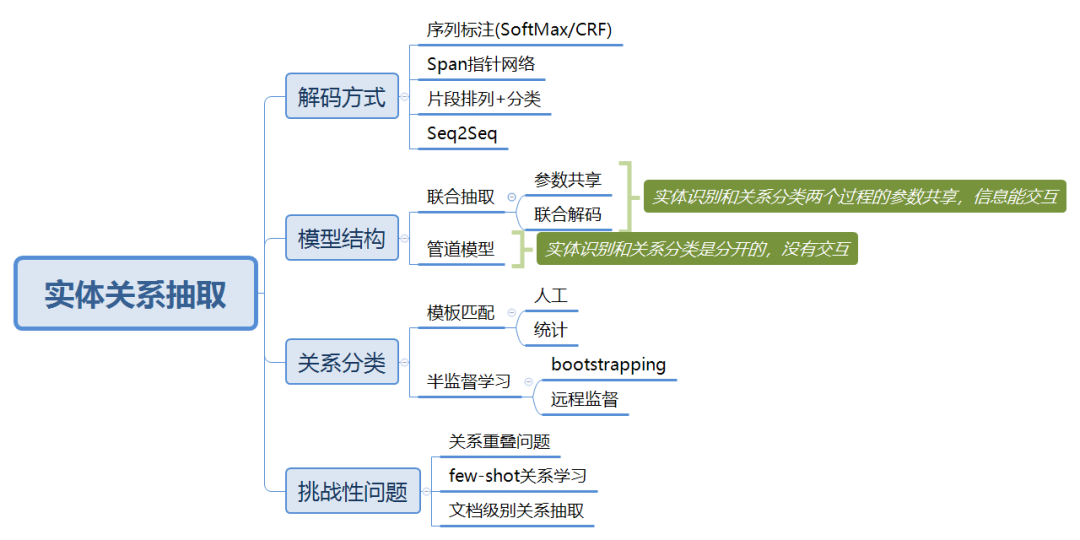
不同的解码方式
序列标注:简单高效,但无法解决实体重叠问题
Span指针网络:能解决实体重叠问题且有较高的准确率,但容易遇到标签不平衡问题
片段分类:可以直接得到实体,不需要从标签到实体的转换过程,但文本过长时会大大增加计算量
联合关系抽取
参数共享的联合模型抽取spo三元组的过程是分成多步完成的(不同步),整个模型的loss是各个过程的loss之和,在求梯度和反向更新参数时会同时更新整个模型各过程的参数,后面过程的训练可以使用前面过程的结果作为特征 (注:管道模型各子过程之间没有联系)。目前多数SOTA方法都使用这种方式。
联合解码的联合模型则更符合“联合”的思想,没有明确的将抽取过程分为实体识别和关系分类两个子过程,spo三元组是在同一个步骤中进行识别得到的,真正实现了子任务间的信息共享(缺陷:不能识别重叠的实体关系)。

经典模型
使用参数共享的经典模型
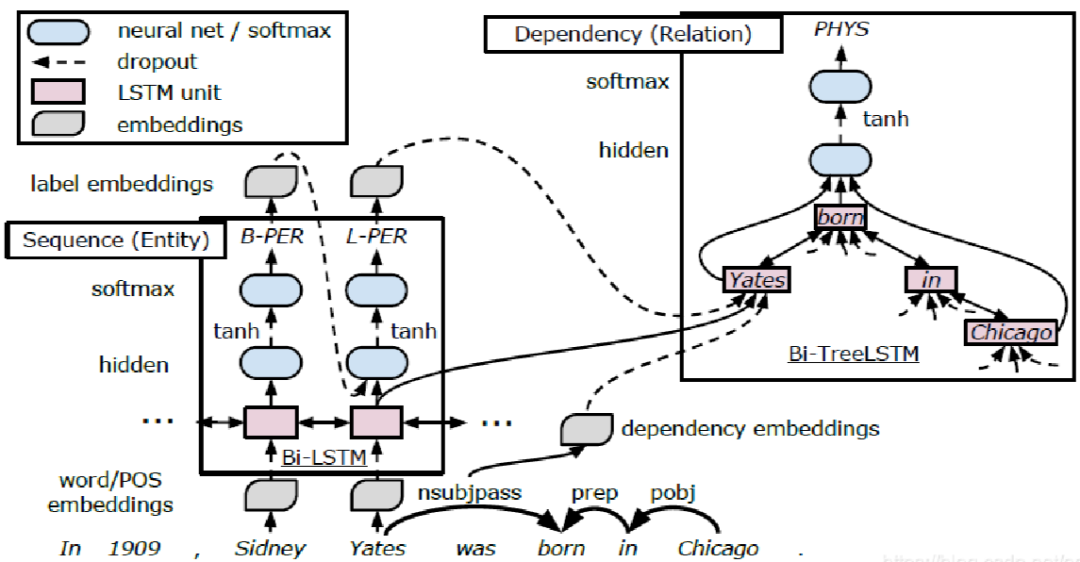
论文:《End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures》
简介:模型中有两个BiLSTM,一个基于word sequence,主要用于实体检测;另一个基于tree structures,主要用于关系抽取;后者堆叠在前者上,前者的输出和隐层作为后者输入的一部分。
使用联合解码的经典模型
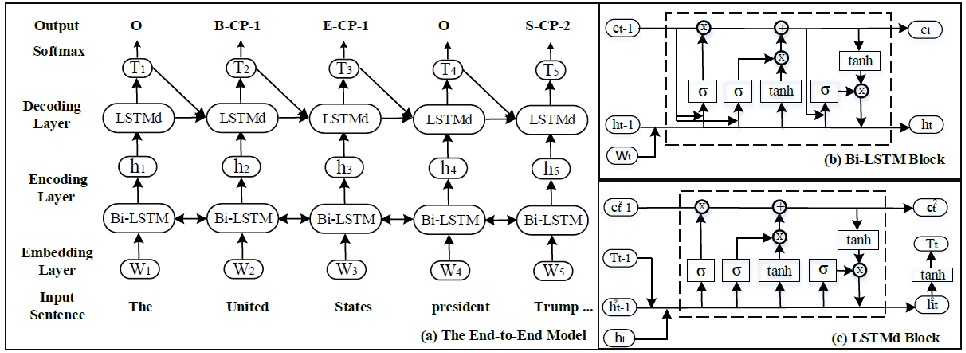
论文:《Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme》
简介:将实体识别和关系分类转化为序列标注问题,采用一种端到端模型, 通过编码器对句子进行编码,将隐层向量输入解码器后直接得到spo三元组,没有将抽取过程分为实体识别和关系分类两个子过程。
共包含 3 种标注信息:
实体中词的位置{ B,I,E,S,O },表示为{实体开始,实体内部,实体结束,单个实体,无关词};
实体关系类型,需根据关系类型进行标记,分为多个类别,如 {CF,CP,… } ;
实体角色信息{1,2},分别表示{实体1,实体2}。

预训练模型+关系分类
输入层BERT:分别用特殊符号$和#号标识两个实体的边界和位置;
利用了BERT特征抽取后2个部分的特征:BERT [CLS]位置的embedding和两个实体相对应的embedding;
将上述3类特征拼接起来,再接一个FC和softmax层输出关系的分类。
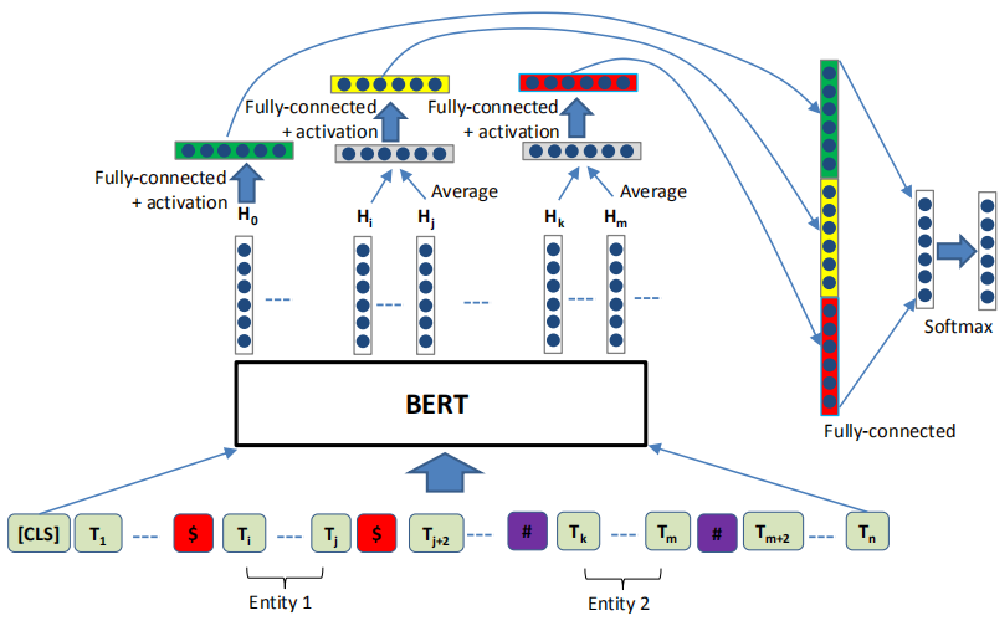
预训练模型+联合抽取
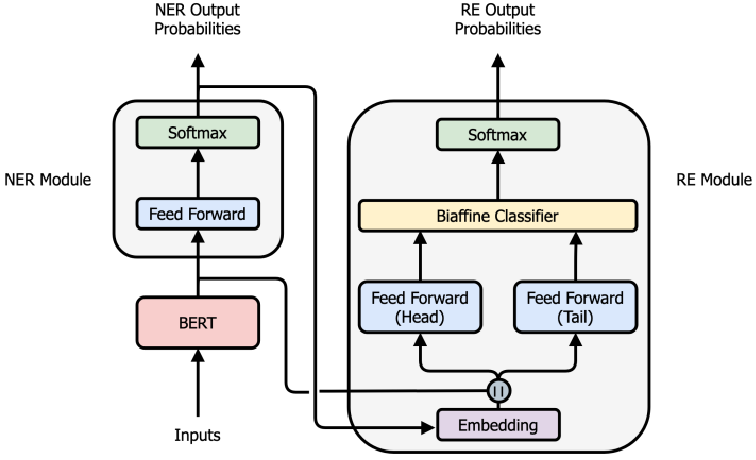
使用一个模型得到输入文本中的实体以及实体之间的关系,包括实体抽取模块、关系分类模块和共享的特征抽取模块。
关系分类模块:
BERT对输入序列编码得到特征序列;
NER模块的输出,经过argmax函数得到一个与输入序列长度相同,转化为固定维度的序列;
拼接得到的向量分别通过一个FFN层,通过一个Biaffine分类器,预测出实体之间的关系。
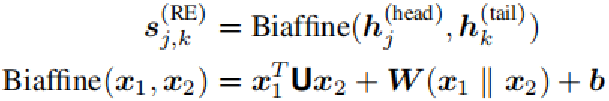
参考文献:
[1] Miwa M, Bansal M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures[C]//Proceedings of ACL. 2016: 1105-1116.
[2] Zheng S, Wang F, Bao H, et al. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme[C]//Proceedings of ACL. 2017: 1227-1236.
[3] Yu B, Zhang Z, Shu X, et al. Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy[M]//ECAI 2020. IOS Press, 2020: 2282-2289.
[4] Wei Z, Su J, Wang Y, et al. A novel hierarchical binary tagging framework for joint extraction of entities and relations[J]. arXiv preprint arXiv:1909.03227, 2019.
[5] Eberts M, Ulges A. Span-Based Joint Entity and Relation Extraction with Transformer Pre-Training[M]//ECAI 2020. IOS Press, 2020: 2006-2013.
[6] Luan Y, Wadden D, He L, et al. A General Framework for Information Extraction using Dynamic Span Graphs[C]//Proceedings of NAACL-HLT. 2019: 3036-3046.
[7] Bekoulis G, Deleu J, Demeester T, et al. Joint entity recognition and relation extraction as a multi-head selection problem[J]. Expert Systems with Applications, 2018, 114: 34-45.
[8] Dai D, Xiao X, Lyu Y, et al. Joint extraction of entities and overlapping relations using position-attentive sequence labeling[C]//Proceedings of the AAAI conference on artificial intelligence. 2019, 33(01): 6300-6308.
[9] Li X, Yin F, Sun Z, et al. Entity-Relation Extraction as Multi-Turn Question Answering[C]//Proceedings of ACL. 2019: 1340-1350.
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!
