
- 1[语音识别] 基于Python构建简易的音频录制与语音识别应用_python 麦克风录音
- 2Android中使用BroadcastReceiver打开和关闭WIFI_android root 禁用或者启动wifi
- 3IntelliJ IDEA 使用---导入版本控制SVN项目_idea svn import project
- 4邬贺铨院士:大模型赋能企业数字化转型
- 5简单的投屏、数据大屏前端代码_js 电脑投屏到显示屏代码
- 6jumpserver堡垒机
- 7人工神经网络的应用领域,人工神经网络技术及应用_使用人工智能系统来组织运营、融资投资和管理资产,机器人在模拟金融交易竞赛中击
- 8Bean的生命周期_mybits bean生命周期
- 9基于Python字典(列表)Lambda函数的排序问题
- 10python入门选择题_python单选题
【论文翻译】Issues and Challenges of Aspect-based Sentiment Analysis: A Comprehensive Survey_issues and challenges of aspects
赞
踩
Issues and Challenges of Aspect-based Sentiment Analysis: A Comprehensive Survey
细粒度情感分析的问题和挑战:综述。
ps:写综述就写综述,能不能别用这么多复杂从句,真的,没意义……
翻译的很不好…aspect通常会翻译成属性 也不知道够不够准确
超级长 一万多字
文章目录
摘要
随着社交媒体上公共反馈越来越多,细粒度情感分析领域越来越受到关注,包括aspect提取,aspects情感分析以及随着时间地情感变化。这个领域快速发展,迫使研究者不断采用新的技术和方法来应对难题和复杂场景。这篇综述着重于与提取不同aspects及其相关情感有关的问题和挑战,还有方面之间的关系映射,不同数据对象之间的交互,依存关系和上下文语义关系,以提高情感准确性,并预测情感演变动态。基于对aspect extraction、aspects sentiment analysis以及sentiment evolution几个领域的问题的处理的情况(是否有助于减轻困难提高效果),给出对最新进展的概述,以及结果对比。还通过辩证的分析当前解决方案讨论了未来的研究方向。
1 Introduction
sentiment analysis也叫opinion mining,一般极性是positive,negative和neutral。各个领域都可以应用情感分析。
研究上,SA一般分为三个层次,document-level,sentence-level以及aspect level,分别表示是一整个文档还是一个句子还是一个属性表达了情感。细粒度情感分析有助于更好的理解SA问题,因为直接关注情感而非句子结构。
aspect是和实体关联的,不仅仅是判断,还可以扩展为想法、观点、思考方式、视野、社交影响等等,因此ABSA可以随着事件分析跨越不同内容的情感。
ABSA可以分为三个主要过程:AE aspect extraction, ASA aspect sentiment analysis和 SE sentiment evolution。第一阶段处理aspect的抽取,可以是显式的aspect也可以是隐式的,还可以是aspect terms, entities 以及opinion target expressions(OTE).。第二个阶段是为预先定义好的aspect,target或实体进行情感分类。这一阶段还会formulate 不同数据对象(aspect,实体,target,multiword target,sentiment word)之间的interations,dependencies以及contextual-semantic relationships,以更好的提高情感分类准确性。可以进行三级分类,或者更细粒度的情感值。第三阶段关注人们对aspects(events)的情感随着时间的变化。社会特征和自我经验被认为是SE的主要原因。
1.1 综述的关注点
ABSA研究过程中是有很多问题的。
研究者通过不同的注意力机制和神经网络模型来处理复杂的场景。需要一个综述来总结这个领域现在的发展。现存的综述一般局限于技术细节,或者absa的特定阶段,没有指明这三个阶段的关键问题。而且现有的综述已经有点过时了,所以我们写了篇新的。
我们的综述针对AE,ASA和SE以及它们的集成解决呈现系统的、细节的和彻底的研究。调查还提供了一些可能的建议,有助于未来的研究开展。
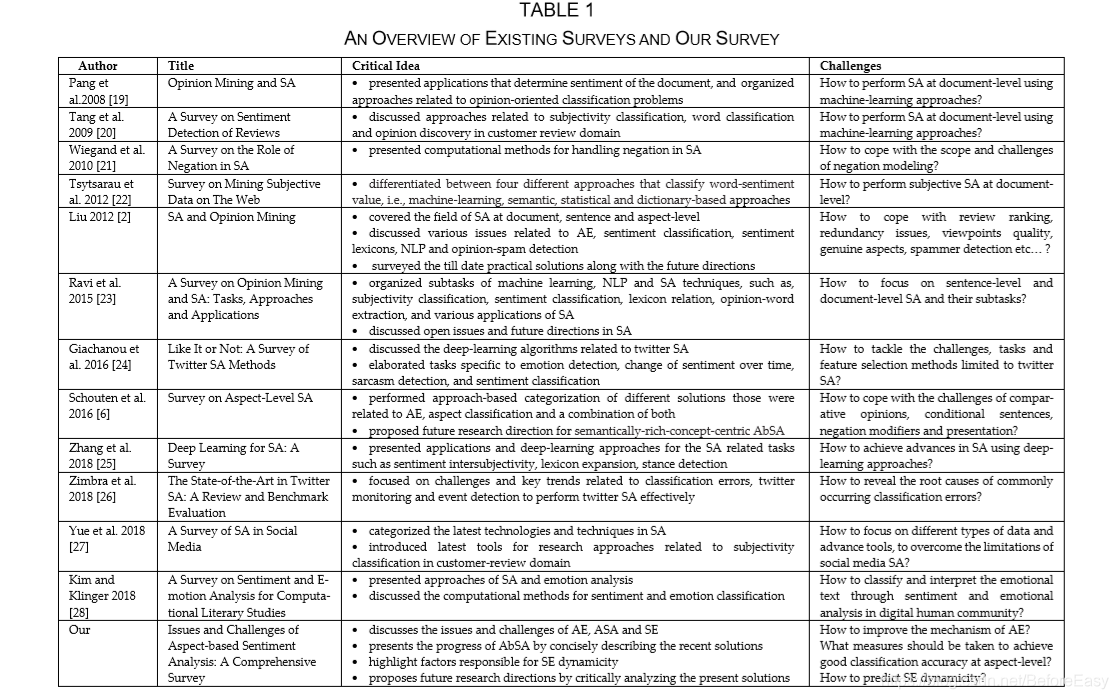
表1给出了对一些现存研究的简洁的总结(有关Absa和SA)
1.2 文章组织结构
首先给出了ABSA简要的介绍和意义。下面第二部分给出有关aspect的情感的定义,并列出与AE,ASA和SE有关的主要的问题和挑战。第三部分和第四部分讨论AE和ASA的主要问题,并简要描述现存的解决方法。第五部分讨论SE。第六部分强调未来研究方向。最后总结。
2 关键的解决方案
这一部分给出定义,列出主要问题和子问题。
2.1 定义(ABSA)
A sentiment is basically an opinion that a person expresses towards an aspect, entity, person, event, feature, object ,or a certain target。现在研究者多用aspect这个术语而不是feature。
Liu的定义是这样的,“an opinion is defined as a 五元组,
(
e
i
,
a
i
j
,
s
i
j
k
l
,
h
k
,
t
l
)
(e_i,a_{ij},s_{ijkl},h_k,t_l)
(ei,aij,sijkl,hk,tl)
其中ei是一个实体,对象或者人,aij是ei的第j个aspect,sijkl是观点的持有者hk在t时刻对ei的一个aij表达的情感,可以是正面的负面的或者中立的。ei和aij共同构成opinion target”
2.2 ABSA的核心问题和挑战
这篇综述要讨论的问题有:
- 如何有效进行AE,为什么到现在这还是个挑战
i. 如何提取显式的aspects,OTE ,隐式的aspects以及中性情感的aspects
ii. 如何进行跨领域跨语言的AE
iii. 如何映射不同数据对象间的关系来提升AE
-
如何进行ASA,如何实现一个可以深度分析所有aspects的情感计算的模型;为什么到现在这还是个很大的挑战以及热门方向
i. 如何在aspect(target),entity以及multi-word-target层面上进行情感分析
ii. 如何用多任务学习来提升情感预测准确度
iii. 不同数据对象间的联系、依赖和上下文情感关系是怎样提升情感分类效果的
-
如何测量情感值随着时间的变化;为什么到现在还没有杰出的成就,让SE成为一个开放的问题。
i. 如何在连续变化的情感特征中识别factors 以及跟踪明显的依赖
ii. 如何在社交数据上预测SE
以上三个问题是ABSA的核心,在granular-level上解决任何一个问题都可以带来提升。图1展示了这三个阶段,有一个必须的初始预处理过程,比如分词,大小写,stemming以及过滤停用词,排除无关信息等。接下来是将数据转为词向量(如word2vec,Glove,Elmo,Bert),然后相应的计算单词的位置信息等。
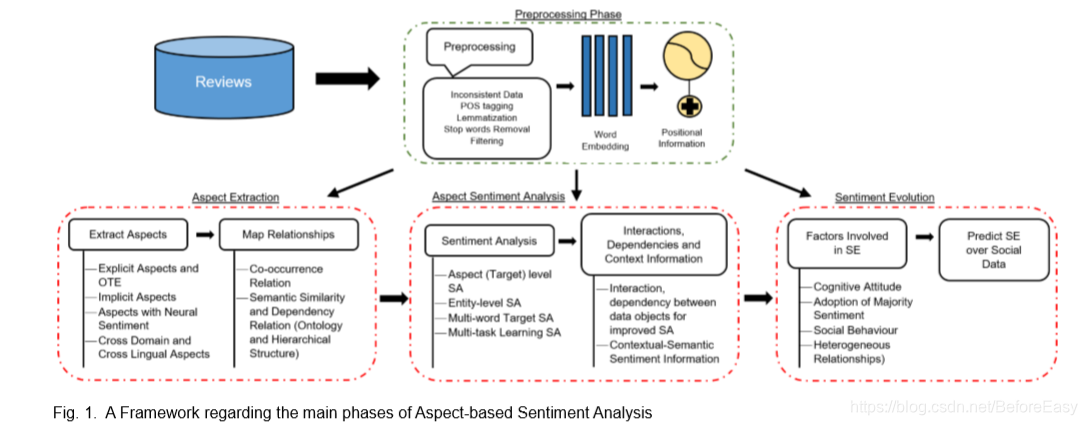
3 AE aspect extraction
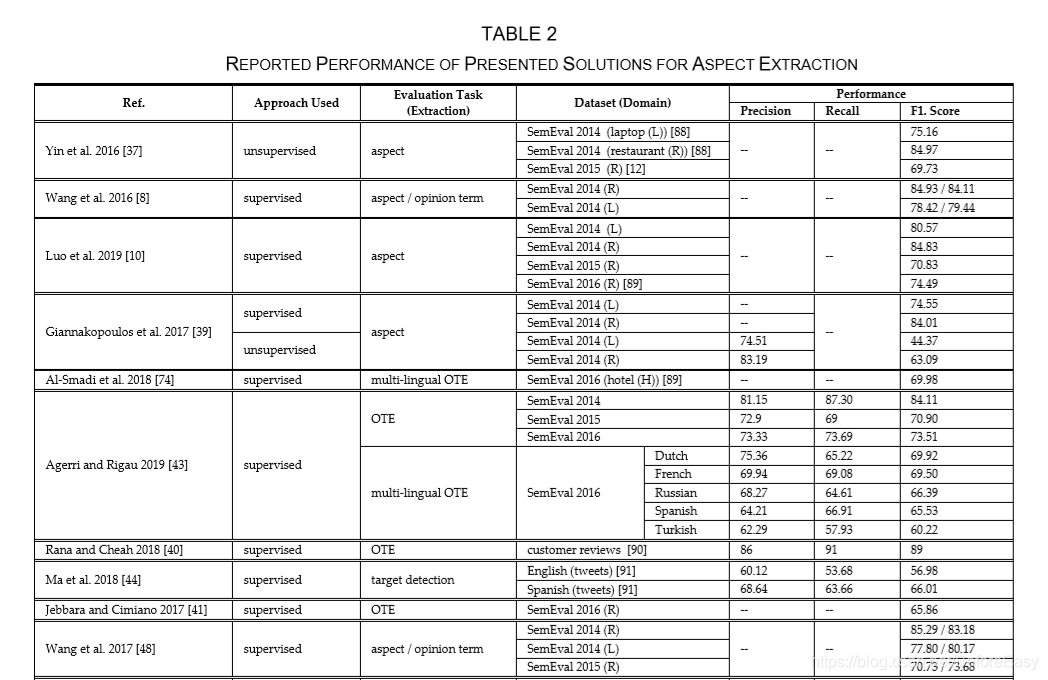
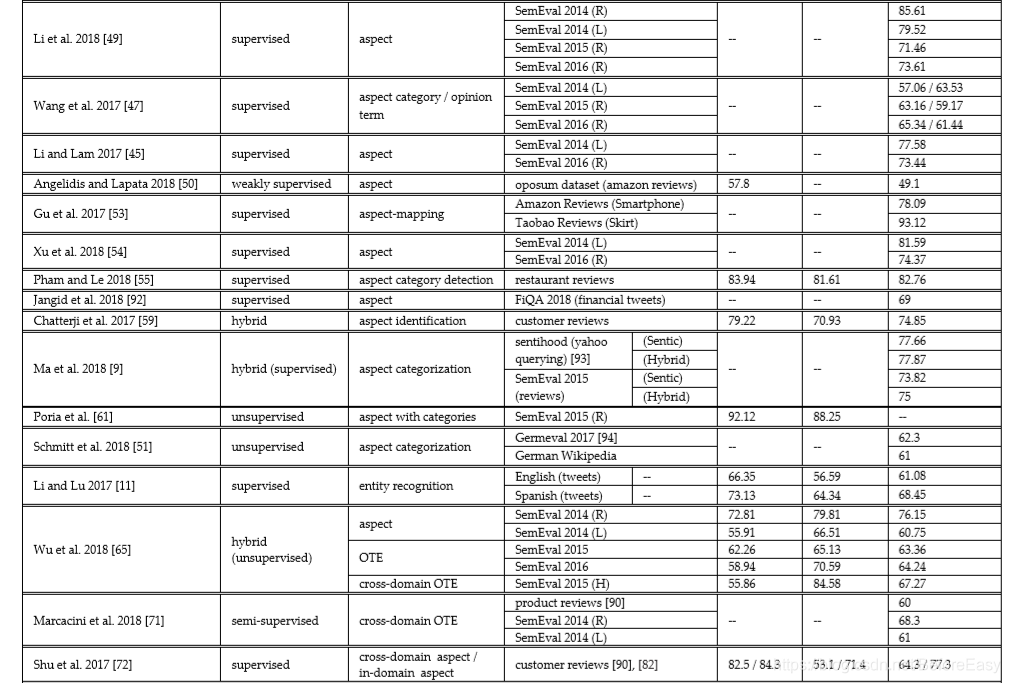
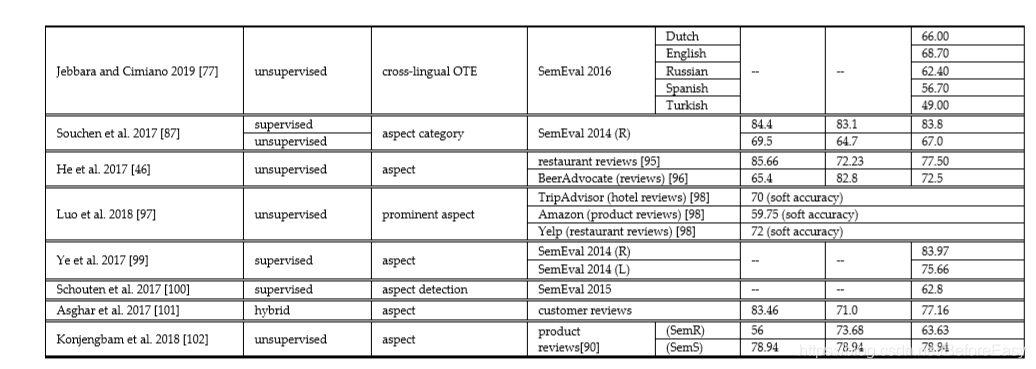
AE主要是检测和发现各种显式的隐式的aspects,实体,aspect categories和OTE。还会处理不同aspects之间的相关分布,以此从数据集中识别连续的、相关的、相似的aspects,以便提升抽取的整体效果。表2给了个总结。

3.1aspects的抽取
3.1.1 显式的aspects和OTE
AE最重要的问题就是提取显式的aspects、实体、aspect categories和OTE,在这些上面有表达的情感。
这里,“显式的” 的意思是,这些直接在文本里有。比如“the camera of this mobile phone is great”就是显式的,an explicit aspect: camera; explicit entity: mobile phone。 aspect category 是实体和这个实体的一个属性的组合对,比如“This mobile looks great but expensive”有两个aspect category:
“MOBILE#APPERANCE” and “MOBILE#PRICE”,然后这里的OTE是mobie,因为用户在targeting the mobile’s attribute。
序列标注技术,比如CRF,对于通过深度学习以及词向量,可以很好的提取不同种类的aspects。
很多研究者组合了CRF和RNN来提取显式的aspects和情感词,基于似然和反向传播机制。比如有人用BiLSTM+CRF来抽取显式属性和OTE,得到了很好的结果,监督和非监督的都可以。也有人通过CRF基于aspects和情感词之间直接和间接联系的生成序列模式规则来提取,关注从用户评论中学习pattern rules而不是手动来设计。也有人提出在CRF之后加上有charater-level embedding的RNN模型,结论是character embeddings有助于提高对没见过单词的鲁棒性和拼写纠正。
CRF还用于grouping semantic, syntatic以及lexical aspects。
此外,研究者还通过利用神经单元操作以及注意力encoders提高了aspect的表示。这两个方式处理了aspects和sentiment词之间的联系,让提取过程更顺利,还有助于实现多任务学习。例如,Li等提出一个两个LSTM的memory-interaction机制在多任务学习环境中提取aspect和情感词,记忆操作基于方面和情感词的位置信息以及情感术语的整体得分,还增加了情感句子的限制,以促进通过另一个LSTM的提取过程。Wang等提出多层神经注意力来处理aspects和情感词之间的dual-interaction。输入词向量和aspect以及情感词的向量来guide attention,以此来衡量每个输入单词之间的注意力得分,有更高的注意力得分的词会被认为是aspects或情感词。此外,Li等采用trimmed-history-attention机制,将有用的history-aware-aspect representation编码成从两个LSTM中得到的sequential-aspect representations。使用two-stacked rnns以及之后的auxiliary-opinion-based-word-recognition模块有助于refine提取OTE的边界。还有人提出一个弱监督神经注意力encoder,平均每个部分的词向量来识别aspects words;encoder假设数据中出现的每个aspect包含一个小的seed words集合,这个集合可以用于在多任务目标中识别包含aspects的segments。
尽管,正如之前讨论的,RNNs是执行AE过程中用的最多的模型,但是,要处理社交媒体中文本语法和语义的不规律,CNN比RNN效果更好。因为CNN提取局部的、position-invariant aspects,而RNN基于序列信息捕获更长范围内的语义相关性。例如,Gu等提出cascaded-CNN结构,通过卷积和最大池化来映射每个aspect的局部情感,这可以把每个aspect和它相关的句子联系在一起生成aspect category labels。 Xu等通过一个不那么复杂的神经结构来调整可见词的aspects以及语义来建模label dependencies,用Dual-Embeddings CNN(cross-domain embedding & domain-specific embedding)来encode每个输出词的信息,并用少量的监督来进行AE,但是没有处理the semantics of conjunction words(连接词的语义). 还有,Pham等通过三种不同的词向量表示(word2vec,Glove,one-hot)提取了更多的语义。每个embedding都经过一个独立的CNN channel 以及一个非线性的激活函数,来得到全局的句子表示,然后接一个单独的NN来执行aspect-category-label-prediction任务。
3.1.2 隐式的aspects extraction
隐式的和显式的aspects应该给予同等重要性。而隐式的aspects意味着并没有在text里清晰的指出,比如“I could not use the camera because of very low charging”,实体camera的一个隐式的aspect: battery。然而,显式的aspects得到了研究者更多的注意力。因为识别隐式的aspects十分具有挑战性,毕竟常常不包含任何名字或线索单词。不过像LSTM之类的NN类似人脑的工作机制,可以用门机制从数据中学习隐藏的知识。例如,Sentic-LSTM可以显式的组合隐式和显式的知识,它采用一个sequence-encoder以及自注意力机制来把affective-common-sense knowledge计算并合并到一个deep-neural-sequential model来处理multi-instance target。
还有一些通过dependency parsing, association rule mining, semantic ontology,classification, clustering 以及rule-based approach识别隐式aspect的研究,可以大致分为基于监督的、非监督的、半监督的以及混合学习。SemEval 2015包含实体隐式属性的分离。还可以用CRF。此外还有人提出AspectFrameNet, 把aspects看作Frame elements,把识别隐式属性显式属性看作是sequnce-labeling task。根据定义好的模式规则,AspectFrameNet可以自我更新。Gaillat等通过经济领域预先定义好的aspect’s patterns来对显式和隐式属性分类。输入中每个词的联系是基于occurence计算的aspect-class,然后再进一步用机器学习算法来进行最后的分类。Poria等通过Sentic Latent Dirichlet算法,集成了常识推理来计算单词的表示,在clusters中概率最高的词被认为是aspect terms。
尽管有上述讨论的方法,但implicit-aspect extraction仍然是需要解决的问题,可以考虑提高特征工程以及用更大的数据集。
3.1.3 Aspect Extraction with Neutral Sentiment
每个属性对于提高情感分类的准确性都起着不可或缺的作用。 但是,研究人员主要关注具有积极和消极情绪的属性,而具有中立或语言情感的属性则被忽略了。也还是有人用端到端的优化NN模型来检测正面负面和中立的情感。例如,Wu等提出chunk-level-extraction method 来提取中立和隐式aspects。该方法既有基于规则的方法也有监督学习方式来得到合理的预测和经过深度NN后更高级别的aspect表示。Li等调查了通过捕捉aspects与实体之间无限的长距离依赖关系的情感-范围图,研究了中性方面的情感范围。
3.1.4 Cross-Domain and Cross-Lingual AE
领域应用的局限性和特征会导致领域依赖性,这是AE中的一大挑战。Inductive-transfer learning 可以用于从两个领域中提取公共aspects,但前提是它们有共同的特征空间以及相同的分布式特征。由于不同的域具有不同的边际概率分布和特征空间,因此跨不同的域使用预训练和微调可能会导致不一致问题。尽管跨领域迁移学习有一些可行的方法,但是使得数据的常规标记变得昂贵甚至近乎不可能。与此相反,转换学习(transductive learning )对于处理未标签数据分类更为有效。例如,Marcacini等通过统一表示模型用转换学习集成不同领域的知识。他们借助数学形式化框架和融合的理论保证,从源域的标记属性到目标域的未标记属性,在异构网络中映射了不同的特征(作为节点),即语言特征。Shu等声称通过保留以前领域的知识,可以极大地改善终身机器学习-CRF( lifelong-machinelearning-CRF),以从不同领域提取aspects,以方便将来的学习。Akhtar等采用 Particle Swarm Optimization technique不管领域如何,可以有效的自动发现最相关的aspects。
一般来说,研究集中在英语,但是近些年来其他语言的研究也多了起来。用机器翻译找多语言OTE需要NLP资源来进行POS tags 和依存特征间的单词对齐。类似的,用POS , bigrams,lemmas等不同特征的CRF系统也在西班牙和英语上取得了很好的效果。 Agerri 等还把多语言OTE提取建模成了序列标注任务。他们的语言独立模型从基于语义分布的各种数据源中获得了不同的特征簇,即局部特征,浅特征和独立特征。Jebbara等用zero-shot-cross-lingual approach 以及多语言词向量来预测OTE。它们用共同的向量空间将源语言转换学习到目标语言。
3.2 Map relationships
为了精确映射特定实体和属性间的关系,提取的数据对象的显式表达很重要。这些关系包括co-occurrence relations ,dependency relations , dependency-context information以及其他关系,可以通过基于树结构、 sentiment ontology or conceptual ontology的aspects层级表达来映射。这些映射表示都有助于理解不同数据对象间的关系并以结构化的方式呈现product information。
3.2.1 Co-occurrence Relation
共现关系有助于预测单词分布间完整的、连贯的一致的知识,比如把beef,mutton,fish(aspect terms)关联到一个aspect(meat 也可能是 food)。现存的很多模型并没有包括先验知识,比如在AE过程中考虑每个文档的主题分布、编码单词共现统计特征来保存主题一致性,因此常常deduce aspects of poor quality. 为了解决这个问题,Souchen等人采用一种监督方法来计算annotated categories以及lemmas间的共现频率,还添加了单词间的语法依赖来增加检测准确性。此外为了计算单词间直接或间接的关系,他们还考虑了非监督的association-rule minning。通过spreading-activation过程给每个单词分配一个activation value ,activation value 高的单词会被认为是aspect category。He等根据单词上下文映射共现关系来发现 neural-embedding 空间中的相关aspects。通过注意力机制成功的区分出了不是aspect的单词还保留了词向量的唯一性。Li等也是通过memory interactions捕获aspects和sentiment之间的共现模式。neural-memory operators 获得数据对象之间的联系,并且生成任务级别的信息summary。
还可以用association-rule-mining , aspects-clustering, co-occurrence matrix以及基于图的方法等捕获单词之间的共现关系。 co-occurrence matrix关注句子和aspects之间的关系,目的是找到隐式的aspects,而基于图的方法用概率模型来定义单词间边的权重来表达共现关系。
有时,共现关系和词频信息会导致从句子中提取到相似的aspects,而实际场景中这些aspects 应该被视为不一样的。比如,“beautiful design” and “good looks” 应该被视为手机的两个方面,虽然两者都在appearance catogory下。为了解决这个问题,Luo等通过检测输入数据的lexico-syntactic 来解决潜在aspect terms重叠的问题。他们通过WordNet中的同义词集在子图中的包含关系中找到了唯一的aspect terms。,他们的方法充分涵盖了prominent and distince aspect。
3.2.2 Semantic and Dependency Relation (Hierarchical and Ontology Structure)
基于语义和语法序列的依赖模式有助于发现缺失的同义aspects并区分非aspect词。可以通过层级结构或ontology tree得到依赖关系。
在两个aspects(nodes)之间 进行关系分类来得到分布式表达,节点可以是相邻的也可以是父子节点。Ye等提出的句子树相关信息,通过卷积神经网络捕获句法和语言的aspects,然后加一层推理层来得到最后的tag 结果。此外,Yin等通过递归神经网络encode语义和上下文信息到词嵌入表示中来显式的学习semantic embedding paths来作为grammatical relations in dependency tree,并使用sequence-labeling CRF来提高AE。类似的,Luo等也是基于BiLSTM学习sequence-labeling syntactic-dependency tree用于aspect提取。
用ontology tree and ontology feature 作为knowledge-base有助于定义不同领域概念间的关系。这些公理可以用隐式信息生成aspects并review summaries以提高提取效果,还可以把领域知识编码到ontology-tree中来减少训练数据。例如,Schouten等把领域知识编码到有target和sentiment lexicons的ontology tree,把aspect detection任务看作是是二元分类。文本与其领域的联系可以更好的指导AE。 Konjengbam等提出一个包括aspects,sub-aspects及其之间的关系和不同aspects间语义联系的层级树结构。在探索了所有的aspects机器相关的review-snippet后,用两个基于语义关系和相似度的ontology tree来集成每个product相关的信息。
除了层级结构和ontology tree,基于语义相似度的heuristic patterns 也能在合理的时间内得到不错的AE近似解。例如, Asghar 等用一个hybrid-integrated framework with an extended set of heuristic patterns来提取语义上接近的aspects,其中评论数据里的名词、名词词组和动词都被视为候选terms。
4 ASPECT SENTIMENT ANALYSIS (ASA)
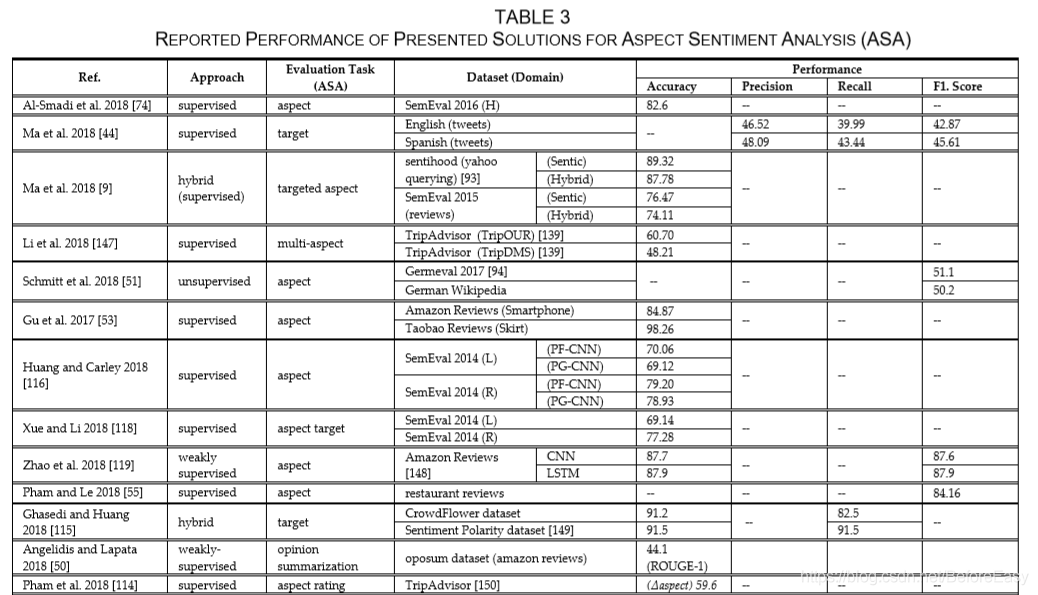
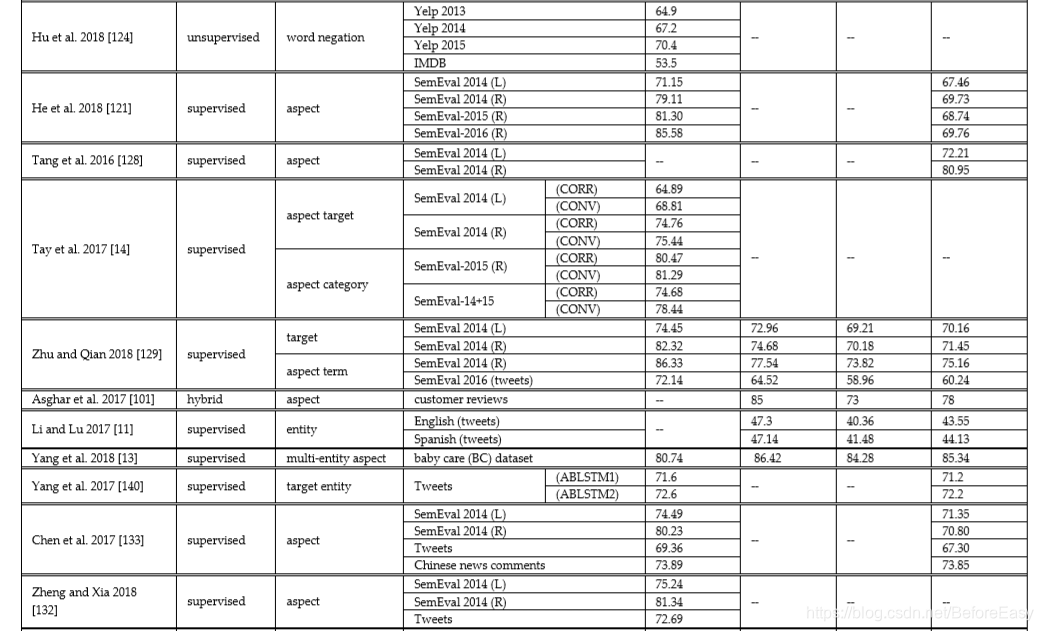
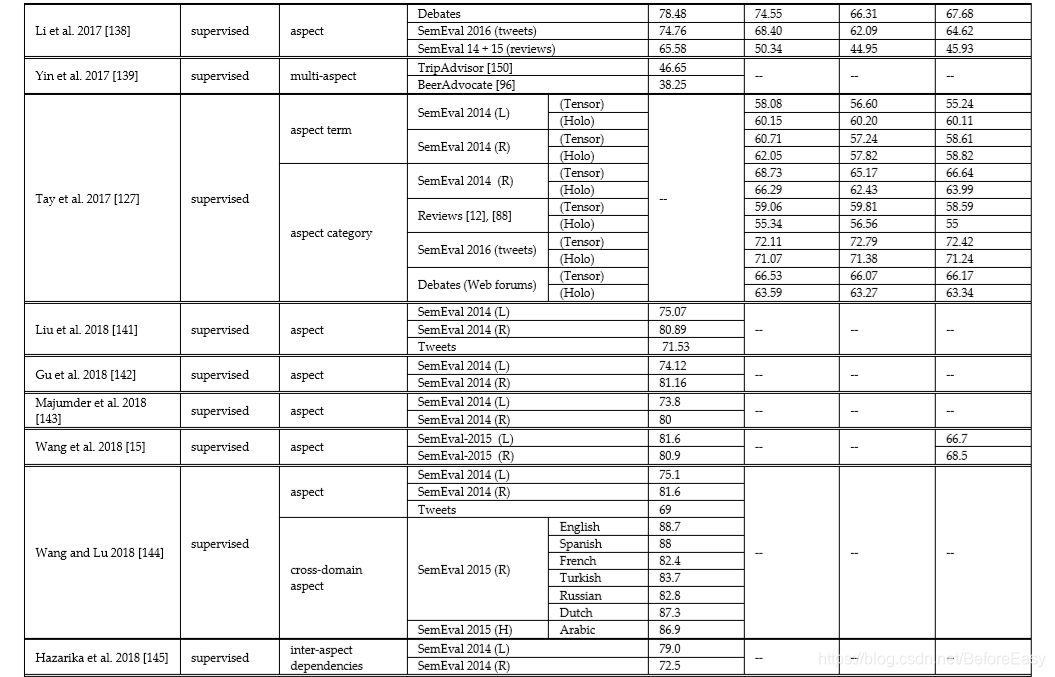
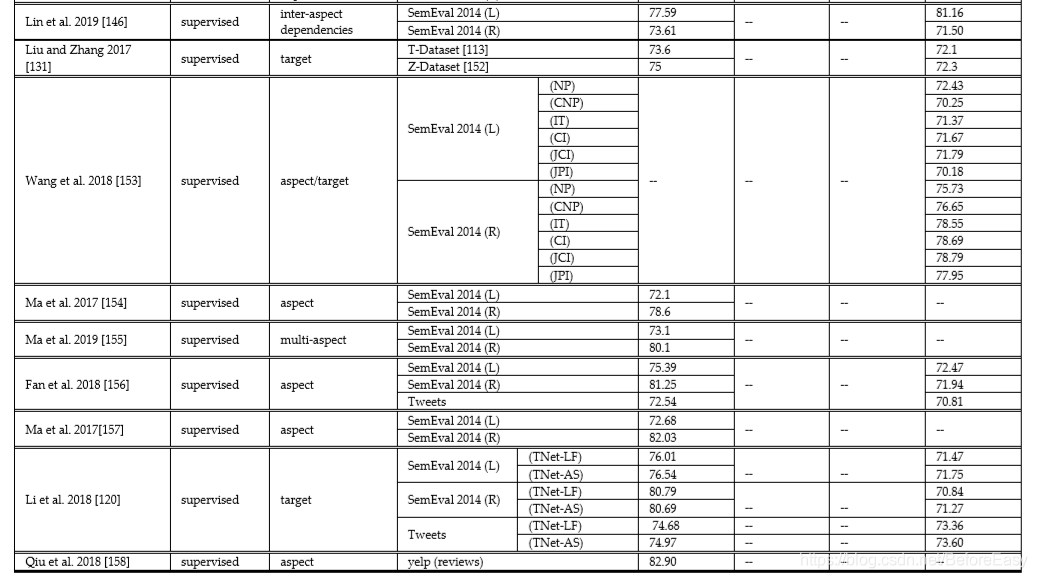
ASA是ABSA的第二个阶段,给提取出的aspect,target or entity分配一个情感得分。为了提高情感分类准确性,还会考虑不同数据对象之间的关系、依赖和上下文情感联系。表3列了一下针对ASA的各种方法

4.1 Sentiment Analysis (SA)
ASA相比一般的SA有更详细的信息,因为预测给定aspects,target和entites的情感极性。一开始ASA主要依靠手工设计特征,比如n-grams, sentiment lexicons或dependency information。但是,随着深度学习的发展,可以用于自动学习aspects及其情感,从而为AbSA中的许多问题提供最佳解决方案。
4.1.1 Aspect (Target)-level SA
Aspect (Target)-level 通过为每个数据对象学习单独的表示来进行情感分类。NN模型可以清楚地表示单词,即通过测量和识别不同数据对象之间的语义和句法相关性,在单词级别添加更多信息。具有字符级嵌入的BiLSTM可以清晰地表示OTE和非词汇词,从而有助于获得良好的情感信息。比如,Ma等通过一个多层的BiGRU学习并指出non-vocabulary words。该模型可以适当地生成目标标签,因此可以很好地预测情感标签。Pham等人将包含词嵌入的表示学习技术的前馈NN与用于捕获语义信息和更丰富知识表示的组成矢量模型 相结合,设计的神经网络利用现有的aspectrating and higher-aspect representation layer 来产生综合情感。Ghasedi和Huang采用了CrowdDeep自动编码器和概率方法,以有效地重建和减少损坏的文本数据的噪声。该方法通过估计文本数据的基础信息来对情感进行准确的分类。由于使用文本数据作为信息源,因此在处理非常大的数据集中训练参数不足时,它也没有遇到任何内存耗尽问题。除神经网络外,Asghar等人还构建了一个混合集成框架,根据语义相似度对提取的aspects进行分组。通过基于词汇和语料库概念的情感评分技术将情感分数分配给各个方面。
除了像LSTM和GRU这样的顺序模型外,CNN还被证明可有效实现目标情感分类的准确性,以及许多其他NLP任务,例如关系分类和信息检索,比如,Xue and Li开发了一个包含新的门控Tanh-ReLU单元(GTRU)的门控卷积网络,该网络利用aspect embedding来选择每个receptive field上的n-gram特征以执行aspect-category SA和aspect-term SA。用ReLU激活函数的GTRU单元在卷积层之上,可以并行计算。此外,Zhao等人提出了基于CNN的weakly-supervised-deep embeddings,以学习高级表示形式,从而反映来自大量弱标记句子的总体情感分布,分别使用评论评分(作为弱标签)和带有标签的句子来训练和微调深度NN。此外,Pham和Le还采用了多CNN模型,其中每个CNN均使用不同的word embedding(即Word2Vec,Glove和one-hot字符嵌入)进行初始化,以捕获文本中的语义。每个CNN模块同时用相同的非线性激活函数进行训练。最后得到的向量表示经过单层NN来进行情感分类。Li等人利用CNN层从双向RNN起源的转换词(transformed word)表示中提取salient features。他们采用了一种接近度策略,即通过根据词与目标之间的位置相关性来缩放CNN层的输入,从而准确地定位情感指标。该技术可以处理一般和目标敏感(target-sensitive)的情感。
尽管RNN和CNN都通过门控机制和卷积程序从一个步骤到另一个步骤显著处理了相关信息,以改善情感分类。但是随着输入句子长度变长,隐藏向量很难保持住。在这里,注意力机制通过对输入序列中最相关的信息进行编码,有助于缓解长序列问题。它与神经词嵌入相结合以捕获句子的关键部分,这有助于显式结合显性和隐性知识,并产生良好的情感信息。比如,He等用基于注意力的LSTM在aspect-level数据上进行训练以捕获领域特殊的情感词。他们假设可以通过使用两种转移学习方法(即预训练和多任务学习)来充分利用领域知识,从相似领域的文档中获得更多知识,因为这两项任务在语义上高度相关。此外,Hu等人利用聚集的情感(aggregated-sentiments)和否定词作为attentions,从数据中捕获语义成分以形成句子表示;接着将单词,句子和文档表示的层次结构合并到一个目标类别(one-target-class)的标签中,以进行最终的情感预测。He等人采用了一种自动编码器,该编码器经过基于神经注意力的情感分类器的训练,可以学习与语义相关(有意义)的aspect embeddings;此外,还利用局部注意机制,通过平均目标和上下文信息,为给定目标创建weighted combination of aspect embeddings。所采用的自动编码器提供了良好的目标表示,并具有较高的预测情感准确度。Angelidis和Lapata利用了基于分层注意的神经体系结构,该体系结构采用了贪心算法来丢弃多余的opinion。这个神经结构需要很少的知识和较少的监督来进行情感分类,并以最少的人工干预就能从高级意见(high-ranked opinions)中生成基于均衡意见的摘要。
网络体系结构的另一类是memory network,它为序列中的每个输入单词提供显式上下文表示。像注意机制一样,memory network也减轻了学习顺序数据中的远程依赖关系的问题,并且还绘制了不同数据对象之间的关系以提高情感分类表现。例如,Tang等人使用了一个包含多层的external memory,其中每一层都作为attention mechanism,用于学习每个上下文单词的含义;他们将aspect terms视为一种query,并利用上下文信息进行连续的文本表示。 最后一层的计算特征被用于情感分类。Zhu和Qian执行两个存储器之间的交互,即,深存储器网络和辅助存储器,以学习每个输入单词的上下文并显式地生成aspect和term之间的连接,将每个memory视为注意力,并将辅助记忆的结果反馈到主记忆以进行最终情感分类。
4.1.2 Entity-level SA
实体SA是ASA的子域。 引入情感范围图以基于以下假设共同确定命名实体及其各自的情感:假定每个实体被负责捕获其情感极性的无界窗口包围,固定大小的有界窗口是无法实现的。但有时,评论包含具有相同aspects的实体,因此很难捕获aspect与entities之间的情感依赖性。比如,“Bought Johnsons baby lotion, texture was very smooth, but bit expensive. Then I tried Mother Care but texture was bit oily“,这个例子中有两个aspects:price和texture,两个实体都有涉及( Johnsons and Mother Care).为了解决这个问题,Yang等同时建模了上下文、实体和aspect memory。其中context memory用三层( interaction, position and LSTM layer),上下文存储器利用三层(即交互,位置和LSTM层),来执行实体,方面和上下文信息的逐元素乘法和级联。其他两个存储器,即实体和属性存储器,以迭代的方式有效地更新了上下文存储器,以预测每个(aspect-entity)对的情感极性。
4.1.3 Multi-word Target SA
社交媒体上评论大多包含不止一个词的aspects,比如 hot-dog, mango pudding, Chinatown 等。 Single-attention-based methods 或仅仅是LSTMs不适合多个单词的表达,因为取单词向量平均来进行aspect-mapping不能很好的捕获多单词target的语义,而且可能影响每个单词的完整性。因此,有研究设计模型通过注意力机制和RNN结构对句子中每一个单词的贡献度建模。例如,Chen等人利用BiLSTM非线性地结合了多种注意力(记忆)来处理复杂的多词表达。 句子中的每个目标都有自己合适的记忆,并且根据目标在特定句子中的位置来定义记忆片的权重。Fan等人提出了一种基于卷积的存储网络,该网络与注意力机制结合在一起,可以对句子中的单词和多单词信息进行显式建模。 该模型将上下文信息通过BiGRU存储到固定大小的窗口中以进行情感分类,从而映射了低维嵌入空间(map low-dimensional embedding space),提取了连续的方面并捕获了远距离依存关系。
4.1.4 Multi-Task Learning SA
传统的SA方法已分别处理三元(3类)和细粒度(5类)分类学习的任务.但是随着时间的前移,多任务学习在各个领域得到验证。这些技术可以优雅地访问为类似任务开发的资源,以学习不同任务的隐藏表示,并通过NN促进多任务学习环境。例如,Balikas用BiLSTM进行三元和细粒度情感分类来联合学习多个独立的任务。这些任务通过共享信息联系在一起,可以提升整体的泛化性能。每个任务有独立的softmax层来进行最后的分类。此外,Li等采用一个多任务深度memory network,通过公共情感空间有效的建模子任务和targtets间的关系。其中的语义相关性有助于同时学习targets及其各自的情感极性。此外,Yin等将层级注意力架构建模为机器理解问题,并使用多任务框架为ASA在单词级别和句子级别构建不同的表示形式。这些表示与aspect-questions相关,用一些aspect-related关键词和ratings可以构造伪问答对,用于通过input-encoders和迭代attention模块来学习aspect-aware-document的表示。
4.2 Interactions and Contextual Sentiment Information for Improved ASA
4.2.1 Interaction between Data Objects
数据对象之间的交互和依存关系可实现精确的属性表示和情感分类。但是现有的工作没有考虑到句子中邻近的aspects和inter-aspect 的关系和依赖。单层的神经网络也缺乏捕捉aspects和terms间相关性、提取不同aspects 以及aspects和word terms间关系的表示学习能力。但是,注意力机制和深层存储网络通过侧重于正确的aspect terms以及从句子中捕获长距离,inter-aspect,从句级别和结构上的依存关系,可以有效地用于绘制不同数据对象之间的关系。例如,Tay等人采用向量的循环卷积和循环相关性,通过attention layer对属性和单词之间的关系进行建模;注意力利用associative memory operator计算了aspect-word fusion 的概率权重, 然后将这些学习到的注意力得分和LSTM层的所有隐藏表示传递给softmax进行最终情感分类。该模型高效且廉价,因为它没有在LSTM上附加任何额外的任务来学习单词-属性关系。Liu等也通过content-attention 机制考虑了单词和aspects间的关系。他们首先通过句子级内容注意机制从全局角度捕获了有关给定属性的重要信息。 接下来,为了关联属性和单词,并将顺序单词嵌入到自定义的memory中,他们采用了上下文注意机制。双方的注意力共同考虑了每个单词(方面)传达的句子的全部含义,以进行最终的情感分类。此外,Tay等人采用的存储网络利用参数化的神经张量组成(parameterized-neural-tensor compositions)和全息组成( holographic compositions )来对属性和单词之间更丰富的交互进行建模。具有复杂值计算能力的丰富的二元交互(dyadic interactions)有助于提高情感分类性能。Zhu和Qian提出了一种新型的具有辅助存储器的深度存储网络,该网络可通过注意力机制且基于语义相关性来处理属性与术语之间的关系。 辅助存储器( auxiliary memory )的结果被转发到主存储器(main memory),以捕获每个单词的上下文以进行情感分类。
Gu 等认为,相比其他远距离的单词,应该给aspects及周围的词更多权重。他们提出了一个position-aware-bidirectional-attention network 来处理aspects和句子之间的关系。先为对应句子中的每一个单词生成aspect-positional embeddings,然后再拼接上word embedding一块得到最后的上下文相关的隐含状态用于分类。此外,Majumder等也提出了一个记忆网络结构来建模inter-aspects及其相邻aspects间关系,利用GRU提升单词的contextual information,然后再用注意力机制得到aspect-aware-sentence representation。最后的aspects和情感分类通过不断再记忆网络中迭代来得到。不过,Wang等是通过一个segementation-attention-based LSTM来选择对分类有最重要影响的情感词,并捕获和建模targets与情感以及情感词之间的结构依赖。
然而,另一个挑战是处理有多个aspects的句子,会有两个部分的难点:一是把aspect对应到包含其情感的那部分句子中;二是为没有足够上下文或情感信息的aspects总结情感。因为,有时候,有连接词“ but, not, also, though, however, only etc”的词很适合预测aspects的情感,比如“Food is great, but I doubt about the freshness of meat”,food的正面情感加上表示转折的but可以推测出meat的情感是负向的。另一个例子,““The grocery list was short; I remember it contained only 5 to 7 items”中,aspect-item并没有包含情感词,除非我们也考虑到aspect-“grocery list”,因此。“grocery list“的负面情感也导致”items“有相似的情感。为了解决这些困难, Hazarika 等通过一个带注意力的LSTM,关注所有aspects以及句子中的特定单词来得到aspect-sentence表示;此外他们还用另一个LSTM通过序列建模aspect-sentence表示来捕获inter-aspects依赖,以此估计那些上下文信息不够多的aspects的情感。另外,Wang等为了提高情感分类效果,用层级的aspect-specific-attention network 来处理句子中单词级 以及 clause-level的信息;首先实现elementary-discourse units把句子分成不重合的几个clauses,接着用BiLSTM和单词级别的注意力机制来分别编码clauses的信息和每个clause中每个单词的重要性;然后用另一个BiLSTM和clause-level attention来计算每个clause的attention weights以及相对的重要性。此外,Lin等采用深度记忆网络来建模,通过语义attention和上下文学习学习来建模inter-aspect-semantic 依赖以最终确定所有aspects的情感。通过语义解析,注意力机制可以利用出现在memeory中的每个显式aspect的信息,而且 通过学习整个句子的语义分布,context-moment-learning 模块可以提供特定aspects的完整上下文。
4.2.2 Contextual-Semantic Sentiment Information
注意力机制带来的显著提升极大的提高了神经网络的能力,对文本的情感分析越来越多变成上下文分析。文本数据背后的上下文情景富含丰富的信息,让事情变得有趣起来。因此,一个关键的步骤就是检测给定aspect(target)的情感上下文,用于正确的情感预测。很多研究者都采用注意力机制来得到targets和上下文单词之间的语义相关性,以捕获target信息并为情感分类计算上下文表示。除了注意力机制,深度记忆网络、LSTM、GRU以及aspects的位置信息也都被用于提高单词的上下文语义情感信息。比如,Fan等用BiLSTM和多粒度注意力网络来捕获相似上下文间的关系,可能包含相似或不同的情感极性;通过不断链接和融合aspect terms以及上下文单词来获得单词间的时序联系,这样没有信息损失。网络根据aspect terms 和targets来计算上下文单词的注意力得分,反之亦然。注意力机制还学习了有相同上下文单词的aspects的attention difference。此外,Yang等采用一个多视野的、联合注意力的网络来建模情感词、目标和上下文单词的通用语义。首先通过低维度的embeddings学习单个输入、POS和单词位置特征的表示;接着用三个独立的LSTM和注意力分别获得情感、目标和上下文单词的隐含状态以及捕获不同位置来自不同表示空间的重要情感信息。另外,Ma等,为了同时处理多aspects及其情感,用LSTM和位置注意力机制来计算aspects和上下文单词间显式的位置上下文信息。
但是有时候,简单地依靠注意力模型并不能解决上下文语义情感信息问题,因为当上下文单词的情感对给定target单词敏感时(is sensitive to),效果会变差。因此,Ma等从人类认知特性中得到启发,并专注于对每个上下文单词用更有效的表达方式。他们观察到只用词嵌入作为外部记忆是不够的,因而他们通过记忆网络提取了位置、POS以及情感特征来丰富每个上下文单词的表示。模型的每一层都被设计为计算aspects表示和上下文单词间的注意力得分,最后一层的aspects表示过ReLU来得到最后的情感得分。总体上,这个模型在分布注意力得分和无视非情感单词上表现不错。Yang等以相对均匀的方式考虑了不同单词的位置后,对单词间的长序列进行了建模,用于在BiLSTM以及顶部有额外注意力层的情况下来进行target-dependent-sentiment分类。一个注意力层考虑了当前输入和target的上下文以及intent importance,通过点乘操作来计算每个单词的注意力得分。另一个注意力层通过bilinear term计算注意力得分。此外Wang等提出六种可选的target-sensitive-recurrent-attention-memory 网络来捕获aspects及其上下文情感间的关系,通用和target-sensitive情感这个网络都能处理。
还有,Qiu【158】等通过考虑aspects和相邻的上下文,用序列标注技术CRF来预测评论的得分,模型的核心是概率判别模型,CRF的一个变种,叫SentiCRF,SentiCRF建立一个术语对列表,术语对中每一个元素是其对等元素的上下文。这些上下文信息有助于给术语对分配合适的情感得分。
5 Sentiment Evolution
SE是ABSA的第三个阶段,处理情感随着时间的动态变化。SE引起研究者关注已经有二十年了,因为SE描绘了形成情绪变化的overall agreement的社会多样性。SE的两个主要问题是:认识到促使人们改变情感的因素(比如认知态度、采取主要情感、社会行为以及异类自信的影响);以及预测社交媒体上的SE。
5.1 Recognition of Factors in SE
5.1.1 Cognitive (Informational) Attitude
认知态度指的是对特定aspects的想法、知觉以及理解。基本上是一种观点,描述了一个人对特定aspect(object, event, entity, target or person)的general knowledge,而这会使其改变ta对特定事件的情感。比如,随着时间的流逝,诸如世界杯这样的大型赛事的情感结果也充满了活力。记住这一点后,Chi等提供了一个理论框架,将情感评估态度( affective-evaluation attitude )和认知评价态度联系起来,以评估SE。Chi等研究了这些态度并预测了人们在一段时间内对某个事件的决策心理。他们发现人们赛前赛后的态度变化是由于对特定aspects的信息洞察和理解,因而随着时间改变了情感态度。研究者明确表示,某个aspect(event)的上下文是人类决策倾向的基本原因。
5.1.2 Adopting the Majority Sentiment (Minority Avoidance
SE相关的另一个问题是对主流情感的偏好。人们会采取邻居或亲戚的情感,并避免与持不同情感态度的小社区产生关联,而不是展示自己的情感倾向。Fu等发现SE大致上基于适应主流、避免小众的规则。他们的网络结构是一个主流规则模型(majority-rule model),研究发现人们更倾向于跟着大众更新自己的情感,并和持有不同情感的团体切断链接。研究表明,与邻居建立联系的趋势不断增加,降低了情感数量。他们的调查清楚地表明,志趣相投的人具有相同的情感,属于该网络中的单个团体。
5.1.3 Social Behavior
当个体与community及其周围环境交互时,社会行为产生。在社交互动过程中,情感的变化取决于诸多社会影响(如和谐和分歧等)。因为有时个人会受到邻居的影响并作出决定,但是仍有可能个人仍保持自己的观点而不是跟随大众。Chen等还表明社会政策、关系和范式(norms)对social evolution有巨大的影响。他们基于社会文化和政策的多样性提出了三个不同的social-acquaintance networks ,分别叫kinship-priority-acquaintance network (KPAN), independence-priority-acquaintance network (IPAN), and hybrid-acquaintance network (HAN),发现由于人们大多数时候会相信亲朋好友的情感,KPAN总是得到情感上的碎片(fragmentations in sentiment);在IPAN中,SE基于西方价值观(?)鼓励独立决定情感但同意讨论。HAN同时考虑了这两个网络,表明情感在很大程度上会达成共识。这些网络的发现有助于在不同的社交网络下计算和预测SE,还有助于形成合力的文化政策。
5.1.4 Heterogeneity of Confined Confidence and Influence (HCCI)
有时候,heterogeneity-confidence 在网络上的分布会被忽略,由于地理位置或社会身份,人们不能彼此交流却仍然有相同的情感度。为了解决这个问题,Liang等在离散时间场景下检测了HCCI,这种情况下所有agents在平均其neighbor的情感后同步更新了他们的情感级别。在网络中,每个cluster都在促成情感共识之前的有限时间内保留了情感的价值,但这并不总是正确的。此外,为了在异构网络环境中发现各个节点之间带权重和符号的关系,Pengyi等探索了在异构关系中的动态情感模式。经过一系列模拟,他们发现在稳定状态下,情感水平取决于网络之间的社交沟通程度。观察发现,当网络中的和谐度参数(harmoniousness parameter )增加时,情绪将从双极化( bipolarization )转化到共识阶段( consensus phase)。
5.2 Predicting Sentiment Evolution over Social Data
在实时应用中预测变化的个人社交行为是很复杂的任务。Nguyen等提出一个统计机器学习模型来分析收集到的情感级别,进而把模型转变为大的结构化网络,包含许多个人和tweets。从历史数据中提取aspects并用来预测未来的情感变化。此外,Guerra等跟踪社交媒体用户在twitter上持续变化事件中的情绪反应(如突发新闻、政治谈话等),发现用户更倾向于积极的想法而非消极的,而且用户更喜欢表现自己针对事件的极端想法而不是普通想法。加上对这些极端想法的考虑,他们提出了一个特征表示方法,能够通过捕获真实世界事件导致的情感频繁变化来发现新的aspects。Lumin等提出一个层级的多维度的模型,首先捕获针对事件的非冗余情感模式,然后通过聚类算法发现closed情感模式。这个算法还能维护一个情感向量,保留情感变化背后的原因。模型专注于用户级的情感动态,并在正是数据集(2011年3月的日本地震)上进行了研究。Charltron等观察不断发展的网络的动态交流能力,从而认识到Twitter上的顶级传播者。首先,他们计算communities的初始情感,然后通过community-detection算法检测了用户流失之间的相关性;还在几个月的时间内监控了稳定的已连接的Twitter社区,发现与普通用户相比,具有最高可传播性的广播目录(highest communicability-broadcast directories )的人们总体上表现出积极的情绪。研究还发现,每个社区都保持稳定的情感水平,并通过发送消息保持联系,但是当一个社区显示出比其通常的情感较大的偏离时,某些社区将留住了所有的用户,而某些社区则失去了少量用户。
6 DISCUSSION AND FUTURE RESEARCH DIRECTIONS
在NLP尤其是ABSA领域取得很好的结果需要大量的努力。aspect抽取和情感判分是ABSA的核心挑战,可能无法用single-general solution来解决。研究者需要考虑很多子挑战和子问题来解决主要的挑战。这些子挑战将为AbSA开发有效的工具,并在某种程度上提高情感分类的性能(在某种程度上)。这部分将讨论一些。
6.1 Data Pruning and Cleansing
通常在预处理阶段,会从文本中去掉标点符号、常见词、特殊字符、俚语及代词。据我们所知,所有这些都对分析文本的情感极性没有多大贡献。不过停用词和冗余术语应该用有效的pattern-based方法去掉。
在预处理时,多个领域特定的词典也将是一个有趣的发展,它将产生距离度量,整合未分类评论的模糊成员并执行自动域标记;还可以用于AE,来丰富有意义的文本信息。
6.2 Cross-Domain-Transfer Learning
有监督的方法可以很方便的处理有标记的数据,但是需要很大的训练数据集。通常,AE过程的效率会在处理未标记的数据集时受到影响,并且在将其应用于新域时可能会失败,比如,在餐厅数据集上训练的模型就不能用于旅店的数据。无疑,很难有个通用的模型可以在所有领域上都表现的不错。不过,如果搭配有效的self-attention机制来进行阔领域前移学习,就可以通过预训练和微调过程提高模型表现。因为self-attention网络可以通过关联输入及其上下文和位置信息来处理复杂的数据。我们相信这一挑战会成为ABSA中有个新的领域,但它需要对文本表示进行适当的改进,例如统计和语言功能,以及通过有效的转换学习(transductive learning)进行标签传播( label propagation )。
6.3 Contextual-Semantic Relationships
对于根据上下文信息关联单词和句子,语义信息是必须的,有助于从数据中提取显式的和隐式的aspects,中性情感表达以及复杂文本,比如否定词。基于语义信息,还可以映射不同数据对象之间的关系来提高情感分类准确性。此外,包含上下文语义信息(例如,ngram,从属关系和句法关系以及句子之间的相似度)也将有利于知识提取过程的升级和处理复杂的场景,如,“We went to a Pakistani restaurant and they offered us 5 to 6 choices of cocktails”,例子中,“choices of cocktails” 应被考虑成正面的情感,但是通常会被当作中性的。另一个例子是,“Try the hand ripped bread”,在这里,单词"try"本身并没有情感色彩,但在考虑了正确的上下文后就具备了语义情感。
6.4 Aspect Summarization
aspect summarization是entity-centric以实体为中心的,目标是产生有关特定aspect(entity)及其情感的简短总结。可以通过上线问相关的词、否定词、相似情感词等产生这些总结,但困难是进行改进的个性化摘要,并针对应用中推荐的aspect给出清晰的解释。不过,实际的表示大体上依赖于特定应用的需求。
6.5 Predicting Dynamicity of Sentiment
某些情感的转变因素可能是对“政府信任度”的降低和一些“政治问题”。因此,应该提升社交内容来跟踪用户、群体和多群体级的情感,这有助于理解社交媒体用户的行为和 complex-posting patterns 。主要的模式将对SE进行更详细的分析,并且还将在各个群体之间建立不同的关系,以产生 moreinformative-social contexts. 。多数时候,预测模型可以计算现有用户不断变化的情绪,但要验证新用户对真实数据的影响本身就是一项艰巨的研究任务。
6.6 Multimodal SA
最后,社交媒体上不只是文本数据,还可以包括图片、视频、表情、贴图等,可以根据场景描述用户的行为和态度。因此,通过设计用于提取视觉特征语义的新方法,对这类多媒体数据执行统一将很有趣。这种cross-modal的特征融合有助于从社交媒体上用户产生的内容中实现更综合的aspect分析。此外,还可以采用认知技术,通过模仿机器智能来阅读和学习人类的综合技能和行为。可以具体看下其他研究。
但是,研究人员还应考虑其他问题,例如作者的偏爱,情感(情感特征)分析和计算等。除了必要的元素,ABSA还处理很多其他的挑战,不限于 aspects’ quality and flexibility.比如,Robustness,为了解决用户内容的非正式书写风格(用于表达情感的拼写错误、语法错误、非词典词、俚语词汇,特殊字符、表情等);Scalability 可扩展性,随着问题和系统的增长的效率问题; Learning rate decay 学习率下降,系统的学习时长应当随着时间减少。其他主要问题是过度拟合归约和改进的正则化(相对于预测大型NN)。还有一个是最大池化,对不同的aspect 特征做出预测。最后,当效果变差时应该学着停止。
ABSA领域研究永无止境。
7 CONCLUSION
这个综述研究了NLP领域中一个非常重要的研究领域,ABSA细粒度情感分析,这是情感分析的一个子领域,针对该领域已经有很多出色的研究。本综述对ABSA的最近进展进行了全面的概述,描述了用于定位target位置的最新的深度学习技术,可以是实体,也可以是一个target或entity的一个方面、它们之间的关系以及各自的情感和情感变化。提出了基于问题的方法分类,每种方法都对方面提取、方面情感分析或情感进化问题作出了贡献。还列出了关键的挑战,可以考虑这些挑战来提升细粒度情感分类的表现。
我们的调查可以为希望了解该领域最新进展的研究人员提供基础,并帮助他们制定适用于大多数情况的一般策略。

