
- 1opencv-python车牌识别_opencv车牌识别python
- 2App自动化测试:高级控件交互技巧
- 3【已解决】 linux下提示:pip未找到命令(bash: pip: command not found_-bash: pip: 未找到命令
- 4git使用git reset --hard 版本号 回退版本后并强制提交,找不到所回退版本之前的所有提交记录。_reset --hard 强制提交
- 5基于开源的BPM流程引擎VS天翎自研BPM流程引擎_开源bpm
- 6hadoop无法访问70050(9870)_虚拟机:9870打不开
- 7kafka源码导入idea_kafka 3.4源码导入 idea
- 8hbase常用操作命令_undefined local variable or method `user' for main
- 9Android真机调试 显示端口被占用 杀死进程仍旧无效_android 连接模拟器的时候 端口被占用 杀死端口之后还是不行
- 10KVM虚拟机安装_kvm虚拟机安装csdn
超越Llama3,多模态比肩GPT4V:GLM-4智能体,新一代语言处理利器_智谱ai glm-4和glm-4v
赞
踩
在人工智能领域,自然语言处理技术一直备受关注。就在昨日,今年备受关注的国内AI公司北京智谱AI发布了第四代 GLM 系列开源模型:GLM-4-9B。这是一个集成了先进自然语言处理技术的创新平台,它凭借清华大学KEG实验室提出的GLM模型结构,为智能体功能的发展带来了新的突破的同时所有大模型全部保持开源,一系列商业化成果、技术突破让人眼前一亮。让我们一起揭开GLM-4的神秘面纱,探索其在代码执行、联网浏览、画图等领域的无限可能。
模型介绍
对于将构建 AGI 视为目标的智谱 AI 而言,不断迭代大模型技术能力,同样是重中之重。
自 2020 年 all In 大模型开始,智谱就一直走在人工智能浪潮的前沿。其研究涉及大模型技术的方方面面,从原创的预训练框架 GLM、国产算力适配、通用基座大模型,到语义推理、多模态生成,再到长上下文、视觉理解、Agent 智能体能力等各个方面,智谱都投入了相当多的资源来推动技术的原始创新。
在过去一年里,智谱相继推出了四代通用大模型:2023 年 3 月发布 ChatGLM,6 月推出 ChatGLM2,去年 10 月推出 ChatGLM3;今年 1 月,最新一代基座大模型 GLM-4 正式发布。在 Open Day 上,智谱 AI 向外界介绍了基座大模型 GLM-4 的最新开源成果 ——GLM-4-9B。

它是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。在语义、数学、推理、代码和知识等多方面的数据集测评中, GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能,并首次拥有多模态能力。
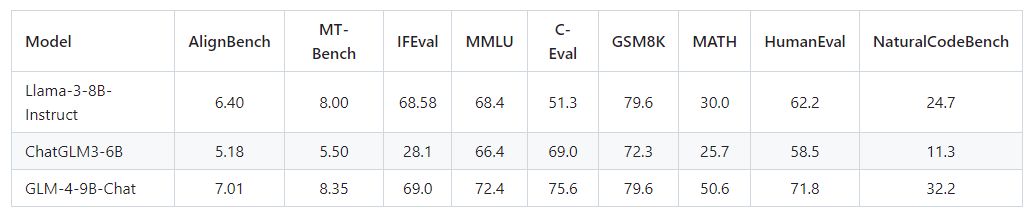
基于强大的预训练基座,GLM-4-9B 的中英文综合性能相比 ChatGLM3-6B 提升了 40%,在中文对齐能力 AlignBench、指令遵从 IFeval、工程代码 Natural Code Bench 等基准数据上都取得了非常显著的提升。对比训练量更大的 Llama 3 8B 也并不逊色,英文方面实现小幅领先,中文学科方面更是有着高达 50% 的提升。
主要功能和特点
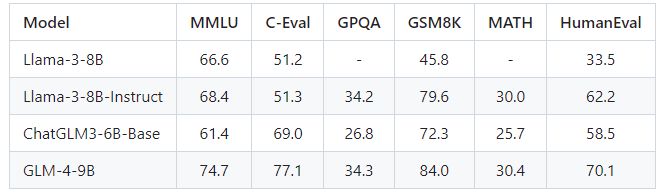
模型性能:在语义、数学、推理、代码和知识等数据集评测中,GLM-4-9B及其对齐版本GLM-4-9B-Chat表现优于Llama-3-8B。
高级功能:GLM-4-9B-Chat支持多轮对话、网页浏览、代码执行、自定义工具调用和长文本推理,最大支持128K上下文长度。
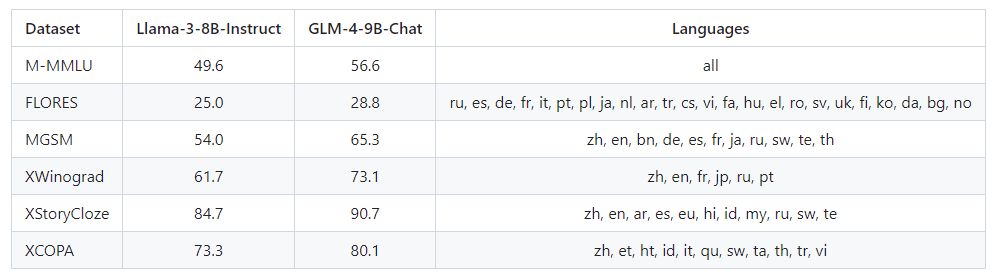
多语言支持:支持包括日语、韩语、德语在内的26种语言。
长文本支持:GLM-4-9B-Chat-1M模型支持1M上下文长度,约200万中文字符。
多模态支持:基于GLM-4-9B的多模态模型GLM-4V-9B,具备1120×1120高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别和图表理解等多方面表现卓越,超越多个现有先进模型。
用户自定义:用户可以根据自己的需求,为GLM-4智能体添加更多功能,打造属于自己的个性化智能体
模型评测结果
对话模型
基座模型
长文本模型
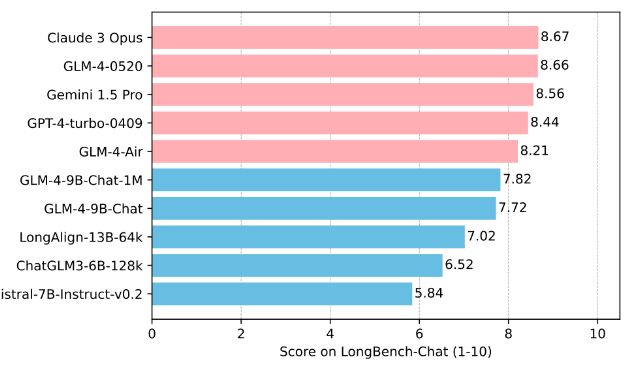
在上下文长度为1M的情况下进行大海捞针实验,结果如下:

在LongBench-Chat上进一步评估长文本能力,结果如下:
多语言
GLM-4-9B-Chat 和 Llama-3-8B-Instruct 的测试在六个多语言数据集上进行。测试结果以及每个数据集选择的对应语言如下表所示:
函数调用
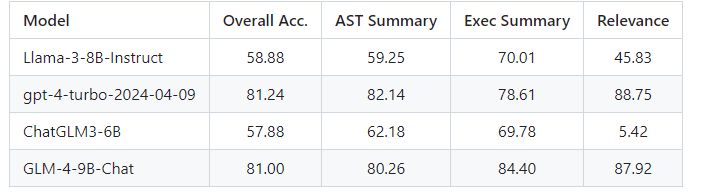
多模态
GLM-4V-9B是一种具有视觉理解能力的多模态语言模型。其相关经典任务的评测结果如下:

由此可见,GLM-4-9B和GLM-4V-9B在多项评测中表现优异,包括对话模型典型任务、基座模型典型任务、长文本能力、多语言能力和工具调用能力。
相关链接
LLaMA-Factory: 高效开源微调框架,已支持 GLM-4-9B-Chat 语言模型微调。
SWIFT: 魔搭社区的大模型/多模态大模型训练框架,已支持 GLM4-9B-Chat/GLM4v-9B-Chat 模型微调。
Xorbits Inference: 性能强大且功能全面的分布式推理框架,轻松一键部署你自己的模型或内置的前沿开源模型。
self-llm: Datawhale 团队的提供的 GLM-4-9B 系列模型使用教程。
高性价比GPU算力:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0620_shemei

