- 1微博情感分析系统:洞察社交网络的细微之处
- 2Unity Metaverse(三)、Protobuf & Socket 实现多人在线_c# protobuf socket 服务端
- 3探索AI人脸识别新境界:CompreFace
- 4配置MDM的描述文件
- 5Hotcoin Research|玩赚WEB3:探索Apeiron:颠覆传统的区块链游戏,融合神话与现代玩法_apeiron链游
- 6开源人脸识别系统compareface介绍
- 7pgAdmin_there is no transaction in progress
- 81、rolableimg标注旋转框的xml文件转dota格式的txt文件;2、如何批量从指定文件夹中根据后缀名提取文件,并存到新文件夹中_rolabelimg转dota
- 9java excel导入和导出(poi,jxl)_java里技术jxl导出excel怎么获取流长度
- 10开发与集成&外包驻场【聚焦:物流供应链AI解决方案】
论文阅读[UIU-Net: U-Net in U-Net for Infrared Small Object Detection]_uiunet
赞
踩
Overview
这篇文章相比于U^2 net没有太大新意,U^2net是用来做salient segmentation的,关注local detail和global semantic information的提取,同样适合Small target detection。本篇文章UiU在U^2上对feature fusion进行了一定的创新,添加了IC-A模块作为注意力机制,增加了U^2Decoder的特征维度。
1.Introduction of the UiUnet
在Decoder中,除了将Encoder中的feature map给skip connection到Encoder中以外,还将Encoder中的Low-level feature map和Decoder中的High-level feature map 一起经过IC-A模块,得到了Cross attention feature,并将Cross attention feature和High-level feature一起送入IC-A得到了Interactive-cross Attention feature。将High-level feature/Cross attention feature/Interactive-cross Attention 这三个特征concatenate起来,一起送入到后续的Residual U-Net中。
2. 为什么要这样设计网络?
因为small target detection任务中的target对比度低,目标小。在深层feature中只剩下全局的semantic information,而浅层的feature中包含local的position/color information。因此整体要设计成U-Net的网络。
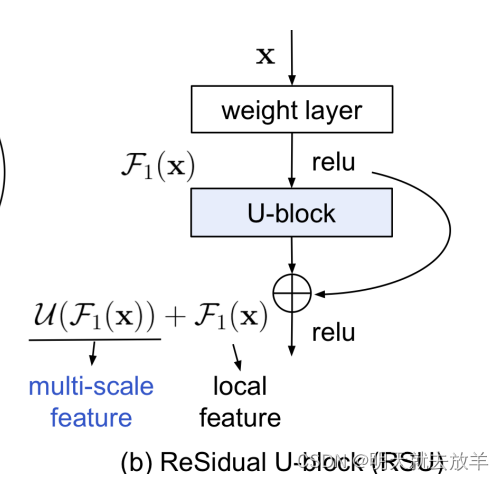
而区别于classic U-Net,每一层中的两次卷积,被替换为了一个Residual U-Net。这样可以更加丰富地在各个尺度上提取信息。
使用Residual,为了能够更好地提取到Multi-scale feature
【也可能是因为网络过深,而训练的数据较少(MSISTD仅有不到500张),为了防止网络退化,所以使用了pixel-wise connection将每一个U-Net变成了Residual-Unet,这样整个UiU再差再差,每一层的Residual学习到的残差函数F(x) = 0。】
3. 和U-2 Net的区别
Article of U-2Net.
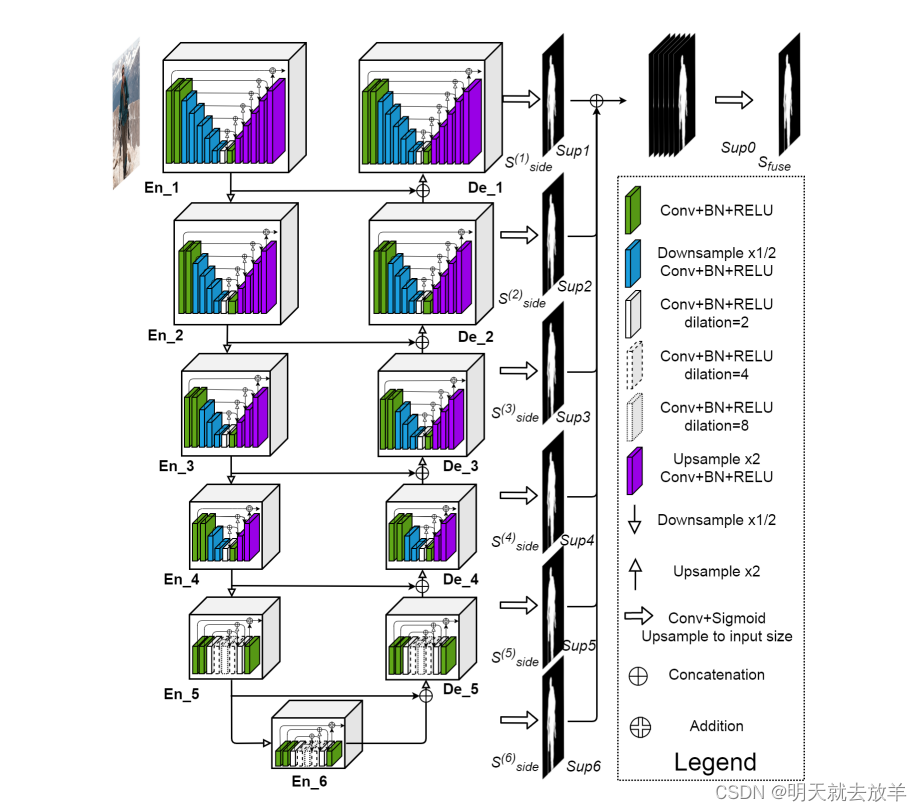
没有太大区别,网络整体设计一致。只不过在U-2 Net中的Encoder和Decoder的feature fusion只是使用了concatenate,但是在UiU中,使用了IC-A模块融合。IC-A模块实质上就是一种混合注意力【但是得到的结果没有直接作为attention来改变feature map的值,而是直接作为feature map拼接到了特征上】,既有channel-wise,又有pixel-wise。
简单介绍一下IC-A module的工作机制:首先看下面这一支,F^h经过全局平均池化后,再经过两次全连接调整得到了channel-wise attention的channel weight,使用这个channel weight来调整F^l的通道权重,经过Conv/Bn/Relu后调整通道维度为c/r,随后在通道维度上进行全局平均池化和全局最大池化,得到两个spatial-wise的注意力权重,相加后经过Conv调整通道为1,经过sigmoid得到spatial-wise的attention map,和F^h进行pixel-wise multiplication,最后经过Conv/Bn/Relu输出。
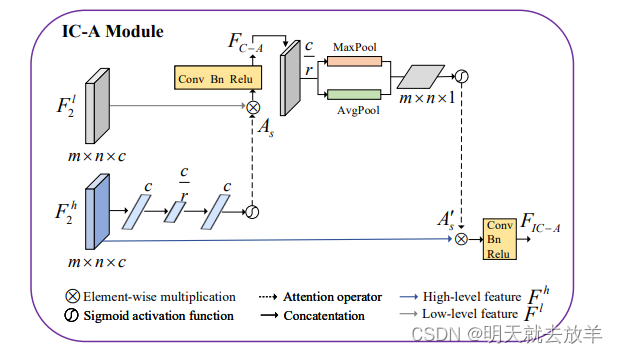
本篇文章的设计如下,并没有在每一层的feature extraction中进行skip connection。