
- 1springCloudAlibaba之分布式网关组件---gateway
- 2初次使用Github_ssh keys associated with your account 创建
- 3Out-of-distribution Detection系列专栏(十)_oodl
- 4网工学习之ARP详解_arp教学
- 5向量数据库入坑指南:初识 Faiss,如何将数据转换为向量(一)_向量库的向量和内容怎么转换
- 6MBTI测试指南:如何在职场中运用你的直觉和情感智慧(包含开源免费的API接口)
- 7CAPL如何在底层模拟TCP Client端断开TCP连接
- 8在FPGA板上用Verilog实现车牌识别_fpga车牌识别
- 9vmware安装android系统_vmware android
- 10毕业设计——基于循环神经网络(LSTM)的社交媒体用户情感倾向分析及检测系统(数据集采用用户电商评论+源码+模型+可视化界面)_lstm神经网络实战项目
在windows下使用本地AI模型提供翻译、对话、文生图服务_ollama 文生图
赞
踩
在windows下使用本地AI模型提供翻译、对话、文生图服务
我的机器配置如下:
处理器:AMD Ryzen 7 8845H w/ Radeon 780M Graphics 3.80 GHz
内存: 32G
GPU: 4060 8G
实测跑8-10G模型只能开一个会话,所以我一般选择跑4G左右的模型。
ollama
简介
官网地址:Ollama
Ollluma全面兼容MacOS、Linux和Windows系统,它提供简洁的一键式本地模型部署流程,并将API功能统一转换至与OpenAI相匹配的标准格式,旨在为您带来无缝且高效的使用体验。
下载
安装
详细安装步骤省略,双击exe程序,即可装好。
安装完之后,最小化图标可以看到ollama,
在浏览器输入地址localhost:11434,即可看到下面输出:
Ollama is running
至此,安装流程已全部顺利完成。
配置
环境变量
OLLAMA_DEBUG Show additional debug information (e.g. OLLAMA_DEBUG=1) OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434) OLLAMA_KEEP_ALIVE The duration that models stay loaded in memory (default "5m") OLLAMA_MAX_LOADED_MODELS Maximum number of loaded models (default 1) OLLAMA_MAX_QUEUE Maximum number of queued requests OLLAMA_MODELS The path to the models directory OLLAMA_NUM_PARALLEL Maximum number of parallel requests (default 1) OLLAMA_NOPRUNE Do not prune model blobs on startup OLLAMA_ORIGINS A comma separated list of allowed origins OLLAMA_TMPDIR Location for temporary files OLLAMA_FLASH_ATTENTION Enabled flash attention OLLAMA_LLM_LIBRARY Set LLM library to bypass autodetection OLLAMA_MAX_VRAM Maximum VRAM OLLAMA_DEBUG 显示额外的调试信息(例如:OLLAMA_DEBUG=1) OLLAMA_HOST ollama服务器的IP地址(默认 127.0.0.1:11434) OLLAMA_KEEP_ALIVE 模型在内存中加载的持续时间(默认 "5m") OLLAMA_MAX_LOADED_MODELS 加载的最大模型数量(默认为1) OLLAMA_MAX_QUEUE 队列中的最大请求数 OLLAMA_MODELS 模型目录的路径 OLLAMA_NUM_PARALLEL 并行请求的最大数量(默认为1) OLLAMA_NOPRUNE 不在启动时清除模型块 OLLAMA_ORIGINS 允许源头的逗号分隔列表 OLLAMA_TMPDIR 临时文件的位置 OLLAMA_FLASH_ATTENTION 启用闪速注意力 OLLAMA_LLM_LIBRARY 设置LLM库以绕过自动检测 OLLAMA_MAX_VRAM 最大VRAM

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
模型安装目录
默认是会安装到C盘,但是模型一般都很大,所以我选择安装到其他盘,只需要设置OLLAMA_MODELS变量为你想要安装的目录即可。
服务监听地址
默认是监听localhost:1143,如果需要局域网其他设备访问可以设置OLLAMA_HOST为0.0.0.0,如果需要更改默认端口,可以设置为0.0.0.0:12345。
跨域配置
如果有一些特殊需求,例如想让浏览器插件可以访问本地的ollama,正常操作时会报跨域错误,所以需要设置OLLAMA_ORIGINS为*
我的配置
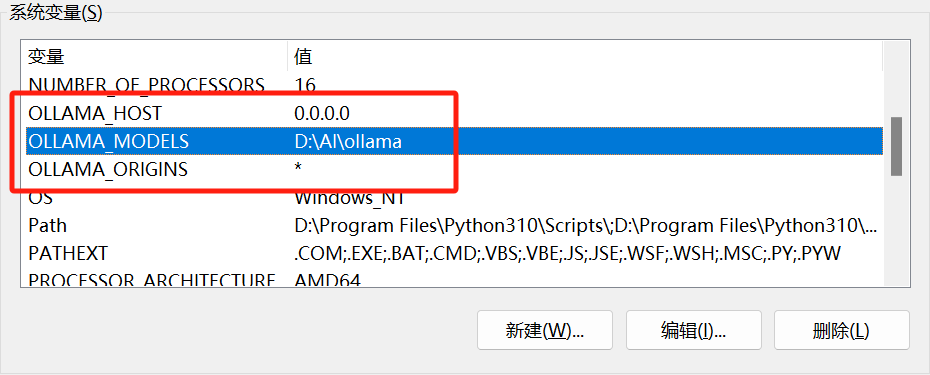
ollama提供了很多配置项,按需配置即可。
注意事项
设置完环境变量后需要重启ollama服务,才会生效。
可以在最小化右键ollama图标,点击选择退出,然后在开始菜单中找到ollama,双击运行。
开机自启
把ollama设置为开机自启,这样每次开机时就不需要手动运行ollama了,做到无感使用。
使用
打开cmd,输入ollama -h即可看到下面帮助信息。
ollama -h Large language model runner Usage: ollama [flags] ollama [command] Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model pull Pull a model from a registry push Push a model to a registry list List models ps List running models cp Copy a model rm Remove a model help Help about any command Flags: -h, --help help for ollama -v, --version Show version information Use "ollama [command] --help" for more information about a command. 大型语言模型运行工具 使用方法: ollama [标志] ollama [命令] 可选命令列表: serve 启动 ollama create 根据 Modelfile 创建模型 show 展示模型信息 run 运行模型 pull 从注册表下载模型 push 将模型推送到注册表 list 列出所有模型 ps 列出正在运行的模型 cp 复制模型 rm 删除模型 help 获取任何命令的帮助信息 对于每个命令获取更多信息,请使用 "ollama [command] --help"。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
可能每个版本支持的环境变量不一样,所以可以输入ollama serve -h查看帮助信息。
ollama serve -h Start ollama Usage: ollama serve [flags] Aliases: serve, start Flags: -h, --help help for serve Environment Variables: OLLAMA_DEBUG Show additional debug information (e.g. OLLAMA_DEBUG=1) OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434) OLLAMA_KEEP_ALIVE The duration that models stay loaded in memory (default "5m") OLLAMA_MAX_LOADED_MODELS Maximum number of loaded models (default 1) OLLAMA_MAX_QUEUE Maximum number of queued requests OLLAMA_MODELS The path to the models directory OLLAMA_NUM_PARALLEL Maximum number of parallel requests (default 1) OLLAMA_NOPRUNE Do not prune model blobs on startup OLLAMA_ORIGINS A comma separated list of allowed origins OLLAMA_TMPDIR Location for temporary files OLLAMA_FLASH_ATTENTION Enabled flash attention OLLAMA_LLM_LIBRARY Set LLM library to bypass autodetection OLLAMA_MAX_VRAM Maximum VRAM 启动 ollama 使用方法: ollama serve [标志] 别名: serve, start 标志: -h, --help 获取关于 serve 命令的帮助信息 环境变量: OLLAMA_DEBUG 显示额外的调试信息(例如,设置 OLLAMA_DEBUG=1) OLLAMA_HOST ollama服务器使用的IP地址(默认为127.0.0.1:11434) OLLAMA_KEEP_ALIVE 模型在内存中加载后的保留时长(默认为"5分钟") OLLAMA_MAX_LOADED_MODELS 最多可以加载的模型数量(默认为1个) OLLAMA_MAX_QUEUE 接收请求的最大队列数 OLLAMA_MODELS 模型目录的位置 OLLAMA_NUM_PARALLEL 并发处理请求的最大数量(默认为1) OLLAMA_NOPRUNE 在启动时不清理模型快照 OLLAMA_ORIGINS 允许的源地址列表,以逗号分隔 OLLAMA_TMPDIR 临时文件的位置 OLLAMA_FLASH_ATTENTION 启用闪速注意力 OLLAMA_LLM_LIBRARY 设置 LLM 库以绕过自动检测(需提供具体库名) OLLAMA_MAX_VRAM 最大VRAM使用量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
运行模型
这里以qwen2模型为例,演示如何使用ollama运行模型。执行命令ollama run qwen2:7b,如果本地有模型则会直接启动一个会话,如果本地没有模型,则会自动去服务器下载模型,如果模型有更新,也会自动更新。
注:ollama有个优点就是可以裸网络全速下载,不需要科学。不像LM-Studio,不用魔法下载不了模型。

对话测试:

对话时的命令
/? Available Commands: /set Set session variables /show Show model information /load <model> Load a session or model /save <model> Save your current session /clear Clear session context /bye Exit /?, /help Help for a command /? shortcuts Help for keyboard shortcuts Use """ to begin a multi-line message. 可选命令如下: /set:用于设置会话变量。 /show:展示模型信息。 /load <model>:加载一个会话或模型,其中 <model> 需要替换为具体的模型名称或ID。 /save <model>:保存当前的会话至指定模型。同样, <model> 应该被替换成你想要命名的新模型名称。 /clear:清除会话上下文,使得所有变量和状态都归于初始状态。 /bye 或 /exit:用于退出程序或系统环境。 /? 或 /help:提供对于某一命令的帮助信息。 /? shortcuts: 帮助你了解可用的键盘快捷键。 请使用引号 """ 来开始和结束多行消息,以便于命令解析。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
最常用的就是/bye退出会话了。
查看本地已安装模型
ollama list
NAME ID SIZE MODIFIED
qwen2:7b e0d4e1163c58 4.4 GB 6 hours ago
aya:latest 7ef8c4942023 4.8 GB 7 days ago
openchat:latest 537a4e03b649 4.1 GB 12 days ago
llama3:latest 365c0bd3c000 4.7 GB 12 days ago
- 1
- 2
- 3
- 4
- 5
- 6
删除模型
ollama rm llama3
deleted 'llama3'
- 1
- 2
查看ollama支持的模型
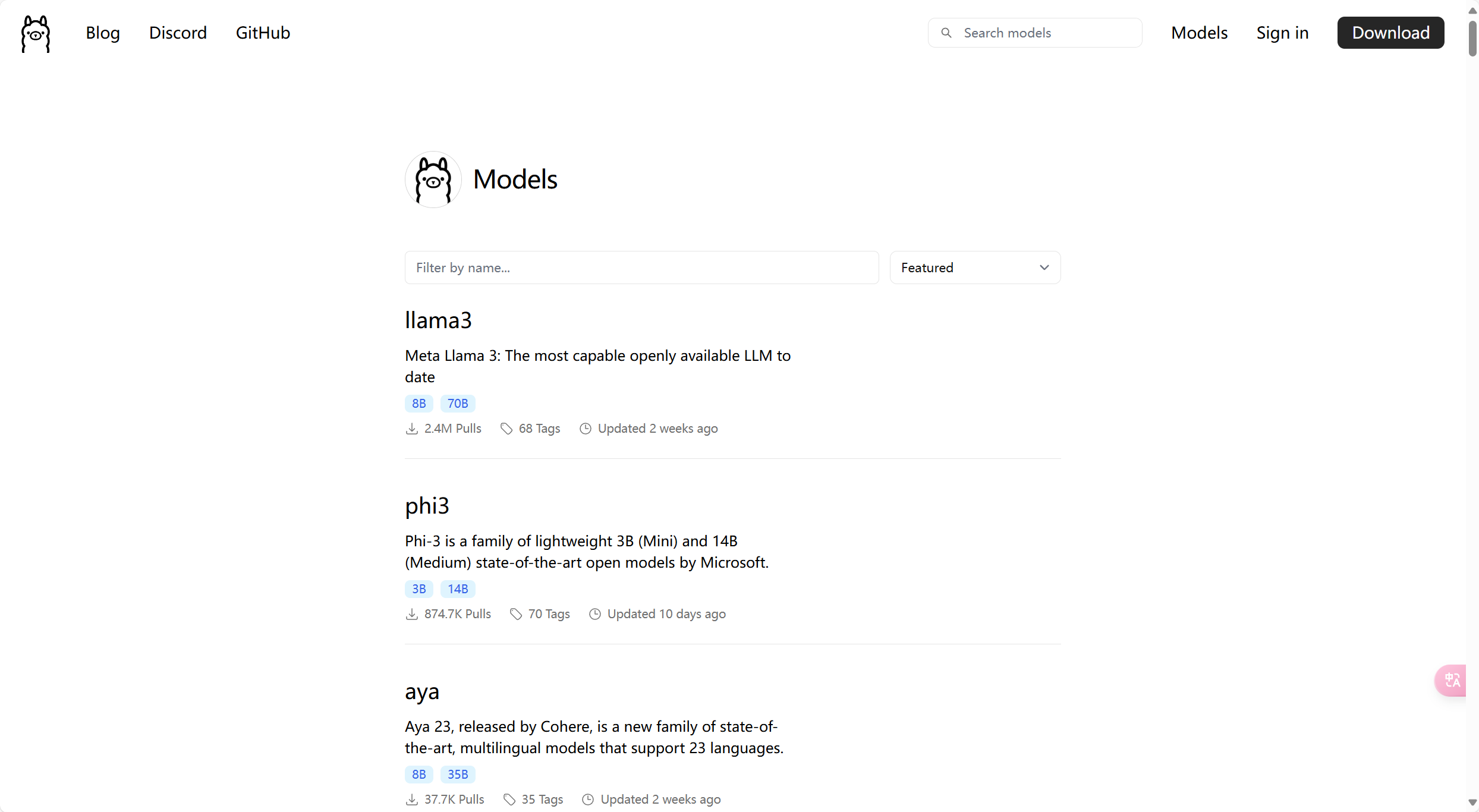
这里以qwen2为例,讲解一些注意事项。
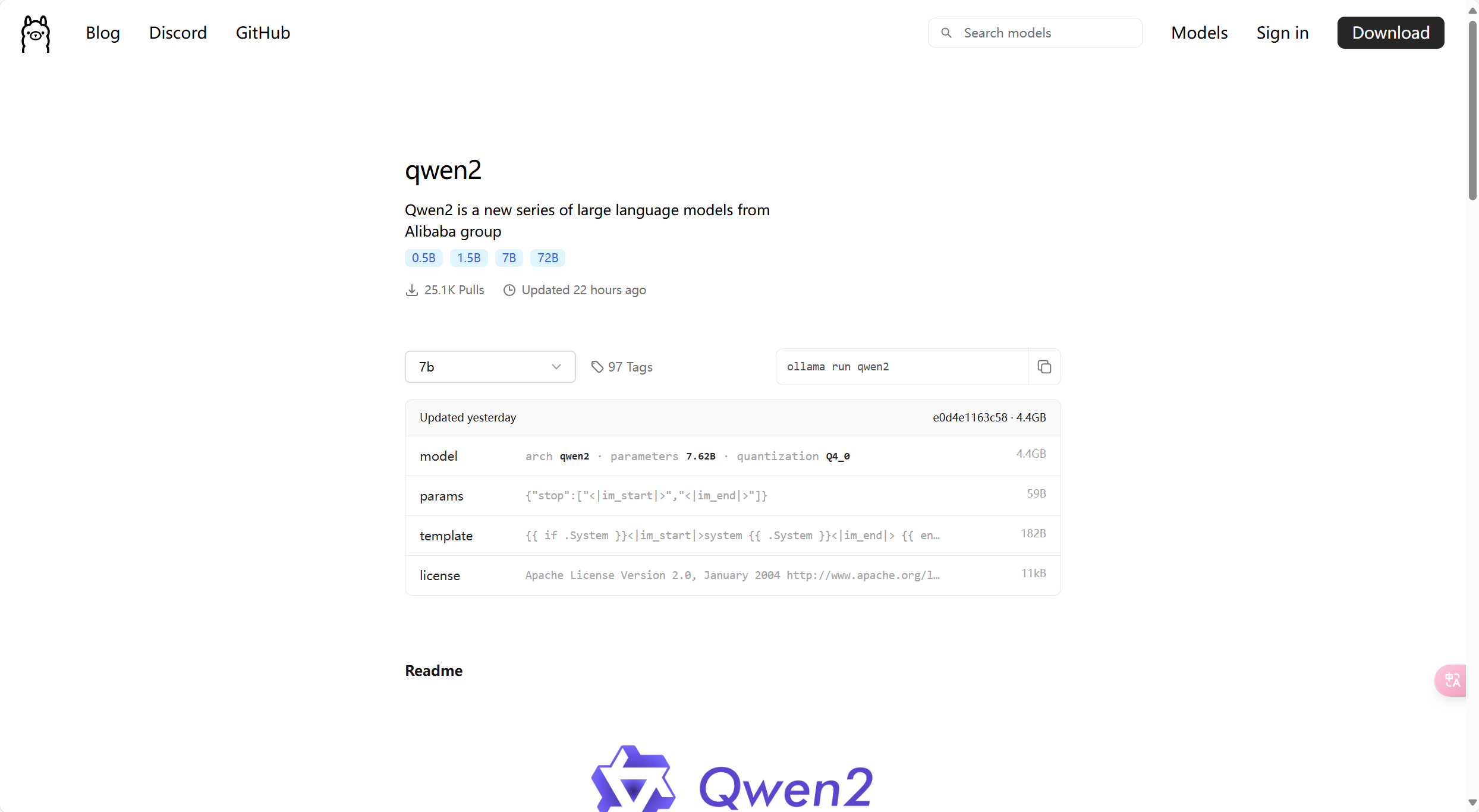
下面readme有一些模型的介绍。

模型一般会有多个tag,就类似于github上面有多个分支一样。
同一个模型首先会按参数数量分,如72b、7b、1.5b、0.5b,参数越多的模型越大,需要的算力也就越大。
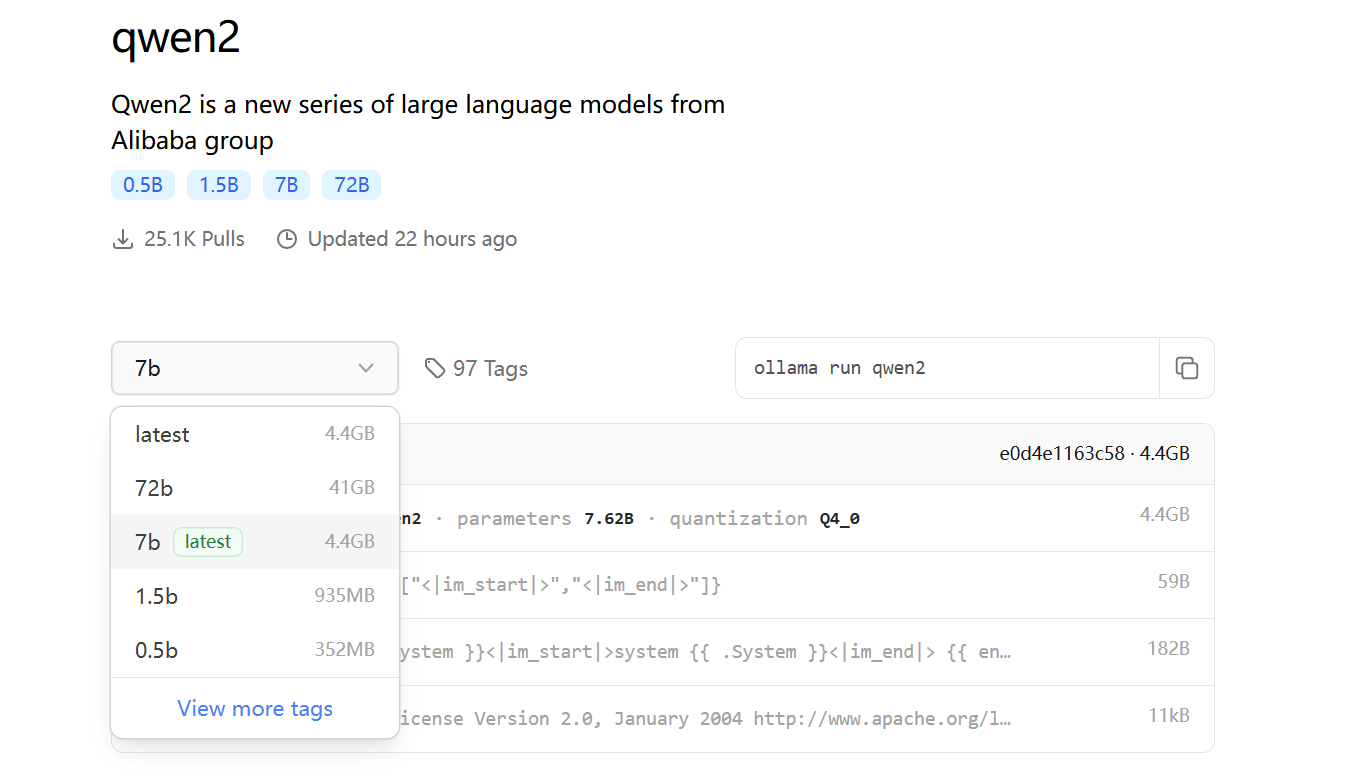
所以给ollama run qwen2启动的时候可以指定模型tag,例如ollama run qwen2:7b。
选择tag后,右上角会出现运行的命令,直接copy去运行就行了。
Docker Desktop
简介
官网地址:Docker Desktop
Docker Desktop 是一个由 Docker Inc. 开发的桌面应用软件,用于在 Windows、macOS 和 Linux 操作系统上运行本地容器。它提供了一种简单且易于使用的界面来启动和管理 Docker 容器,并提供了对一些常用工具(如 Kubernetes)的支持。
注:这个就需要魔法才能稳定访问。
现在有非常多比较优秀的项目支持openai,所以理论上支持openai的项目就支持ollama。
开源项目一般都会提供docker镜像来简化部署,所以我们就使用docker来跑相关项目。
下载
安装
安装之前需要开启windows对WSL的支持,如果版本过低,需要手动升级到WSL2。
WSL2弄好后,就可以安装docker desktop程序了。
安装完后点击运行启动引擎,它会创建两个WSL虚拟机。
配置
docker desktop使用WSL2运行容器,它自己本身就是两个wsl虚拟机。
wsl --list
适用于 Linux 的 Windows 子系统分发:
docker-desktop(默认)
docker-desktop-data
- 1
- 2
- 3
- 4
这个虚拟机默认也是在C盘,因为docker 镜像一般也比较大,所以需要放到其他盘去。
需要先退出docker desktop软件。
导出这两个虚拟机:
wsl --export docker-desktop D:\AI\docker-desktop.tar
wsl --export docker-desktop-data D:\AI\docker-desktop-data.tar
- 1
- 2
删除两个虚拟机:
wsl --unregister docker-desktop
wsl --unregister docker-desktop-data
- 1
- 2
导入虚拟机到其他盘:
wsl --import docker-desktop D:\AI\dockerdesktop D:\AI\docker-desktop.tar --version 2
wsl --import docker-desktop-data D:\AI\dockedesktopdata D:\AI\docker-desktop-data.tar --version 2
- 1
- 2
到此就完成了迁移了。
开机自启
设置开启自启,这样可以无感使用本地AI。
Open WebUI
简介
官网:Open WebUI
帮助文档:
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

