
- 1Yaralyzer:一款功能强大的YARA与正则式检查解析工具
- 2华为OD机试 - 分披萨 - 递归(Java 2024 D卷 200分)_华为od 分披萨
- 3生物大分子平台(11)_为什么bert的训练集要标注
- 4玩客云刷armbian安装zoneminder_zoneminder安装教程
- 5关于重装电脑碰到的BUG及其修复教程_verification failed:(0x1a)
- 6网络安全相关竞赛比赛_网鼎杯网络安全大赛2024
- 7LeetCode刷题---707. 设计链表(双向链表-带头尾双结点)_leetcode707 双链表
- 8AI产品经理必备:AI和大模型的区别_ai和大模型的区别是什么
- 9Flutter开发学习过程_intitle:flutter的学习过程
- 10MDPI、Wiley和Frontiers持续爆雷!继多本期刊被列入“掠夺性期刊”黑名单后,又惨遭“降级”!
中文分词_SOTA 中文分词介绍
赞
踩

首先给大家分享一个github站点,https://github.com/sebastianruder/NLP-progress, 这里记录了很多自然语言处理任务当前最好的方法。
今天给大家分享的文章是《Toward Fast and Accurate Neural Chinese Word Segmentation with Multi-Criteria Learning》,这篇文章在中文分词任务10个数据集上都取得了最好的结果。
模型结构
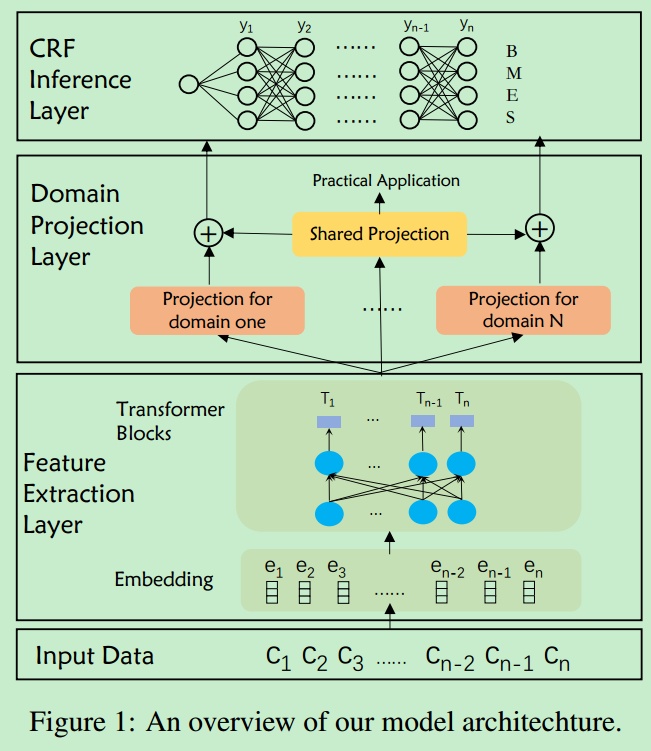
首先用Bert进行Feature Extraction, 然后进行Domain Project,然后用CRF预测输出标签, 标签集为{B, M, E, S}。
Domain Project:
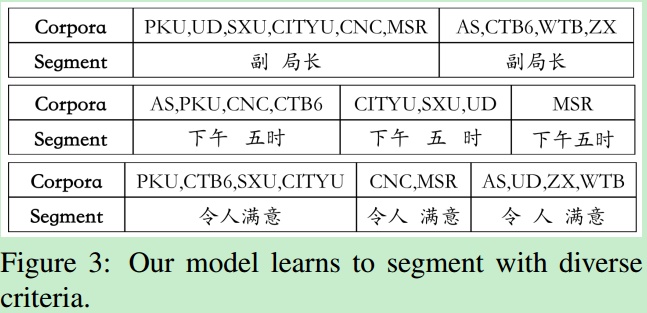
不同数据集有不同的分词粒度。比如副局长,下午五时,令人满意在不同的数据集上,分词标注也不相同。
Domain Project用来捕获每个数据集的特定的分词标准。
投影层可以有很多的选择,作者使用的(简单且有效)的线性变换。同时,用一个额外的共享投影层用来学习不同数据集的公共知识。
由于分词是一项基本任务,要求该任务快且准确。
作者使用了三种提高速度的方法。分别是
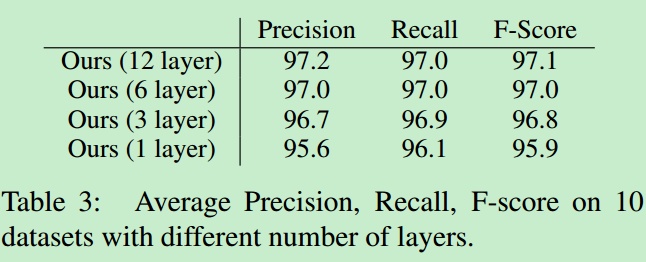
Pruning:bert中文有12层,作者通过减少层数来提高速度。层数减少F-Score没有的明显降低。
Quantization:kernels of multi-head attention layers and feedforward layers use half precision (FP16) rather than full precision (FP32)。也就是将权重的参数类型设置为float16而不是float32.
Compiler Optimization:使用XLA编译器。XLA is a domain specific compiler for linear algebra that optimizes TensorFlow computations.
下图是优化后的速度对比。
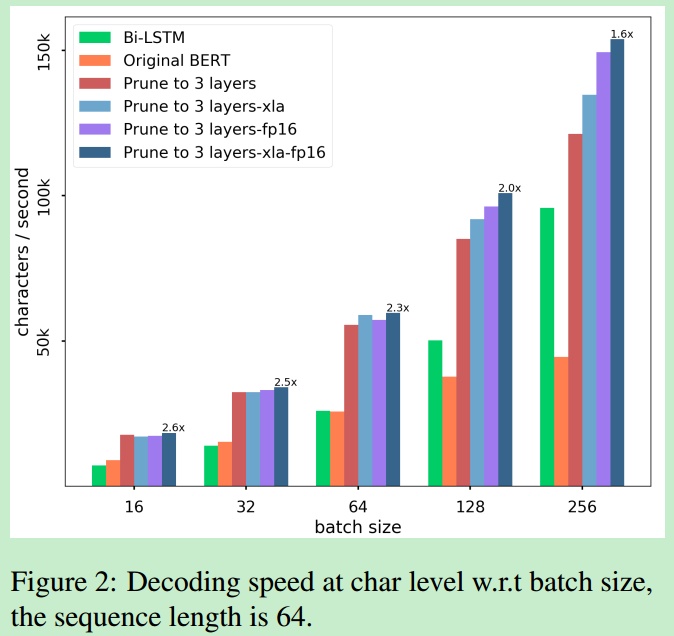
结果:
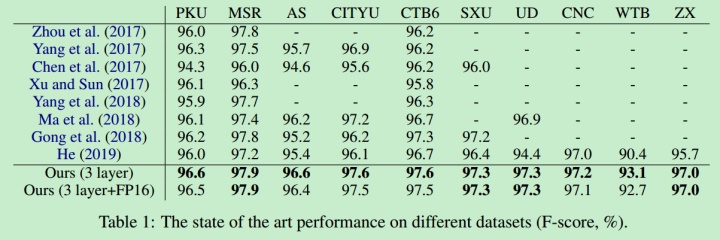
在十个中文分词数据集上都取得了最好的结果。
另外利用多个数据集提高了OOV的召回率。

作者在附录中提出我们真的需要12 层transformer来进行中文分词吗?
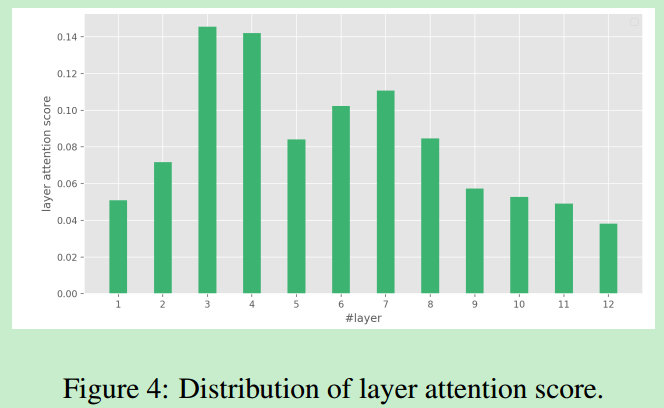
作者实验发现分词模型对不同层的attention score 是不一样的。其中第3层最高,说明第3层包含最多的分词信息。从7层到12层注意力得分逐渐下降,说明对于分词任务,高层学习的语义特征可能对分词影响较小。
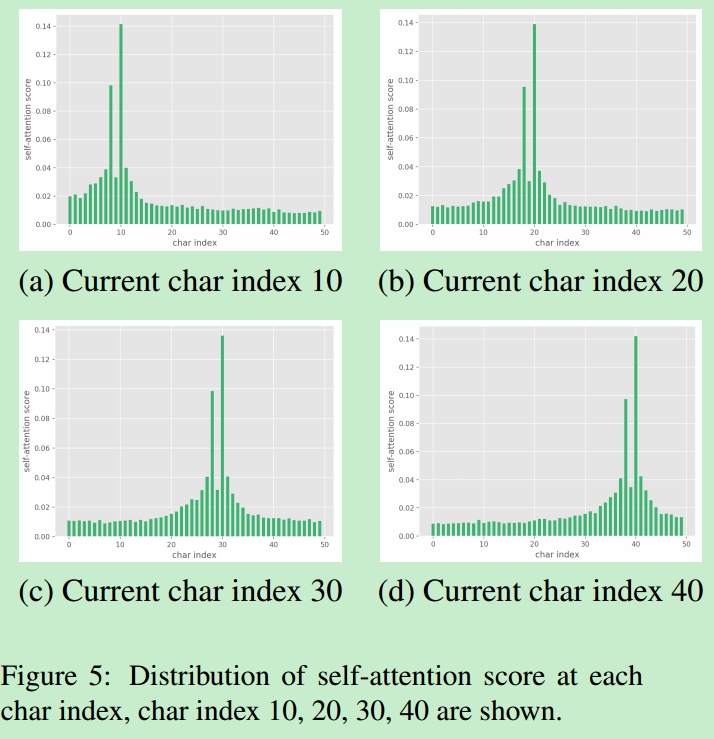
作者实验还发现,跟长距离的字符相比,当前字符周围的字符会有较大的权重,说明分词更多地依赖于语法,长程依赖性相对不重要。可能自注意限制到固定窗口大小可以用来减少计算和模型加速。

