
热门标签
热门文章
- 1java必学8大排序_排序必java
- 2三天让车跑起来!stm32寻迹车——第三天:如何让车跑得更好?_stm32智能小车 米字格绿色拐弯
- 3OpenCV与AI深度学习 | 如何使用YOLOv9检测图片和视频中的目标_ai视频分析 yolo
- 4Unity-Flutter(UIWidgets)萌新入门学习记录--Hello Word_unity中运行flutter
- 5Vue核心 — Vue2响应式原理和核心源码解析(核心中的核心)_vue2 源码响应是
- 6python俄罗斯方块游戏代码_pygame俄罗斯方块代码
- 7SequoiaDB集群部署简易步骤_sequoiadb配置集群
- 8自然语言处理(NLP)——前馈网络_前馈网络什么意思
- 9我用wxPython搭建GUI量化系统之多只股票走势对比界面_股票量化实践 网盘
- 10Java--Mybatis万字长文经典面试题王者笔记《收藏版》_java 什么插件可以自动生成insert语句
当前位置: article > 正文
声音生成项目(4)——从VariantAutoencoder(VAE)到VQ-VAE矢量量化变分编码器_vqvae 嵌入矢量的变化
作者:秋刀鱼在做梦 | 2024-07-18 10:12:14
赞
踩
vqvae 嵌入矢量的变化
论文介绍
- 不同于变分编码器和自动编码器,vq-vae中的latent space是离散的,并不是连续的,这能够避免后验塌陷。除此之外,vq-vae中的先验概率分布并不是静态的,是可以通过训练进行学习的。
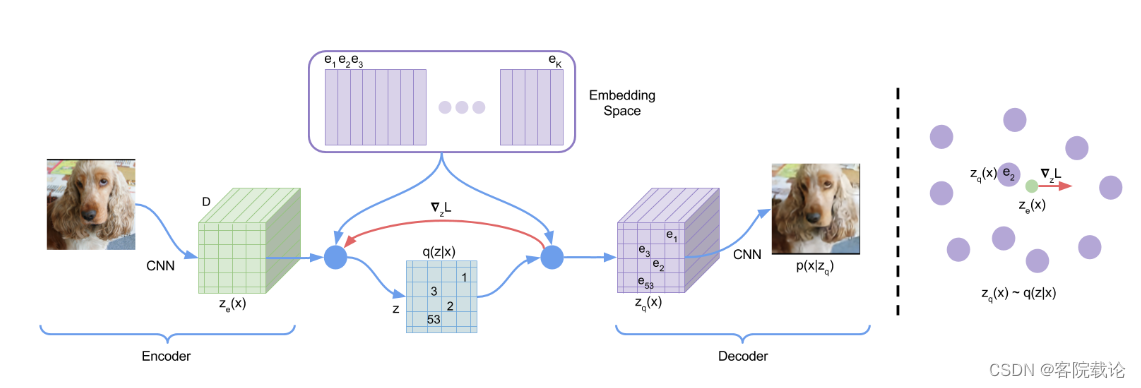
- 编码器是使用卷积网络生成对应的特征,然后计算欧式距离,将是映射到离散的码本中
- 解码器是根据最近的码字索引抽取对应的码本中的编码,并且使用这个码进行数据生成。这个就不用与自编码器中的latent space是一个连续的空间。
- 前向很简单,但是反向传播就很苦难,因为在正向过程中,获取最近码字的过程,是不可导的。可以使用straight-through estimator因为编码器和解码器的大小是相同的。通过复制梯度,调整对应的编码向量的方向,实现编码器的输出不断向最近的编码靠近。
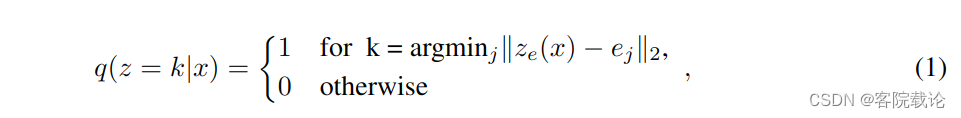
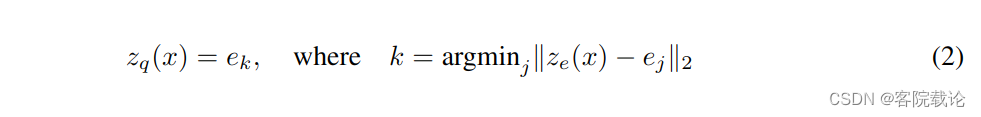
- 这里是实现将ze编码器的输出,找到最近的一个码本中的码字进行映射,然后保留对应的索引。
- 因为对于等式2是没有真实梯度的,而且该等式是不可导的,所以我们通过straght-through estimator近似梯度,简单来说就是使用解码器的输入梯度,复制给编码器的输出梯度。
- 因为编码器的输出和解码器的输入是具有相同的尺寸的,所以解码器的梯度信息对于编码器而言也是有用的,可以让编码器了解如何改变输出,才能降低重建损失。
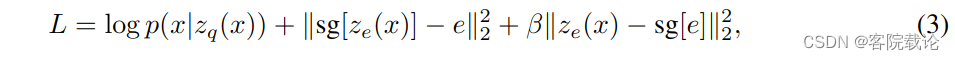
- 上述图片为损失函数的构成,分别是三个部分
- 第一个部分是重建损失函数,保证重建之后和原来的之间的差异,解码器和编码器都会优化 这部分损失函数。
- 第二部分是优化码本中的编码embedding ,是码本中码字不断向输入进行靠拢。学习embeddings.
- 第三部分是优化编码器输出,向码本中的码进行逼近的损失函数。调整编码器的输出。
步骤具体讲解
自定义矢量量化层
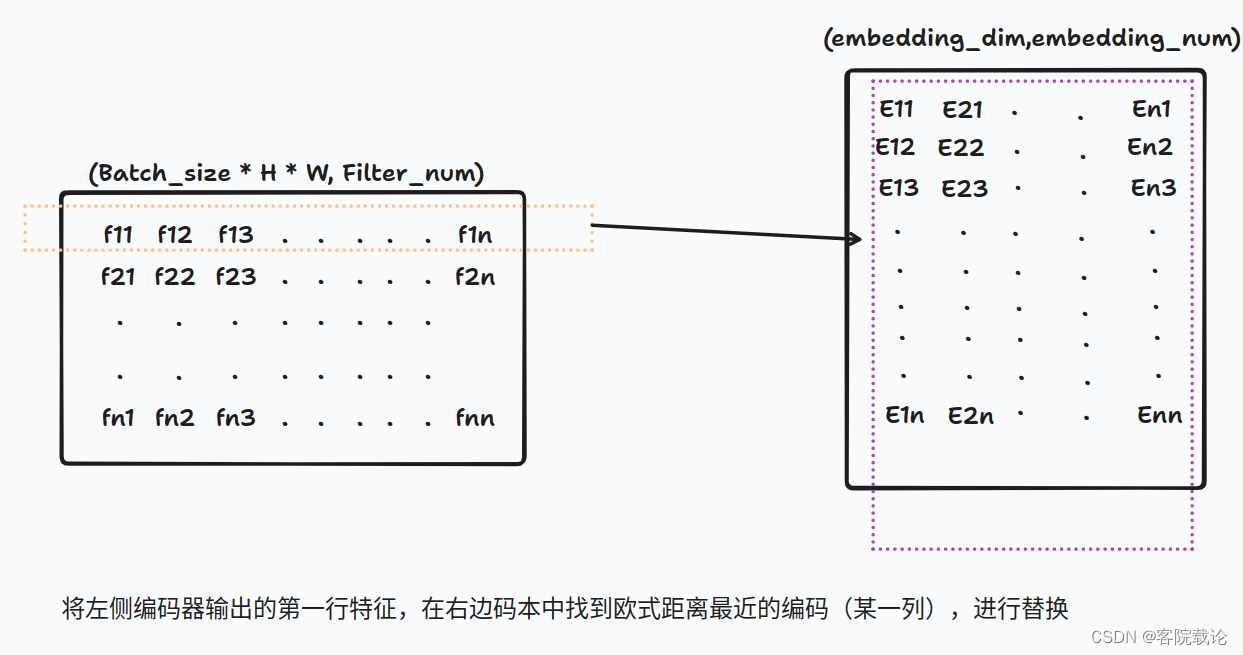 * 左边矩阵是编码器的输出,进行reshape之后的一个二维矩阵,每一行表示一个特征编码,然后在右边码本中找到欧式距离最近的一列特征进行替换映射。替换如下,每一行的f特征,换成了码本中对应E码字,这是最终结果,中间省略了很多计算过程。
* 左边矩阵是编码器的输出,进行reshape之后的一个二维矩阵,每一行表示一个特征编码,然后在右边码本中找到欧式距离最近的一列特征进行替换映射。替换如下,每一行的f特征,换成了码本中对应E码字,这是最终结果,中间省略了很多计算过程。

具体计算过程如下
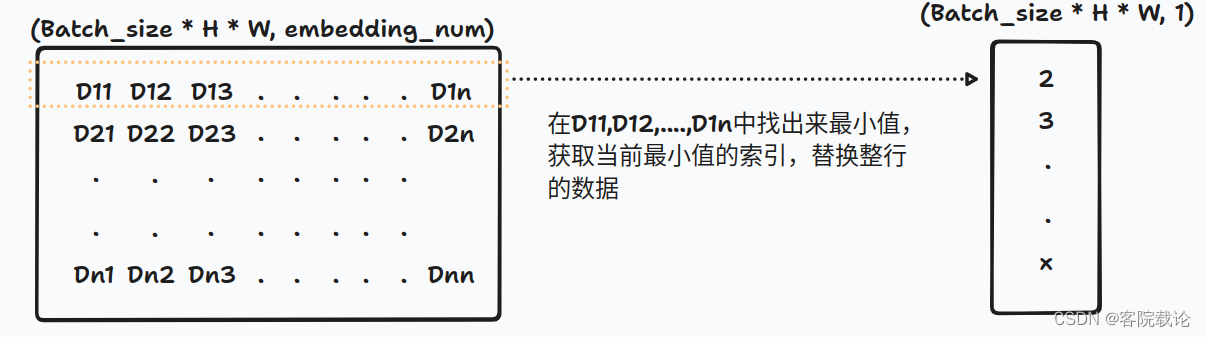
- 首先计算一行特征到码字中各个码字的距离,形成一个新的向量,每一个位置,表示对应行的特征到对应列的向量之间的码字距离。

- 选取每一行最小值,并记录对应的索引,生成一个新的矩阵,记录的是每一行最小值对应的索引。
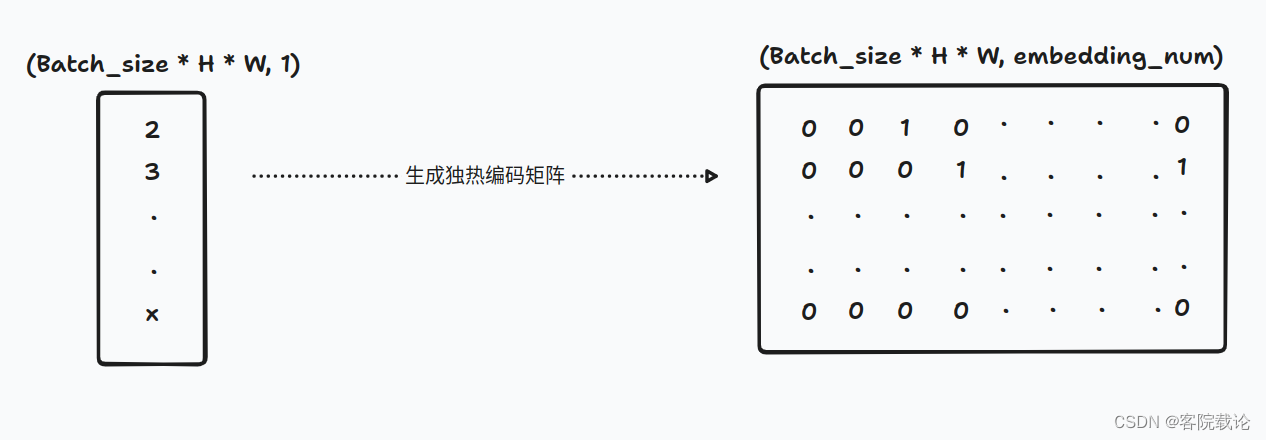
- 根据索引,生成对应的独热编码矩阵,根据索引形成对应的矩阵。原来获取最近的索引的时候,就是在所有的码本中找最近的码进行计算的,所以这里生成对应同宽度的独热编码矩阵。和原来的码本进行相乘,获得结果就是对应最近的码字
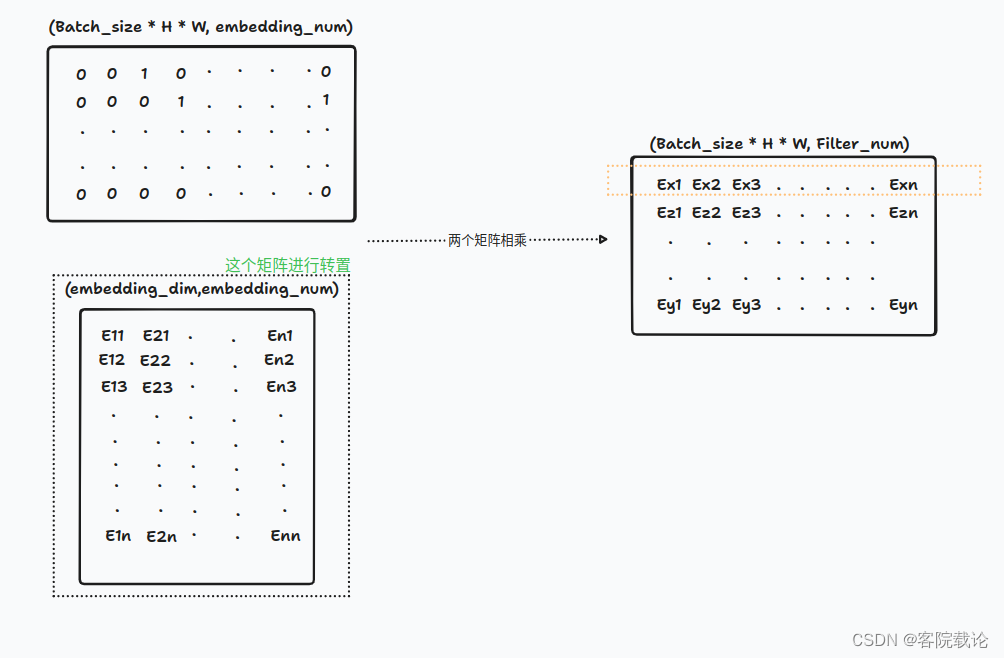
- 直接和对应的码本进行相乘,获取最近的码字。
获取最近距离的码字的索引计算推导
- 这里是距离计算的具体方式,对于两个1x3的向量,对于更加复杂维度,计算的方式也相同,这里结合具体的代码来看一下
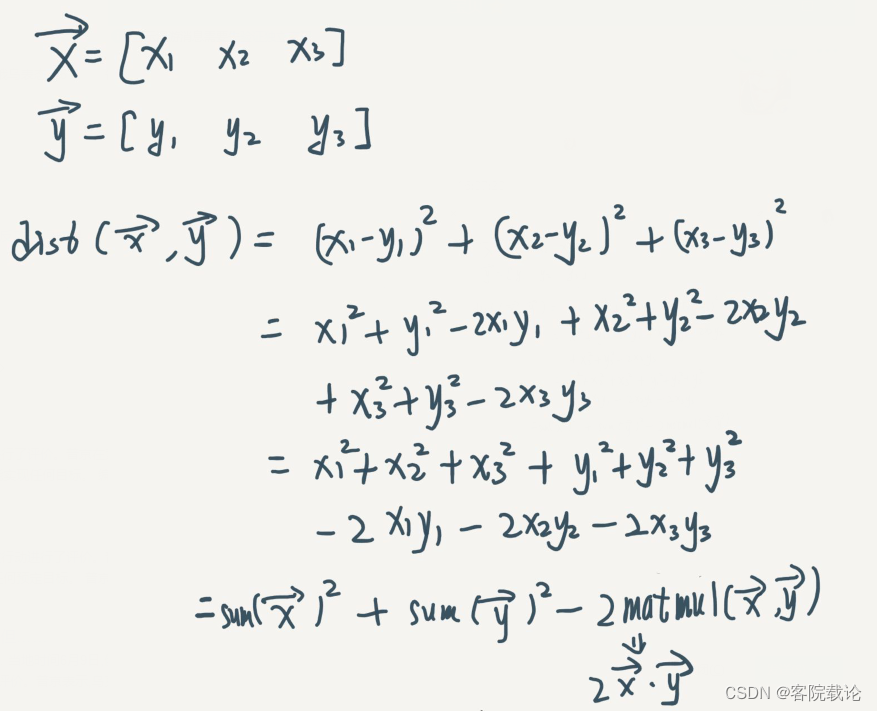
- 计算两个矩阵的相乘,就是上图中的xy
similarity = tf.matmul(falttened_input,self.embeddings)
- 1
- 计算两个两个矩阵的平方和,对于第一个矩阵而言,每一列是一个特征向量,对于第二个矩阵而言,每一行是个向量,是计算这两个向量的平方和。
distances = (
tf.reduce_sum(falttened_input**2,axis=1,keepdims=True)
+ tf.reduce_sum(self.embeddings ** 2,axis=0)
- 2 * similarity
)
- 1
- 2
- 3
- 4
- 5
- 选出最近的索引
# 获取最小距离的索引,最终返回的是每一个样本在对应行中最小值,返回的是一个(Batch_size*H*W,1)的数组,
# 每一行的特征对应最小的码的索引
encoding_indices = tf.argmin(distances,axis=1)
- 1
- 2
- 3
- 具体的矩阵的形状的变化,见上一个个章节的内容。

损失函数
-
损失函数主要由里那个部分构成,分别是量化损失(commitment loss)和码本损失(codebook loss)
-
量化损失
- 衡量量化之前的原始输入和量化之后的输出的差异
- 通过计算原始输入和停止梯度的量化输出之间的均方差来衡量
- 使模型学习将输入的数据映射到码本中最接近的向量,是控制输入x的,所以不需要对码本进行梯度调整。
-
码本损失
- 衡量量化输出和原始输入之间的反向重构误差
- 通过计算量化输出和停止梯度的原始输入之间的方差衡量。
- 使模型学习将量化输出映射回原始输入空间,是控制码本的梯度,所以不需要改变输入x的参数
-
最终的损失函数‘
- 两部分的损失进行加权想家,权重有 β \beta β进行控制
- 使用stop_gradient是为了控制损失函数对于解码器输出的影响,保证解码器能够正确反量化码本向量,不受梯度的干扰。
-
具体实现代码,说实话,这部分理解的不够透彻
# 计算矢量化的损失,并且将之加到当前层上,
# reduce_mean:计算张量指定维度上的平均值
# tf.stop_gradient:不计算输入变量的梯度
commitment_loss = tf.reduce_mean((tf.stop_gradient(quantized) - x ) ** 2)
codebook_loss = tf.reduce_mean((quantized - tf.stop_gradient(x) ) ** 2)
self.add_loss(self.beta * commitment_loss + codebook_loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 最终的输出,总的前向传播中,码本是离散的,无法求导,需要直接将梯度传到输入续
# straight-through estimator:直接将参数的梯度作为对应浮点型参数的梯度
# 直接使用激活函数之后的梯度,代替之前的梯度
quantized = x + tf.stop_gradient(quantized - x )
- 1
- 2
- 3
相关参考
Straight——through Estimator的解释
stop_gradient的解释
矢量量化层的代码实现
from tensorflow.keras import Model # 一般进行版本更新都是改变的包的导向,或者改变包的方法名 from tensorflow.keras.layers import Input,Conv2D,ReLU,BatchNormalization,Flatten,Dense,\ Reshape,Conv2DTranspose,Activation,Lambda from tensorflow.keras import layers,metrics # 引入backend,这个用来自己定义层,将一些函数定义成特定的层 from tensorflow.keras import backend as K # 导入numpy,对三维数据进行操作 import numpy as np # 导入对应优化器,注意,这里已经改变了包的地址 from tensorflow.keras.optimizers.legacy import Adam # 导入损失函数 from tensorflow.keras.losses import MeanSquaredError # 导入系统模块 import os # 序列加载模块 import pickle import tensorflow as tf tf.compat.v1.disable_eager_execution() # 自定义层,自定义矢量量化层 # 这是在编码器和解码器之间自定义的一个层。 # 输入为编码器的输出,形状是(batch_size, height, width,num_filters) # 矢量量化器将会输入进行flatten,仅仅保证过滤核filter的尺寸不变, # 最终的尺寸是batch_size * height * width,num_filters) # 作用:将滤波器的总数当作是潜在embedding的大小 # 然后embedding 表格是被初始化,用来学习码本code book # 我们我们通过计算展平之后的编码器输出和码本码字的欧式距离 # 我们选择距离最小的码字,然后应用独热编码实现量化效果,借此实现了码字和相应距离最近的编码器输出作为关联 # # 因为矢量量化是不可导的,所以直接用解码器的梯度作为编码器的梯度 # # class VectorQuantizer(layers.Layer): def __init__(self,num_embeddings,embedding_dim,beta=0.25,**kwargs): ''' 确定矢量量化的码字尺寸, :param num_embeddings:batch_size * height * width :param embedding_dim:num_filters :param beta:beta参数设置为0.25 :param kwargs: ''' super().__init__(**kwargs) self.embedding_dim = embedding_dim self.num_embedding = num_embeddings self.beta = beta # 初始化将要量化的embedding # 生成具有均匀分布的张量的初始化器 w_init = tf.random_uniform_initializer() # 定义tensorflow中的图片变量并且命名为embedding_vqvae self.embeddings = tf.Variable( initial_value=w_init( shape = (self.embedding_dim,self.num_embedding), dtype = "float32" ), trainable=True, name = "embeddings_vqvae", ) def cal(self,x): """ 步骤: 1、将input进行flatten,仅仅保留embedding_dim这一个维度 2、使用独热编码对embedding进行量化 3、将量化的值,还原回原来的输入形状 4、计算量化层的损失函数 5、将解码器的梯度传到编码器 :param x: 当前层的输入 :return: 一个展平之后的embeddings,并且保存了对应的filter_num """ # 1、将input进行flatten,仅仅保留embedding_dim这一个维度,(Batch_size, H,W,filter_num) input_shape = tf.shape(x) # 将原来的处理过后的特征改变为特定的形状,最后一个维度指定,前两个维度自动调整,(Batch_size*H*W,filter_num) flattened = tf.reshape(x,[-1,self.embedding_dim]) # 2、使用独热编码对embedding进行量化,获取距离最近的 encoding_indices = self.get_code_indices(flattened) # 这里是生成对应的独热编码,位数是embedding的维度,索引是embedding的编号 # 创建一个独热编码矩阵形状为(Batch_size*H*W,self.num_embeddings),根据索引将对应的列置为1 encodings = tf.one_hot(encoding_indices,self.num_embedding) # 矩阵连乘,除了对应的独热编码对应的embedding可以保留,其余的都归零 # matmul矩阵相乘,将之原来的矩阵(Batch_size*H*W,self.num_embeddings), # 映射为一个(Batch_size*H*W,self.embedding_dim)的矩阵 quantized = tf.matmul(encodings,self.embeddings,transpose_b=True) # 将经过独热编码处理之后的embedding还原成原始大小的数据 quantized = tf.reshape(quantized,input_shape) # 计算矢量化的损失,并且将之加到当前层上, # reduce_mean:计算张量指定维度上的平均值 # tf.stop_gradient:不计算输入变量的梯度 commitment_loss = tf.reduce_mean((tf.stop_gradient(quantized) - x ) ** 2) codebook_loss = tf.reduce_mean((quantized - tf.stop_gradient(x) ) ** 2) self.add_loss(self.beta * commitment_loss + codebook_loss) # straight-through estimator:直接将参数的梯度作为对应浮点型参数的梯度 # 直接使用激活函数之后的梯度,代替之前的梯度 quantized = x + tf.stop_gradient(quantized - x ) return quantized def get_code_indices(self,falttened_input): """ 计算输入和不同码字的欧式距离,判定对应的值 :param falttened_input:平展之后的输入 :return: """ # (Batch_size*H*W,filter_num) * (self.embedding_dim,self.num_embedding) similarity = tf.matmul(falttened_input,self.embeddings) # 这部分就是xx+yy-2xy distances = ( tf.reduce_sum(falttened_input**2,axis=1,keepdims=True) + tf.reduce_sum(self.embeddings ** 2,axis=0) - 2 * similarity ) # 这里的最终结果是(Batch_size*H*W,num_embeddings)其中每一个元素为每一个输入样本和码本之间的欧式距离 # 获取最小距离的索引,最终返回的是每一个样本在对应行中最小值,返回的是一个(Batch_size*H*W,1)的数组, # 每一行的特征对应最小的码的索引 encoding_indices = tf.argmin(distances,axis=1) return encoding_indices

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
完整代码实现
from tensorflow.keras import Model # 一般进行版本更新都是改变的包的导向,或者改变包的方法名 from tensorflow.keras.layers import Input,Conv2D,ReLU,BatchNormalization,Flatten,Dense,\ Reshape,Conv2DTranspose,Activation,Lambda from tensorflow.keras import layers,metrics # 引入backend,这个用来自己定义层,将一些函数定义成特定的层 from tensorflow.keras import backend as K # 导入numpy,对三维数据进行操作 import numpy as np # 导入对应优化器,注意,这里已经改变了包的地址 from tensorflow.keras.optimizers.legacy import Adam # 导入损失函数 from tensorflow.keras.losses import MeanSquaredError # 导入系统模块 import os # 序列加载模块 import pickle import tensorflow as tf tf.compat.v1.disable_eager_execution() # 自定义层,自定义矢量量化层 # 这是在编码器和解码器之间自定义的一个层。 # 输入为编码器的输出,形状是(batch_size, height, width,num_filters) # 矢量量化器将会输入进行flatten,仅仅保证过滤核filter的尺寸不变, # 最终的尺寸是batch_size * height * width,num_filters) # 作用:将滤波器的总数当作是潜在embedding的大小 # 然后embedding 表格是被初始化,用来学习码本code book # 我们我们通过计算展平之后的编码器输出和码本码字的欧式距离 # 我们选择距离最小的码字,然后应用独热编码实现量化效果,借此实现了码字和相应距离最近的编码器输出作为关联 # # 因为矢量量化是不可导的,所以直接用解码器的梯度作为编码器的梯度 # # class VectorQuantizer(layers.Layer): def __init__(self,num_embeddings,embedding_dim,beta=0.25,**kwargs): ''' 确定矢量量化的码字尺寸, :param num_embeddings:batch_size * height * width :param embedding_dim:num_filters :param beta:beta参数设置为0.25 :param kwargs: ''' super().__init__(**kwargs) self.embedding_dim = embedding_dim self.num_embedding = num_embeddings self.beta = beta # 初始化将要量化的embedding # 生成具有均匀分布的张量的初始化器 w_init = tf.random_uniform_initializer() # 定义tensorflow中的图片变量并且命名为embedding_vqvae self.embeddings = tf.Variable( initial_value=w_init( shape = (self.embedding_dim,self.num_embedding), dtype = "float32" ), trainable=True, name = "embeddings_vqvae", ) def cal(self,x): """ 步骤: 1、将input进行flatten,仅仅保留embedding_dim这一个维度 2、使用独热编码对embedding进行量化 3、将量化的值,还原回原来的输入形状 4、计算量化层的损失函数 5、将解码器的梯度传到编码器 :param x: 当前层的输入 :return: 一个展平之后的embeddings,并且保存了对应的filter_num """ # 1、将input进行flatten,仅仅保留embedding_dim这一个维度,(Batch_size, H,W,filter_num) input_shape = tf.shape(x) # 将原来的处理过后的特征改变为特定的形状,最后一个维度指定,前两个维度自动调整,(Batch_size*H*W,filter_num) flattened = tf.reshape(x,[-1,self.embedding_dim]) # 2、使用独热编码对embedding进行量化,获取距离最近的 encoding_indices = self.get_code_indices(flattened) # 这里是生成对应的独热编码,位数是embedding的维度,索引是embedding的编号 # 创建一个独热编码矩阵形状为(Batch_size*H*W,self.num_embeddings),根据索引将对应的列置为1 encodings = tf.one_hot(encoding_indices,self.num_embedding) # 矩阵连乘,除了对应的独热编码对应的embedding可以保留,其余的都归零 # matmul矩阵相乘,将之原来的矩阵(Batch_size*H*W,self.num_embeddings), # 映射为一个(Batch_size*H*W,self.embedding_dim)的矩阵 quantized = tf.matmul(encodings,self.embeddings,transpose_b=True) # 将经过独热编码处理之后的embedding还原成原始大小的数据 quantized = tf.reshape(quantized,input_shape) # 计算矢量化的损失,并且将之加到当前层上, # reduce_mean:计算张量指定维度上的平均值 # tf.stop_gradient:不计算输入变量的梯度 commitment_loss = tf.reduce_mean((tf.stop_gradient(quantized) - x ) ** 2) codebook_loss = tf.reduce_mean((quantized - tf.stop_gradient(x) ) ** 2) self.add_loss(self.beta * commitment_loss + codebook_loss) # straight-through estimator:直接将参数的梯度作为对应浮点型参数的梯度 # 直接使用激活函数之后的梯度,代替之前的梯度 quantized = x + tf.stop_gradient(quantized - x ) return quantized def get_code_indices(self,falttened_input): """ 计算输入和不同码字的欧式距离,判定对应的值 :param falttened_input:平展之后的输入 :return: """ # (Batch_size*H*W,filter_num) * (self.embedding_dim,self.num_embedding) similarity = tf.matmul(falttened_input,self.embeddings) # 这部分就是xx+yy-2xy distances = ( tf.reduce_sum(falttened_input**2,axis=1,keepdims=True) + tf.reduce_sum(self.embeddings ** 2,axis=0) - 2 * similarity ) # 这里的最终结果是(Batch_size*H*W,num_embeddings)其中每一个元素为每一个输入样本和码本之间的欧式距离 # 获取最小距离的索引,最终返回的是每一个样本在对应行中最小值,返回的是一个(Batch_size*H*W,1)的数组, # 每一行的特征对应最小的码的索引 encoding_indices = tf.argmin(distances,axis=1) return encoding_indices class VQVAE: """ Autoencoder: 变分自动编码器 这个是在原来的自动编码器上做了如下的修改 1、去除原来的bottleneck部分,换成量化层进行实现 2、更新损失函数,加入KL散度以及修改原来的MSE """ # 1、当前类别的构造函数, def __init__(self, input_shape, conv_filters, conv_kernels, conv_strides, latent_space_dim, num_embeddings ): # 2、 将所有的属性都赋值给对应实体属性 self.input_shape = input_shape # [28,28,1]这里是使用minst手写数据集进行测试的 self.conv_filters = conv_filters # [2,4,8] self.conv_kernels = conv_kernels # [3,5,3] self.conv_strides = conv_strides # [1,2,2] self.latent_space_dim = latent_space_dim # 码本中单个码字的维度 self.num_embeddings = num_embeddings # 码本中码字的个数 # 3、这里的习惯就很好,将一个大模型拆解成两个小模型,编程的时候,只需要对应进行修改就行了 self.encoder = None self.decoder = None self.vq_layer = None self.model = None # 4、将部分变量声明为隐私变量,前置单下划线,私有变量 self._num_conv_layers = len(conv_filters) # 5、设置build函数,这里是实例化类的时候进行调用 self._build() # 9、后续添加的变量 self._shape_encoder = None # 3.1 添加整体模型的输入,和encoder的输入是相同的 self._model_input = None # 4.2 损失函数权重 self.reconstruction_weight = 0.5 # 这个方法在三个模块都是需要修改的 def summary(self): """ 做测试,判定模型是否成功 """ self.encoder.summary() self.decoder.summary() self.model.summary() # 3.2 增加编译函数 def compile(self,learning_rate = 0.0001): """ 指定损失函数和优化器,并对模型进行优化 """ optimizer = Adam(learning_rate = learning_rate) self.model.compile( optimizer = optimizer, loss = self._calculate_reconstruction_loss, ) self.total_loss_tracker = metrics.Mean(name="total_loss") self.reconstruction_loss_tracker = metrics.Mean( name="reconstruction_loss" ) self.vq_loss_tracker = metrics.Mean(name="vq_loss") @property def metrics(self): return [ self.total_loss_tracker, self.reconstruction_loss_tracker, self.vq_loss_tracker, ] # 3.3 增加训练函数 def train(self,x_train,batch_size,num_epochs): self.model.fit( x_train, x_train, batch_size = batch_size, epochs = num_epochs, shuffle = True ) # 3.4 模型保存部分 def save(self,save_folder = "."): """ 保存模型,需要创建文件,分别保存参数和权重""" self._create_folder_if_not_exist(save_folder) self._save_parameters(save_folder) self._save_weights(save_folder) # 3.5 模型加载部分,这部分要注意,是声明为类方法,不用实例化,直接可以调用 @classmethod def load(cls,save_folder ="."): """ 加载模型,包括模型的参数设置和模型的训练权重 """ parameters_path = os.path.join(save_folder,"parameters.pkl") with open(parameters_path,"rb") as f: parameters = pickle.load(f) vae = VQVAE(*parameters) weight_path = os.path.join(save_folder,"weights.h5") vae.load_weights(weight_path) return vae def load_weights(self,weight_path): self.model.load_weights(weight_path) def reconstruct(self,image): """ 重建图片,并返回生成之后的图片以及对应的特征空间 """ latent_space = self.encoder.predict(image) reconstruct_image = self.decoder.predict(latent_space) return reconstruct_image,latent_space # 4.2 将两种损失函数进行综 # 4.2 损失函数重建 def _calculate_reconstruction_loss(self,y_target,y_predict): """ 模型重建损失函数,加上了对应alpha """ error = y_predict - y_target reconstruction_loss = K.mean(K.square(error),axis = [1,2,3]) # 注意,这里只需要返回除了第一个图片序号的后两个维度 return reconstruction_loss # 3.4 分别实现上述方法 def _create_folder_if_not_exist(self,save_folder): if not os.path.exists(save_folder): os.makedirs(save_folder) # 3.4 分别实现上述方法 def _save_parameters(self,save_folder): """ 主要是保存模型对应的参数,包括每一层具体的设置 """ parameters = [ self.input_shape , self.conv_filters, self.conv_kernels, self.conv_strides, self.latent_space_dim ] save_path = os.path.join(save_folder,"parameters.pkl") with open(save_path,"wb") as f: pickle.dump(parameters,f) # 3.4 实现save的子方法 def _save_weights(self,save_folder): save_path = os.path.join(save_folder, "weights.h5") self.model.save_weights(save_path) # 6、具体实现相关的方法,这个是总的build函数,需要构建三个模块,分别是encoder、decoder和model def _build(self): self._build_encoder() self._build_quantizer_layer() self._build_decoder() self._build_VAE() def _build_quantizer_layer(self): # 获取编码器的输出,并生成对应的中间层 # 感觉这里有问题,所有的层应该都是事先已经声明好的 vq_layer = VectorQuantizer(self.num_embeddings,self.latent_space_dim,name = "vector_quantizer") # vq_output = vq_layer(quantizer_input) self.vq_layer = vq_layer # 7、从上到下,逐个子方法进行实现 def _build_encoder(self): # 8、按照网络的层次,将模型串联起来,按照模块进行组装 encoder_input = self._add_encoder_input() conv_layers = self._add_conv_layers(encoder_input) # 调整通道维度,使之和特征空间相适应, encoder_output = layers.Conv2D(self.latent_space_dim,1,padding="same")(conv_layers) self._shape_encoder = encoder_output.shape self._model_input = encoder_input self.encoder = Model(encoder_input,encoder_output,name="encoder") # 8、从上到下,按照顺序,逐个实现_build_encoder模块中所有方法 def _add_encoder_input(self): return Input(shape = self.input_shape,name= "encoder_input") # 8、从上到下,按照顺序,逐个实现_build_encoder模块中所有方法 def _add_conv_layers(self,encoder_input): """ 在编码器中增加卷积模块 """ x = encoder_input # 9、这部分是按照层的顺序逐渐叠加网络层 for layer_index in range(self._num_conv_layers): # 尽量将自己的模块封装在别的人的模块上 x = self._add_conv_layer(layer_index,x) return x # 8、从里到外,完成对应的卷积模块 def _add_conv_layer(self,layer_index,x): """ 增加卷积模块,每一部分构成如下,conv2d + relu + batch normalization """ layer_num = layer_index + 1 conv_layer = Conv2D( filters = self.conv_filters[layer_index], kernel_size = self.conv_kernels[layer_index], strides = self.conv_strides[layer_index], padding = "same", name = f"encoder_conv_layer_{layer_num}" ) x = conv_layer(x) x = ReLU(name = f"encoder_relu_{layer_num}")(x) x = BatchNormalization(name = f"encoder_bn_{layer_num}")(x) return x # 7、从上到下,逐个子方法进行实现 # 2.1 完成解码器的大部分框架 def _build_decoder(self): """ 创建解码器,输入层、全连阶层、恢复成三维、进行反卷积、输出层 """ decoder_input = self._add_decoder_input() conv_transpose_layers = self._add_conv_transpose_layers(decoder_input) decoder_output = self._add_decoder_output(conv_transpose_layers) self.decoder = Model(decoder_input,decoder_output,name = "decoder") # 2.2 具体实现各个子函数,下述函数都是按照顺序完成并实现的 def _add_decoder_input(self): """ 解码器的输入 """ return Input(shape = self._shape_encoder[1:],name = "decoder_input") def _add_dense_layer(self,decoder_input): """ 解码器的全连阶层,输出数据是二维的,这里并不知道怎么设置??""" # 这部分设置神经元的数量,和输出的维度而数量相同 num_neurons = np.prod(self._shape_before_bottleneck) # 将数据恢复原始的数据[1,2,4]=>8,现在是将8转成三维的数组 dense_layer = Dense(num_neurons,name = "decoder_dense_layer")(decoder_input) return dense_layer def _add_reshape_layer(self,dense_layer): """ 增加对应的调整形状层,将全链接层的输出,恢复成三维数组 """ # 这里并不知道调用什么层进行设计 reshape_layer = Reshape(self._shape_before_bottleneck)(dense_layer) return reshape_layer def _add_conv_transpose_layers(self,x): """ 增加反卷积模块 """ # 按照相反的顺序遍历所有的卷积层,并且在第一层停下 for layers_index in reversed(range(1,self._num_conv_layers)): # 理解:原来的卷积层标记[0,1,2],翻转之后的输出为[2,1,0] x = self._add_conv_transpose_layer(x,layers_index) return x def _add_conv_transpose_layer(self,x,layer_index): # 注意,这里的层序号是按照倒序来的,需要还原成正常序号 # 一个卷积模块:卷积层+ReLu+batchnormalization layer_num = self._num_conv_layers - layer_index conv_transpose_layer =Conv2DTranspose( filters = self.conv_filters[layer_index], kernel_size = self.conv_kernels[layer_index], strides = self.conv_strides[layer_index], padding = "same", name = f"decoder_conv_transpose_layer_{layer_num}" ) x = conv_transpose_layer(x) x =ReLU(name=f"decoder_ReLu_{layer_num}")(x) x = BatchNormalization(name = f"decoder_BN_{layer_num}")(x) return x def _add_decoder_output(self,x): """ 增加模型的输出层 """ # 这部分要和encoder是一个完全的逆过程,而且之前的反卷积模块是少了最后一层 # ,所以这里需要额外设置一层 conv_transpose_layer = Conv2DTranspose( filters=1, # filters 对应图片中的channel.最终生成图片是一个[28,28,1]的灰度图片 kernel_size=self.conv_kernels[0], strides=self.conv_strides[0], padding="same", name=f"decoder_conv_transpose_layer_{self._num_conv_layers}" ) x = conv_transpose_layer(x) output_layer = Activation("sigmoid",name = "sigmoid_layer")(x) return output_layer # 3.1 实现整个模型而自动编码器 # 7、从上到下,逐个子方法进行实现 def _build_VAE(self): """ 对于自动编码器的识别,链接编码器和解码器 """ model_input = self._model_input encoder_output = self.encoder(model_input) quantizered = self.vq_layer(encoder_output) # model_output = self.decoder(quantized_latent) model_output = self.decoder(quantizered) self.model = Model(model_input,model_output,name = "VQVAE") if __name__ == '__main__': VAE = VQVAE( input_shape= [28,28,1], conv_filters = [32,64,64,64], conv_kernels = [3,3,3,3], conv_strides= [1, 2, 2, 1], latent_space_dim=16, num_embeddings=64 ) VAE.summary()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 可以加群一块讨论一下关于声音生成的技术
- 群号:722462964
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/秋刀鱼在做梦/article/detail/844949
推荐阅读
相关标签

