
热门标签
热门文章
- 1AGI时代的奠基石:Agent+算力+大模型是构建AI未来的三驾马车吗_ai agent agi
- 2CSDN创作者等级(升级体系①流量②收获③权限 创作者如何快速升级 如何获得创作分 查看我的作者等级 基础增值权益 新手 活跃 资深 免费VIP付费获取积分下载资源高定价权 批量 优先审核 专属运营)_csdn升级
- 3测试岗_用户测试是谁做的
- 4区块链结合物联网会碰撞出怎样的火花?_区块链物联网结合
- 5ubuntu中修改网卡物理地址_ubuntu修改物理地址
- 6简单创建基于Go1.19的站点模板爬虫
- 7第 13 周 / 编程题 - Helloworld for U 【选做】_can be printed
- 8pycon 2018_PyCon UK 2018:我的想法–包括育儿评论
- 9C语言算法赛——蓝桥杯(省赛试题)_蓝桥杯c语言题目省赛
- 10Th3.8:基类和子类指针、虚函数和纯虚函数、多态性详述_基类::子类::函数名称
当前位置: article > 正文
python爬取百度图片_写一个从百度抓取图片的代码 python
作者:秋刀鱼在做梦 | 2024-07-22 15:03:34
赞
踩
写一个从百度抓取图片的代码 python
1.查询数据
打开网页。
我们右键查看网页源代码,发现能找到我们需要的img衔接,但是这是一个动态网页。我们每次向下滑动网页,会发现图片更新,而图片更新一般伴随着异步请求。
并且我们打开控制台,如下图所示:
1.点击网络 2.点击Fetch/XHR

随着向下滑动:
下图红框异步请求次数增多。
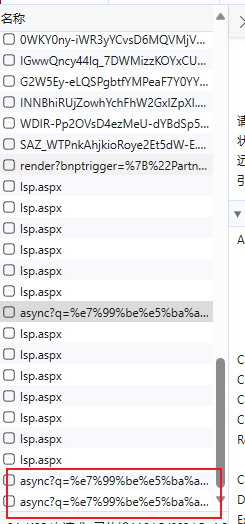
我们将异步请求衔接,在另一个标签页打开。
发现这个异步请求的响应数据有我们需要的图片。

2.请求数据
我们在上面知道是一个动态网页之后,并且找到请求img的地址之后,我们是不是要探寻请求url的规律,发现是如何向下滚动,出现新的图片?
经过查找对比,发现这几个请求参数,新的请求会发生变化。
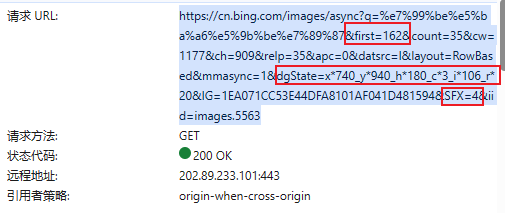
然后,我们通过对这几个参数修改进行请求,发现实际起作用的是first。也就是图片起始索引。
另外,q也就是我们搜索的数据进行url编码之后的东西。
3.解析数据
我们找到我们找寻的图片在哪里,但是发现请求响应的是一堆html + css + js代码,因此我们需要对其进行过滤,只找到我们需要的img的url。
我们在打开刚才的那个异步请求url,查看页面源代码。

将前端代码,粘贴到在线 HTML 格式化工具,HTML 代码美化工具 - 在线工具-wetools.com微工具
这个html格式化工具里面,格式化后,将格式化后的代码,粘贴到vscode里面。
我们查看代码发现,我们需要img的url,是在下图所示的层级结构里面:
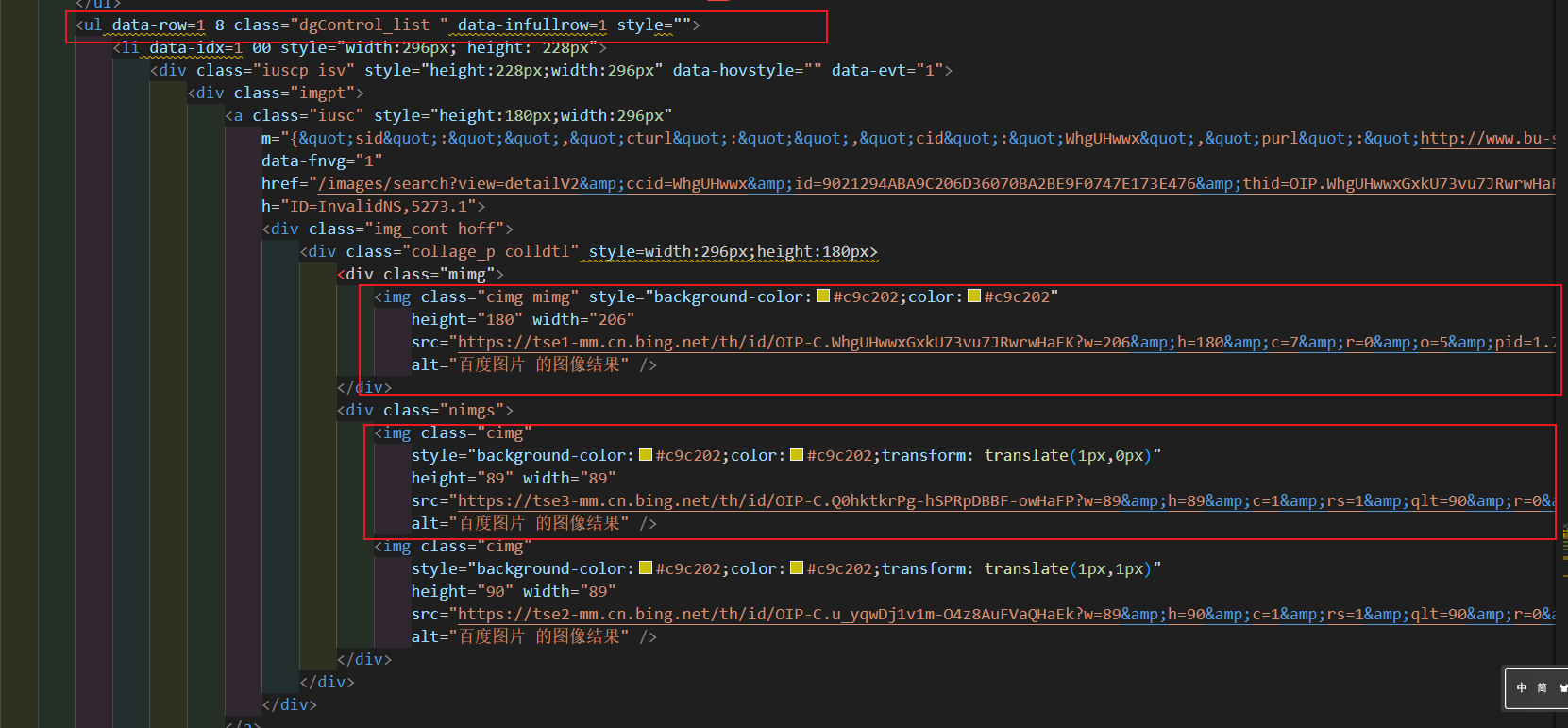 更往上的html层级结构为:
更往上的html层级结构为:
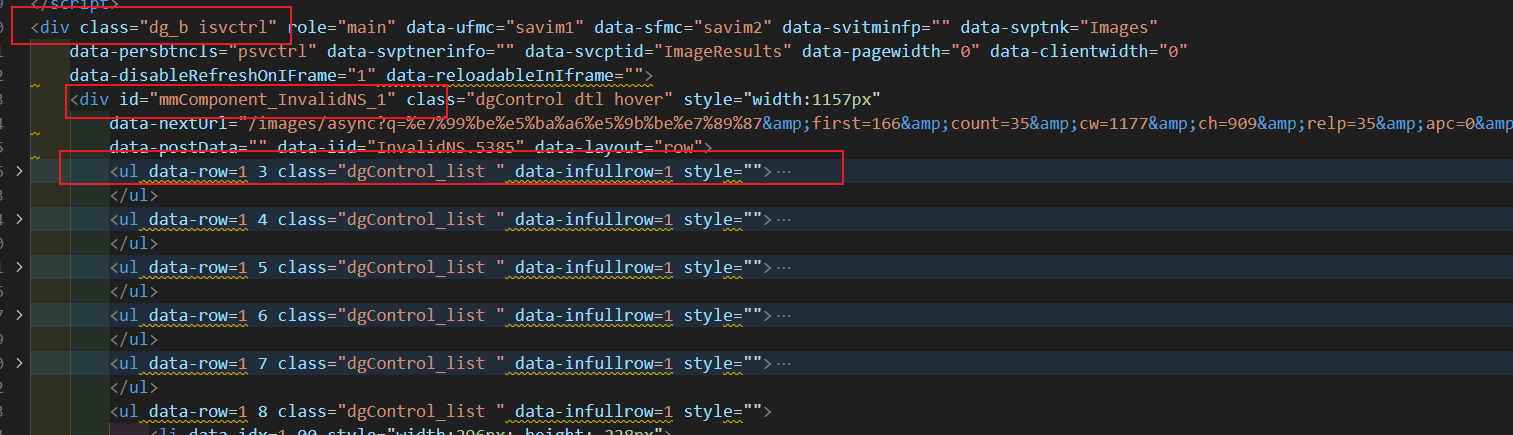
因此我们的python爬虫代码可以这样写:
- from lxml import etree
- import requests
- from fake_useragent import UserAgent
-
-
- if __name__ == '__main__':
- headers = {
- 'User-Agent': UserAgent().random
- }
-
- url = "https://cn.bing.com/images/async?q=%e7%99%be%e5%ba%a6%e5%9b%be%e7%89%87&first=162" \
- "&count=35&cw=1177&ch=909&relp=35&apc=0&datsrc=I&layout=RowBased&mmasync=1&dgState=x*740_y*940_h*180_c*3_i*106_r*20&" \
- "IG=1EA071CC53E44DFA8101AF041D481594&SFX=4&iid=images.5563"
- # 请求响应数据
- html = requests.get(url=url,headers=headers).text
- p = etree.HTML(html)
- img_list = []
- # 解析响应数据
- ul_list = p.xpath('//ul[@data-row]') # 基准表达式
- for ul in ul_list:
- li_list = ul.xpath('.//li[@data-idx]')
- for li in li_list:
- img1_list = list(li.xpath('.//img[contains(@class,"mimg")]/@src'))
- img2_list = list(li.xpath('.//img[contains(@class,"cimg")]/@src'))
- for img1 in img1_list:
- img_list.append(img1)
- for img2 in img2_list:
- img_list.append(img2)
- print(img_list)

4.将图片保存到本地
我们将上述img 衔接,再次进行请求并下载到本地。
- # 保存图片
- def save_images(self, img_list, dir_path, q):
- # 不存在,创建目录
- dir_path = dir_path + '/' + q + "/"
- if not os.path.exists(dir_path):
- os.makedirs(dir_path)
- i = 1
- for img in img_list:
- img_path = '{}{}-{}.jpg'.format(dir_path,q,i)
- self.save_image(img_path,img)
- i += 1
-
- # 保存图片
- def save_image(self,img_path,img):
- html = requests.get(url=img,headers=self.get_headers()).content
- with open(img_path,'wb') as f:
- f.write(html)
4.完整代码
- from lxml import etree
- import requests
- from fake_useragent import UserAgent
- from urllib import parse
- import os
-
-
-
- class BaiduSpider:
- def __init__(self):
- self.url = "https://cn.bing.com/images/async?q={}&first={}&count=35&cw=1177&ch=909" \
- "&relp=35&apc=0&datsrc=I&layout=RowBased&mmasync=1"
-
- # 获取请求头
- def get_headers(self):
- return {
- 'User-Agent': UserAgent().random
- }
-
- # 获取响应数据
- def get_html(self, q, first):
- q = parse.quote(q)
- url = self.url.format(q, first)
- html = requests.get(url=url, headers=self.get_headers()).text
- return html
-
- # 解析响应数据
- def parse_html(self, html):
- p = etree.HTML(html)
- img_list = []
- # 基准表达式
- ul_list = p.xpath('//ul[@data-row]')
- for ul in ul_list:
- li_list = ul.xpath('.//li[@data-idx]')
- for li in li_list:
- img1_list = list(li.xpath('.//img[contains(@class,"mimg")]/@src'))
- img2_list = list(li.xpath('.//img[contains(@class,"cimg")]/@src'))
- for img1 in img1_list:
- img_list.append(img1)
- for img2 in img2_list:
- img_list.append(img2)
-
- print(img_list)
- return img_list
-
- # 保存图片列表
- def save_images(self, img_list, dir_path, q):
- # 不存在,创建目录
- dir_path = dir_path + '/' + q + "/"
- if not os.path.exists(dir_path):
- os.makedirs(dir_path)
- i = 1
- for img in img_list:
- img_path = '{}{}-{}.jpg'.format(dir_path,q,i)
- self.save_image(img_path,img)
- i += 1
-
- # 保存图片
- def save_image(self,img_path,img):
- html = requests.get(url=img,headers=self.get_headers()).content
- with open(img_path,'wb') as f:
- f.write(html)
-
- # 入口函数
- def run(self):
- q = input("请输入搜索内容:")
- first = int(input("请输入起始页数:"))
- dir_path = "../img"
- html = self.get_html(q, first)
- img_list = self.parse_html(html)
- self.save_images(img_list, dir_path, q)
-
-
- if __name__ == '__main__':
- bds = BaiduSpider()
- bds.run()
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

