
- 1spark为什么比mapreduce快?_下面哪些是spark比mapreduce计算快的原因(4分) a 基于内存的计算 b 基于dag的调
- 2Android 进阶——常用的Base64编码算法和MD5 信息摘要算法详解_android md5
- 3使用llama.cpp实现LLM大模型的格式转换、量化、推理、部署
- 4LLM 大模型实用指南 | The Practical Guides for Large Language Models_ret-llm: towards a general read-write memory for l
- 5activemq的优势_【消息队列】1-为什么使用消息队列?消息队列有什么优点和缺点?Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么优点和缺点?...
- 6数据结构之B树
- 7智能新时代的天津故事
- 8谷歌插件市场
- 9请求限流算法有哪些?分别面向什么应用场景?_对用户请求限流
- 10华为OD机试C卷-- 贪吃的猴子(Java & JS & Python & C)
使用SparkSQL的电影分析_spark统计出:每个类别的 平均电影评分。
赞
踩
项目介绍
数据集介绍
使用MovieLens的名称为ml-25m.zip的数据集,使用的文件时movies.csv和ratings.csv,上述文件的下载地址为:
http://files.grouplens.org/datasets/movielens/ml-25m.zip
-
movies.csv
该文件是电影数据,对应的为维表数据,大小为2.89MB,包括6万多部电影,其数据格式为[movieId,title,genres],分别对应[电影id,电影名称,电影所属分类],样例数据如下所示:逗号分隔
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
-
ratings.csv
该文件为定影评分数据,对应为事实表数据,大小为646MB,其数据格式为:[userId,movieId,rating,timestamp],分别对应[用户id,电影id,评分,时间戳],样例数据如下所示:逗号分隔
1,296,5,1147880044
项目代码结构
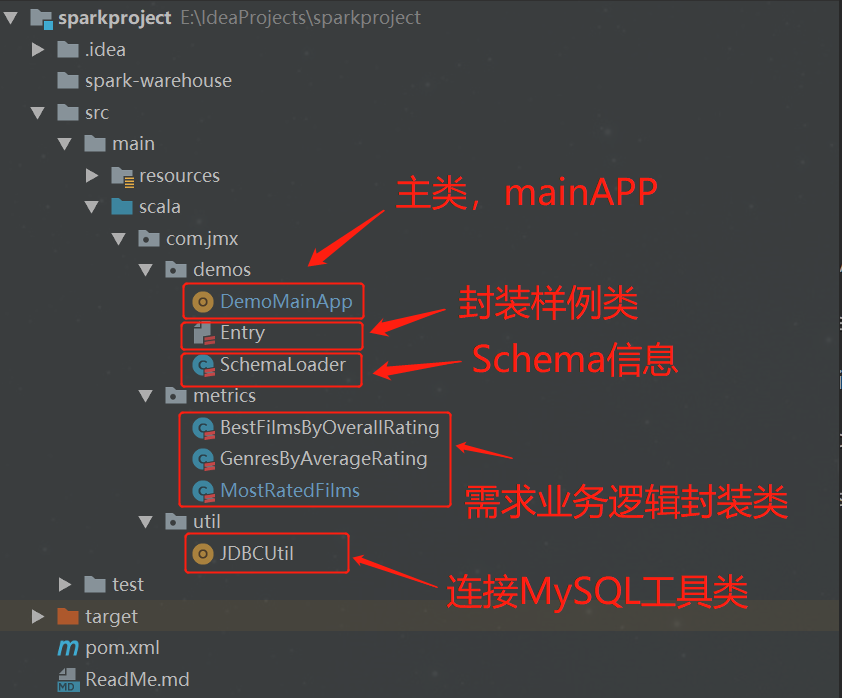
需求分析
-
需求1:查找电影评分个数超过5000,且平均评分较高的前十部电影名称及其对应的平均评分

-
需求2:查找每个电影类别及其对应的平均评分

-
需求3:查找被评分次数较多的前十部电影

代码讲解
-
DemoMainApp
该类是程序执行的入口,主要是获取数据源,转换成DataFrame,并调用封装好的业务逻辑类。
- object DemoMainApp {
- // 文件路径
- private val MOVIES_CSV_FILE_PATH = "file:///e:/movies.csv"
- private val RATINGS_CSV_FILE_PATH = "file:///e:/ratings.csv"
-
- def main(args: Array[String]): Unit = {
- // 创建spark session
- val spark = SparkSession
- .builder
- .master("local[4]")
- .getOrCreate
- // schema信息
- val schemaLoader = new SchemaLoader
- // 读取Movie数据集
- val movieDF = readCsvIntoDataSet(spark, MOVIES_CSV_FILE_PATH, schemaLoader.getMovieSchema)
- // 读取Rating数据集
- val ratingDF = readCsvIntoDataSet(spark, RATINGS_CSV_FILE_PATH, schemaLoader.getRatingSchema)
-
- // 需求1:查找电影评分个数超过5000,且平均评分较高的前十部电影名称及其对应的平均评分
- val bestFilmsByOverallRating = new BestFilmsByOverallRating
- //bestFilmsByOverallRating.run(movieDF, ratingDF, spark)
-
- // 需求2:查找每个电影类别及其对应的平均评分
- val genresByAverageRating = new GenresByAverageRating
- //genresByAverageRating.run(movieDF, ratingDF, spark)
-
- // 需求3:查找被评分次数较多的前十部电影
- val mostRatedFilms = new MostRatedFilms
- mostRatedFilms.run(movieDF, ratingDF, spark)
-
- spark.close()
-
- }
- /**
- * 读取数据文件,转成DataFrame
- *
- * @param spark
- * @param path
- * @param schema
- * @return
- */
- def readCsvIntoDataSet(spark: SparkSession, path: String, schema: StructType) = {
-
- val dataSet = spark.read
- .format("csv")
- .option("header", "true")
- .schema(schema)
- .load(path)
- dataSet
- }
- }

-
Entry
该类为实体类,封装了数据源的样例类和结果表的样例类
- class Entry {
-
- }
-
- case class Movies(
- movieId: String, // 电影的id
- title: String, // 电影的标题
- genres: String // 电影类别
- )
-
- case class Ratings(
- userId: String, // 用户的id
- movieId: String, // 电影的id
- rating: String, // 用户评分
- timestamp: String // 时间戳
- )
-
- // 需求1MySQL结果表
- case class tenGreatestMoviesByAverageRating(
- movieId: String, // 电影的id
- title: String, // 电影的标题
- avgRating: String // 电影平均评分
- )
-
- // 需求2MySQL结果表
- case class topGenresByAverageRating(
- genres: String, //电影类别
- avgRating: String // 平均评分
- )
-
- // 需求3MySQL结果表
- case class tenMostRatedFilms(
- movieId: String, // 电影的id
- title: String, // 电影的标题
- ratingCnt: String // 电影被评分的次数
- )
-
SchemaLoader
该类封装了数据集的schema信息,主要用于读取数据源是指定schema信息
- class SchemaLoader {
- // movies数据集schema信息
- private val movieSchema = new StructType()
- .add("movieId", DataTypes.StringType, false)
- .add("title", DataTypes.StringType, false)
- .add("genres", DataTypes.StringType, false)
- // ratings数据集schema信息
- private val ratingSchema = new StructType()
- .add("userId", DataTypes.StringType, false)
- .add("movieId", DataTypes.StringType, false)
- .add("rating", DataTypes.StringType, false)
- .add("timestamp", DataTypes.StringType, false)
-
- def getMovieSchema: StructType = movieSchema
-
- def getRatingSchema: StructType = ratingSchema
- }
-
JDBCUtil
该类封装了连接MySQL的逻辑,主要用于连接MySQL,在业务逻辑代码中会使用该工具类获取MySQL连接,将结果数据写入到MySQL中。
- object JDBCUtil {
- val dataSource = new ComboPooledDataSource()
- val user = "root"
- val password = "123qwe"
- val url = "jdbc:mysql://localhost:3306/mydb"
-
- dataSource.setUser(user)
- dataSource.setPassword(password)
- dataSource.setDriverClass("com.mysql.jdbc.Driver")
- dataSource.setJdbcUrl(url)
- dataSource.setAutoCommitOnClose(false)
- // 获取连接
- def getQueryRunner(): Option[QueryRunner]={
- try {
- Some(new QueryRunner(dataSource))
- }catch {
- case e:Exception =>
- e.printStackTrace()
- None
- }
- }
- }
需求1实现
-
BestFilmsByOverallRating
需求1实现的业务逻辑封装。该类有一个run()方法,主要是封装计算逻辑。
- /**
- * 需求1:查找电影评分个数超过5000,且平均评分较高的前十部电影名称及其对应的平均评分
- */
- class BestFilmsByOverallRating extends Serializable {
-
- def run(moviesDataset: DataFrame, ratingsDataset: DataFrame, spark: SparkSession) = {
- import spark.implicits._
-
- // 将moviesDataset注册成表
- moviesDataset.createOrReplaceTempView("movies")
- // 将ratingsDataset注册成表
- ratingsDataset.createOrReplaceTempView("ratings")
-
- // 查询SQL语句
- val ressql1 =
- """
- |WITH ratings_filter_cnt AS (
- |SELECT
- | movieId,
- | count( * ) AS rating_cnt,
- | avg( rating ) AS avg_rating
- |FROM
- | ratings
- |GROUP BY
- | movieId
- |HAVING
- | count( * ) >= 5000
- |),
- |ratings_filter_score AS (
- |SELECT
- | movieId, -- 电影id
- | avg_rating -- 电影平均评分
- |FROM ratings_filter_cnt
- |ORDER BY avg_rating DESC -- 平均评分降序排序
- |LIMIT 10 -- 平均分较高的前十部电影
- |)
- |SELECT
- | m.movieId,
- | m.title,
- | r.avg_rating AS avgRating
- |FROM
- | ratings_filter_score r
- |JOIN movies m ON m.movieId = r.movieId
- """.stripMargin
-
- val resultDS = spark.sql(ressql1).as[tenGreatestMoviesByAverageRating]
- // 打印数据
- resultDS.show(10)
- resultDS.printSchema()
- // 写入MySQL
- resultDS.foreachPartition(par => par.foreach(insert2Mysql(_)))
- }
-
- /**
- * 获取连接,调用写入MySQL数据的方法
- *
- * @param res
- */
- private def insert2Mysql(res: tenGreatestMoviesByAverageRating): Unit = {
- lazy val conn = JDBCUtil.getQueryRunner()
- conn match {
- case Some(connection) => {
- upsert(res, connection)
- }
- case None => {
- println("Mysql连接失败")
- System.exit(-1)
- }
- }
- }
-
- /**
- * 封装将结果写入MySQL的方法
- * 执行写入操作
- *
- * @param r
- * @param conn
- */
- private def upsert(r: tenGreatestMoviesByAverageRating, conn: QueryRunner): Unit = {
- try {
- val sql =
- s"""
- |REPLACE INTO `ten_movies_averagerating`(
- |movieId,
- |title,
- |avgRating
- |)
- |VALUES
- |(?,?,?)
- """.stripMargin
- // 执行insert操作
- conn.update(
- sql,
- r.movieId,
- r.title,
- r.avgRating
- )
- } catch {
- case e: Exception => {
- e.printStackTrace()
- System.exit(-1)
- }
- }
- }
- }
需求1结果
-
结果表建表语句
- CREATE TABLE `ten_movies_averagerating` (
- `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
- `movieId` int(11) NOT NULL COMMENT '电影id',
- `title` varchar(100) NOT NULL COMMENT '电影名称',
- `avgRating` decimal(10,2) NOT NULL COMMENT '平均评分',
- `update_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `movie_id_UNIQUE` (`movieId`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
统计结果
平均评分最高的前十部电影如下:
| movieId | title | avgRating |
|---|---|---|
| 318 | Shawshank Redemption, The (1994) | 4.41 |
| 858 | Godfather, The (1972) | 4.32 |
| 50 | Usual Suspects, The (1995) | 4.28 |
| 1221 | Godfather: Part II, The (1974) | 4.26 |
| 527 | Schindler's List (1993) | 4.25 |
| 2019 | Seven Samurai (Shichinin no samurai) (1954) | 4.25 |
| 904 | Rear Window (1954) | 4.24 |
| 1203 | 12 Angry Men (1957) | 4.24 |
| 2959 | Fight Club (1999) | 4.23 |
| 1193 | One Flew Over the Cuckoo's Nest (1975) | 4.22 |
上述电影评分对应的电影中文名称为:
| 英文名称 | 中文名称 |
|---|---|
| Shawshank Redemption, The (1994) | 肖申克的救赎 |
| Godfather, The (1972) | 教父1 |
| Usual Suspects, The (1995) | 非常嫌疑犯 |
| Godfather: Part II, The (1974) | 教父2 |
| Schindler's List (1993) | 辛德勒的名单 |
| Seven Samurai (Shichinin no samurai) (1954) | 七武士 |
| Rear Window (1954) | 后窗 |
| 12 Angry Men (1957) | 十二怒汉 |
| Fight Club (1999) | 搏击俱乐部 |
| One Flew Over the Cuckoo's Nest (1975) | 飞越疯人院 |
需求2实现
-
GenresByAverageRating
需求2实现的业务逻辑封装。该类有一个run()方法,主要是封装计算逻辑。
- **
- * 需求2:查找每个电影类别及其对应的平均评分
- */
- class GenresByAverageRating extends Serializable {
- def run(moviesDataset: DataFrame, ratingsDataset: DataFrame, spark: SparkSession) = {
- import spark.implicits._
- // 将moviesDataset注册成表
- moviesDataset.createOrReplaceTempView("movies")
- // 将ratingsDataset注册成表
- ratingsDataset.createOrReplaceTempView("ratings")
-
- val ressql2 =
- """
- |WITH explode_movies AS (
- |SELECT
- | movieId,
- | title,
- | category
- |FROM
- | movies lateral VIEW explode ( split ( genres, "\\|" ) ) temp AS category
- |)
- |SELECT
- | m.category AS genres,
- | avg( r.rating ) AS avgRating
- |FROM
- | explode_movies m
- | JOIN ratings r ON m.movieId = r.movieId
- |GROUP BY
- | m.category
- | """.stripMargin
-
- val resultDS = spark.sql(ressql2).as[topGenresByAverageRating]
-
- // 打印数据
- resultDS.show(10)
- resultDS.printSchema()
- // 写入MySQL
- resultDS.foreachPartition(par => par.foreach(insert2Mysql(_)))
-
- }
-
- /**
- * 获取连接,调用写入MySQL数据的方法
- *
- * @param res
- */
- private def insert2Mysql(res: topGenresByAverageRating): Unit = {
- lazy val conn = JDBCUtil.getQueryRunner()
- conn match {
- case Some(connection) => {
- upsert(res, connection)
- }
- case None => {
- println("Mysql连接失败")
- System.exit(-1)
- }
- }
- }
-
- /**
- * 封装将结果写入MySQL的方法
- * 执行写入操作
- *
- * @param r
- * @param conn
- */
- private def upsert(r: topGenresByAverageRating, conn: QueryRunner): Unit = {
- try {
- val sql =
- s"""
- |REPLACE INTO `genres_average_rating`(
- |genres,
- |avgRating
- |)
- |VALUES
- |(?,?)
- """.stripMargin
- // 执行insert操作
- conn.update(
- sql,
- r.genres,
- r.avgRating
- )
- } catch {
- case e: Exception => {
- e.printStackTrace()
- System.exit(-1)
- }
- }
- }
- }
需求2结果
-
结果表建表语句
- CREATE TABLE genres_average_rating (
- `id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT '自增id',
- `genres` VARCHAR ( 100 ) NOT NULL COMMENT '电影类别',
- `avgRating` DECIMAL ( 10, 2 ) NOT NULL COMMENT '电影类别平均评分',
- `update_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
- PRIMARY KEY ( `id` ),
- UNIQUE KEY `genres_UNIQUE` ( `genres` )
- ) ENGINE = INNODB DEFAULT CHARSET = utf8;
-
统计结果
共有20个电影分类,每个电影分类的平均评分为:
| genres | avgRating |
|---|---|
| Film-Noir | 3.93 |
| War | 3.79 |
| Documentary | 3.71 |
| Crime | 3.69 |
| Drama | 3.68 |
| Mystery | 3.67 |
| Animation | 3.61 |
| IMAX | 3.6 |
| Western | 3.59 |
| Musical | 3.55 |
| Romance | 3.54 |
| Adventure | 3.52 |
| Thriller | 3.52 |
| Fantasy | 3.51 |
| Sci-Fi | 3.48 |
| Action | 3.47 |
| Children | 3.43 |
| Comedy | 3.42 |
| (no genres listed) | 3.33 |
| Horror | 3.29 |
电影分类对应的中文名称为:
| 分类 | 中文名称 |
|---|---|
| Film-Noir | 黑色电影 |
| War | 战争 |
| Documentary | 纪录片 |
| Crime | 犯罪 |
| Drama | 历史剧 |
| Mystery | 推理 |
| Animation | 动画片 |
| IMAX | 巨幕电影 |
| Western | 西部电影 |
| Musical | 音乐 |
| Romance | 浪漫 |
| Adventure | 冒险 |
| Thriller | 惊悚片 |
| Fantasy | 魔幻电影 |
| Sci-Fi | 科幻 |
| Action | 动作 |
| Children | 儿童 |
| Comedy | 喜剧 |
| (no genres listed) | 未分类 |
| Horror | 恐怖 |
需求3实现
-
MostRatedFilms
需求3实现的业务逻辑封装。该类有一个run()方法,主要是封装计算逻辑。
- /**
- * 需求3:查找被评分次数较多的前十部电影.
- */
- class MostRatedFilms extends Serializable {
- def run(moviesDataset: DataFrame, ratingsDataset: DataFrame,spark: SparkSession) = {
-
- import spark.implicits._
-
- // 将moviesDataset注册成表
- moviesDataset.createOrReplaceTempView("movies")
- // 将ratingsDataset注册成表
- ratingsDataset.createOrReplaceTempView("ratings")
-
- val ressql3 =
- """
- |WITH rating_group AS (
- | SELECT
- | movieId,
- | count( * ) AS ratingCnt
- | FROM ratings
- | GROUP BY movieId
- |),
- |rating_filter AS (
- | SELECT
- | movieId,
- | ratingCnt
- | FROM rating_group
- | ORDER BY ratingCnt DESC
- | LIMIT 10
- |)
- |SELECT
- | m.movieId,
- | m.title,
- | r.ratingCnt
- |FROM
- | rating_filter r
- |JOIN movies m ON r.movieId = m.movieId
- |
- """.stripMargin
-
- val resultDS = spark.sql(ressql3).as[tenMostRatedFilms]
- // 打印数据
- resultDS.show(10)
- resultDS.printSchema()
- // 写入MySQL
- resultDS.foreachPartition(par => par.foreach(insert2Mysql(_)))
-
- }
-
- /**
- * 获取连接,调用写入MySQL数据的方法
- *
- * @param res
- */
- private def insert2Mysql(res: tenMostRatedFilms): Unit = {
- lazy val conn = JDBCUtil.getQueryRunner()
- conn match {
- case Some(connection) => {
- upsert(res, connection)
- }
- case None => {
- println("Mysql连接失败")
- System.exit(-1)
- }
- }
- }
-
- /**
- * 封装将结果写入MySQL的方法
- * 执行写入操作
- *
- * @param r
- * @param conn
- */
- private def upsert(r: tenMostRatedFilms, conn: QueryRunner): Unit = {
- try {
- val sql =
- s"""
- |REPLACE INTO `ten_most_rated_films`(
- |movieId,
- |title,
- |ratingCnt
- |)
- |VALUES
- |(?,?,?)
- """.stripMargin
- // 执行insert操作
- conn.update(
- sql,
- r.movieId,
- r.title,
- r.ratingCnt
- )
- } catch {
- case e: Exception => {
- e.printStackTrace()
- System.exit(-1)
- }
- }
- }
-
- }
-
需求3结果
-
结果表创建语句
- CREATE TABLE ten_most_rated_films (
- `id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT '自增id',
- `movieId` INT ( 11 ) NOT NULL COMMENT '电影Id',
- `title` varchar(100) NOT NULL COMMENT '电影名称',
- `ratingCnt` INT(11) NOT NULL COMMENT '电影被评分的次数',
- `update_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
- PRIMARY KEY ( `id` ),
- UNIQUE KEY `movie_id_UNIQUE` ( `movieId` )
- ) ENGINE = INNODB DEFAULT CHARSET = utf8;
-
统计结果
| movieId | title | ratingCnt |
|---|---|---|
| 356 | Forrest Gump (1994) | 81491 |
| 318 | Shawshank Redemption, The (1994) | 81482 |
| 296 | Pulp Fiction (1994) | 79672 |
| 593 | Silence of the Lambs, The (1991) | 74127 |
| 2571 | Matrix, The (1999) | 72674 |
| 260 | Star Wars: Episode IV - A New Hope (1977) | 68717 |
| 480 | Jurassic Park (1993) | 64144 |
| 527 | Schindler's List (1993) | 60411 |
| 110 | Braveheart (1995) | 59184 |
| 2959 | Fight Club (1999) | 58773 |
评分次数较多的电影对应的中文名称为:
| 英文名称 | 中文名称 |
|---|---|
| Forrest Gump (1994) | 阿甘正传 |
| Shawshank Redemption, The (1994) | 肖申克的救赎 |
| Pulp Fiction (1994) | 低俗小说 |
| Silence of the Lambs, The (1991) | 沉默的羔羊 |
| Matrix, The (1999) | 黑客帝国 |
| Star Wars: Episode IV - A New Hope (1977) | 星球大战 |
| Jurassic Park (1993) | 侏罗纪公园 |
| Schindler's List (1993) | 辛德勒的名单 |
| Braveheart (1995) | 勇敢的心 |
| Fight Club (1999) | 搏击俱乐部 |
总结
本文主要是基于SparkSQL对MovieLens数据集进行统计分析,完整实现了三个需求,并给对每个需求都给出了详细的代码实现和结果分析。本案例还原了企业使用SparkSQL进行实现数据统计的基本流程

